@gaoxiaoyunwei2017
2017-12-19T07:18:51.000000Z
字数 6062
阅读 1628
Spectrum-去哪儿网基于 Kubernetes/Ceph 的机器学习云实践-叶璐
黄晓轩
讲师 | 叶璐
编辑 | 黄晓轩
讲师简介
叶璐
去哪儿运维开发工程师
GOPS的金牌讲师
前言
我今天分享的题目是Spectrum,这是去哪儿网内部的机器学习云。整个分享分为了四部分内容,深度学习的兴起、深度学习在去哪儿网的应用和GPU云化解决方案以及最后我会简单show一下GPU怎么用。
一 深度学习的兴起
大家对深度学习最直接的印象就是今年5月在乌镇世界互联网大会上柯洁被AlphaGo打败。当时他落泪说它太完美了,找不到打败它的方法。最近又有一个消息,AlphaGo的公司DeepMind研发出了AlphaGo Zero,在没有任何人类输入的条件下,打败了它的上一代AlphaGo。

杰米斯·哈萨比斯(Demis Hassabis),他是DeepMind公司的创始人,也是AlphaGo之父。
- 什么是深度学习
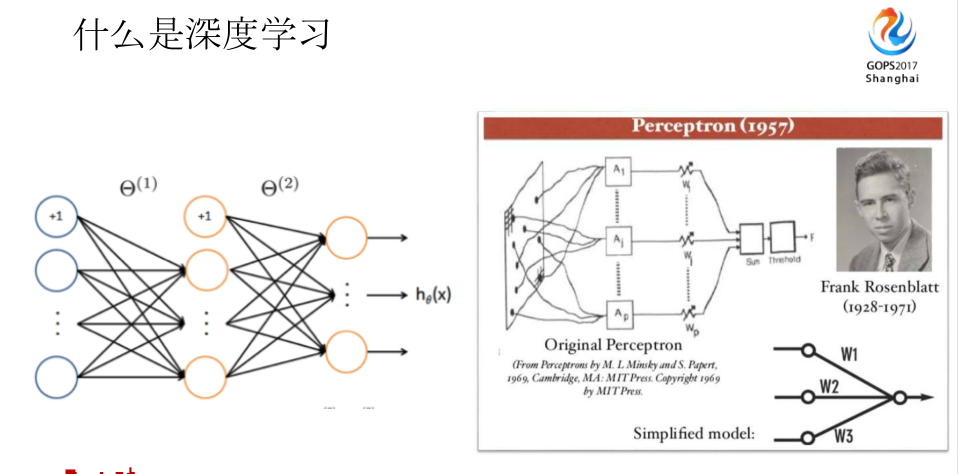
深度学习已经不是非常新的概念了,这是Frank Rosenblatt,他在1957年发布了算法模型,这相当于是深度学习的雏形,类似于两层的神经网络。在当时,大家对于这种方式,或者这种逻辑、设计接受度不高,导致他的学术生涯、论文等等,结果都不是非常好,但他奠定了深度学习的雏形,也就是两层的神经网络。

这是Geoffrey Hinton,被尊称为“神经网络之父”,右边的是Yann LeCun。这两个人是在06年的时候正式提出了深度学习的概念,至于为什么会从上世纪60年代提出这个雏形的概念,到06年才正式把深度学习的概念提出来呢?其实中间有很多的原因。
- 深度学习的发展
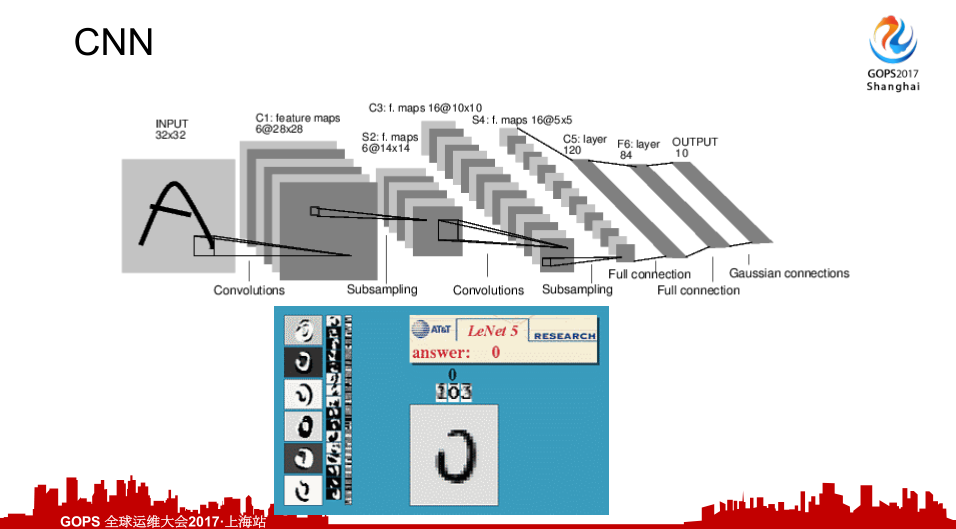
先看一个简单的CNN应用,第一期最成功的应用就是LeNet。当时做的是非常普遍的应用——手写识别。主要应用的模型算法就是CNN,LeNet当时也是两层的神经网络,也是第一例成功的案例,当时主要用于邮政编码、门牌号等等的识别。大家可以看到上面CNN的过程,通过一层层的卷积,到卷积池,再到全连接到最后的输出层。

这是Watson,这两位竞技到最后,Watson机器人在类似于智慧问答的比赛上,打败了以前的擂主,拿到了奖金,这些是机器学习的应用。

到现在Google的无人驾驶是2014年,这是第一辆无人驾驶上路的新闻。
现在国内外几乎所有的科技巨头都在谈论深度学习、机器学习的概念,也有非常多的人才抢夺的事情,大家可以看到李菲菲等等,各大公司也推出了相关开源的机器学习的平台,包括Facebook、Google,还有国内的百度都推出了自己的机器学习的开源平台。
- 兴起的原因
为什么从上世纪60年代到现在,到这两年我觉得才是真正非常火的时候,这是为什么?

- 以前数据量是非常少的。大家也知道深度学习我们需要非常大的数据量作为输入源。大数据的技术慢慢成熟,数据量的提升我觉得是机器学习兴起的主要原因,以前我们数据匮乏,找不到数据去做训练。
- 我们现在的GPU或者说TPU等等计算资源成本的降低。上世纪60年代那时候计算机还不是一个普及的东西,到现在GPU或者说TPU这些计算资源的成本相对以前来说大大降低。
- 对于热度提升最直接的原因,就是开源工具的普及,如果以前大家写一个CNN或者刚刚非常简单的数学识别的应用,你不知道自己要写多少代码,现在如果你要写一个手写识别,只需要一百多行代码。
这三点是最主要的原因。
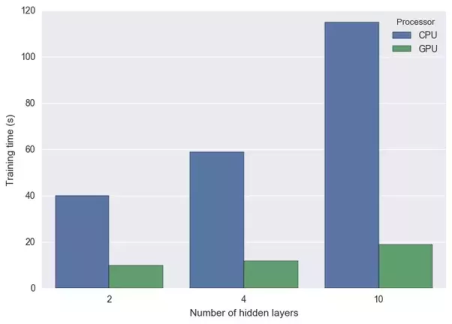
这是我当时做的测试数据,就是GPU和CPU在当时,我设置的是两层、四层和十层隐层所需要的计算时间。CPU和GPU的时间相差是非常多,在增加卷积层的时候。
二 深度学习在Qunar的应用
• 机票验证码识别等
• 看图写诗-小诗机
• 智能客服
• 拿去花用户信用评级
• 根据历史访问记录推荐酒店
• 计算不同酒店房型的价格系数
以上这些或多或少都用到了机器学习。
下面我介绍一下Qunar在做深度学习训练的时候遇到的问题:
第一,多个team的共享GPU资源。我们有多个团队共享GPU资源,其中最大的问题是他不知道这上面跑的应用是谁的,看到这个应用一直在跑,可能跑了好几天了,等的不耐烦了,上去就给kill掉了。别人可能跑了三天了,我碰到最久的是七天的任务,被kill掉了,然后跑的数据就没有用了。
第二,采购周期长。采购周期长就是你要评你这个季度的计划和预算,要说这个东西干什么用的,为什么用这么多GPU,采购周期长,有的同学可能说我就是想试一下这个想法,可能要等一个月,这个想法也就不想玩了。搞机器学习的人我觉得都是非常有活力的人,拿这样流程的东西压他,我觉得是非常残忍的。
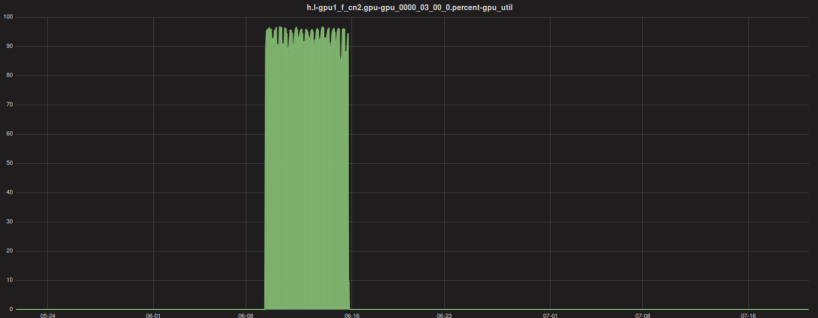
第三,资源利用率低。这是截取的资源利用率图,可以看到某一段时间内资源利用率非常高,其他的时间都是闲置的,以前的方式都是人工调度这些计算资源。

下面介绍一下GPU资源使用的问题。
第一,环境无隔离。这不仅仅包含别人把我的任务删了或者怎么样的,还有就是很多东西发展比较快,大家用的TensorFlow版本差异也非常大,可能别人给升级了,你的程序第二次跑的时候不能跑了,上去检查依赖,发现我的依赖被人污染了,可能有的人就直接装在系统里了。等等很多的问题,我们之前遇到过很多这样的问题。
第二,采购周期长。
第三,资源利用率低。
第四,环境部署成本高。你的环境部署,一个工程师上来,如果说他的东西,整个的技术栈被搞乱的话,就要重新搞一套自己的工作环境。成本比较高,他也不想一遍一遍重复做这样的工作。
我们该怎么办呢?那我们给自己定了两个宗旨。
- 降低资源使用门槛。只需要点两个按钮就可以拿到资源,很方便的用自己以前熟悉的方式使用这个资源。
- 提高资源使用率。这是互联网公司不得不考虑的一点,我们不能买到东西就一直闲置,我们要省钱,要把所有的东西利用率最大化。

依据这两个宗旨,我们定下了GPU云第一期的目标。
- GPU资源云化,支持业务线同学快捷新建机器学习应用,并且秒建秒删,可以一键释放GPU资源,而且能保证在释放资源时包括训练数据等等的所有数据都不会丢失。
- 统一入口。这是跟我们系统相关,大家知道所有的东西都有权限控制跟应用关联,跟企业内部的管理系统,这些东西对接到我们Portal,降低使用者的学习成本,他在介入学习的时候,他要怎么介入这个应用,比如说我怎么分享给我同组的同学用,这块我们Portal内部解决了这个问题。
- 环境隔离。
- 数据持久化。大家知道训练数据非常大,我之前遇到一个同学,我们国内从Google拉数据是非常费劲的事情,他花了很长的时间从Google拉了一堆的数据下来,就是训练的数据,然后那台机子被搞坏了,他的数据也没有了,他也不知道找谁要,那台机子就需要ops手动处理。我们这个平台的目标就是数据持久化和可靠性保证到。
- 支持Tensorflow全工具链。
为什么是Tensorflow?这里可以看一下Tensorflow的社区跟其它的对比。

大家知道一个社区的活跃度对于一个开源项目是非常重要的,如果这个社区非常活跃,非常多的大公司参与。大家可以看到这是参与Tensorflow社区的一些公司,包括推特包括Google。
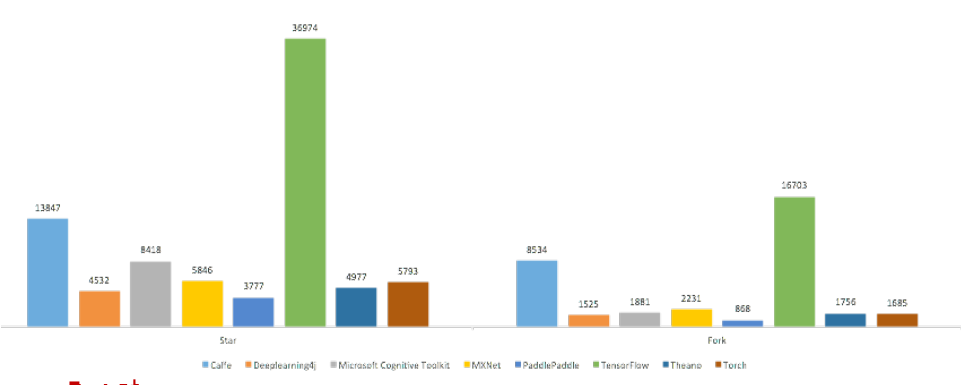
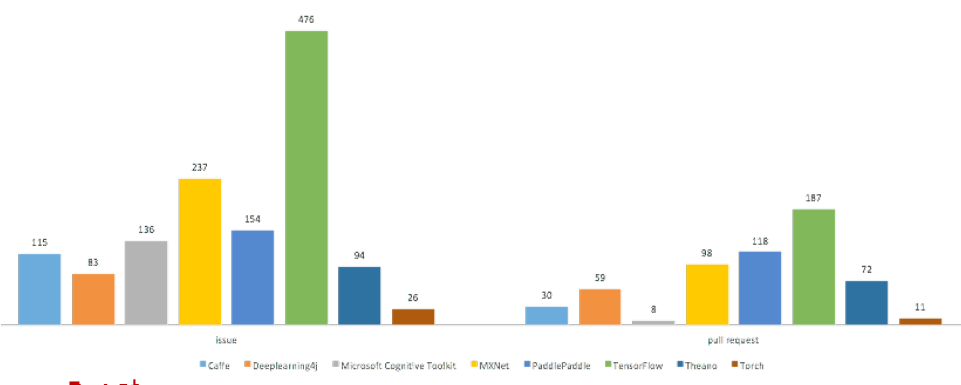
这是从GitHub上拉的社区活跃度数据,可以看到Tensorflow是出类拔萃,几乎能秒杀别的开源工具。

这是我刚刚跟大家提到的,如果你要在Tensorflow上写一个手写识别的应用大概需要什么,需要多长代码,这就是一个整个的代码。Mnist玩过的人可能非常熟悉,因为它是上世纪90年代开始的,类似于数据集,大家可以从上面拉一部分的训练数据,测试自己的程序。发展到现在,它已经不仅仅是手写识别这一块了。作为类似泛化的机器学习模型测试的数据集。上面几行可以看到注释,我这里一共是定义了两个隐层。

这也是我刚刚提到的Tensorflow全工具链里面的Tensorboard。我觉得它是一个非常优秀的工具,它也是机器学习初学者非常喜欢的工具,可以清晰的从图表里面看到你机器学习的模型是什么样的,或者说你训练的流程是什么样的,你需要经过什么样的过程,还可以看到模型效果的展示图。比如说他的下降速度是什么样的,最终的结果是什么样的,都可以非常直观的看出来。
三 GPU云化解决方案
我们当时Qunar内部比较熟悉的是Mesos,我们比较纠结的两点就是Mesos和kubernetes选哪一个。我们比较大型的应用已经选了Mesos,但我们后来选择kubernetes。

为什么是kubernetes?它是最基本的,作为容器编排的工具。而且对于GPU的资源,它有GPU资源感知能力,可以探测出机器上有多少块GPU以及它的型号,它的识别比较早,Mesos当时还没有做相关计算资源拓展这块。还有它对于存储的支持,这块对我们来说非常重要,数据这块对于机器学习来说非常重要,Mesos在我们当时的测试来说,不太支持分布式的存储,可能现在有。我们测试了kubernetes对于S3/RBD等等存储后端支持都非常好,我们主要用的就是S3/RBD这块。还有社区支持。Kubernetes和tensorflow都是来自google的开源项目,一家的支持会好一点。最终选型就是Docker + Kubernetes。
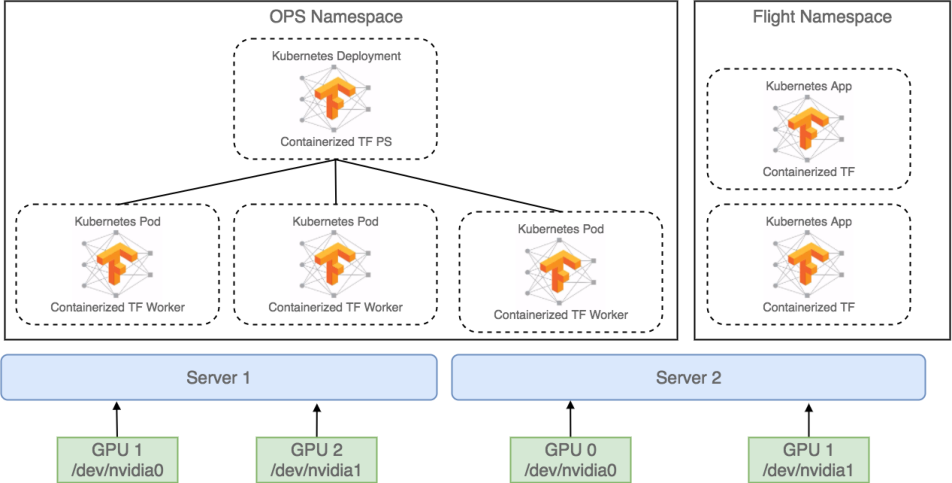
如何完成应用的定制?我们架构这块怎么完成应用的定制的。这是我们简化的图,这是两台服务器,服务器有两块GPU的卡,上面分别跑了两个应用,一个是单机版的Tensorflow,另一个是分布式Tensorflow的应用。这是组织架构图,大家在用PS和work之间肯定要考虑网络这层,这是一个示意图。
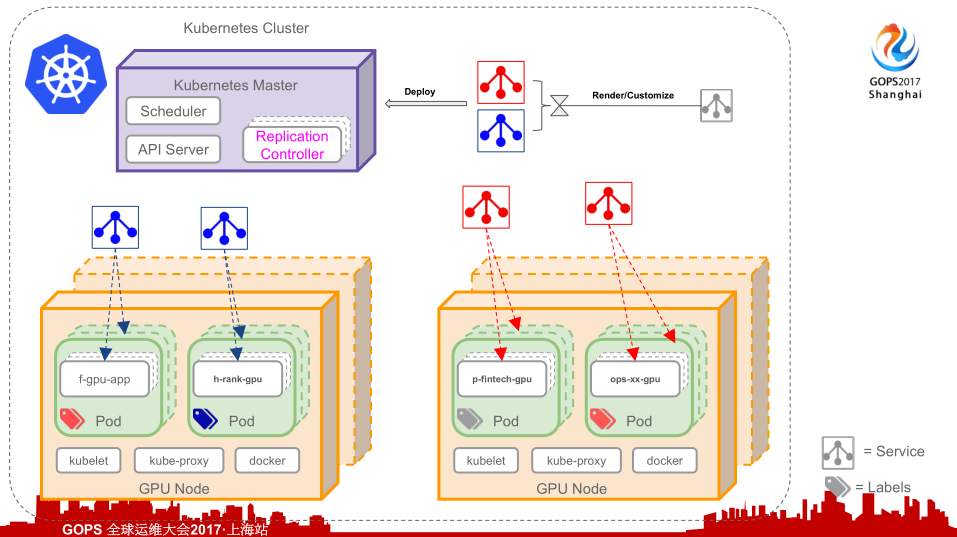
怎么去完成一个应用定制呢?这个图的顺序从右边到左边的,大家可以看到这个应用定义的资源,在平台上按照某个同学应用定制的要求,比如说选择Tensorflow什么版本,副本数量等等,这些会生成Kubernetes能够识别的RC资源定义文件,由Kubernetes Master进行调度,可以看到不同应用调度道不同的主机上,根据这个文件进行应用的自动初始化。
数据存在哪?这也是我们重要的考量,我们是基于 SaaS提供两种接口,RBD和S3。S3我需要解释一下,这并不是指AWS中的S3,我们这边是类似于S3的API,它的接口标准我们都称为S3,类似于企业S3这种,它已经不是一个产品了,已经是OSS的标准了,它提供的对权限的划分等等。在用的过程中,我们提供这两种数据接口的使用方式。RBD是通过容器挂在的方式,让工程师相当于本地操作一样,写到哪个目录,数据就在哪里。S3用来在导初模型的时候可以直接填一个S3的地址。比如说在Google也是类似于S3的接口,AWS也是直接保存到S3。
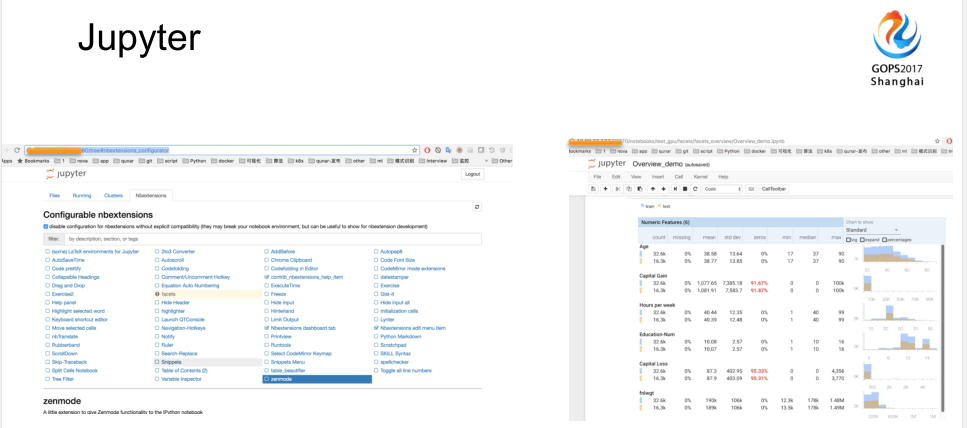
我们选型还有一些细节。我们当时提供给用户的是基于Jupyter,Jupyter能够让算法工程师快速的上手,他们也比较倾向于用Jupyter写自己的代码。这比较方便的一点就是,我们用Portal统一了权限管理这块。当我有一个需要调试的内容,我只需要把这个链接share给他,当是从属于一个应用下的负责人,就可以很快的得到界面并开始代码编写和调试。我觉得Jupyter社区也是比较活跃的,它有非常多的Nbextensions,我们也提供了Nbextensions的管理界面,所有的同学点一点就可以装一个插件,使用非常方便。
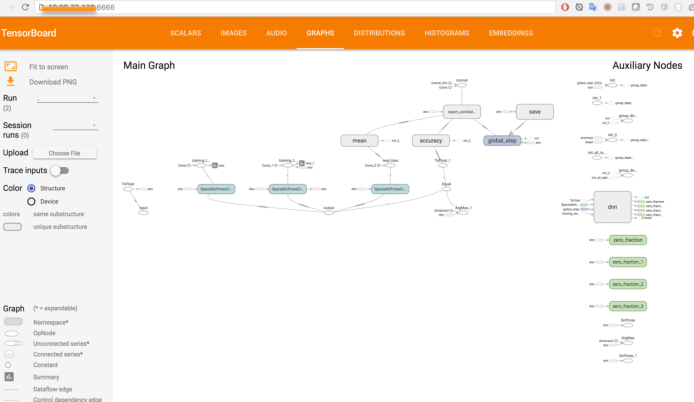
Tensorboard这块也是放到技术学习里面,不过要提到一点Tensorboard不会像Jupyter和Tensorflow那样打包到环境中,Tensorboard我们把权限开放给用户,我们会提供一个terminal,让用户自己去启动。

这是我们最近的进展,这是添加了一些功能。一个是基础环境的固化。很多工程师在用我们初始化环境的时候,可能不是很满意,比如要装很多另外的插件和其他的包什么的,现在可以支持把你基础环境直接固化出来,并提供给你二度使用。比如说这个环境销毁了,希望要一个干净的环境,你可以从post install中讲你固化的环境,重新拉出来使用。我们这里也提供了一个Qunar的高可用Model Registry和Serving,通过一个Serving的地址,把你训练好的模型服务线上。
另外一个是分布式的试用,分布式一直在摸索中,不能说是生产的阶段,我们一直在用,一直在测试,一直在改进。因为这个PS和work之间的数据都需要调优,我暂时放在试用阶段。还有就是计费,比如一个产品真的成熟了以后你的企业可能不会当做一个玩具真正要考虑他的效率,计费这块没有做,所以没有打勾。
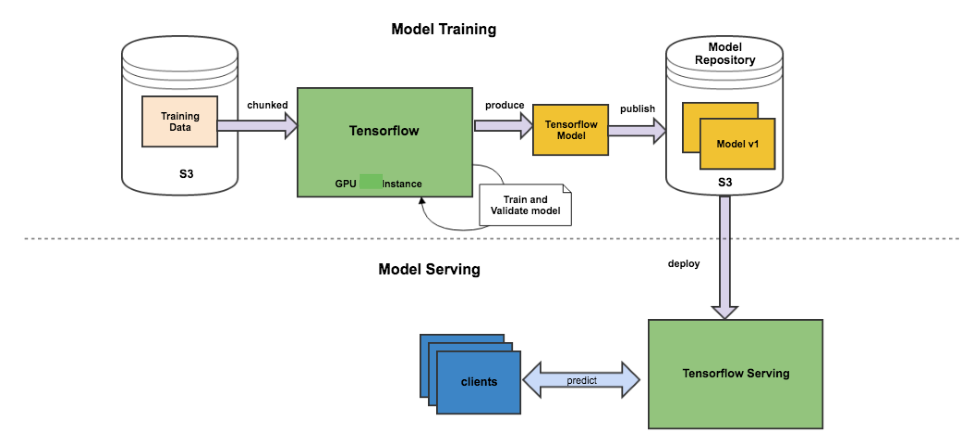
这个是我刚刚提到的Model Training的流程。从左边比如说你的数据也存在S3里面,放在Tensorflow里面进行训练,然后产出,你的产出是一个模型,再到最后我们使用的就是Tensorflow serving的服务。这是一个流程图。
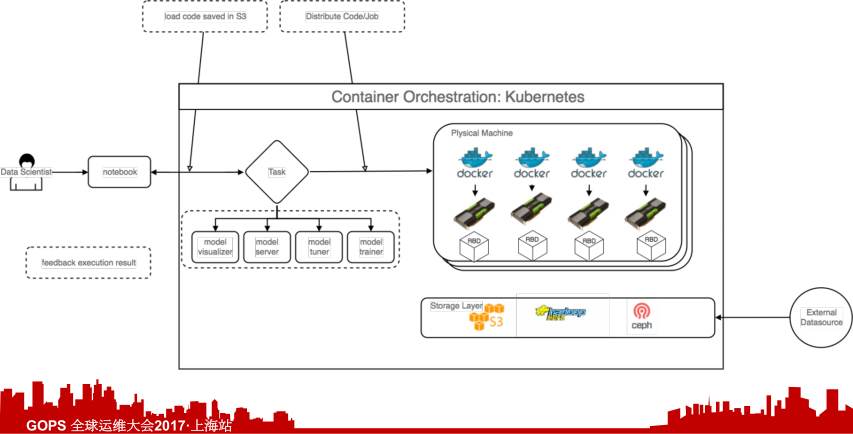
我们可以简单看一下一个机器学习工程师日常的一个工作流(示意图)是什么样的。刚开始他可能有一个想法,他会找一个我们提供的Jupyter工具,他写下他最初的想法,做了一个雏形。第二步就是生成一个类似于task的东西,进行分发。真正去线上进行训练,训练到最后是我们Model serving的过程。整个服务从想法到线上是什么样的流程,要经过哪些步,可能现实中比这个复杂很多。
四 GPU云使用简介

最后可以看一下,我们GPU云简单的界面,这是我们单机部署的界面,这边是三个应用的列表。
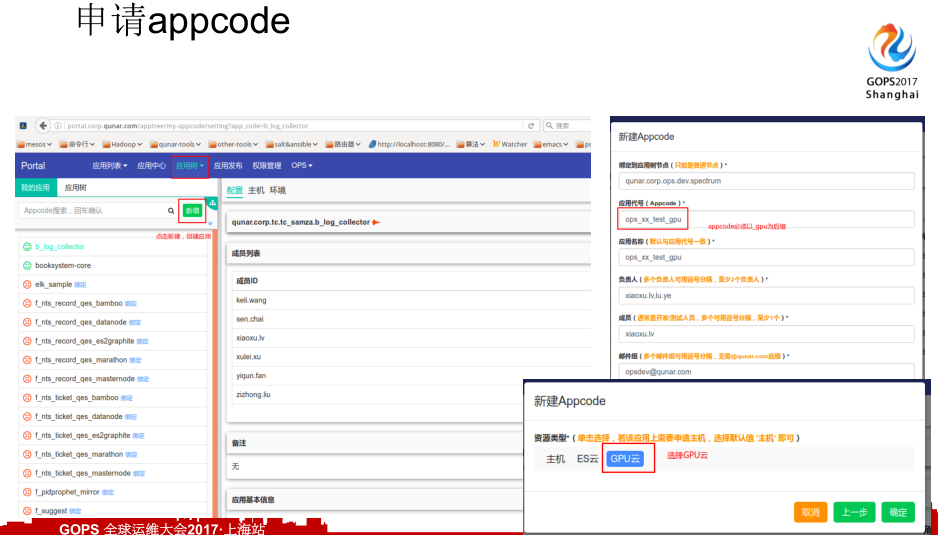
如何启动一个GPU环境,首先是内部的Portal平台,研发新建一个应用,选择应用类型。我们公司内部云化的包括ES还有GPU,还有普通的机器资源,或者是容器,你要选择你的机器,你的appcode后面的资源模型是什么,我们选择GPU,然后选择你负责人等等。

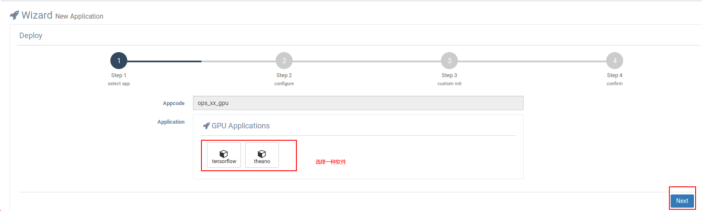
这边直接从GPU链接可以点进去,可以选择机器学习应用的选型,下面可以选择Tensorflow,第二步可以选择版本,第三步可以选择所需要的存储空间是大小,最后就是完全部署。
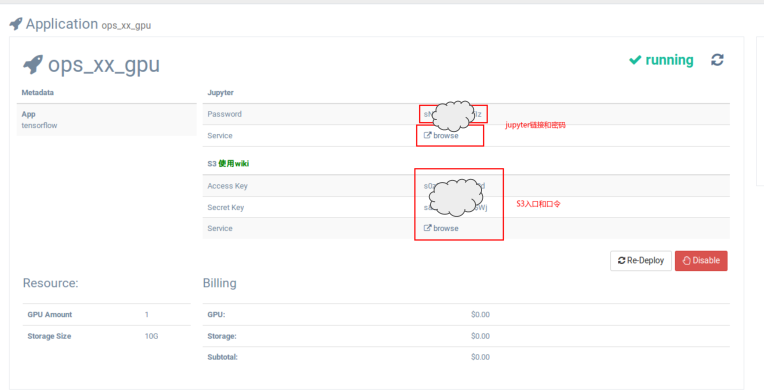
这就是应用的详情。第一个提供的连接我都挡住了,就是Jupyter,第二个就是S3的下面的计费就是没有做的状态,是假的,这边选的GPU块是1块。
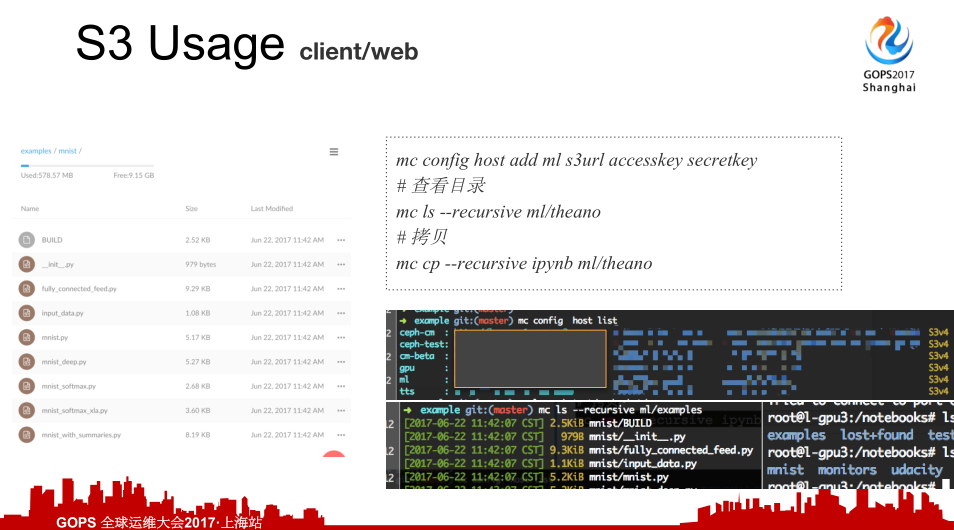
如何上传数据,大家用的时候工程师怎么上传自己的数据,两种方式。一种是通过客户端上传,另一种也提供了这样的web为界面。我们使用方式是两种,一种是RBD,本次磁盘当做是电脑上的一块盘,一种是S3的方式。
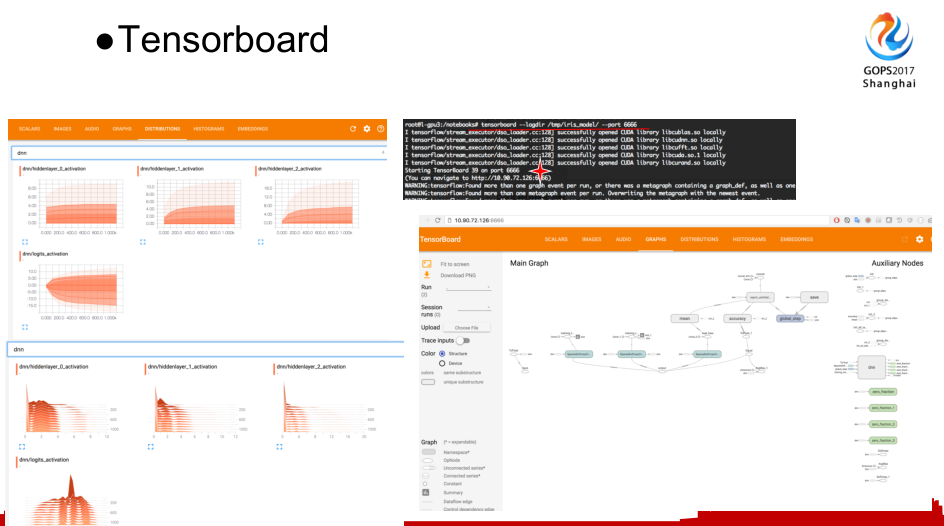
如何启动Tensorboard,直接去提供好的terminal上面点击Tensorboard启动。
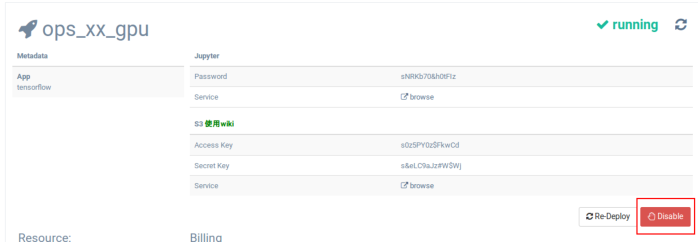
如何停止或者回收一个GPU环境,这个对我们来说非常重要,我们当时给的承诺就是可以一秒钟,把你占用的GPU资源还回来,但所有的数据、当时的状态、环境我们都会给你原封不动的保存。所以他才会点送还GPU卡的动作。

使用对比一个就是要协调GPU资源,要安装环境,可能一遍一遍的安装环境,需要保存数据。还有你数据大小,以前磁盘多大就只能放多大数据,现在我们可以实时扩容。机器学习这个东西训练数据可能非常大,这个上线以前我也遇到很多情况,不仅仅是GPU资源,磁盘空间大家可能都要争抢,这是以前的手动环境。现在环境可以秒起秒删,不用担心数据的问题,对接S3/RBD可以有多种方式获得数据。
