@gaoxiaoyunwei2017
2018-03-22T06:13:54.000000Z
字数 7270
阅读 1322
自动化运维-胥峰
DevOps三十六计
对自动化运维体系的需求,是随着业务的增长、对运维效率和质量的要求不断提高而产生的。
前言:
在很多初创公司和中小型企业里,运维还停留在“刀耕火种”的原始状态,这里所说的“刀”和“火”就是运维人员的远程客户端,例如SecureCRT和Windows远程桌面。
在这种工作方式下,服务器的安装、初始化,软件部署、服务发布和监控都是通过手动方式来完成的,需要运维人员登录到服务器上,一台一台去管理和维护。这种非并发的线性工作方式是制约效率的最大障碍。
同时,因为手动的操作方式过于依赖运维人员的执行顺序和操作步骤,稍有不慎即可能导致服务器配置不一致,也就是同一组服务器的配置上出现差异。有时候,这种差异是很难直接检查出来的,例如在一个负载均衡组里面个别服务器的异常就很难发现。
随着业务的发展,服务器数量越来越多,运维人员开始转向使用脚本和批量管理工具。脚本和批量管理工具与“刀耕火种”的工作方式相比,确实提升了效率和工程质量。
但这个方式仍然有很多问题。
第一是脚本的非标准化的问题。不同运维人员写的脚本在所用的编程语言、编码风格和健壮性方面存在巨大差异,同时这些脚本的版本管理也是一个挑战。
第二是脚本的传承问题,人员的离职和工作交接,都会导致脚本无法很好地在运维人员之间传承和再利用,因为下一个运维人员可能无法理解和修改前一个运维人员编写的脚本功能。
第三是批量管理工具的选择。不同的管理人员选择不同的批量管理工具必然会带来管理混乱的问题,也无法很好地实现在运维人员之间互相备份工作的需求。
因此,对构建自动化运维体系的要求变得越来越迫切。通过自动化运维体系来实现标准化和提高工程效率,是唯一正确的选择。那么如何建设自动化运维体系呢?
本案例研究分为三个大的方面:
第一个是为什么要建设自动化运维体系,就是解决“3W”中的Why和What的问题,即为什么和是什么。
第二个是介绍我司各个运维子系统是怎样设计、运行和处理问题的,解决“3W”中的How的问题,也就是怎样去做的。
第三个是对我司在自动化运维过程中遇到的一些问题的思考,做一个总结。
一、建设自动化运维体系的原因
先来看一下我们为什么要建设一个自动化运维体系。首先来看运维遇到的一些挑战,如下图所示。
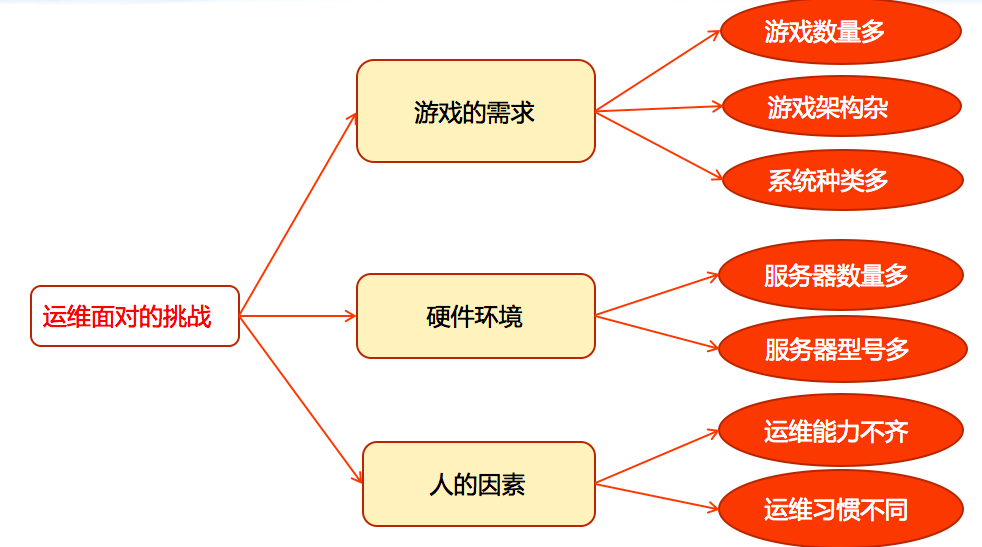
运维面对的挑战
第一个是游戏的需求。它表现为三个方面:
一是游戏数量多,我司现在运营的游戏多达近百款。
二是游戏架构复杂。游戏公司和一般的互联网公司有一个很大的区别,就是游戏的来源可能有很多,比如有国外的、国内的,有大厂商的、小厂商的;每个游戏的架构可能不一样,有的是分区制的,有的是集中制的,各种各样的需求。
三是操作系统种类多,这与刚才的情况类似,游戏开发者的背景与编程喜好不一样,会有Windows、Linux等。
第二个是在硬件环境方面,主要表现为服务器数量多、服务器型号多。因为公司从建立到现在有十几年的时间了,在这个过程中分批、分期采购的服务器几乎横跨各大OEM厂商的各大产品线,型号多而杂。
最后是人的因素。我们在建设自动化运维体系过程中,有一个比较重要的考虑点是人的因素。如果大家的技术能力都很强,很多时候一个人可以完成所有工作,可能也就不需要自动化运维体系了。正是因为每个运维人员的能力不一样,技术水平参差不齐,甚至是运维习惯和工具也不一样,导致我们必须要创建一套规范的自动化运维体系,来提升工作效率。
二、建设自动化运维体系的目标
再看一下建设这套自动化运维体系的目标,也就是说我们的原则是什么?笔者将自动化运维体系的建设目标总结为四个词。
第一个是“完备”,这个系统要能涵盖所有的运维需求。
第二个是“简洁”,简单好用。如果系统的操作流程、操作界面、设计思想都比较复杂,运维人员的学习成本就会很高,使用的效果是会打折扣的,系统的能力、发挥的效率也会因此打折扣。
第三个是“高效”,特别是在批量处理或者执行特定任务时,我们希望系统能够及时给用户反馈。
第四个是“安全”,如果一个系统不安全,可能导致很快就被黑客接管了。所以安全也是重要的因素。
三、自动化运维体系的结构和运作方式
下图所示是我司当前自动化运维体系的几个子系统,我们来看一看它们是怎样联合起来工作的。首先服务器会经由自动化安装系统完成安装,然后会被自动化运维平台接管。自动化运维平台会对自动化安检系统、自动化客户端更新系统和服务器端更新系统提供底层支撑。自动化数据分析系统和自动化客户端更新系统会有关联关系。自动化数据分析系统会对自动化客户端更新系统的结果给予反馈。
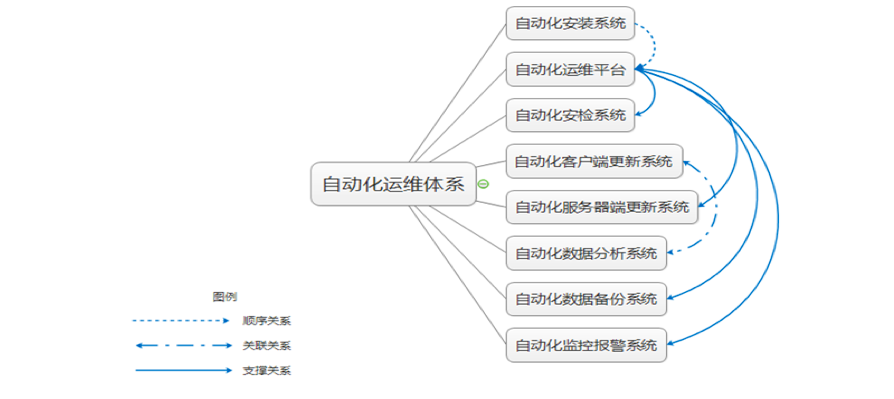
自动化运维体系结构图
下面我们来看一下每个子系统是如何设计和工作的。
3.1、自动化安装系统
说到自动化安装,大家可能并不陌生,我们刚才说到挑战是“两多两少”,型号多、操作系统多,但是人少,可用时间也比较少。
如下图所示,整个流程采用通用的框架,首先由PXE启动,选择需要安装的操作系统类型(安装Windows或者Linux),然后根据Windows系统自动识别出需要安装的驱动。服务器交付用户之前,会进行基本的安全设置,例如防火墙设置以及关闭Windows共享,这在一定程度上提高了安全性,也减少了需要人工做的一些操作。
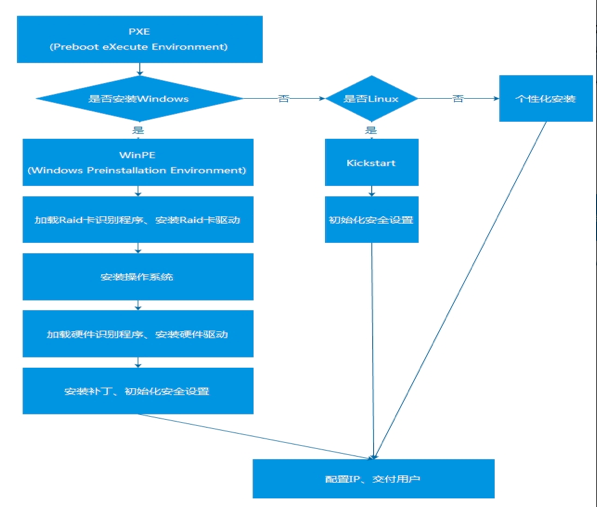
自动化安装流程图
3.2、自动化运维平台
当服务器由自动化安装系统安装完成以后,就会被自动化运维平台接管。自动化运维平台是运维人员的作业平台,它主要解决的问题就是因服务器、操作系统异构而且数量特别多而带来的管理问题。操作系统是五花八门的,我们在设计系统过程中考虑了以下几个因素:
把整个系统的用户界面设计成基于浏览器的架构。运维工程师无论何时何地都可以登录管理系统进行运维操作,这样的话就比较方便。由Octopod服务器对被操作的机器发布指令。
统一管理异构服务器。大家以前可能对Windows深恶痛绝,其实Windows也可以管得很好。我们使用开源的SSH方式管理Windows,这样就可以对系统进行批量的补丁更新,还可以做批量的密码管理和操作。
充分利用现有协议和工具。这个平台的特点是所有的系统使用SSH管理,而不是自己开发一些Agent,这也体现了自动化运维的观点。很多时候我们没必要重新造轮子,即使自己造出一套客户端的方法,大部分时候也并没有在生产环境里得到严格的验证。而SSH协议本身已经存在很多年了,而且已经在我司使用了很多年,该出的问题已经出了,相对于造轮子,使用SSH更加稳定,更经得起考验,使用起来更方便。
3.3、自动化安检系统
下一个系统是自动化安检系统。由于我们的子系统比较多,业务也比较多,怎样设计一套系统去保障它们的安全呢?这里主要是两个系统:自动化安检平台和服务器端。
先来看自动化安检平台。游戏公司和一般的互联网公司有一个区别,就是前者需要给玩家发送很多的客户端(特别是有的客户端比较大),或者补丁文件,去更新、下载和安装。如果这些文件里面出现病毒和木马,将是一件很糟糕的事情,甚至会对业务和公司的声誉造成恶劣影响。当这些文件被发到玩家电脑上之前,必须经过病毒检测系统检测,确保它没有被注入相应的病毒代码。
再来看服务器端,主要是通过安全扫描架构来保障安全。安全并不是一蹴而就,一劳永逸的。如果不对系统持续地检查、检测、探测,那么你的一些误操作会导致系统暴露在互联网上,或者是暴露在恶意攻击者的眼皮之下。通过一种主动、自发的安全扫描架构对所有服务器进行安全扫描,就能在很大程度上规避这样的问题。举一个例子,去年我们遇到过一个情况,某款交换机ACL达到一定的数量的时候,就完全失效了。如果没有相关的配套机制去检查和检测,那么你的服务器、你认为保护得很好的端口或者是敏感的IP可能已经暴露。所以,通过这种主动的探测可以减少很多系统的或者是人为的安全问题。
3.4、自动化客户端更新系统
游戏是有周期性的,特别是在游戏发布当天或者有版本更新的时候,这时候玩家活跃度很高,下载行为也是比较多的,但是平时的更新和下载带宽可能并不大,这也是游戏很显著的特点。这个特点对于我们构建这样一个分发系统提出了很大的挑战。第一个挑战就是在高峰时游戏产生的带宽可能达到数百GB。第二是很多小运营商或者中小规模的运营商会有一些缓存机制,这个缓存机制如果处理得不好,会对业务造成影响,也就是非法缓存的问题。第三是关于DNS调度的问题。DNS调度本身是基于玩家本身的Local DNS的机制解析的,会有调度不准确的问题。第四是DNS污染,或者是DNS TTL的机制导致调度不那么灵敏和准确。针对这些问题,我们有下面两套系统来解决。
第一套是Autopatch系统,它解决的是大文件更新的下载问题,再就是多家CDN厂商流量调度。其操作流程也比较简单,由运维人员上传文件、安检,然后同步到CDN,由CDN分发到相关边缘节点,最后解压文件。刚才说到游戏的周期性特点,就是平时带宽不是很大,但是在某个节点的时候,或者是重大活动的时候,带宽比较大。如果自己构建一套CDN系统,可能不是很划算,所以我们引入国内多家比较大型的CDN厂商调度资源。我们通过302的方法调度,而不是把域名给其中一家或几家。因为直接使用CNAME的话很难按比例调度,特别是带宽大的时候,一家CDN厂商解决不了,或者是一家发生局部故障,需要快速切除。而通过集中的调度系统就可以实现按比例调度的功能。用户发过来的所有请求,首先要在我们这边进行调度,但是本身并不产生直接下载带宽,而是通过相关算法,按比例和区域调度给第三方的CDN厂商,然后玩家实际是由第三方CDN厂商节点去下载客户端的。
第二套是Dorado系统。刚刚讲到小运营商或者某些运营商的非法缓存机制会对业务造成影响,那么对于某些关键的文件,如果缓存的是一个旧版本,可能会造成很大的问题。比如我们的区服列表,如果我们服务器端增加了新的区服,在客户端没有显现出来,就导致玩家没有办法进入到新的区服去玩。针对这些问题,我们设计了内部代号为Dorado的系统,因为这些文件本身是比较小的,而且数量也不是特别多,但是需要用HTTPS加密,通过加密规避小运营商的缓存问题。所以我们对于这些关键文件,全部有自有节点,在节点上支持HTTPS加密方法,规避小运营商缓存带来的一些问题。
3.5、自动化服务器端更新系统
我们采用的服务器端更新模式也是一种比较传统的类似于CDN的方式,是由目标服务器通过缓存节点到中央节点下载,由缓存节点缓存控制,这样可以减少网间传输的数据量以及提高效率。我们在设计这套系统的时候,也想过用P2P去做。大家想P2P是很炫,又节省带宽,但是用于生产环境中大文件分发的时候会有几个问题。一是安全控制的问题,很难让这些服务器之间又能传数据又能进行安全端口的保护。二是在P2P里做流量控制或者流量限定也是一个挑战。所以最终我们采用了一个看起来比较简单的架构。
3.6、自动化数据分析系统
说到客户端更新,其实更新的效果如何,玩家到底有没有安装成功或者进入游戏,很多时候我们也很茫然,只能看日志。但是日志里面的很多信息是不完善和不完整的。下载客户端的时候,如果看HTTP的日志的话,里面是206的代码,很难计算出玩家到底完整下载了多少客户端,甚至他有没有下载下来,校验结果是否正确,也很难知道。所以我们最终设计了一个自动化数据分析系统,目标就是分析从用户开始下载到他登录游戏,数据到底是怎样转化的。最理想的一种情况是用户下载客户端以后,就进入了游戏,但这是一个理想情况。很多时候,比如因为网络不好,导致用户最终没有下载成功,或者是因为账号的一些问题,用户最终没有登录到游戏里面去。所以,展现出来的数据就是一个漏斗状。我们的目标就是让最终登录的用户数接近于起初下载客户端的用户数。
我们来看一下系统的架构。首先由玩家这边的下载器或者是安装客户端,游戏客户端里面集成一些SDK,对于任何一个关键点,比如“下载”按钮或者“终止”按钮的数据都上报,当然这里面不会涉及敏感信息。上报以后会有Tomcat集群,集群处理以后会将数据写入MongoDB。
看一下这个游戏在引导过程中有什么问题,左边的这一列它分为三个文件,有一个是3MB,有两个是2G多的文件,其实大家可以想像一下。很多时候玩家看到小的文件就把小的文件直接下载安装了,但是实际上并不完整。这一点也告诉我们,其实很多时候在运营或者是业务方面,在引导方面也是要比较合理才能去规避掉一些问题。
3.7、自动化数据备份系统
我们第一个版本的备份系统,它的设计和实现是比较简单的:不同的机房会有一台FTP服务器,本机房的数据写入FTP服务器,然后写入磁带,但是这样就导致磁带是分散的,没有集中存放的地方;另外,基于FTP的上传会有带宽甚至有延迟的要求。
后来我们设计了一个集中的备份系统。它主要解决了以下两个问题。
第一是简化配置。我们所有机房的全部配置,用一个负载均衡器的IP就可以了,当客户端需要上传文件时,通过负载均衡器获取实际上传的地址,然后上传文件,由左边第二个框里面的服务器进行接收,并且根据MD5值进行校验,如果校验没有问题,就转到Hadoop的HDFS集群里面去。目前这个集群有数十PB的规模,每天上传量有几个TB。
第二是提高传输效率和成功率。大家会想一个问题,在中国,网络环境十分复杂,运营商之间存在隔阂甚至是壁垒,导致网络不稳定,丢包和延迟的问题是怎样解决的呢?如果基于TCP传输大文件,理论上存在单个连接上带宽延时积的限制。这里我们创新的是,客户端的上传采用UDP协议,UDP本身没有任何控制,说白了就是客户端可以任意、使劲地发文件。最终会由服务器端检查你收到了哪些文件片段,然后通知客户端补传一些没上传的片段就可以了。基于这种方式能规避很多因为网络抖动或网络延迟比较大而导致的问题。当然,在客户端做流量控制也是可以的。在遇到问题的时候多想想,或许能找到不走寻常路的解决方案。
3.8、自动化监控报警系统
再看一下游戏的自动化监控报警系统(如下图所示)。游戏的架构中有游戏客户端、服务器端、网络链路,所以必须要有比较完整的体系进行全方位、立体式的监控,才能保证在业务发生问题之前进行预警,或者在发生问题时报警。
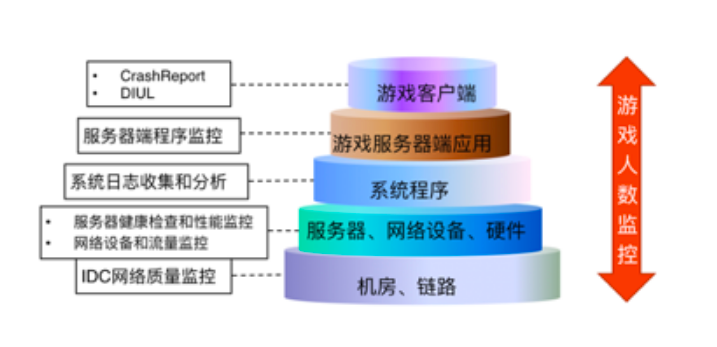
对于机房链路,有IDC(Internet Data Center)的网络质量监控;在服务器、网络设备和硬件方面,我们会做服务器的健康检查、性能监控,以及网络设备和流量监控;在系统程序方面,我们会收集和分析系统日志;在游戏服务器端应用方面,有服务器端的程序监控;在客户端方面,我们会收集植入的SDK做下载更新后的效果,以及收集崩溃的数据。
作为运维人员,我们考虑问题或者设计架构的时候,视角不能仅局限于一个技术方面,或者选用多炫酷、多么牛的技术,要想想技术在业务方面的架构,或者能否通过业务指标监控我们的运维能力与运维系统。在游戏里,有一个很重要的指标就是在线人数,通过监控在线人数这个业务指标,就可以知道系统是否工作正常,是不是有漏报、误报的情况,因为很多时候任何一个环节出了问题,最终都会体现在业务上,在产生价值的数据上。所以我们有一套监控在线人数的系统,每个游戏上线之前会接入这个系统,把在线的人数实时汇集到系统里面。如果发生异常的抖动,系统中都会有所显示,也就可以知道是否发生了问题。
以上讲的是一个框架,下面我们看一下细节,怎样做服务器的监控。首先由运维工程师在监控策略平台配置监控策略,监控策略平台会将这些数据格式化成相关格式,然后推送给自动化运维平台。自动化运维平台会判断是这些数据是外部来的,还是远程检测到的;是网络模拟的,还是本地的监控得到的。比如流量、本地进程的监控、本地日志的监控,会分别推给远程探测服务器,或者游戏服务器本身,然后由它们上报数据。数据上报以后,根据运维工程师配置的阈值,会触发相关的报警,然后通知运维工程师进行相关处理。因为虽然游戏多种多样,操作系统五花八门,但是总有一些大家可以公用的东西,比如监控的模板或者监控的策略,我们对服务器的东西也进行了整合汇总。大家可以看到我们里面有很丰富的插件,运维人员只要选择相关的插件,配一下阈值和周期,就可以节省时间和学习成本,提高配置策略的效率。当配置策略完成以后,直接绑定到想要监控的服务器上就可以了。
总结
我们从2000年初到现在一直在做自动化运维体系,对过去进行总结,我觉得有3个方面可以供大家参考。
第一是循序渐进的原则,特别是中小公司或者初创公司,很多时候并不需要一个“高大上”的系统。聚焦当前的问题,把当前的问题处理好,后面的问题也就迎刃而解。如果一开始设计的系统很庞大、功能特别丰富,会导致一些无法控制的局面。比如这个系统可能最后做不下去了,或者因为耦合性太强,开发控制不了了,或者项目因为经费问题搁浅了。但是如果一开始的目标是解决一些特定的问题,有针对性,那么推进起来也会比较简单。在我司的自动化运维体系建设过程中,我们首先构建的是一个基础的服务器批量操作平台,先把一部分需要重复执行的工作搬到平台上来,再依据运维的需求丰富这个操作平台的功能和提升效率,最后把周边的系统打通,相互对接,形成完整的自动化运维体系。
第二是考虑可扩展性。设计系统的时候,功能或者设计方面可能不用考虑那么多,但是要考虑当服务器数量发生比较大的扩张时,系统是否还能支撑,比如数量级从十到百,或者上千了,这个系统是否还是可用的。
第三是以实用为目的。这在我们系统中也是有体现的。很多情况下,市面上可能已经有比较成熟的协议和工具,拿来评估看看它们在生产环境里面是否可用,如果能用就直接用,没必要自己再去做一套。自己做的这一套工具,很多方面没有经过验证,可能会带来安全问题。基于成熟的协议和框架去做,可以提升效率,保证稳定性和安全性。在“自动化运维平台”一节可以看到,我们并没有自己从头开始研发一套Agent植入到被管理的服务器上,而是用了开源的SSH协议和成熟的OpenSSH软件。这体现了优先考虑开源方案加一部分二次开发而不是重复造轮子的思想。
