@gaoxiaoyunwei2017
2019-08-30T10:51:09.000000Z
字数 7218
阅读 1118
Kubernetes在去哪儿的百万容器实践
白凡
分享:孔晖
编辑:白凡
我是来自去哪儿网的孔晖,我是去哪儿网的数据维护部门,主要是负责容器的技术平台,还有Elasticsearch集群的开发和维护,主要是和大家讲四点一个是去哪儿网容器化的现状与发展,还有就是K8S容器化的实践,第三个就是ES云,第四个就是生产中碰到问题。

1. 容器化现状与发展
去哪儿网现在的容器规模主要是1700+的状态容器和4700家没有状态的容器,还有这些集群处理日志的。

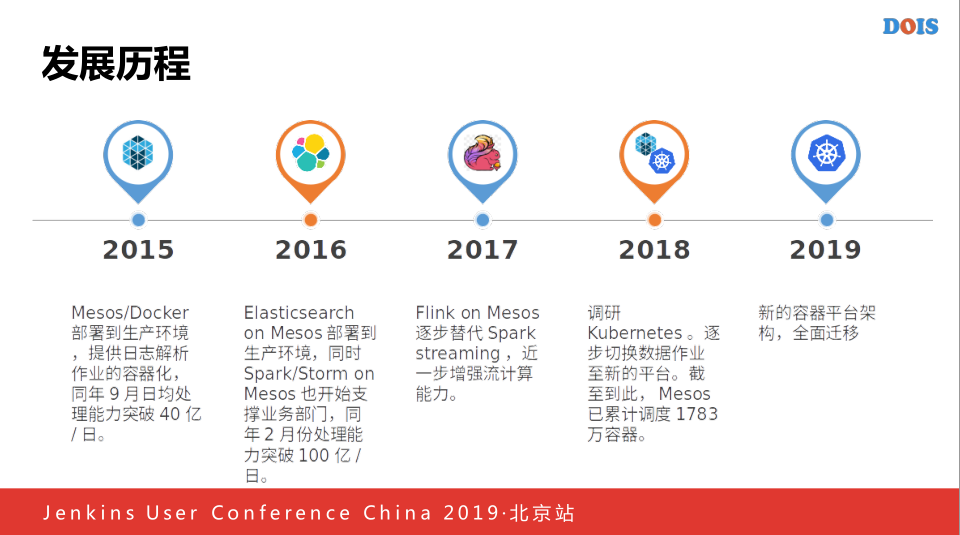
去哪儿网容器开始的时候2015年开始考虑做了自己的一套容器平台,主要是最开始的时候,是使用Mesos做的,因为生态没有现在的那么成熟,所以9月份的时候把我们所有的日志解析放到Mesos平台,等到9月份的时候,日志处理平台达到40亿/日,到2016年我们将Spark/storm迁移到Mesos平台上,同年的时候2月份我们处理能够达到了100亿/日,2017年的时候,开始使用Flink on mesos替换掉现在所有的Spark Streaming,2018年的时候才开始真正的做Kubernetes容器编排,目前的话,我们Mesos已经调用了1700多万个容器,2019年将数据部门所有的Mesos全部迁移到Kubernetes里面。
2. K8S容器平台的实践
第二部分主要大家讲一下去哪儿网K8S平台和现有平台整合在一起。
首先去哪儿的K8S不太一样,我们的组建方式是分为两级,首先每一个机房有一个存在多个K8S集群,通过一层的Reflector聚合在一起,因为原先的是不支持的层级,所以我们做了二次开发,最后可以实现这种数据的结果,我们最开始没有将K8S做成这么多的小集群,最开始是使用的网络查检导致这个问题,还是最终的容器故障率缩小一点,现场发生问题的时候不至于导致出现的面积的问题。
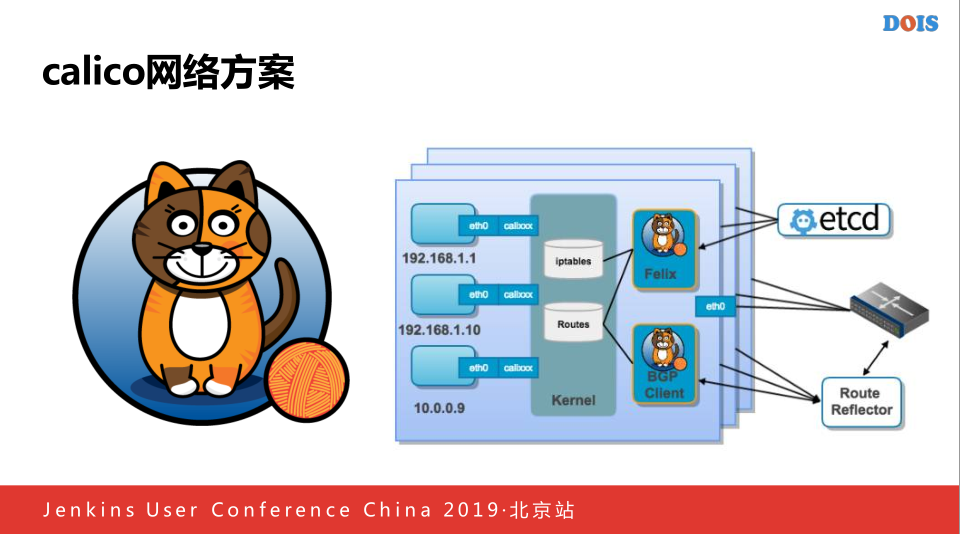
首先网络方案选用Calico,现在存在了两种不同的版本,之所以选用Calico的原因是老版的不支持K8S,性能不是特别的好,但是后来运维的时候发现存在一些问题,他是很新的技术就是BPF,对于我们大部分人来说,本身是一个很少人了解一个技术,当线上容器网络出现问题的时候,我们需要盲人摸象,不知道这个东西到底什么原因,也许看代码,但是他里面很多编一些语言,编出来一些内核的东西,所以就会出现我们调查问题的时候,经常不知道因为什么,比如当时就发现了一个网络地址泄露的问题,一个容器跑着正常突然发现地址是备用码,就会导致整个网络不可用,后来我们就开始选用了Calico,他增加量很高,特依赖于BGP实现的,对于公司网络的来说,对BGP也是非常高的,他比Calico好的一点,他是基于Kubernetes做的,你一旦做好一个集群是很难在集群上面规划好网络,你如果不能增加新的节点,就只能做正每一个机房小集群的方式,这样动态通过增加集群的方式完成一个大集群规模的建设,所以后来我们换成了Calico,他的网络方案,主要带着自己的IP管理的规则,管理的方式,所以当时使用Calico的时候,如果出现了集群资源不够,因为当时的原因,因为集群的IP地址分配不够多,后来用着用着发现地址完了,就可以在Calico动态添加一个新的IP网络,这样对于我们来说是运维起来方便一点,而且Calico他添加主机的时候不像别的那么麻烦,Calico只需要开始的时候路由器配反射器之后就解决掉这些问题,本质上是一个每一个跑的路由器客户端,每一个机器不停的把所有的主机的网络信息通过路由器传播给机房路由器,就可以知道每一个机器上面到底有哪些网络的容器,可以准确的实心容器之前的互通,最主要是使用Calico的原因就是下面这个。
他支持网络层的负载均衡,我们做内部ES云的时候,我们需要一个可以做到4层负载的设备,但是目前来说做不到这一点,Calico主要是一种Cluster模式,新建一个系统,我们的Calico会加入一个通告,可以告诉你几个网络可达,这样的话我们就在路由器的哪一层实现负载的均衡,我们开始使用Calico是需要添加一个CalicoITS的网络的配置,告诉路由器,这个网段是仅供Client使用的,他会将IT地址加到里面,但是他最后出现一个问题,如果我们使用外部的客观Proxy,他会随机挑到一个随机的主机,而不是他发现这个不属于这个主机,会通过再一次路由访问到Proxy,因为他本身知道哪一个Client到这里面,这样话可以减少每一个机器上面的延时。

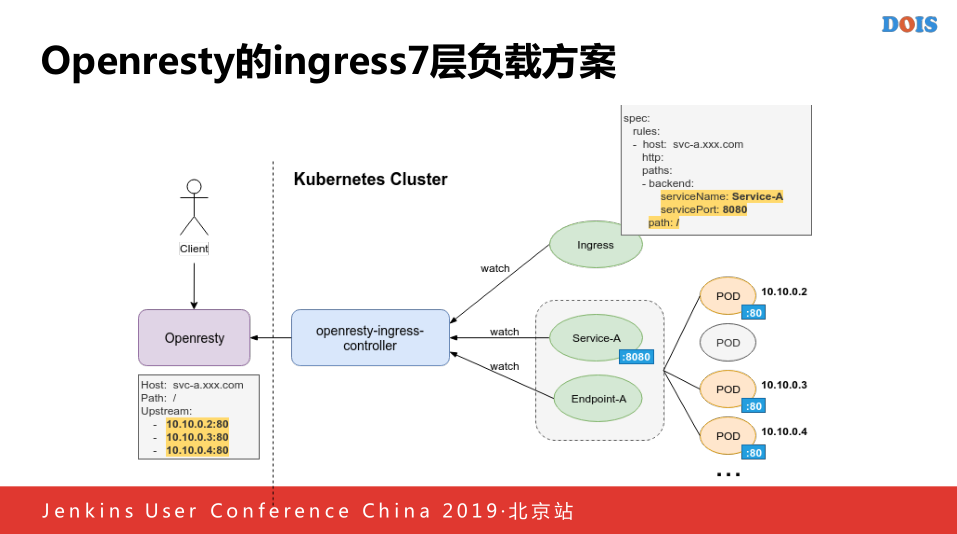
接下来我们做了Ingress七层的分享方案,我们做了类似广泛开源的做的控制器,首先我们写了一个Openresty-Ingress-Controllr,当用去新建一个新的Ingress里面的URI和对应的分享的域名,还有就是拉去到里面对应的主题列表,最后做成一个对应的类似于Ingress的配置,我们之后将对应的列表和指向的URL拉入到Openresty系统中,我们将所有泛域名就会指向七层的Ingress方案。
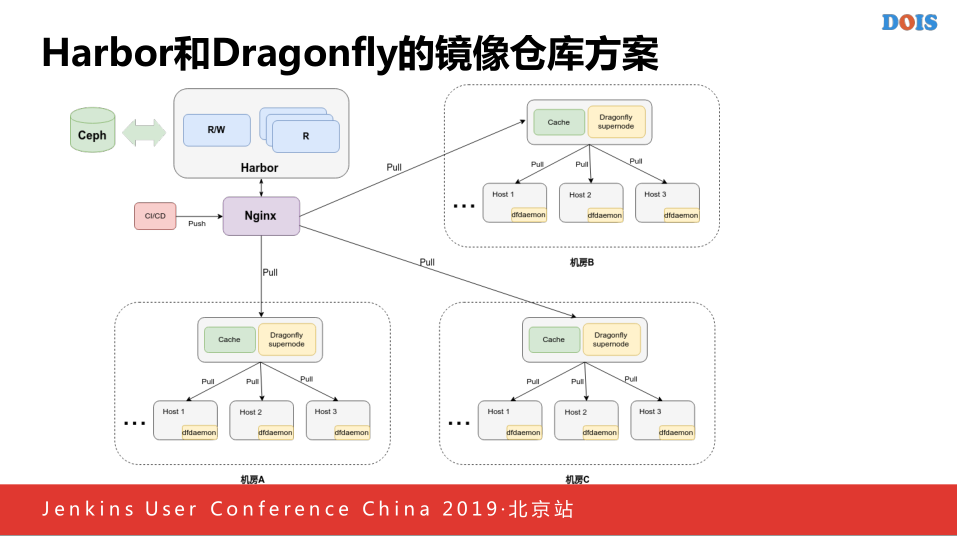
接下来我们做的镜像仓库的方案,我的是Harbor,因为实际上目前的方案不是特别的多,主要就是Harbor做这个报告,没有选择其他的原因他是通过RB这些不熟悉的语言还有一定的成本,他所建立的理念,Harbor有一些接口,可以和所有的系统连接起来,首先上面有一个Harbor集群,他后面有后端的镜像存储,CICD进行透视镜像的时候,我们首先配对Harbor的域名做了分布式的解析,他属于一个机房的话,首先访问在机房解析中对应的Cache,他本身是一个服务器,里面有了Dfdaemon,他会指向这个主机,他会将请求推送到主机上,他有一层配置,如果他发现是一个路游信息,将他返回到最定量的Harbor集群里面,我们可以通过Kubernetes保证每一次的AIP,这样的话镜像从底下进行到Harbor,他本身还会解析出每一个机房对应的时间点的IP,解决对应的Cache进行镜像的拉取,首先访问NGS,他会拉去镜像的,这个时候返回拉取本机的地址,来拉取镜像,如果镜像存在的话,就会想数据返回,进行P2P的分发,如果不存在的话回源到最上层服务器里面,这样就实现了一个镜像仓库的存储方案,这个最开始使用制造方案的原因是因为Harbor本身支持复制的功能,但是他实际上存在一些问题的,假如我有多个机房,加入从总机房开始进行相互的比较,他会发现你到另外一个机房和另外一个节点需要时间的,这个时候进行整理非常有可能出现失败,所以这个时候做成了类似CDN的模式,解决之前碰到的问题。
还有就是如果使用节约成本的问题,因为公司的机房可能不太可以接受在每一个机房里面因为容器的原因单独部署一套CFS,因为CFS的成本很高,主要是机器的成本,所以我们最终选择了这一套的镜像仓库的方案。
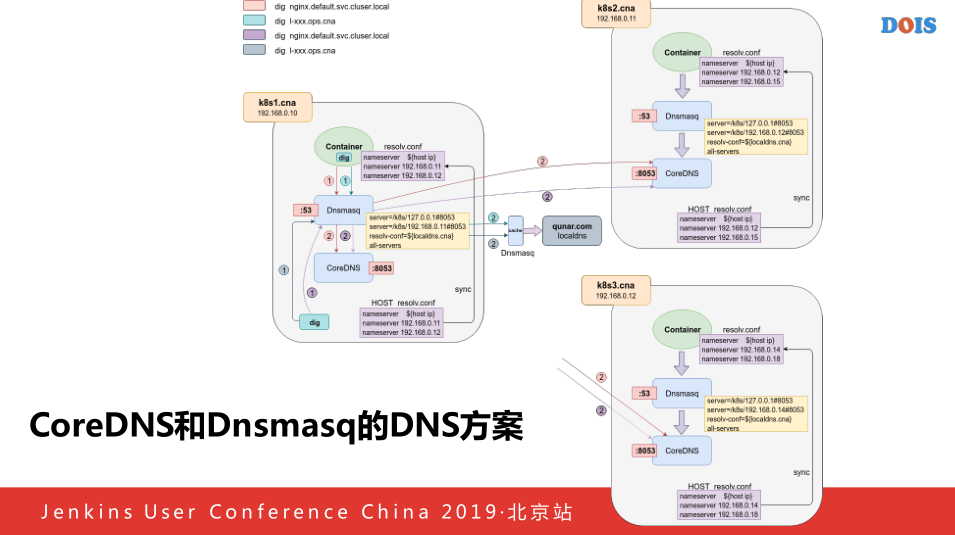
这是我们K8S解析的方案,DNS解析是因为目前,我们在每一个机器上跑一个Dnsmasq,他的DNS解析的IP由我们外在的一个类似专门洗牌的工具,拿到本机机器所有的机器,修改每一个机器上的配置还有Dnsmasq的问题,首先保证第一个写成本地+IP,第二个第三个随机挑两个IP,第二个本身接近午餐端口,做DNS的一层,后端的本机节点还有后端新插入的一二两个节点,这样的话当用户访问解析的时候如果访问的是KYS集群,内部运营的话,首先访问本机的Dnsmasq,他会查看这是去哪儿网内部的运营,就是PDS的运营,如果他属于KYS运营话,请求定位到后面的本机的上面去,这样话,每个机器实际上都靠KYS,这样的话就不会受到个别机器宕机的影响,当CorDNS的话,他本质有一个SNAT的问题,如果你访问的域名都是相同的IP+POT的话他有一个很频繁的问题就会导致你的解析不成功,我们通过这种方式实际上也是参考了DNS解决的方案,如果是外部域名非常的简单,首先访问Dnsmasq,会将本机的查看,查看本机的域名是否是去哪儿内部运营,进行PDS进行解析,这样的话容器可以访问集群到其他机房内实现机器非容器内的机房的互通,这是我们的新方案。
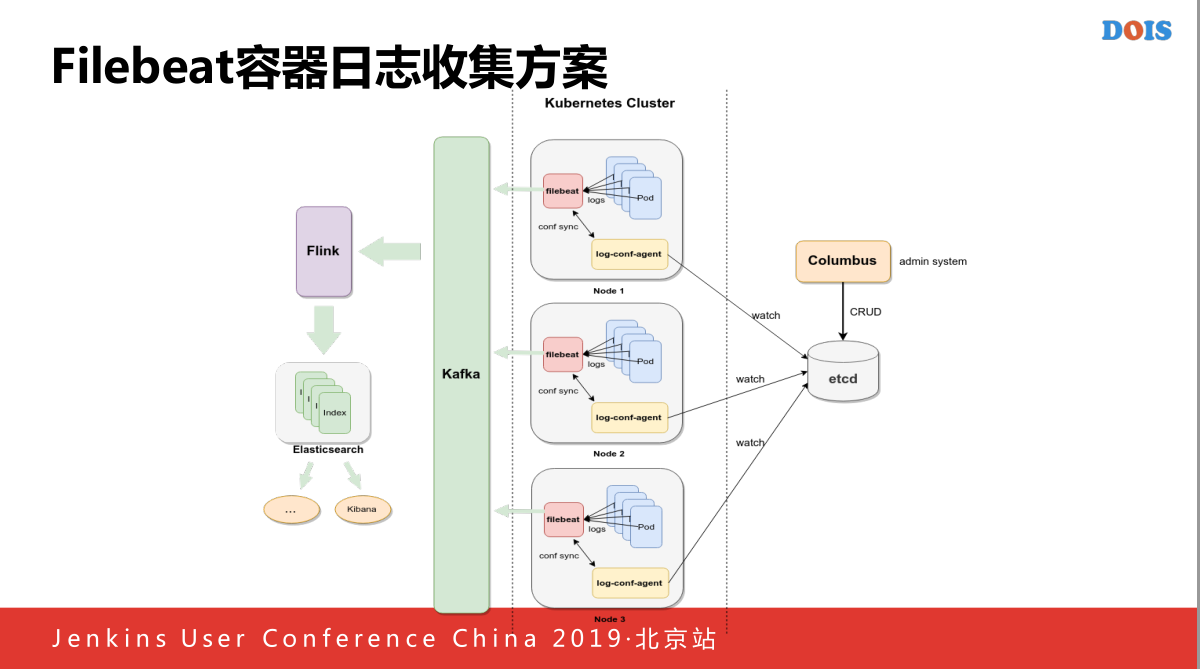
Filebeat是一个日志收集的方案,如果我们线上出现问题的话会出现什么以知的问题,首先自己做了一个Kubernetes Cluster,这台机器主要做来两件事情,他或许最新的配置,因为我们Filebeast是做的一个插件,本身为每一个Pod上面添加一个原信息,属于哪一个容器,这些消息,但是本身不太适合于我们场景,因为我们和Filebeat插件不一样通过挂在点识别我们每一个应用属于哪一个,当我们他也会通过访问的方式知道这些哪些应用存在于我的机器上的,并且名字对应的是哪一个,就会将下发新的分发方式的时候,如果存在对应的文件上面,存在一个新的文件,这样的话,一个新的日志的收集请求,新的日志发到Kafka里面,但是还有一个问题,Filebeat我们之前遇到一个问题,他有一个问题,因为我们没有使用另外一个模式,他的容器跑在一起,或者我们其他的跑在一起,有些他们可能由于程序的BUG,导致刷新特别频繁,打得特别快的话导致Filebeat资源使用特别的高,到时候就认为你的Filebeat特别的高,后来就加到主机里面,做了资源的限制,Filebeat本身还做了一个,当Columbus删掉一个容器的时候,原来没有识别到这个容器卸载了,还一直不停的收日志文件,这个还会导致他的分区,这个正在被写入,或者把他释放掉,这样的话就会导致Kubernetes频繁报错,因为他没有办法将这个卡在了这个状态,于是我们获得了应用即将挂载的一些消息,我们当收到这些消息之后,会修改Filebeat的文件,因为我们知道这个文件即将被销毁,将对应收集的文件的分区修改一下,去掉,重新分集,这样的话最后就可以完美的让销毁的时候可以很好的销毁掉。
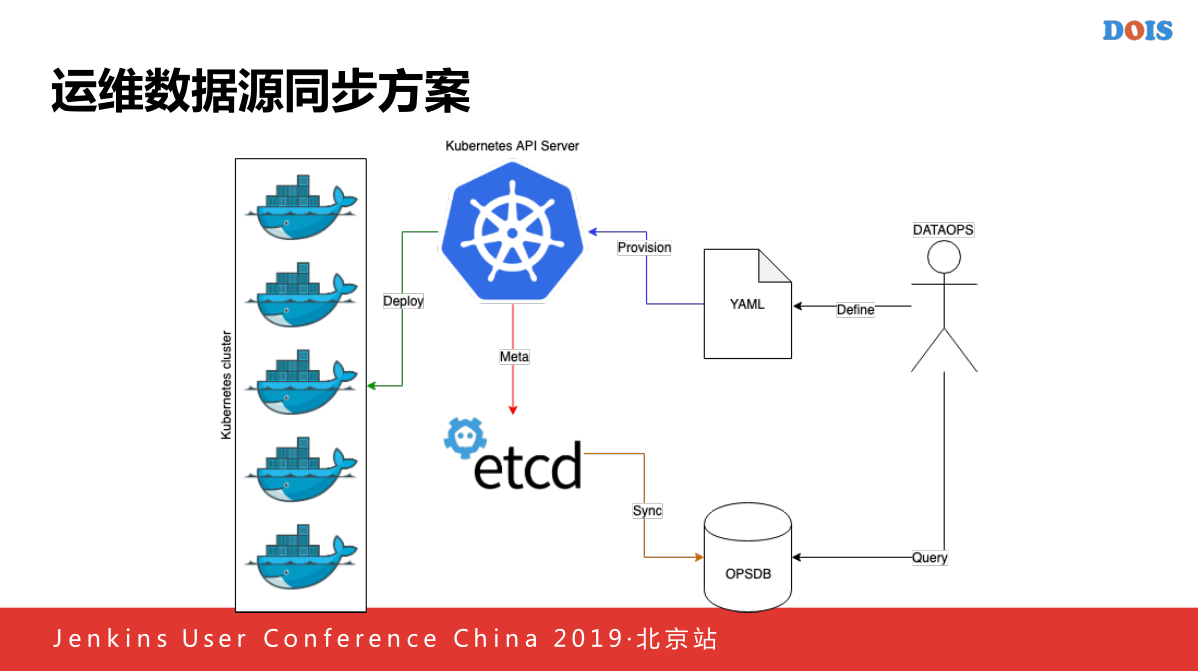
前面的Elesticsearch就相当于给业务方使用,而且使用还有一个问题,就是如果你要加他话,你需要一直加,你不加的话,你需要重启业务方的容器,有些时候业务方没有办法接受这件事情的,接下来是运维的同步方案。
每一个CMBD保存了容器的信息,当我们进行我们需要写一个开始的功能写一个程序,他负责监听所有创建和删除的事件,当发生创建和删除的时候,会读取对应信息,他就是镜像信息,主机信息,机房信息,所有的信息写入到我们的OPSDB上面,当一个容器销毁的时候,将所有的程序删除,因为OPSDB类似于一个资产管理工具,所以我们要保证这个系统里面的数据一定是真实的。
这个是OPSDB上面做的图,上面是OPSM的一个图,主机屏用的是FQDN,下面有创建名,类型是Container,我们把他的主机速度传上去,还有就是镜像,还有就是机房属于哪一个CNA,我们作为历史存下来,因为有些时候,我们没有做到,主要是我们没有做到他们做容器的时候,就是容器的ID不可变,要么就是IT变,或者主机屏不可变,你会发现这个容器,今天要这个,明天要那个,所以后来又做了一个类似于一个同步的东西,所有的事件全部收集到的上面做将来原来识别出现一些审计的部门,同时也会使用审计的时候使用一些功能用来方便审计。
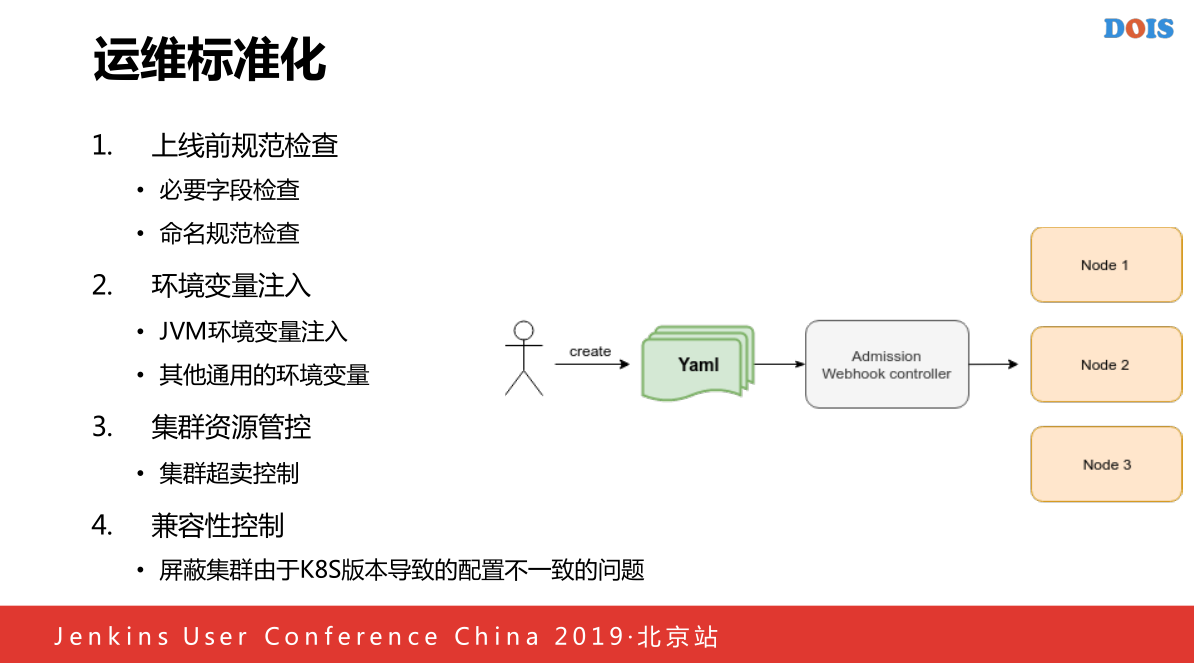
这个是K8S的功能,我们主要做了几点:
一个是上线前的规范检查,就是每一个上线的容器必须存在对应的容器,需要多少的内存,多少的磁盘,多少的CPU,添加之后还会对容器进行归分的检查,因为我们的容器里面每一个都是和去哪儿的APP强绑定的,如果你创建了一个系统,根本查不到这个名字,我们会拒绝一类的创建.
还有就是环境变量的注入,因为JVM相关的程序我们用JVM根据用申请内存做一些JVM相关的,比如大小,进行注入到容器里面,因为本身不支持根据磁盘的角度,所以我们会发现一些问题,一个机器有内存,有CPU,就是建不出容器里,因为他本身的磁盘已经满了,但是他本身没有磁盘相关的角度策略,所以我们实现了一个自己的根据拓展资源,每一个机器上注入他在这上面加入了一个磁盘的申请,加入100个机和200个机,通过Controller加一个我们的磁盘使用的标记,注入一些企业,加入到磁盘的配置里面。
第三点,是集群资源管控,目前我们集群资源管控主要应用于超卖的,比如这里写了超卖1.2的话,我们将当用户一个CPU的时候,将CPU的要求从1变成2,内存也是这样的,这样的话实现了自己内部的一个内存超卖的控制
四就是K8S不一样的问题,我们使用不同的时候,就会发现K8S有一些版本,这个版本叫这个,下一个版本的名字就变了,我们将所有配置不一样的东西留一个统一的口径产生对应的正确的配置。
存储方案,我们主要使用的是lvm,因为公司都有一个比较大的存储,我们倾向于使用lvm,容器创建的时候,就会创建对应的lv卷,挂在Actor方面,一个Deployment,就会在SubPath上挂载,这样导致日志是不可读的,而且数据卷的话,后来做ES云的时候,因为K8SES云出现一个群过小,就会出现单台机器存在一个Statefulset,这样的话如果实使用原始的SubPath这样会导致整个数据的破坏,后来我们自己开发了一个Provision,主要是用来客户做每次创建一个ES集群的时候,或者需要单独数据卷的时候,写一个程序,他本身产生一个PPC,VG卷的信息,还有APPcode的挂载点,到时候产生一个以APPcode开头,后面是一个UID唯一的标识,这样的话可以保证每一个PVC产生唯一的卷的名字,这样不会出现一台机器上相同出现卷一模一样的问题。

容器基础监控我们自己写了一个监控软件,主要是负责监控每一个集群的POD的使用,还有磁盘的IOPS,所以我们还会判断对应的每个应用是否正确的,解析文件,读取里面的相关指标,作为一个技术监控上报到我们的Watcher,主要是由Grafana+Graphite的系统.
右下角就是可以看到容器指标的截图,还有一个问题,在做容器指标的时候,我们之前说过,保证每一个统一性,因为今天原生的没有办法保证统一性的.
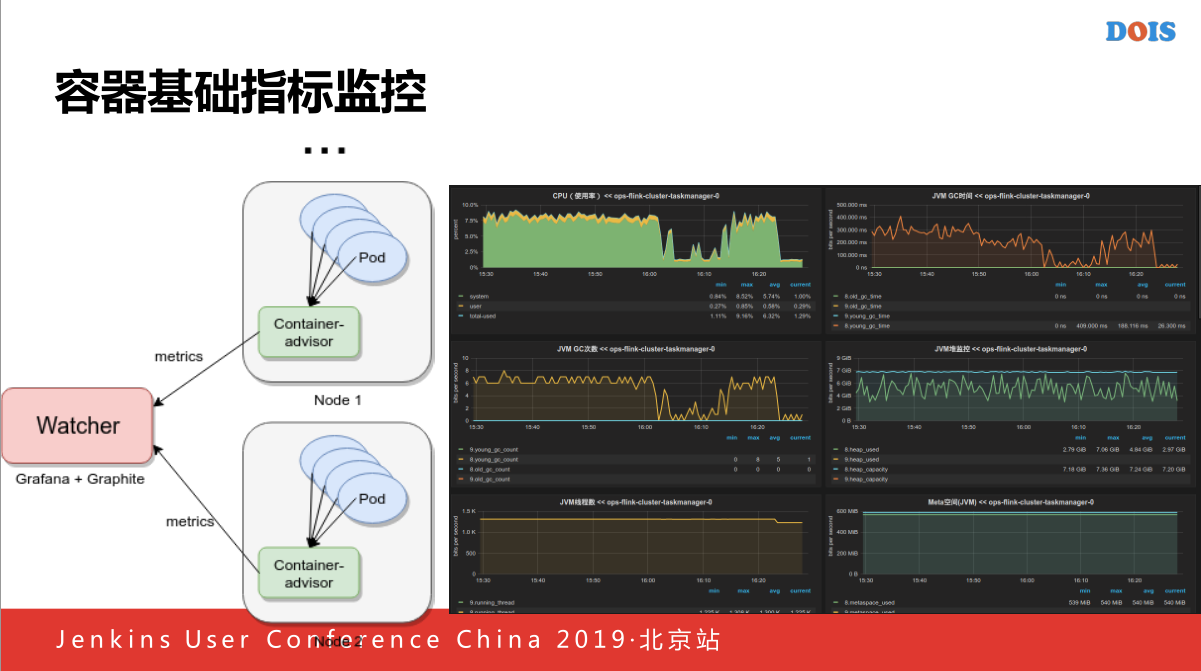
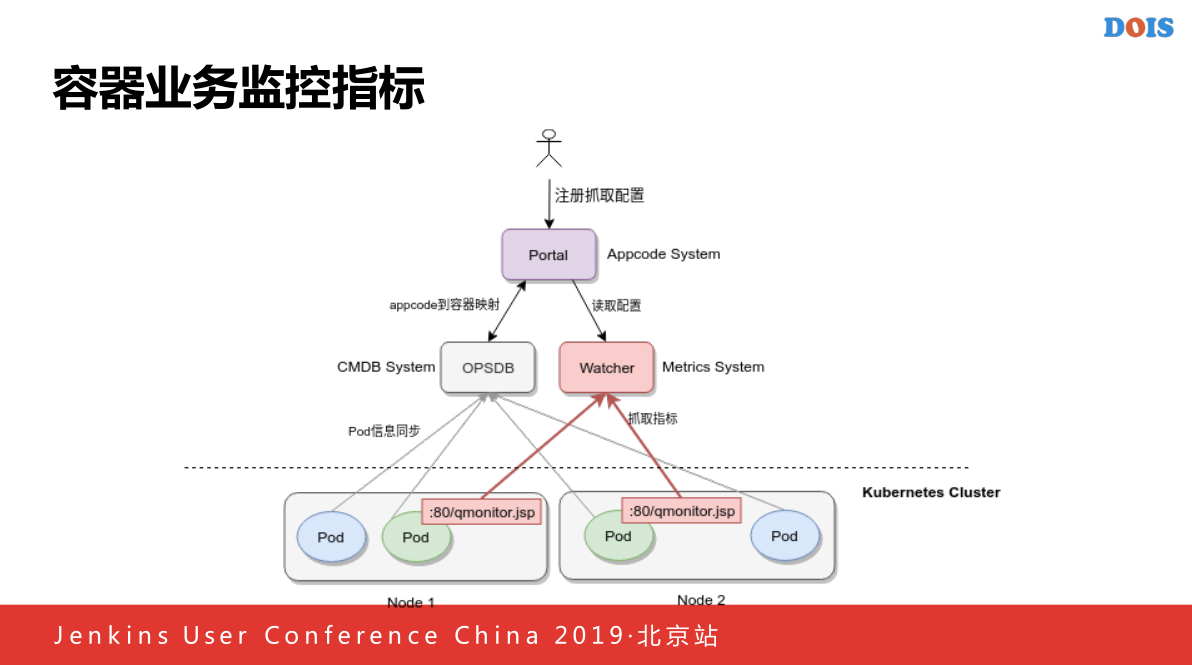
他由于Watcher本身存储原因导致的,假如他本身文件存储的话,如果今天指标要A,明天要B,因为POD的生命周期很短,所以后来做了一次修改,产生一个序列号,通过容器名的不变的方式实现最终达到容器重启之后,他的监控曲线在监控那个层面相对来说还是一个连续的,容器业务指标的监控,容器业务指标通过通过Portal平台上面收集一个业务指标,从OPSDB上面查到,因为收集业务监控是以APPcode接入的他对应的对应的主机是哪些,之后Watcher添加日志的配置,抓到之后主动的访问80/Qmonitor.jsp的指标。
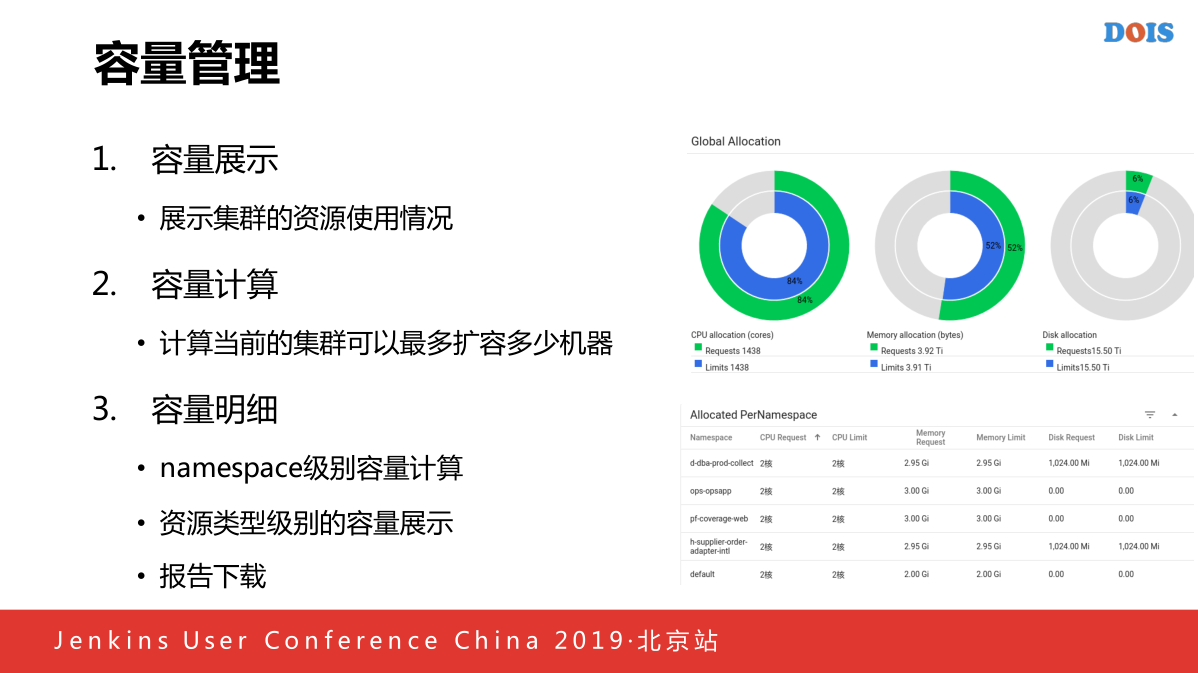
容量管理对于容器来说是一个很重要的功能,比如我要知道这个容器还能扩多少个容器,所以我们自己添加了集群管理的功能,比如展示集群的使用情况,使用了多少个CPU和内存,容量计算,会显示我们当前的集群,4U,8G扩出多少的容器来,我们下面显示出我们每一个APPcode使用了多少个磁盘,可以对应的形式出来,还可以提供一些下载,方便对自然摊销的时候。
3. ElasticSearch on Kubernetes
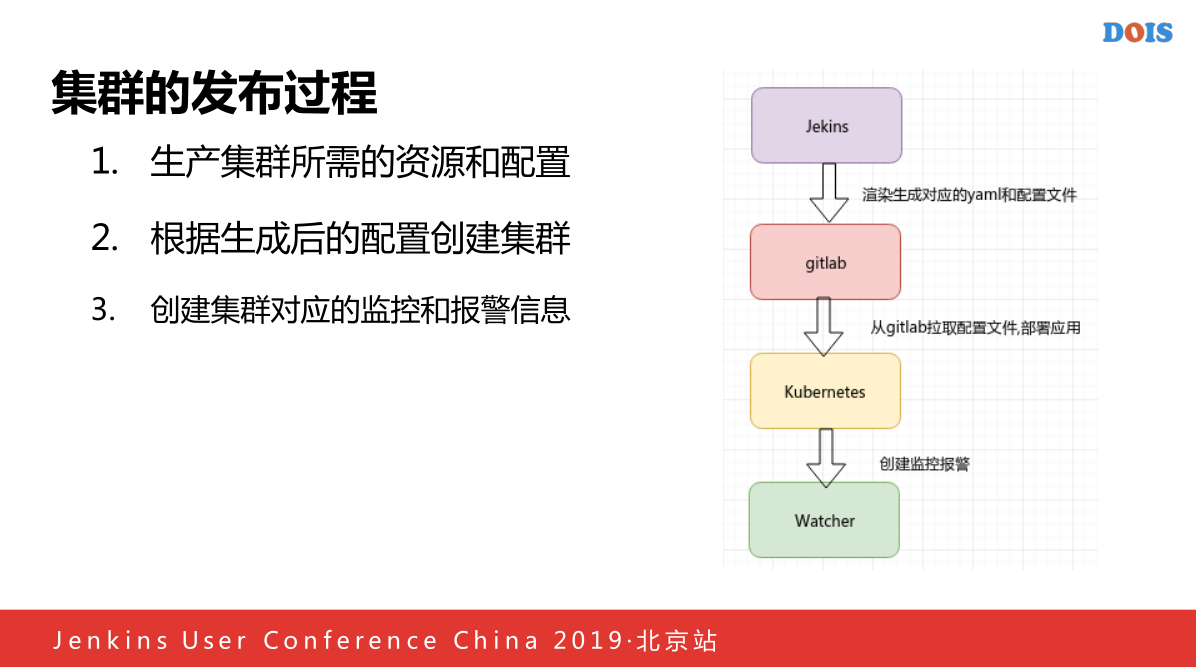
第三点主要讲一下我们现在做的ElasticSearch on Kubernetes的方面,首先我们会通过Jekins发布一个集,发布以后我们的脚本生成根据用户集群名称还有就是多少个数据,多少个磁盘和多少个CPU声称一个对应的配置文件,还有还会生成比如监控,因为我们Watcher通过这个声称,我们还会创造一个项目我们有一个大的Gitlab对应配置列表,对应新建为名的仓库中,之后我们从对应的项目拉取出来文件,ES启功的时候会挖取一个最新的启动脚本,参数等,最后我们还会创建一个对应的监控报警,所有的比如说之前渲染好的Watcher报警模板,监控模板,有一个ES他通过抓取每一个集群进行容器的健康状况等。
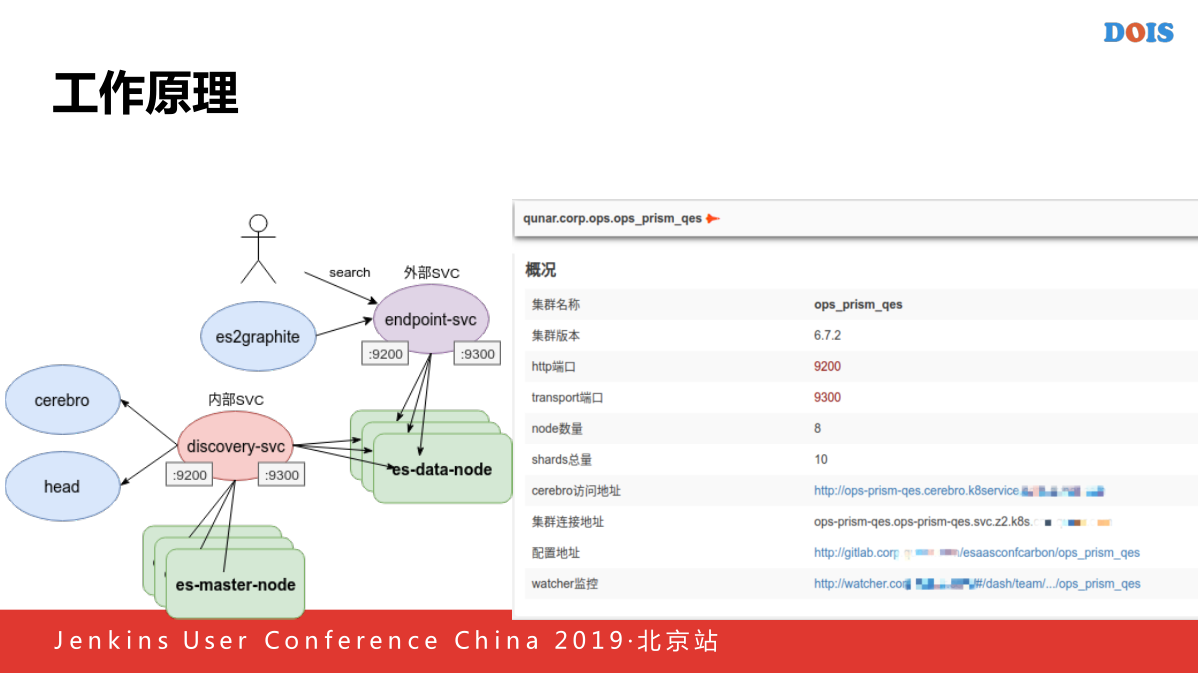
这个是我们现在主要的工作原理,用户首先通过外部的SVC就是前面做的SVC,他是外网可见的,通过这个SVC访问内网的ES,也是通过这个外部的SVC拉取我们对应的数据,将他发送到我们的Watcher指标当,同时还会发布一些查检,他也确通过外部的SVC进行一些运维的使用。
右下是我们现在做的一个ES的管理方式,主要是一个集群概况本身提供一个重启集群,插件还有集群查看日志的功能,他向下面的集群地址也是ES的插件,状态,就是每一个对应的配置地址就是一个仓库,里面保存着容器的ES集群的配置和脚本,他可以跳转到每一个容器对应的监控链,可以看到各项指标,比如QBS,驱逐等等各项指标。
4. 一些生产中碰到的问题
第四个分享一下遇到的问题,一个是无法正常续签证书的问题,因为今年的时候出现很大规模的故障,晚上八点快下班的时候所以容器全部都驱逐出去,经过我们一段排查发现是因为所有的Kubernetes无法正常续签证书,当时是续签一年发现已经过期了,过期以后没正常启动cert-manager导致的,但是理论上来说开启了续签证书,但是看了的原因,最后还是不行,最后通过看代码的时候发现还要加一个配置,但是这上面没有提到,因为一般来说以为只需要加server TLSBootstrap的功能。
第二问题就是被清零的问题,我们之前有一个拓展资源,添加到Kubernetes上面,因为Kubernetes原来添加扩展资源方式本身来说是一个很临时的方式,他通过Patch的方式,那种方式对于我们来说可能太重了,只提供一个Patch的方式,当你重启之后,扩展资源立马清零,所有的资源就会被驱逐出去,后来我们发现6月份已经有提交这个PR会解决这个问题,他会保留所有的扩展资源,大家紧急的话可以进行Patch,一定快,还会第一时间加很多不满足资源的一些任务驱逐出去,我们的方式主要代码加了一个参数可以支持Kubelet的方式加到Kubernetes里面。

