@gaoxiaoyunwei2017
2018-05-29T09:57:30.000000Z
字数 5429
阅读 1460
阿里巴巴实时计算平台运维架构演进——杨乾坤
黄晓轩
讲师 | 杨乾坤
编辑 | 黄晓轩
讲师简介
杨乾坤
2012年加入阿里,先后在阿里巴巴技术保障部、技术架构、搜索事业部任职,现任职于阿里巴巴计算平台事业部,主要负责大数据相关的运维和运维平台的开发。
前言
我今天分享的主题是《阿里巴巴实时计算平台运维架构演进》。一共分四个部分:
- 实时计算平台的运维挑战
- 统一的运维自动化平台
- 主动出击,消除隐患
- 走向智能化
实时计算平台的运维挑战

大家知道最近两年随着AlphaGo的兴起,算法成为各个公司,如阿里巴巴、腾讯重金投入的场景。实时计算平台包括实时计算、流计算,它在搜索、推荐、广告、监控方面,对于实时的反馈效果的提升有非常大的帮助。实时计算最近两年火起来,其面临着与在线服务和离线计算不一样的一些挑战。
在去年双十一时,阿里的实时计算平台服务了20多个BU、有1K多的 Job、近万台机器,其计算峰值达到了4.72亿QPS,大家在双十一当天看到的阿里巴巴对外提供不断滚动的大屏,其计算峰值达到1.8亿QPS。
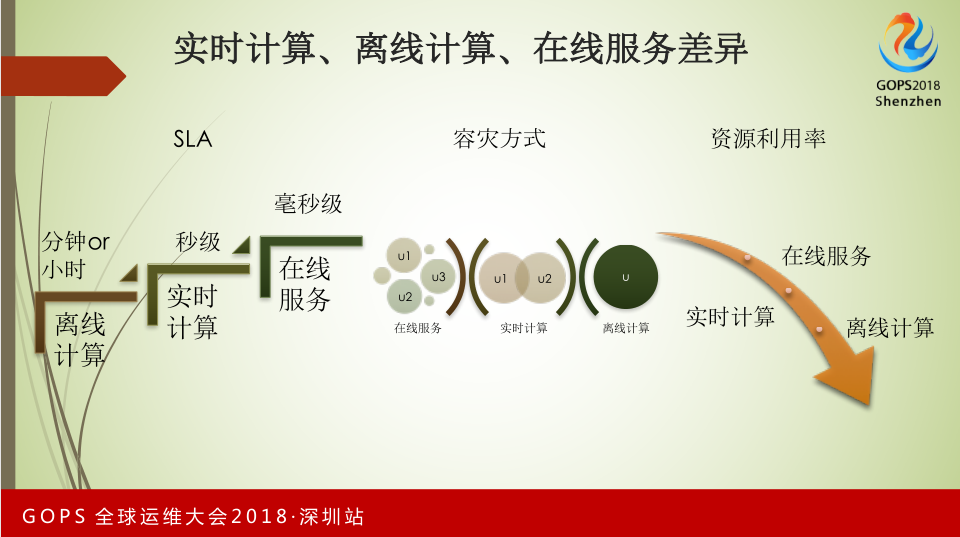
关于实时计算、离线计算和在线服务的差异。离线计算对SLA的要求不高,分钟甚至小时的延时都是可以接受的。实时计算就要求必须达到秒级,不得出现一分钟卡顿的情况。大家比较熟悉的在线服务必须是毫秒级或者微秒级的要求。
针对不同的情况,容灾方式也不一样。在线服务需要有异地双备或者多地单元化部署,保证能随时互切。对于实时计算,它只会针对个别核心业务做双备,大部分业务只有一个运行实例。
离线计算几乎没有双备。针对这种容灾方式造成资源利用率的不不同。在线服务要保障随时互切,资源利用率比如CPU不能超过40%。实时计算和离线计算对资源利用率有更高的要求,必须达到70-80%以上,甚至达到90%以上。
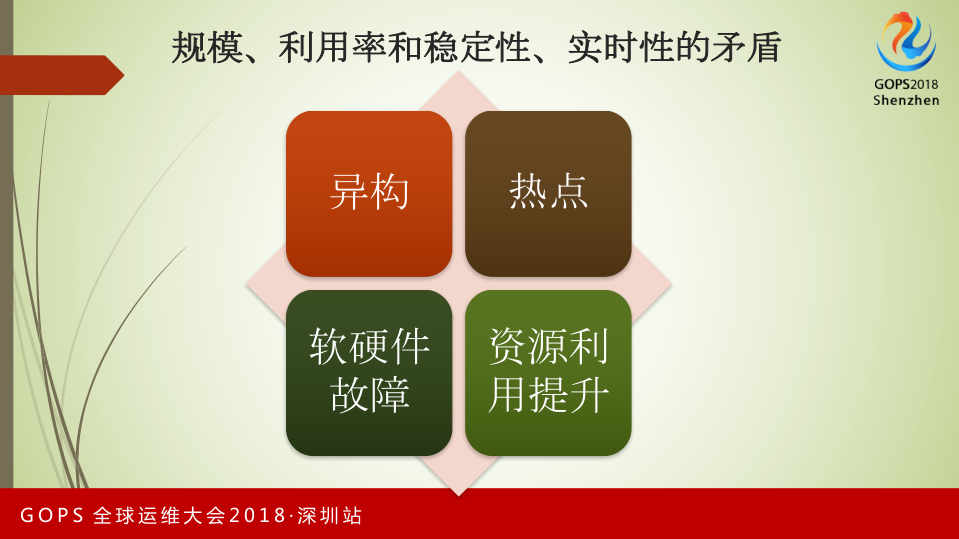
现在实时计算面临几个挑战:
- 第一,集群异构情况。我们的机器每年在更新换代,今年的机器和去年的机器相比,CPU和内存的提升,会导致集群机型的异构;
- 第二,热点的情况。在离线计算的挑战不大,可以接受一个小时或者几分钟的延时。对于实时计算来说,一旦出现热点,必须能够马上进行实时自动化处理,否则会影响整个服务;
- 第三,软硬件故障导致服务的可用性;
- 第四,资源利用率的提升对于稳定性的挑战非常大。实时计算和离线计算对于资源利用率的要求几乎一致,要达到80-90%的利用率。
统一的运维自动化平台

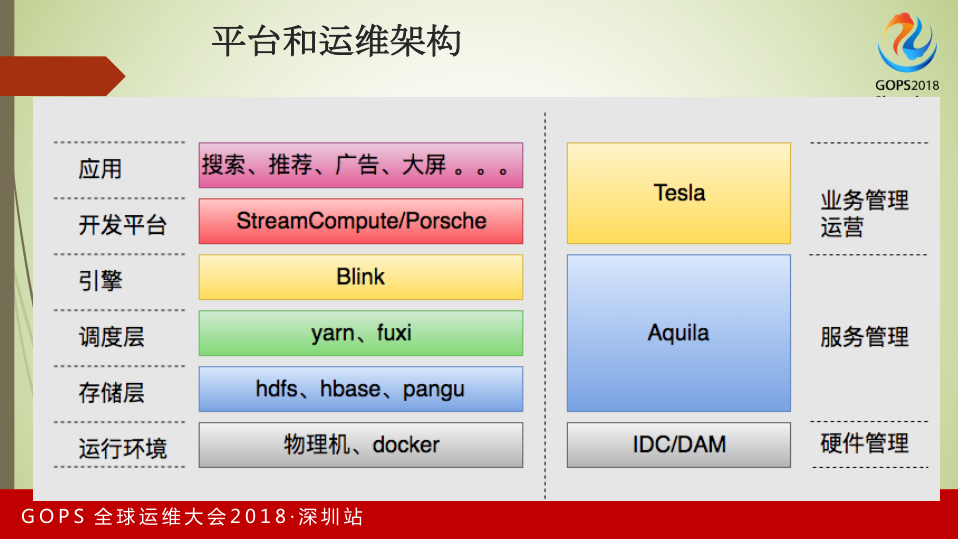
这是阿里巴巴实时计算的平台和运维架构的情况。
最下层是运行环境的管理,我们主要通过阿里自研的IDC系统以及大数据平台自己做的代码系统,做物理机和Docker的硬件管理,包括硬件的运行。
往上一层对应存储层、调度层、引擎。我们的存储主要有HDFS、HBase、Pangu。在调度层主要是Yarn和我们自研的Fuxi。在引擎层是阿里巴巴基于开源的Blink打造的引擎。
在运行层的管理,我们通过Aquila做了管理。Aquila是我们基于社区开源【英文没听清】做的企业版服务。之所以叫Aquila,因为类似像Hadoop、HBase等,是以动物的形象展现给大家。Aquila是我们在网上搜索到的非洲野生动物园,我们想通过Aquila把类似Hadoop、Blink的生态系统,将其全部管理起来。
阿里巴巴的开发平台目前主要是StreamCompute和Porsche。StreamCompute已经在阿里云公开对外输出,如果大家对实时计算感兴趣,可以到阿里云的官网做试用或者采购。
最上面一层实时计算支撑整个阿里的业务,包括搜索、推荐、广告、大屏。整个的开发和应用层是通过阿里计算平台事业部开发的Tesla系统做业务的管理和运营。以上是目前阿里实时计算的平台架构和运维体系。

DAM主要做的包括四部分:
- 硬件检查。
- 故障预测。我们依赖很多底层算法及大数据相关的技术。
- 故障修复。机器自动化故障处理,自动化的提交报修单,囊括提报修单、现场维修、重新交付。
- 硬件运营。对于底层硬件运营情况的展示,包括资源利用率、机器上线情况,同时另一部分的工作是做多种机型故障率、维修时长等运营工作,可以帮助我们发现每种机型或者同机型不同厂商之间的硬件故障率,对我们后续硬件的采购产生影响。

Aquila,目标是把Aquila从工具到产品的升级。我们需要提供对运维自动化有帮助的能力,包括以下几点:
- 运维操作百屏化;
- 服务统一的运维规范和模式;
- 可持续集成能力;
- 对自动化操作的支持能力。它能提供完整的API供外部接口做调用,支持自动化的操作。

Aquila:概念和功能需求的划分分为以下几点:
- 第一,Stack管理。一组特定版本的服务集合,它本身有版本的概念,比如1.0-1.1中间的差异可以是其中某一个Service版本的变化或者多个Service版本的变化,通过Stack管理来做整个集群的升级管理。
- 第二,配置管理。我们面对的是集群管理异构的情况,所以它必须支持机器配置分组管理。配置代码化,通过Git管理,有版本概念,支持Review和回滚。
- 第三,自动化方案。一是要支持完善的API,能够做自动化的扩容,机器从故障预测、下线、机器修复和重新上线的自动化流程;二是支持服务的自动拉起和维持,现在集群会出现一些异常,它要保证随时把停掉的进程拉起来。
- 第四,是通用接口。
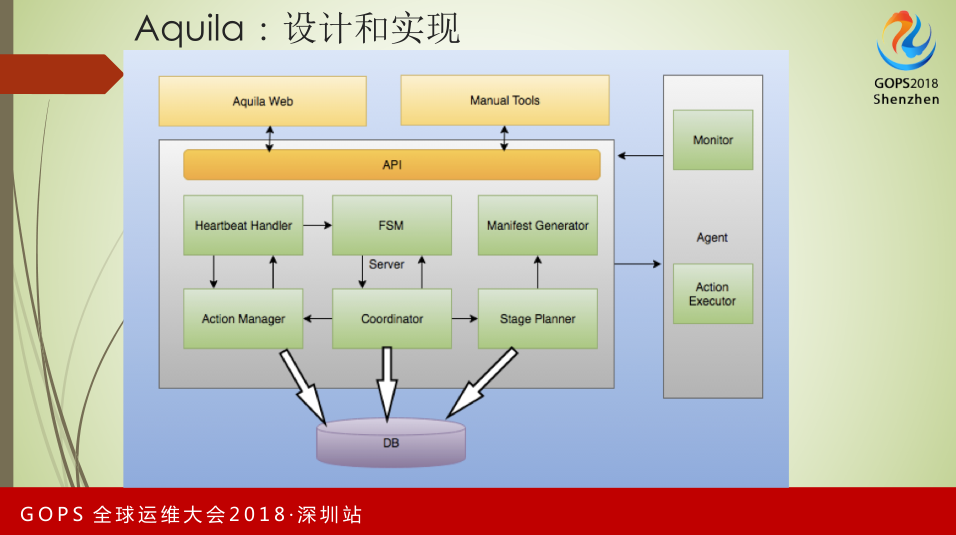
Aquila设计和实现。其底层依赖DB,Server层包括几部分,一是Heartbeat Handler,它负责和Agent通信;FSM是状态机的管理。在Aquila里,各种服务的管理是通过状态机进行的。Action Manager、Coordinator、Stage Pianner负责从请求到生成对应的操作流程。 Agent和Server通信方式是由Agent主动发起,Server端的命令下发、监控是通过Heartbeat respond方式完成,包括Agent监控的信息、动作执行情况,全部以主动向Server汇报的方式进行。

相比于开源社区,Aquila提供以下优势:
- 服务更稳定
- 支持Server的HA架构,保障server的高可用。开源社区【英文】是单点服务,包括DB、Server。我们在此之上做了一个改造,就是HA的架构。保证我在一个Server挂掉的情况下,不影响整个集群的操作。
- DB采用阿里云数据库,能够保证数据的安全性。
- 增加配置Review流程。该流程可以保证我们的配置经过对应的开发、QA,做Review后的配置,才能分发到整个集群里。
- Bugfix达到100+。
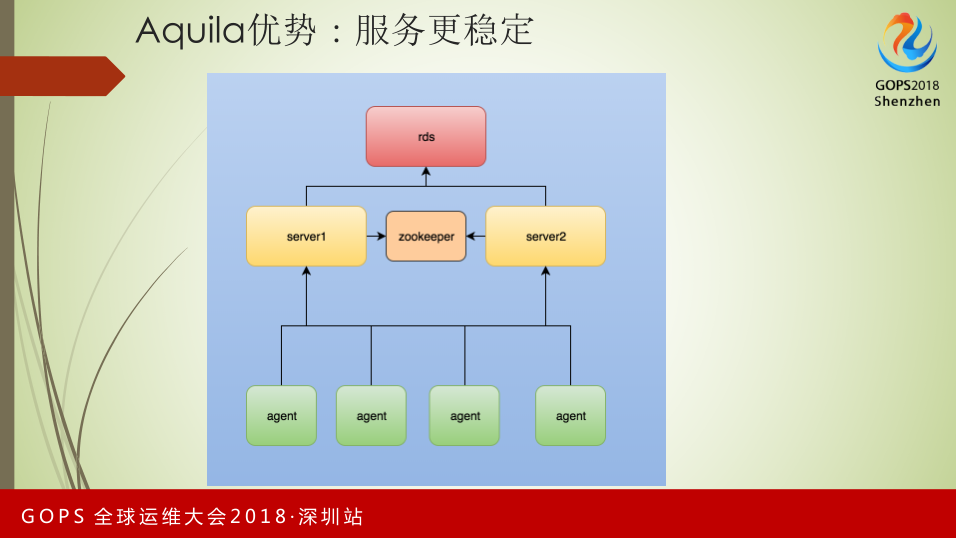
这是我们改造后HA的情况。我们的后台是RDS,RDS可以在出现故障的情况下做无缝迁移。在Server端,我们支持两个Server,这两个Server通过Zookeeper保证一致性,保证只有一台Server在运行状态,另一台准备状态。Agent的通信类似Hadoop的工作方式,当它向其中一台Server发起通信受阻情况下,它会主动去另一台做重试。通过这样的方式来保障Aquila的高可用。
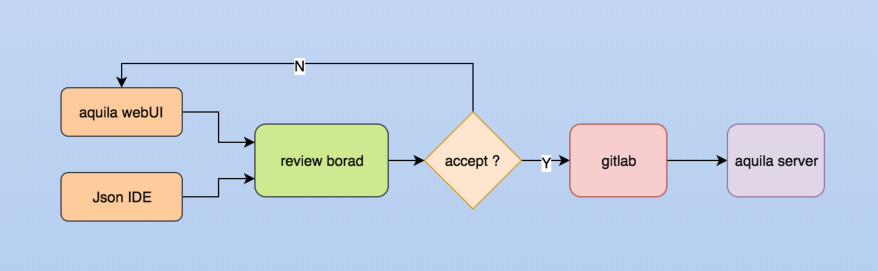
这是改造后的配置管理情况。我们通过Aquila WebUI或Json IDE发起配置变更,我们的配置保存在Git上。不管你是通过Aquila WebUI还是Json IDE,都会生成Review Borad。这个Review是通过Facebook提供的开源工具来做,它已经集成到阿里的系统上。生成Review后,我们可以通过对应的开发和QA Review后,才可能进到Git。只有进入Git才有可能被Aquila Server接受,下发到计算平台的集群里。大家看到的不是特别大或者特别复杂的改造,这对于生产环境来说,是一个非常重要,而且是必须要做的事情。
【图:Aquila优势:管理更高效--文字部分】
- Aquila优势:管理更高效。
我们做了很多管理上的改造,让整个集群的管理变得更高效。
- Stack的管理。我们对Stack依赖管理重新设计,整体更加简洁。我们原来会做得【英文】非常复杂,1.0有一个基础,1.1某一个服务做了改动,其他的都会改为对1.0的依赖。这对于整个服务管理非常复杂,我们要对其中一个服务做操作上的改动,所有的Stack1.0、1.1要重新升级。改造后,Stack1.1-1.0的依赖类似拷贝的过程,从1.0-1.1做升级,对应做版本变更、操作变更,使整个依赖变得更加简洁,对于我们的操作更加友好。
- 比较大的改动是我们的集群管理,支持多集群管理功能。Aquila Server的部署是一个比较复杂的过程,包括它的依赖情况。我们在此情况下做了多集群管理功能,一台Aquila可以管理整个生产的多个集群。
- 我们增加配置导入导出的流程,方便我们做新集群部署,我们所有已经Review好的配置可以从GitLab上直接导入集群,做配置的复用,直接配置新集群。
- 支持机器自动注册和服务自动部署,支持Docker服务自动部署。这是针对阿里现在的大环境做的,阿里在做统一调度系统,阿里所有的业务都要进容器。我们如何做服务扩容,我们要向一层调度,申请一部分资源。它反馈给我们的是Docker容器。我们做自动注册服务,Docker只要把Aquila拉起来,我可以通过Server中的配置自动把服务拉起。
- 流程优化达到30+,包括部署向导、Batch升级、Rack信息导入等。
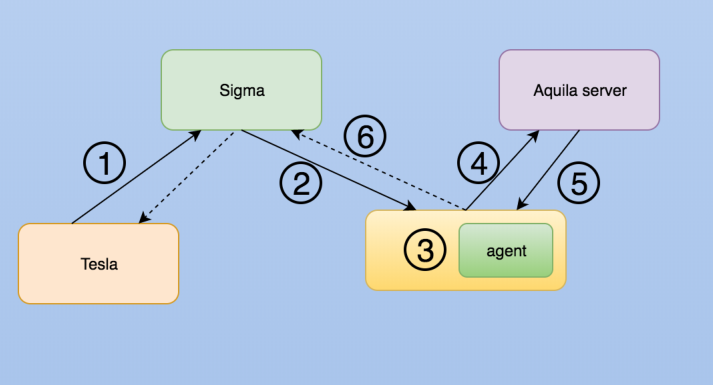
这是服务自动注册和拉起的情况。Tesla是我们的大数据业务运营管理平台,它可以探测我们集群的水位情况,水位是否超过我们预定的80%,如果超过,我们可以主动向阿里资源管理一层调度平台Sigma做资源申请。申请下发后,如果Sigma可以满足我们的资源申请,它会主动把容器拉起来交给我们。我们拉起时做了一个动作,把对应的Aquila Agent拉起来。拉起来后,Aquila agent会自动向Server做汇报,完成汇报后,Aquila Server可以根据自己在服务端的配置,比如针对Docker需要部署的服务有哪些,它属于哪些配置分组。在这种情况下,Aquila Server会下发部署和配置更新的命令,把Agent和容器内的服务部署好后,向Sigma返回,Sigma知晓情况后,会向运营管理平台做最后的确认。完成从水位检测到资源扩容的整个自动化流程。

- Aquila的优势:服务接入更开放。
- Stack和Server做打包分离,加快Stack的迭代,让服务接入更方便。
- 我们对Service的Meta文件进行拆分,将版本信息、操作信息、依赖信息分离,Stack升级更加灵活。如果我们要对服务做操作方面的改造或者升级,它不需要专门做Stack的升级便能完成。
- 我们支持更灵活的安装方式和源,如Rpm、Tar、Git、Oss等。

- Aquila优势:性能更高。
我们在性能方面做了很多的改造,目前从Aquila社区看到,单集群支持2500+机器。现在我们通过对数据库表结构的优化及Host管理优化,单集群可以支持5000+机器和单Server支持50+集群。其他性能优化20+,包括锁优化、事件管理优化及前端框架的优化。从整个平台看来,有了Aquila后,我们可以依赖这个产品做很多自动化的工作。

这是Tesla在业务运营层面的,统一的大数据运营平台,包括业务中心、平台运营和工具服务。
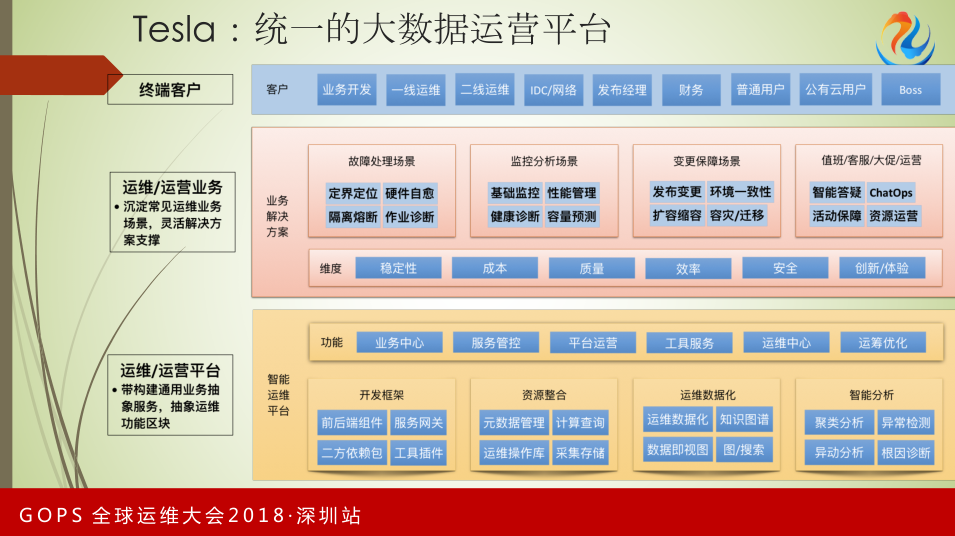
运维运营平台提供分站开发框架、资源整合相关管理、运维数据化的支撑、智能分析工具,它的功能涵盖业务中心、服务管控、平台运营、工具服务、运营中心和运筹优化。
从运维/运营业务场景来看,它提供故障处理场景、监控分析场景、变更保障场景和值班、大促的场景。Tesla面向的客户包括业务开发、一线运维、IDC、财务,它涵盖资源账单情况。
主动出击,消除隐患

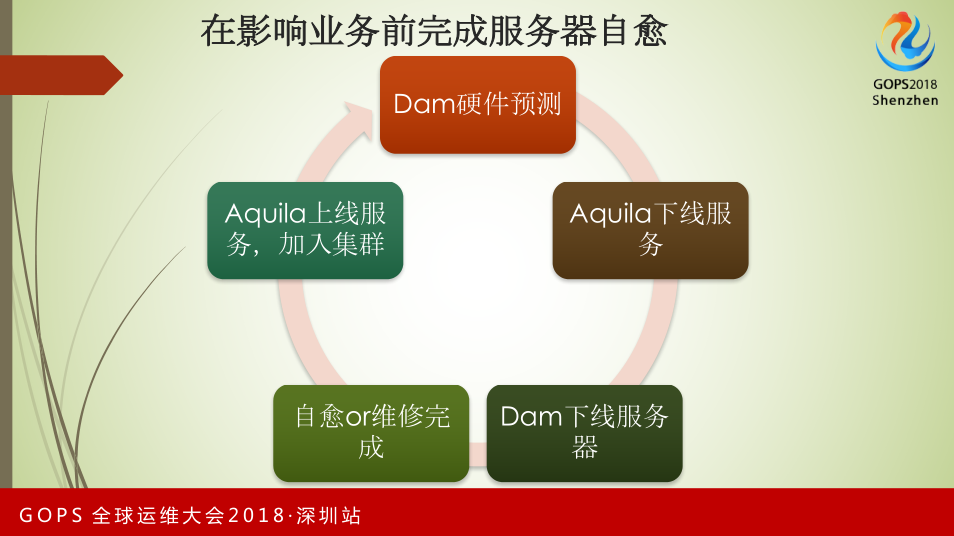
这是我们在此平台上做的自动化保障。对于实时计算平台来说,机器出现故障,影响业务后再进行处理有比较大的风险。我们通过引入DAM做硬件预测,在预测到故障时,主动通过Aquila完成服务的下线,把机器交还给DAM,做硬件自愈,自愈完成后重新加入到集群中,形成一个完整的闭环。现在在运营工作中,我们不再需要主动做硬件故障管理的工作。
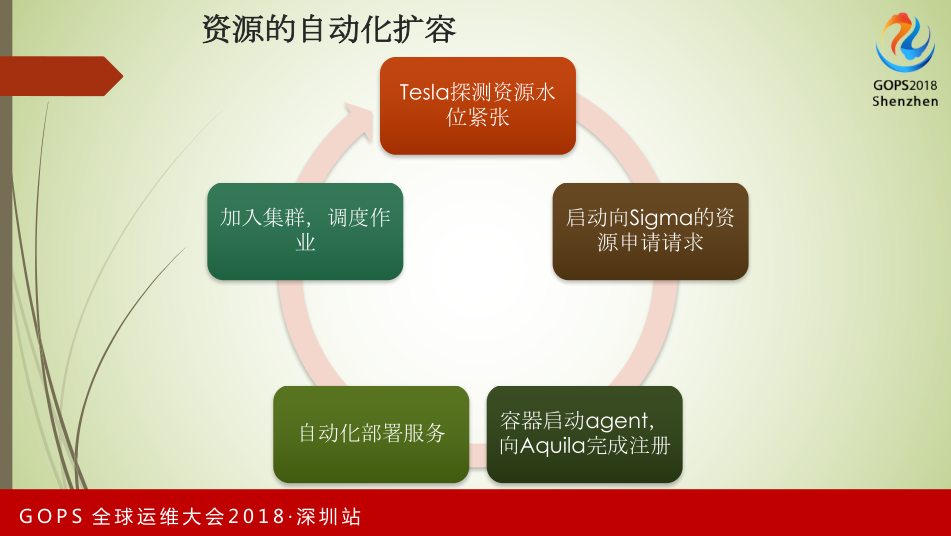
资源自动化扩容,Tesla探测资源水位,在水位紧张的情况下启动向Sigma的资源申请。通过容器做自动注册,完成服务部署,最后加入集群,进行调度作业。
走向智能化

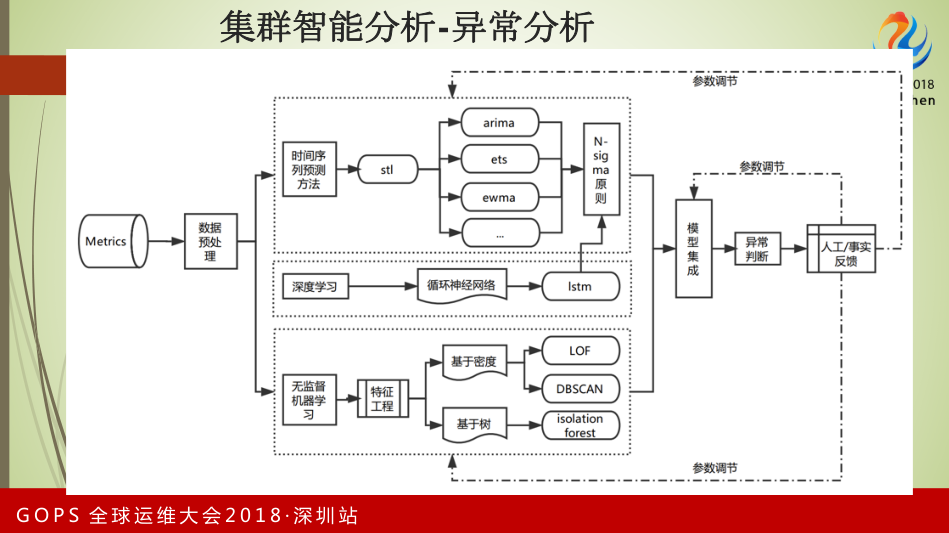
我们现在在做智能化的探索,实时计算对故障的要求比较敏感,我们在做异常分析。可以看到Metrics是时间序列的数据,像ETS、EWMA做预测,通过Sigma做模型的生成。在模型生成中有参数是通过深度学习的方法,不停的做校验。
下面是无监督机器学习的过程,包括特征工程、基于密度和树做LOF、DBSCAN,通过异常报警和人工反馈情况调整参数。
【图:热点机器分析】
具体场景是机器热点分析,我们通过Metrics的采集,做密度聚类,最后生成三个结果,一是PCA降维后的分组图,它会归类哪些机器可以归到一个分组,另外的是不太正常的状态;二是数据化的归一,哪些分组的指标不一样;三是指标明细,哪些分组发生哪些数据。
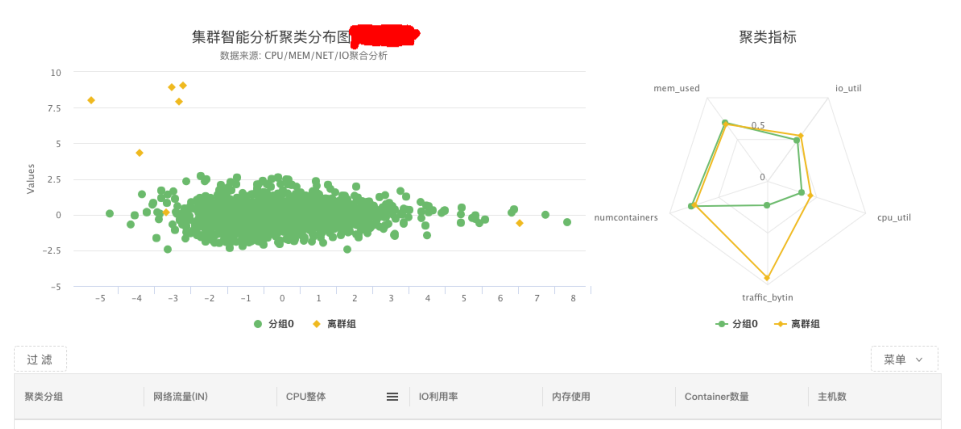
这种情况对我们的应用场景,在集群异构的情况下,由于配置的原因,我们难以发现机器积累的问题。比如一台64核256G的机器,我在配置资源时出现配置错误,如配了10核128G。我们通过传统的监控不太容易发现其问题。传统监控,我们会配置这台机器的CPU超过多少,再做报警。这不太适用我刚才所说的,我们可以通过聚类的分析,发现离群组的情况,它是因为CPU使用过低而被分在不太正常的组里,我们可以根据分析发现问题。以上是我的分享,谢谢大家!
