@gaoxiaoyunwei2017
2017-10-16T03:22:17.000000Z
字数 11701
阅读 1128
无服务器化的微服务持续交付
黄晓轩
在此输入正文
讲师 | 顾宇
编辑 | 黄晓轩
讲师简介
顾宇
ThoughtWorks高级咨询师。在 ThoughtWorks分别以 微服务架构师、微服务咨询师、 DevOps 咨询师
、DevOps 工程师以及软件开发工程师的角色参与了国内外共计 7 个产品和项目的微服务咨询和实施。
现在主要参与 ThoughtWorks 国内外交付项目解决方案的架构设计与实施,以及国内DevOps以及微服
务相关咨询。并长期专注于DevOps、微服务相关最佳实践以及全功能产品团队发展。
在加入 ThoughtWorks 之前,曾经参与中国移动 10086 呼叫中心以及中国联通省级 BOSS 系统的研发
、实施和割接。曾任项目经理,维护经理,开发工程师等职务,拥有丰富的大型系统生产环境实战经验
。
于2015年和ThoughtWorks其它同事翻译并出版《七周七Web框架》,并在等多个平台和媒体发表
DevOps 和微服务领域相关文章。
前言
我在刚进入ThoughtWorks的时候就做微服务,当时不知道什么叫做微服务,只是我们通过一个小的技术应用替换原先的大应用的一个部分,当时只是做一个解耦,后来等微服务的概念兴起的时候才知道我们当时做的是微服务,这是我做微服务的起因。最近在做DevOps的一些咨询,在海外做一些互联网行业的并购,用了DevOps的相关技术。这次我就讲一下我之前做的一个案例,就是无服务化的微服务的持续交付。
一 什么是无服务器架构
无服务器架构,这个词2012年就已经出现了,当时是因为移动互联网兴起。大家会发现移动互联网的很多应用后面都不再采用自己的服务器,都是用第三方的各种服务,慢慢地应用也产生了变化。当时就有人以这个作为起点写了一篇文章(文章链接http://readwrite.com/2012/10/15/why-the-future-of-software-and-apps-is-serverless/),我们就有一个无服务器架构的最早的认识。因为我之前是做运维的,我听到无服务器之后我想的就是一点,Dev终于解放了,每次生产环境要上线的时候就发现这些问题,当你跟Dev说这些权限、防火墙、SDK版本去给他构建环境的时候他是一脸疑问的。
以前的程序员眼里的生产环境是什么样的呢?
- 资源是无限的。就是从来不考虑我的内存是不是有限的,磁盘是不是有限的,CPU是不是有限的,认为一台机器资源是海量的。
- 永远是用root。在生产环境也是用root,不做隔离,没有安全意识。
- 本机当生产环境。在本地机器上运行好的,在生产环境就会出问题。
无服务器就是只要写代码就可以了。我们就有了两个定义:
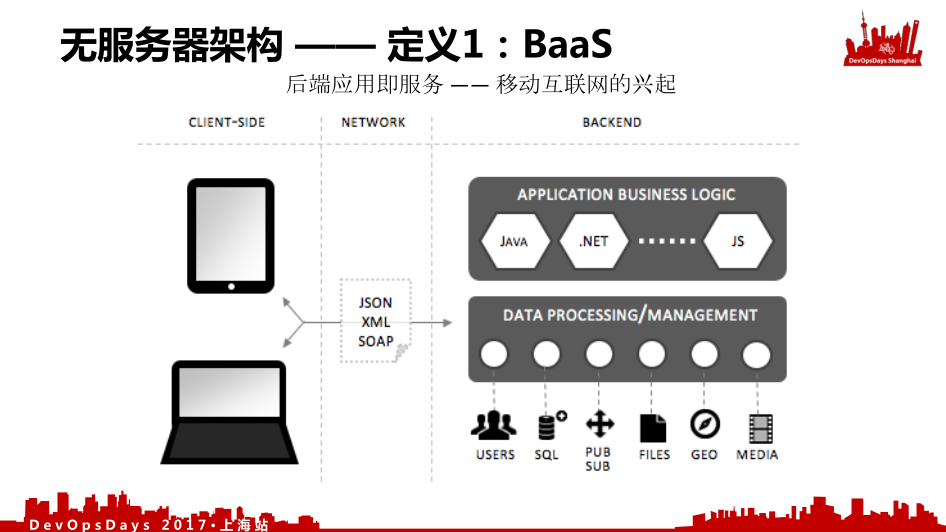
第一版定义,是移动互联网的兴起,前端已经突破了Web浏览器,已经有了移动端的应用之后,通过一些中间协议去访问后面的应用,这个是后端即服务(Bankend as service,BaaS)。
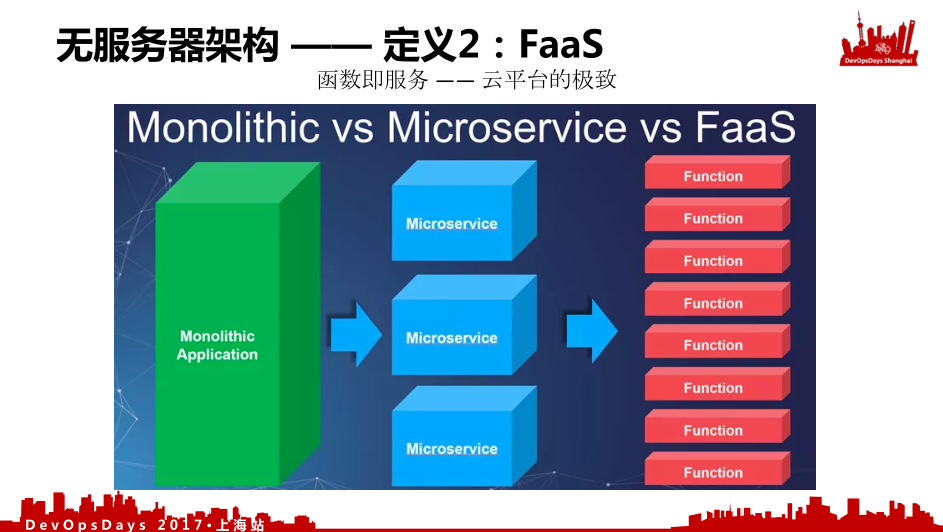
第二版定义,是后来有了AWS Lambda之后,就变成了函数即服务(Function as service,FaaS)。这是微服务目前的演变史,一开始我们有个单体应用,之后就变成了各种微服务,微服务继续拆分就变成各种函数。函数在可扩展性上,因为它是无状态,它有很多的优势,所以特别适合互联网这种大规模的并发应用。

现在可以用Serverless的云厂商有这些:亚马逊有 Lambda;微软的Azure 有函数计算;IBM Bluemix也有函数式;谷歌的 google cloud platform;还有一个很小的厂商 webtask,也用了无服务器这种架构;阿里云已经公开出了无服务架构;腾讯云函数计算这个服务,还是在内测阶段。
如果你想自己整一套,我这里给大家推荐一个开源的工具,OpenWhisk(https://github.com/apache/incubator-openwhisk)。我们在有一些很小的生产环境和测试环境上的某些应用,已经可以用这个框架去做了。
二 基于 AWS Lambda 的无服务器架构
下面我给大家分享一个我做的案例,我是作为这个案例当中的架构师身份出现。该案例是基于AWS Lambda的无服务器架构。
2.1 背景
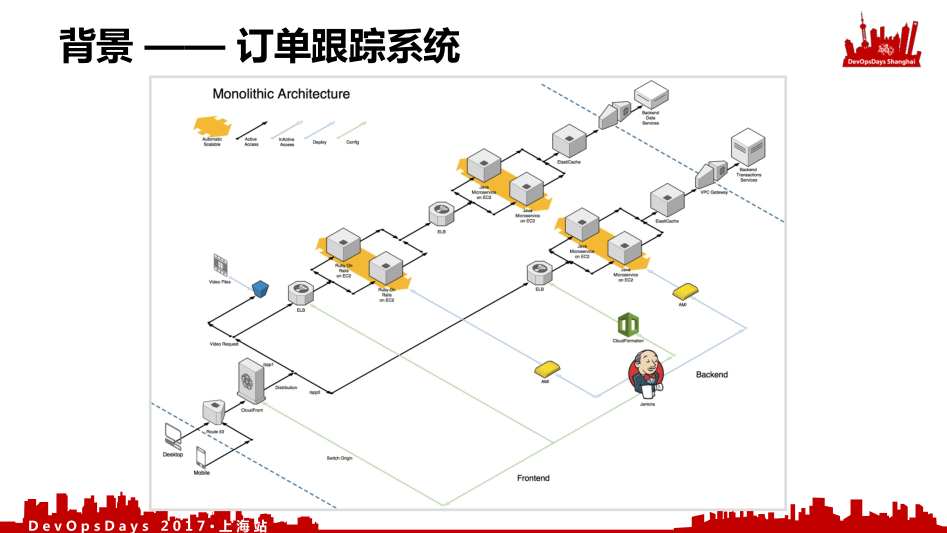
这是我们原先的架构图。一共分成三端:最左下角是我们的浏览器和mobile端;中间是我们放在云上的;右上角是我们在生产环境中的。
这个客户是一个电信客户,他们有一些在线业务,比如订单查询、充值、缴费等等基本业务。这是其中的一个应用,这个应用是一个订单跟踪系统。他们做的是宽带猫,宽带猫就有一个订单,我买了宽带猫之后什么时候出货、什么时候送到你家、什么时候安装,这么一个系统。
这个系统前面是一个Ruby Rails,它是很快就可以做出来的应用。中间可以看到靠后有两个并排的,这是用Java做的一些服务,还不是微服务,虽然称作微服务,但是就是一个代码量很小的Java应用,它还不具备微服务的扩展能力和快速的容错能力。后面通过网关去访问后端系统,这是我们当时的系统架构,用了Jenkins去做它的持续交付流水线,用了AWS CloudFormation和AMI这样的技术去部署环境。这是一开始的架构。
2.2 架构痛点——经典单体架构痛点
这个架构有一些痛点:
- 第一,我们的交付周期很长。一个功能上线要经过各种各样的测试,大概有45分钟。
- 第二,测试周期长。无关的部分仍然要测试,这就要花费20分钟到27分钟,按最长时间计算可能会有半个小时。
- 第三,部署周期也很长。因为是有多层的AWS EC2部署,整个部署需要15分钟。
- 第四,依赖功能点多。因为整个的架构并没有分开,大家都在一个团队里,一个功能完成之后,其他的没有开发好,那所有的东西都在排队。
从这种角度看,你看一个单体架构并不是一开始就是这样。一开始都是很小的应用,经过不断的发展,有很多的技术债不清理,就慢慢演变成突然一天撞到你面前让你业务鸡飞狗跳的情况。当时这个应用开始的时候,客户跟我描述,当时用敏捷开发,我们上线其实很快,大概一个礼拜就可以上线一次。后面随着功能的增多,就像滚泥球一样越来越大,到现在我们虽然需要开发的功能只占两个人天的工作量,但是我需要两周的时间解决后面发布的问题,因为我有很多东西需要进行回归测试,而且又没有自动测试。
首先单体架构,罗马不是一天建成的,泥球也不是一天滚出来的。他都是在技术债上面慢慢变大的,所有人都忽视了技术债可能给未来造成的风险。我所碰到的客户,管理者都是短期的决策,我只考虑未来1到2年,或者1到3年,甚至是半年,我会做什么样的决策,因为可能我还干不到那就被裁了,所以会做一个短期且见效快的决策,但不会为长期去考虑。这样管理层和开发人员对架构风险和技术债就会进行漠视。有的人会考虑到我这是做一些可靠性的设计,但是我们在做服务,会想设计的时候可靠性并不是过度设计,而是对你风险的一种管理。
2.3 组织痛点——Ops 成本极大
我们在架构痛点出现的同时我们还有组织痛点。我们的Ops成本是极大的。
- 第一,AWS需要专业的知识和培训。一个大概60个人的研发团队里面只有3个Ops。而且AWS的架构非常的复杂,需要专业的知识和培训,不是短期一两个月就可以培训起来的。
- 第二,Ops用的工具比编程语言要多。跟dev比较我用一种编程语言,一个框架,加上一些依赖包,只要知道语法怎么写,这个框架和依赖包怎么用,怎么测就可以了。但Ops用的工具从底层到最顶层是非常多的。
- 第三,Ops拥有着阻碍DevOps的权限。在我们的组织里面DevOps变成了一个团队,devops团队是devops实施的反模式或早期阶段。如果你不及时解散你的DevOps团队的话,DevOps团队会成为整个团队的Ops的瓶颈,然后DevOps就成为一个为所有的开发团队服务的角色,变成了一个万能的垄断者,所有都听ops的,感觉就像一个Ops团队统治了所有Dev团队一样,所有人都要听我的。
回看一下我们的架构。这个时候我们在考虑的不是架构痛点。对于客户来说他可能习惯了一两个月的发布速度,你哪怕加快两周他都觉得很高兴了,但是我们主要解决的是组织上的痛点,我们减少了很多Ops的工作。

在Serverless里面,这是 Martin Fowler一篇文章的截图,他在这篇文章里面讲了常见的两个使用Serverless技术的场景。
第一种场景,用户界面的应用程序,多出现于前后端分离,以及我有移动端和browser端的方式。这个场景是这样的,第一步调验证服务,然后查我产品的数据库,然后交到浏览器端,然后通过浏览器端跟API进行交互,对我这个产品进行买或者查找。这么一个用户界面的驱动程序。典型场景就是说我们浏览器和mobile端对后台进行访问。

第二种场景,是消息驱动的应用程序,这是一个广告商应用程序,我点击一下就要对广告进行计费,然后传到我的数据库里面。
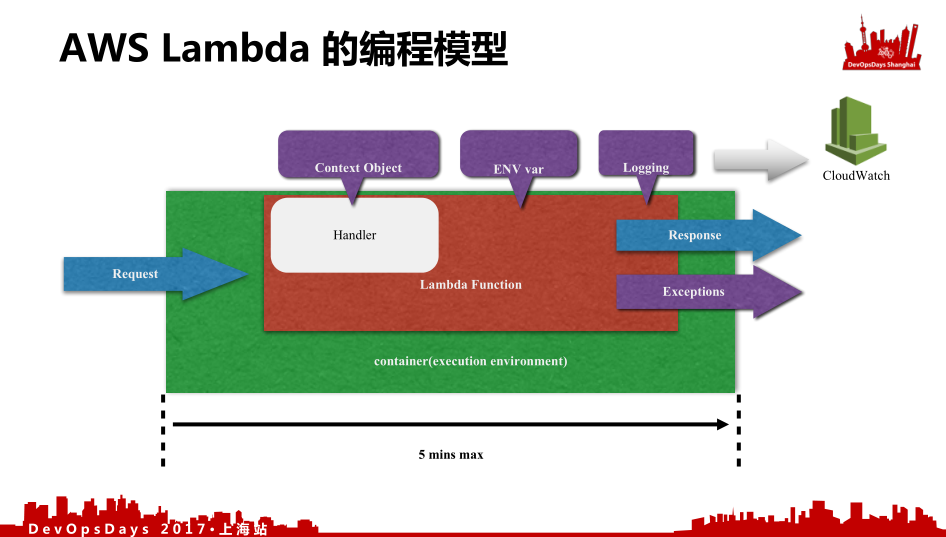
我们在这之前先简单介绍一下AWS Lambda的编程模型。这是它编程模型的架构,整个绿框被称作容器,Lambda执行容器的一个抽象概念。你对它是不可见的。中间就是你的Function,Lambda就是一个函数,这个函数默认给了一个Handler,类似于一个句柄,它通过Handler把我请求中访问的上下文环境,包括我的一些cookie,包括我环境上的一些东西传入到我的函数里面,我还给它注入环境变量,而且可以打日志。这个日志是统一收集的,不需要你额外去做日志收集,你只要采用它的日志对象,就可以打到CloudWatch里面。在处理完成之后会把这个函数的返回值响应出来,以及抛出的异常。这所有的东西你只需要关注函数,剩下的AWS Lambda全都替你考虑到了。但是有一个限制,就是你整个执行时间只有五分钟,五分钟之后不管你有没有成功,都会给你敲回掉当天的执行。
AWS Lambda的优势:
- 无需初始化和管理服务器。你不需要管理服务器,程序员发布完代码就可以执行了。
- 按请求收费,不用考虑负载均衡。
- 根据代码的运行时间付费。
- 自动处理内存、CPU、网络和其它资源。你只需要在AWS统一配置好权限,剩下的事情都不用考虑了。还包括初始化、监控、自动安全补丁、日志也都不需要管。
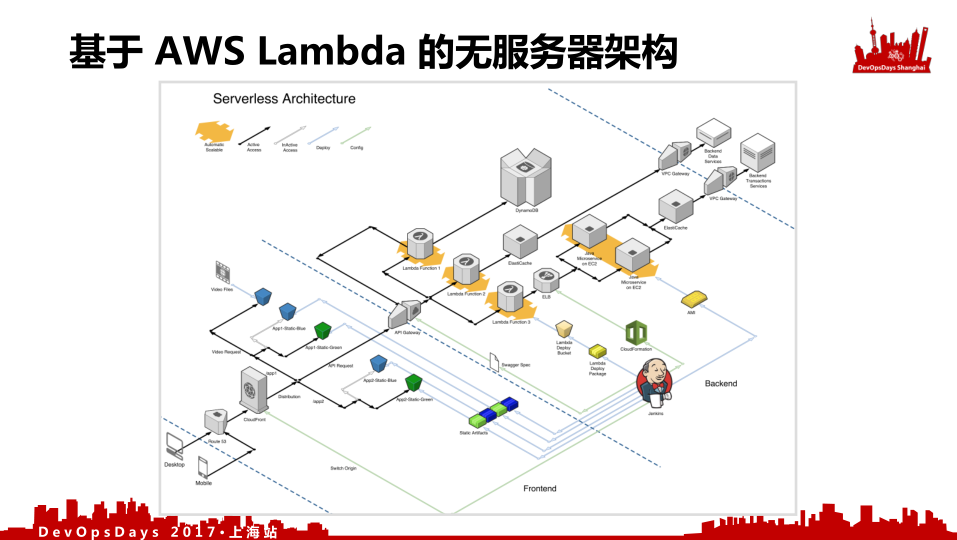
之后我们就变成了这样的架构。这么一套复杂架构,只是替换了我们前面的架构的Ruby Rails应用以及后面堆砌的连接的Java应用的一部分,我们把整个一套替换成了Serverless的架构。前面浏览器不变,中间我们前面经过域名之后到了CDN。CDN这部分,我们采用蓝绿部署,去部署它的静态内容,做了前后端分离,中间关于API请求通过这部分继续往后传,然后有一个API Gateway,它负责把API的请求发散到不同的Lambda。可以看到中间有三个横的 Lambda 去进行计算,继续传递给到后面。右边下边这个部分还是保留了一些Java应用,因为还是需要Java处理一些Lambda处理不了的事情。我们左边通过缓存和数据库直接访问到了我们的后端,我们的网关里面企业内部的一些应用资源。这是一个真实的架构,如果我们把右边的一点点运行到主机上的功能去掉的话,我们就得到了一个完整的无服务化微服务的架构。
我们项目部署的时候可以看到部署比以前复杂多了,我们要控制CDN,要控制CDN部署不同的静态资源,我们在上面增加蓝绿部署。因为我们可以通过蓝绿部署在我们静态资源平滑切换的时候可以得到一些部署上的优势。我们在中间加了很多的配置用来部署我们的API Gateway以及Lambda函数,后面就是传统的AWS EC2部署的。
三 打造无服务器化的微服务持续交付流水线
基于这个架构我们是怎么打造无服务化的微服务的持续交付流水线。
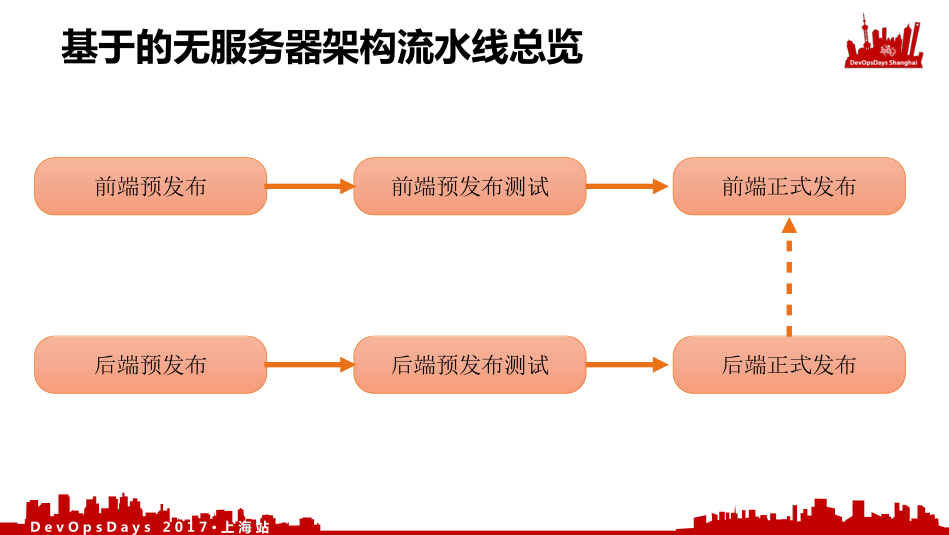
我们是前后端分离的,我们前端预发布,然后进行测试,然后前端正式发布。但是在发布前端之前我们是先发布后端的,因为你前端上线之后可能后端有一些功能还没有上,我们用API的版本,最为新旧功能的替换。我所有的每个版本的功能都会在线上,根据我前端的部分应用指定我使用的是哪个版本的API来切换不同的功能,这是我们当时发布的策略。所以进行前端的正式发布之前我们先进行后端的正式发布。

我们流水线是这样构造的。我们是基于Node.js的应用,用测试驱动开发的方式。我们通过Pull Request提交,然后通过webpack在线上Jenkins里面来构建应用,然后传到S3存储上,就完成了我们的部署。这个时候只需要更新我们的CDN切换到新的S3上即可。我们在S3的存储上用不同的文件夹来区分不同的build方式,所以我的部署到production是持续的,我们会有一个测试环境进行测试,一直往production上部署,用我的CDN来切我用哪个版本正式发布给用户。这是我前端。
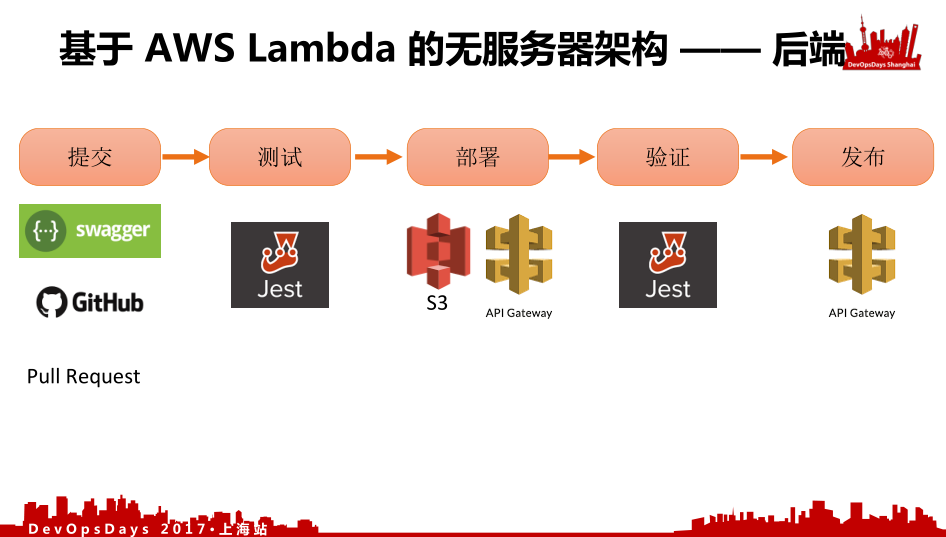
那后端稍微复杂一点。在提交这部分,我首先要变更从我API Gateway进行提交,API Gateway的编程和配置就是通过 Swagger格式,Pull Request到master的过程中,对代码进行review,就能知道影响生产环境的这部分有没有问题。把内容合并后再用Facebook的Jest进行测试。部署Lambda有两种方式,一种是直接打包成一个文件,然后传到S3上面,Lambda指向S3去部署你的函数。还有一种方式是直接在线编辑、在线部署。部署完之后我会切换一下我们的API Gateway,这个时候我们不会直接切换到生产环境上。一个API Gateway可以分成不同的Stage,我们先放到我们预发布Stage上,测试完之后我们再切换到我们的Production Stage,之后再进行一次验证。我们在本地测试完之后,因为本地是没有办法去测 Swagger ,只有把Swagger的规范更新到你的API Gateway之后才可以进行测试,所以我们把本地测试做完之后上传之后进行第二次测试。最后通过切换API Gateway,进行后端的发布。在这里面,我没有提到代码,因为函数会写的很小,所以它也是走这么一个流程。
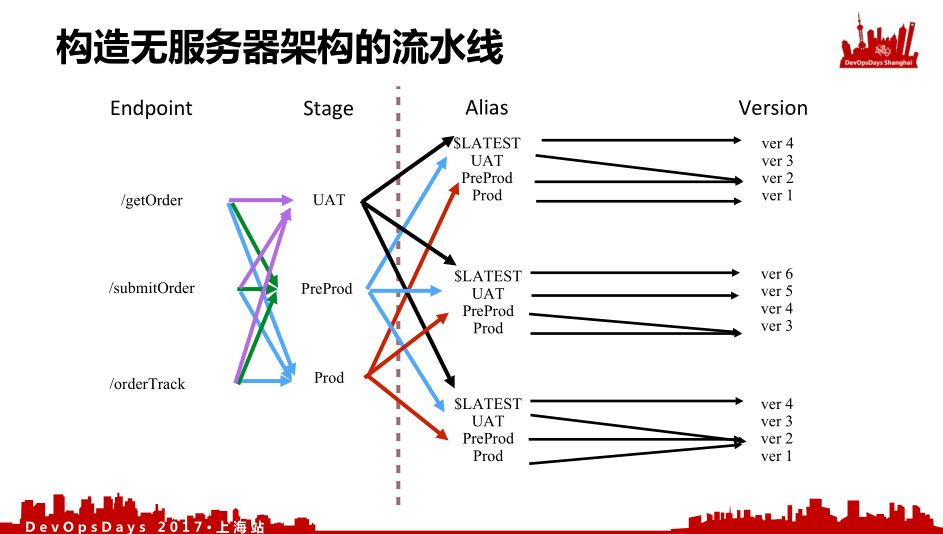
整个过程中我们分为前端和后端,左边是API Gateway,就是后端的部署。右边是我的Lambda。如果我有一个getOrder的API的Endpoint之后,我会有3个Stage,分别是UAT和PerProd和Prod。之后会有一个别名,你部署Lambda时有一个默认的Alias,还可以增加不同的别名,只要我对应的Stage挂载到对应的别名上,我每次部署的时候都会有个版本,也就是每个函数的版本,我每个别名指向不同的函数版本,这样我就完成了函数的端到端的部署。我有三个Endpoint,就是图中的效果。如果我有七八十个函数的话就看不成了。后面我会介绍怎样解决这个问题。
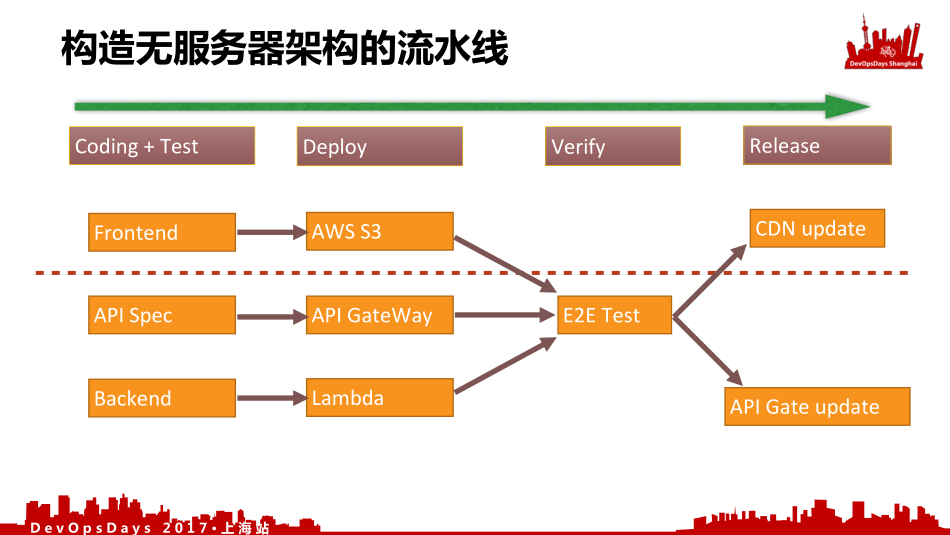
我们构造一个无服务器架构的流水线,我们把前后端拼接一下,上面是前端,下面是后端,中间是API的规范。我们统一部署到AWS S3、Lambda以及API GateWay上。我们在生产环境上切换好之后,会进行一个端到端的测试。测试完成后,我们先部署后端,再部署前端,然后先切换API GateWay,再切换前端。它会把一些新的函数和新的函数功能的版本进行一次重新绑定,更新完前端之后会指向新的函数和新的API版本。我们可以看到整个过程中只有一台服务器就是CI。有一个叫LambCI(http://lambci.org),它是一个无服务器持续集成环境。它整个全部就是依靠AWS Lambda进行处理的。
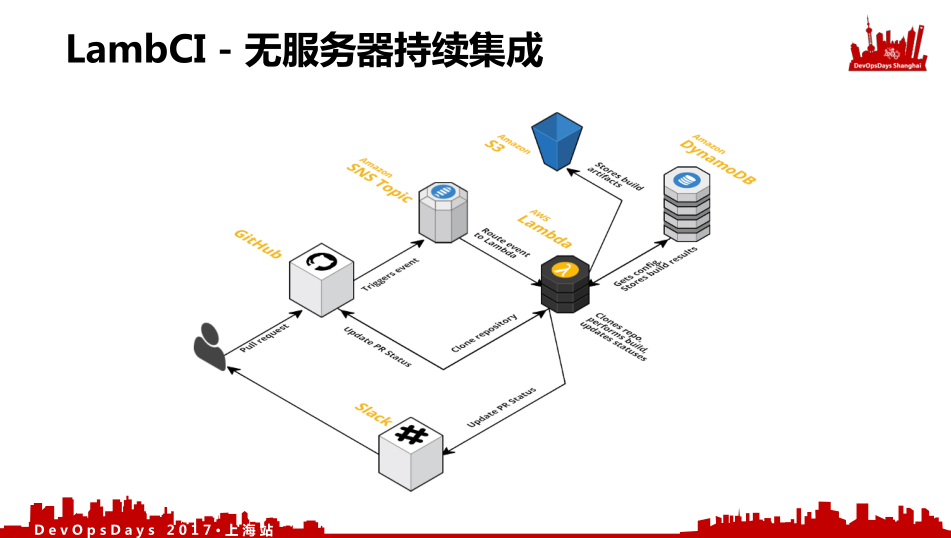
它整个架构时这样的,左下角是用户,我Pull request到Github上,Github有Webhooks的功能,它会挂载到两个部分:一个部分是通过消息队列发放到亚马逊的SNS服务上,这个订阅会发送另外的事件,交给我的 Lambda运行整个的Job,运行完之后我会把运行的产物分别放到S3存储上,然后把对应的数据写到我的(DynamoDB)时间序列数据库,写完数据库后我再通过Slack通知我这个Build完成了。
整个所有的工程这几个组件没有一台是服务器(你需要初始化的服务器),都是在线的服务,这是无服务器持续集成的CI。但是它有一个限制,就是Lambda的限制就是你只能运行五分钟,所以你的所有Job不能超过5分钟。这就带来一个挑战,我们要优化我们的流水线,就是让每一个Job不能超过5分钟。因为你可以不断的触发,所以我们就做了一个事情,把排开的端到端的测试分成每一个请求,每个请求进行一个测试。AWS Lambda的能力就是在一个瞬间可以同时执行一千个,我就把串行的测试工作分成几十个并行的测试工作,这样就会提升效率。如果没有这个限制的话,我们会觉得之前的串行测试是习以为常的,就是端到端一步步执行下来,我们不会考虑优化它。
效率的提升这个是做了一个粗略的统计。我们通过Lambda的架构,包括我们工作的方式,我们的理论开发效率提升了至少8倍,从16个人月到2个人月,这中间还包括什么,包括我们对Lambda技术栈的学习时间。如果用之前的Ruby on Rails架构的话,包括Java可能就是前面说的较长的那个时间。我们大概在开始这个项目之前估算了一下。基础设施代码配置减少了82%,你就可以知道做自动化运维在初始化你的服务器和基础设施的时候花了多少的代码在上面。从提交到部署的时间缩短了84.4%,我们最开始时的最长时间是45分钟,我们通过这个架构变成了7分钟。基础设施导致故障率降低了多少,这个没有进行统计。之前的架构在我进入这个团队的时候在4个月时间发生了3次production故障,但是我这个架构完成了之后,因为它只是一小部分,之前3次production故障是里面一个新的功能挂了,我整个production都挂了。而我这个功能目前没有挂过,所以它能减少的故障是我很期待的数据。
而且这里面发生了一件事情是非常有意义的,我们在新的架构上添加了很小的需求,因为我们是新的应用,我们客户想增加一个很小的需求。我和两个开发人员,包括我们当时客户的经理共4人,跟业务人员两个人在一个房间进行需求讨论,讨论了两个小时。讨论两个小时之后需求定下来了,同时我们代码已经写完了,唯一等待的就是我们需要另外一个测试部门对它进行审批才可以发布到生产环境。在这个过程当中我们就通过 Lambda 这样的技术我们随时改,随时上线,跟我们的业务端客户一起了解需求,改完之后就上线,已经放到我们的预生产环境了。
我相信在未来的时间,如果这个架构,包括对应的技术成熟的话,那我们可以大大缩短我们需求确定之后到我功能上线的整体时间。我们当时把这个应用开发完之后我们实际上等了两周,而在这之间我们没有做任何的修改,我们最后 Release的版本就是我们当天两个小时结束后,需求确定之后直接交付的那个版本。所以整个测试也就在那个过程中完成了。

在这种环境下,Ops工作就只剩下三件事。第一是设计整个的架构。不但包括应用的架构,也包括基础设施的架构,采用什么样的技术解决什么样的痛点。第二是构建一个流水线。用某一种方式构建一个可以快速交付的流水线。第三是监控。在这中间所有初始化、安全相关、网络相关的所有问题,云平台全都会帮你解决的。只有这三个部分是你自己需要解决的,Ops的工作就轻松了很多。
四 无服务器化的挑战
挑战1 函数的管理和微服务的管理
这是我们看到它好的一面,它也有一些问题。函数的开发测试其实非常快,不需要进行部署,不需要等待有各种各样的测试,直接在上面开发就直接运行了。更多的时间你会用更多的时间跟客户进行沟通,而且用更少的时间编程,需求分析完了,功能就开发完了。然后更简单的和面向资源的抽象方式。以前我们要对业务进行建模,但在这里面就是你需要做什么,你准备怎么做,你准备在哪做。这三个问题,你就问你的用户。比如我刚才是查询订单,你需要什么样的数据?我需要用户的订单号和用户基本信息。在哪做?我在AWS Lambda上去调取。调取什么?调取我后台的数据库。未来就是这种句式就可以完成你的需求到架构的转化。然后对复杂问题的拆解更加简单,你面对的就是实实在在的东西,而不会再用各种各样的方式去建模,最后变成你的应用。因为你的试错成本很低,你可以不断地更换来满足用户的需求。
有很多的函数管理起来很麻烦,针对这种问题有很多的框架。Serverless是其中的佼佼者,它是AWS自己的项目,开源之后贡献给开源社区了。它包含命令行以及各种的项目模板,你只要创建你的微服务的项目,它会把所有的函数,以微服务模块把所有的函数组织到一个微服务里面,所以你部署是按微服务去部署的,里面实现微服务功能是用的函数,它会帮你把所有的调用关系、依赖、资源、权限都处理好,所以你不会在很多的资源中到处找这些东西。
另外一个框架叫Claudia.js,但它只支持Node.js。我们可以看到Serverless不光是支持Node.js,同时还支持 Python和Java,以及其他JVM 上的语言,包括 Scala。AWS Lambda目前只支持三种语言,Python、Java和Node.js,使用其他的语言需要进行转化,他会帮你进行转化,如果你用Scala 的话也可以部署。并且它可以支持不同的领域。半年前的 Roadmap里面写到是要支持谷歌和IBM,不知道现在支持了没有。
还有一个基于Serverless部署的一个管理框架,就是这个Apex。
挑战2 测试
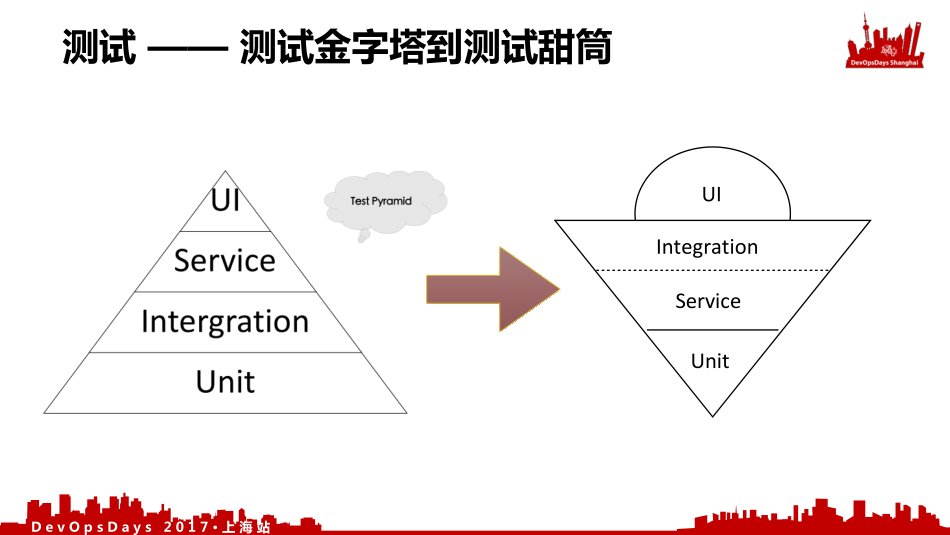
这是大家熟悉的Solidworks的测试金字塔。从上往下,上面的测试代价是比较高的,下面的测试代价是比较低的,但是上面的测试价值比较高,下面的测试对业务的价值比较低。你花的代价和你对应的价值是不匹配的。到了Serverless架构我们可以看到它是一个甜筒的架构。我们在开发的过程中,花在代码上的时间是非常少的,大部分时间都是在跟基础设置和各种配置打交道。我们的集成测试占了很大的部分,我们在Lambda上面Service和集成之间的关系的界限很模糊的。你是跟基础设施集成的Service还是你本身开发的Service,这个界限有些模糊,所以中间是虚线。我们最少的就是单元测试,我们每个函数测试是很容易测试的,对于这种函数式开发而言,但是你把这些东西组合到一起就没有那么简单了。对于UI测试这块,它的尺寸你是很难估计到的,虽然你有UI的端到端的测试,但是它对你实现的价值以及你的架构可以提供的价值是不容易估计到的,不会实现像金字塔的形状的。这个上面的UI部分(冰淇淋球)是可大可小,但是中间集成成本是不变的。这就是测试金字塔到测试甜筒。而这个测试甜筒就非常符合我们测试对业务价值和测试代价之间的关系。
在这里面我们会发现BDD和ATDD的开发方式会更加重要,因为它带来的价值更多。我们首先确保第一点,我们先做一个跟业务相关的测试,然后细化到最后一个函数。单个函数虽然很好测,但是函数集成不一定好测试。因为你跟你的基础设施需要打招呼。然后是在线测试,以前我们做这个测试的时候我们会考虑很多mock的技术。如果你用的技术并没有把你的测试代价变得更低了,反而变得更高了,所以我说不要再做mock测试了,所有东西都在线上测试,进行部署和配置。所以在本地的开发工作量其实很少的。最后就是更多的精力是在AWS的服务之间的集成测试上。
配置管理:Serverless架构就是函数加资源配置。你可以看到整个一个云计算编程模型是各种服务是一个孤立的资源池,而这个孤立的资源池之间如何协调资源完成我整个应用的功能呢?以前是我需要单独的应用去调用不同的资源,现在我把部署在独立主机上的单独的应用去掉了,我通过基础设施之间事件驱动的关系,处理对应的资源,完成我整个应用的架构功能。微服务是作为一个封装函数的资源的单元,你不能把一个函数作为整个业务功能的单元,因为它的粒度实在是太小了。所以微服务是一个独立定义比较清晰的单元。由于粒度更小,对基础设施依赖更大,配置管理的难度更大。
另外一个不好的点,对云厂商的重度依赖。你发现你用AWS Lambda之后,你发现所有的东西都要上AWS,相当于它就把你绑架了,在有些情况下你是有选择的,在某些情况下你是没有选择的。因为你可能自己建一个机房去实现这种快速的发布部署需要很大的成本,相对而言云厂商就提供了这方面的优势。
五 云计算竞争的下一个阶段
Serverless架构的核心有以下三点:
- 第一,服务即状态机(Service as a state machine)。你任何的服务都是一个状态机资源,所有的东西都是对这个装机的状态变化。
- 第二,状态即版本化配置(Status as versioning configs)。各种状态就是通过版本化的配置,可以放到你的代码管理仓库里面,也可以放在你的基础设施的版本化的管理。所以你的状态都是由版本管理起来的。资源的任何一个状态都可以通过版本的管理恢复到之前或者之后的任何一个状态。
- 第三,状态转换即事件消费(Status transition as events consuming)。我状态之间的转换就是我的事件驱动的消费,就是我对事件和数据的消费。
这三个核心就构成了我整个Serverless面对云服务的途径,我不再有孤立的资源,我整个的资源都是通过我内部的方式相互之间驱动的,包括我处理的流程和我处理的数据。每一个资源都是职责、功能单一的处理单元,我通过Serverless的方式用配置和程序,你可以把程序看成一种配置,把它全部组织再一起。
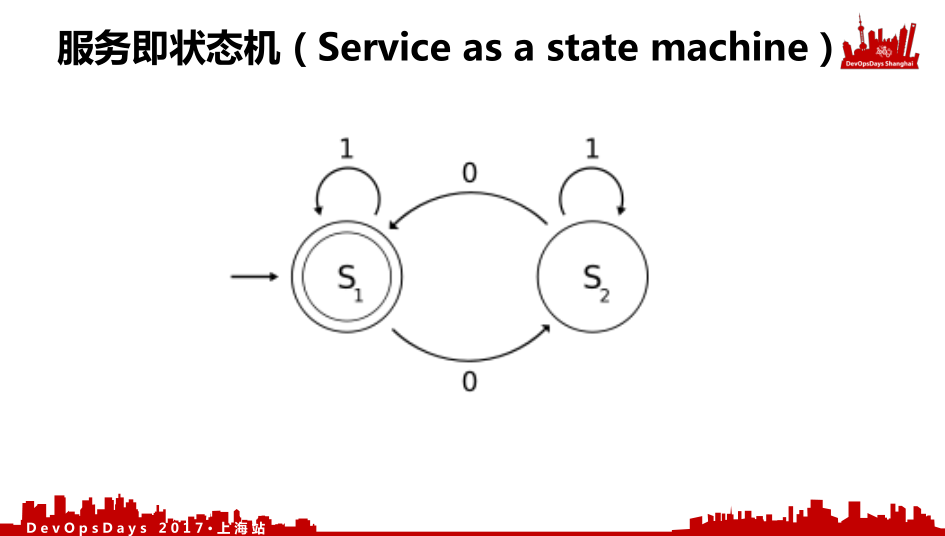
这是我们说的服务就是一个状态机。我们把pipeline看成三个阶段,pipeline抽象看来只有三个阶段,部署前有两个阶段,预部署和部署验证,部署后有一个发布。所有的pipeline都可以变成这三个阶段,所有的资源就是就绪态、服务态两个阶段,这两个阶段通过版本化的状态配置来改变。
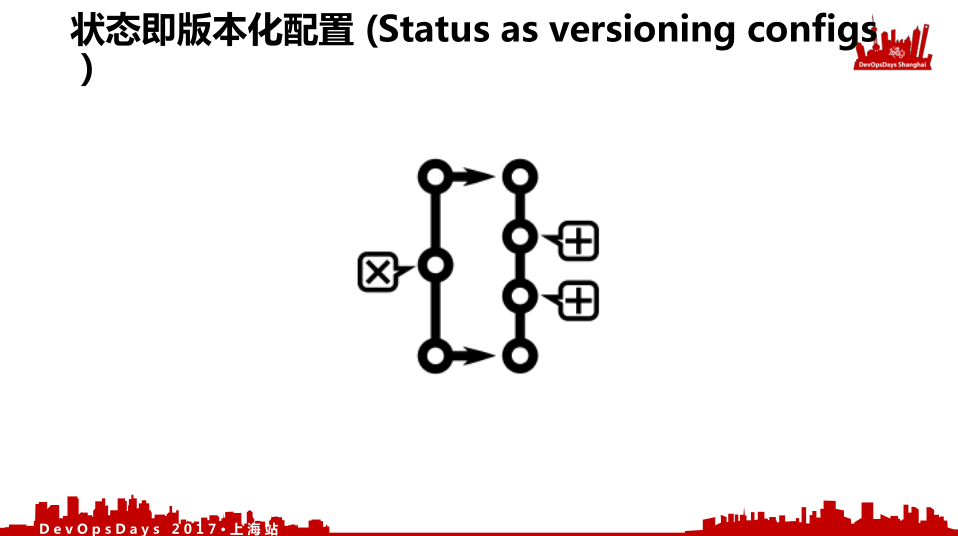
我这个版本化配置可以放到代码库上进行分支管理。
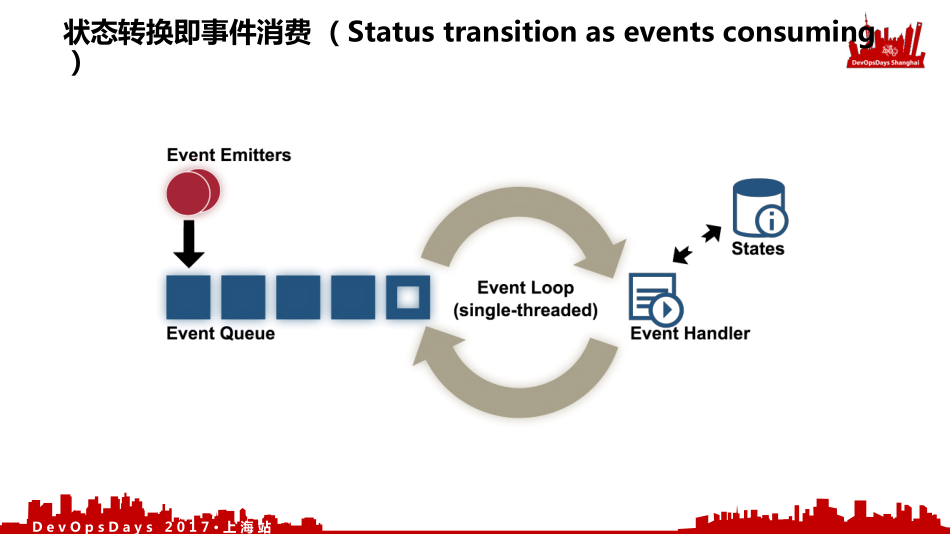
通过上面两个之后对我的事件资源进行消费,形成我整个的应用架构,所以从业务到我实现的中间的距离很短,我不需要进行过多的面向对象的抽象,我可以直接映射到我的基础设施上。
云计算的未来就是配置加资源。代码本身就是一种配置,再加上你对资源的配置就变成一种组合配置。配置应用就是配置和资源的组合,包括我的数据库、API GateWay、对象存储等等都会帮你配置到一起。现在公有云的竞争厂商那么多,关键未来云面向的不是终端用户,面对的是众多的开发人员,所以未来的竞争不是竞争我的终端用户,未来是向开发者竞争。我会面对我的开发者提供更友好的方式。那么谁最后能在云服务的大背景下构建出一套行业标准的DSL会成为云厂商支撑的一个关键。我只要可以创造出基于CloudNative的特定语言我就可以产生不同的基于各种云平台的实现,就相当于我制定了一个云平台上的开发人员标准。这个其实很重要,但是我觉得在国内云计算竞争比较激烈,在国外AWS基本就统一天下,有这种感觉。
另外一点就是我的平台就是我的编程模型——平台即编程模型。我用我的平台来思考我怎么提供业务以及对业务服务,而不是以前我的业务是怎么样的,我再来找我面向对象的模型,找我面向对象的语言,以及我对应的框架,不是从上到下的,而是这种从下向上的。现在的编程模型是由编程语言确定的,每个语言都有自己的特性,我适合扩展的,我是编译的,我是动态的还是静态的,我是脚本的还是非脚本的。语言又跟平台操作系统硬件相关的,我是x86的还是Arm的,我是64位的还是32位的,我是冯诺依曼架构的,还是哈勃总线结构的。都是不同的。未来编程模型将由云平台决定,资源和资源的使用方式的管理会更加方便。对开发人员会越来越友好。我们会看到未来的Dev的门槛会越来越低。我们只需要把现有的东西进行简单的组合加工就可以提供一个新的服务,或创造一个新的场景,去解决我们当前碰到的问题。
举例
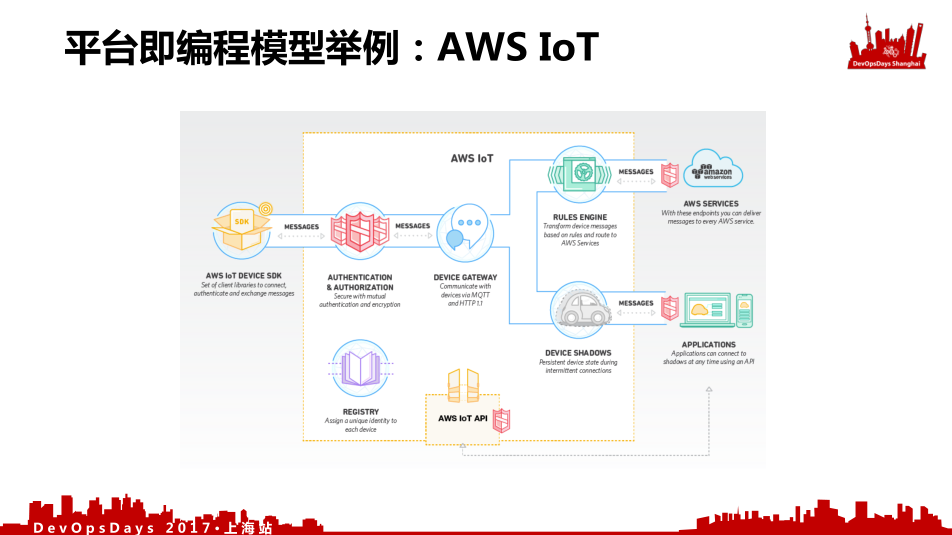
这是AWS IoT平台。我有一个设备端的SDK,中间会有一个设备的GateWay,我会把设备注册上去,中间有一个规则引擎,我什么样的设备带了什么样的数据,触发了什么事件,通过我的规则引擎执行完,再下发到我的设备上,这就是整个设备引擎。可以看到它整个IoT的架构和Serverless架构模式是一样的。我有一个设备的管理,我有一个设备的配置,以及我中间的计算资源。你可以用Serverless完全实现一套IoT这么一个平台。我们可以看到IoT的平台跟我们Serverless的编程模型几乎是一样的,可以预见未来的几年之内所有的AWS的应用架构慢慢会衍生成统一的编程模型,就是我说的资源作为一个状态机,我资源的状态是通过和我的用户数据绑定一起进行配置,这个配置是可以通过版本管理再加上我的程序,我代码的规则引擎,完成我整个的应用,包括我的硬件设备驱动的应用,包括IoT的应用。它都是统一的编程模型,未来可能会慢慢地向统一的编程模型演进。如果在此基础上再制定一套自己云的DSL标准,所有的云厂商都要跟随他的脚步去制定自己的,符合AWS模型的自己的实现。这是我预见的可能在未来的一段时间内,云计算的一些变化,包括对DevOps以及Dev的一些变化。
