@gaoxiaoyunwei2017
2018-04-26T07:40:22.000000Z
字数 4142
阅读 1841
AIOps 亮剑网络运维-ISP流量异常检测
毕宏飞
作者简介
谭学士
前言
感谢高效运维社区提供这样的平台,我是网络工程师,经历了360的架构变革过程,我个人的技术转型开始更专注网络的监控、自动化运维、网络可视化和AI应用上。我今天的分享主要有下面四个部分:
1 项目背景
2 时序序列算法
3 机器学习
4 当下与未来
一、项目背景
聚焦网络的项目,这个项目是如何在DC中ISP出口发现流量异常,通过流量异常能自动发现,自动定位,最后找出哪些业务,通知业务的过程。

我们公司的业务拓展到搜索、智能硬件、手机、行车记录仪、儿童手表、小水滴,也出了扫地机器人,也有360云,虽然公司没有BAT体量那么大,但业务方向麻雀虽小五脏俱全,也积累了很多云方面的经验,公司还有一些在娱乐方面的业务。

OUR OPS ,月活用户的数据不太准确,这是我们去年PC端的月活,移动端还有3.5亿,加起来差不多有8.65亿的月活用户体量。运维数据中心在大陆有120个,香港1个,洛杉矶1个,运维ISP带宽达到3.5T的规模。
面对这样大规模的网络情况,我们对业务中断零容忍,要洞察网络中的任何异常。虽然业务会切换,但对于某个用户体验上会有一定的下降,我们希望能实时的知道现在网络中DC的出口,流量上有没有异常?出现了什么样的异常?
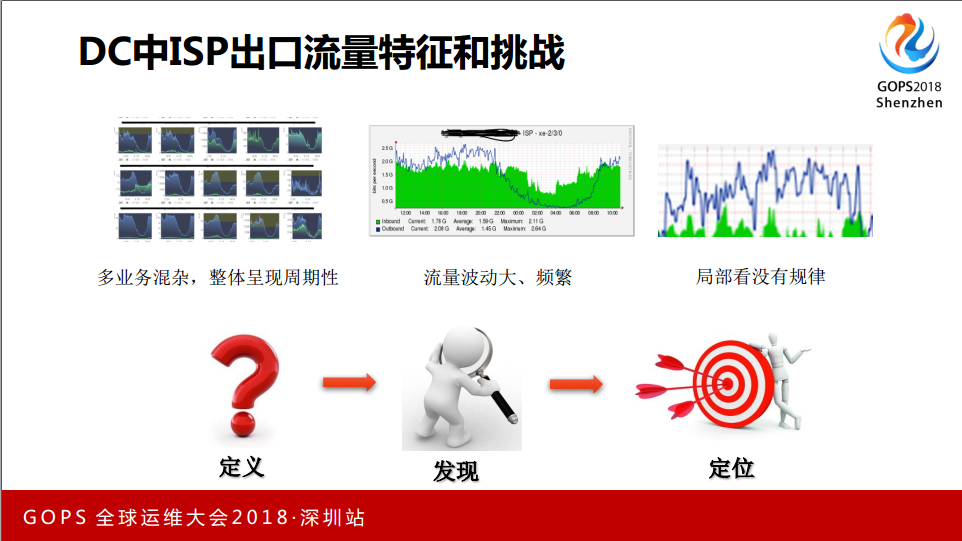
这是我们DC流量出口图,整体上看有早晚高峰的趋势,放大看有一些上下的波动,而且波动比较频繁,局部再放大看没有什么太大的规律。DC不是一个单独的业务,可能是综合性的,很多业务都在流量出口上跑,带来的问题是我一个告警出来,不知道是哪个业务出现的异常。对于我们来讲可能是一个黑盒子,就知道异常发生了,怎么定义异常也是比较挑战我们的。
定义到自动发现,再到我们定位它到底是哪个业务,这是面临的挑战。如果你最后的定位找不到哪个业务,你告诉人家也是没意义的,工程师大半夜起来说我要去看这是谁的业务,给业务打电话,说我今天晚上有一个APP发布,流量高一下是正常的。通过定位应不应该告知这个业务,前面做的很多工作是没有意义的,网络监控也用了一些传统的,传统的监控都是对于流量阈值的监控。
去年的时候我们做了大胆的尝试,360所有的网络算下来有几十万个POT,我们把所有的流量数据都做了时序化的存储。每个POT存储的时候,关注30维以上的数据特征,要知道这个POT是哪台服务器,是哪个域名对应哪个业务负责人,属于哪个地市、哪个区域,因此我们打了很多标签。
二、时序序列算法
拿到数据以后,我们可以用比较时尚的时序序列算法和机器学习的手段对数据进行判断是不是异常,有一些平稳性不到位的数据,我们也会做一些处理。
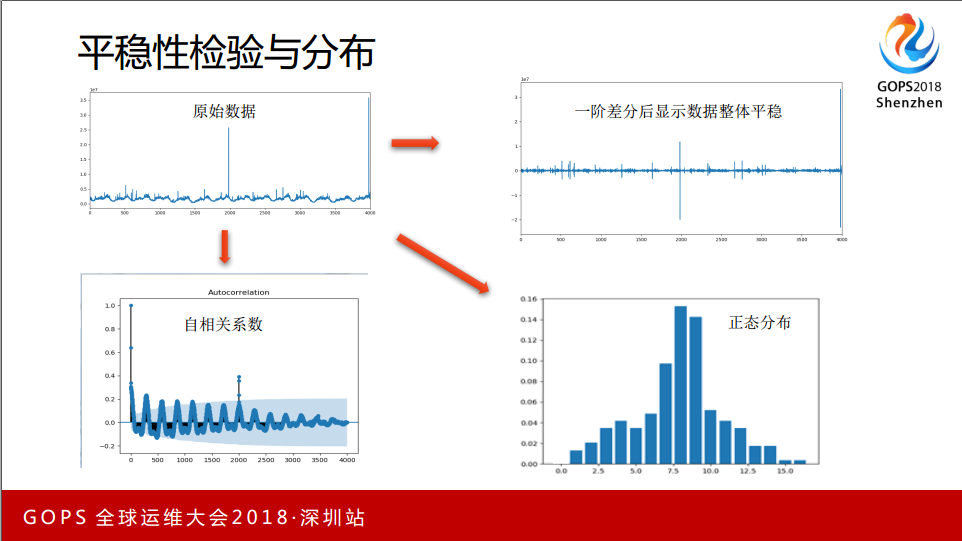
原始数据进行一些拆分,可以看到基本上是0上下进行浮动的区间,算一下自相关系数,在正负0.2的范围,再看一下分布是属于正态分布。
2.1 3-sigma
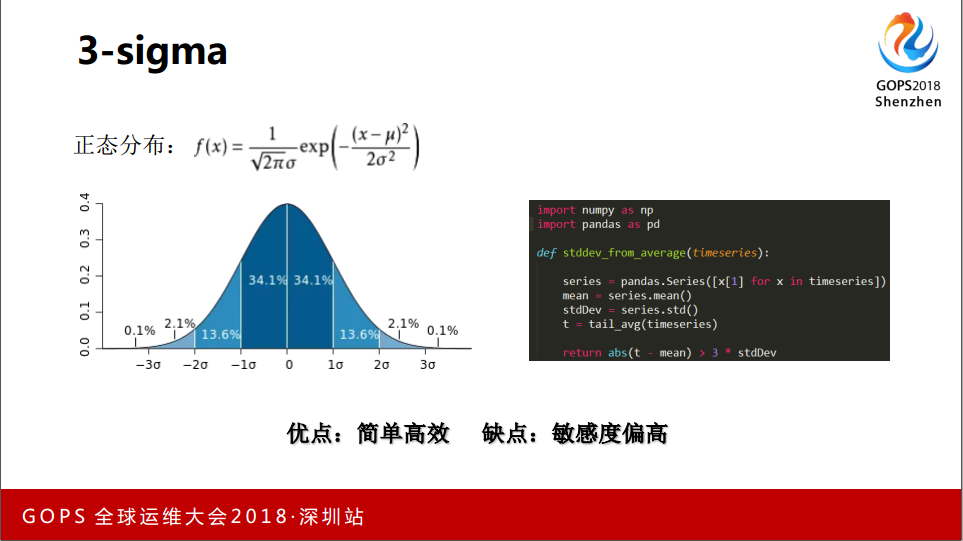
通过校验的数据、平稳的数据我们可以应用一些算法,大家一看这是正态分布的图,横轴代表了数据分布的情况,每个格子代表标准差的范围,这边是小于三倍的标准差。拿到一个数据以后,这个数据解决时间的序列数据,经常有在均值上下浮动超过三倍标准差的情况,非常频繁。
2.2 EWMA指数加权移动平均
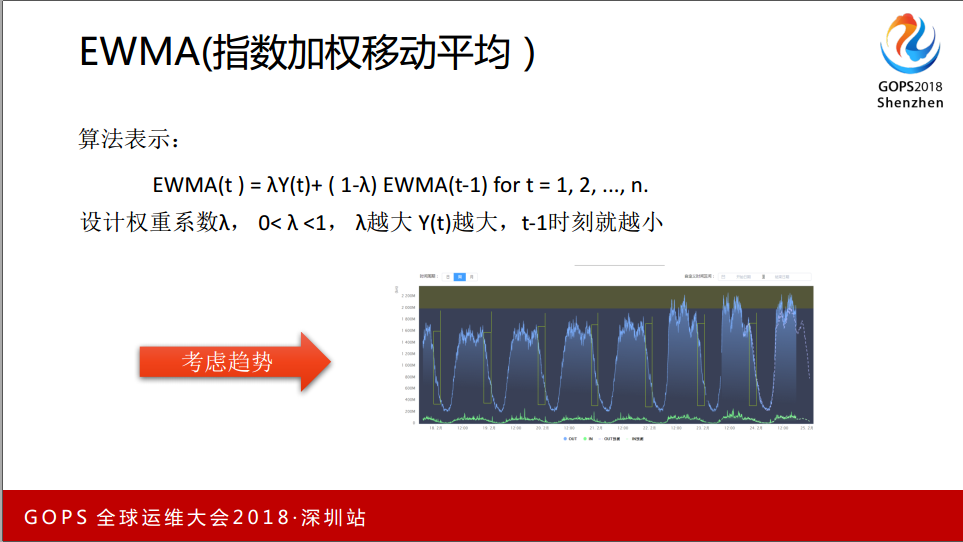
EWMA指数加权移动平均,这个算法的公式,引入了一个权重参数,这是一个加法。考虑趋势,这是一个数据中心一周的流量图,在当前时刻选一个时间窗口做一次EWMA,每天的数据都做EWMA,最后认为当前时刻经过EWMA平滑可信的数据,再根据趋势算一次EWMA,相同时间戳窗口的趋势。

在数据中心流量图这块选两个时间,t时刻和t-1时刻,再取两个时间窗口,分别取均值,用后一个窗口比前一个窗口再比绝对值再乘百分之百,就是波动的比例。方法二采用时间窗口可以有效吸收一定的瞬时波动,也牺牲了敏感性。
2.3 动态阈值
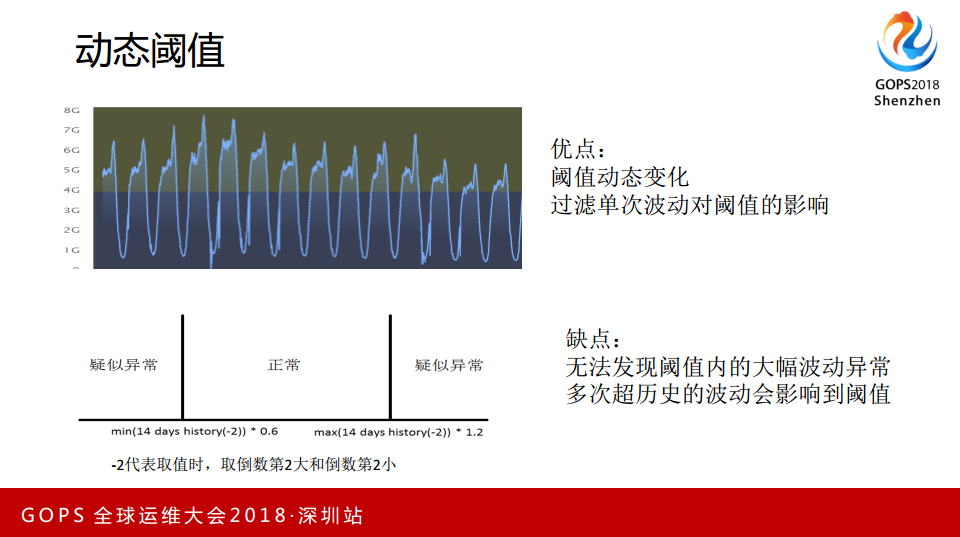
如上图有一个正常的区间,两侧异常的区间,把14天的历史数据倒数第二小的乘以60%,倒数第二个大的乘以1.2就认为它是异常,看起来缺点很大,虽然实现了阈值的动态,经过几次波动以后会发现阈值拉高或是降低了。
2.4 小流量监控优化
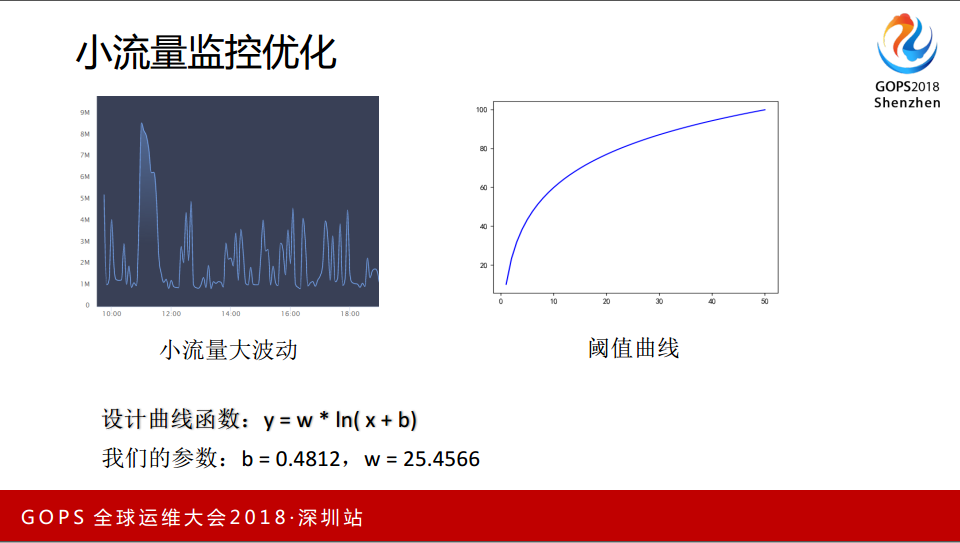
这是我应用之后做的优化算法,应对一些小流量时的处理。X轴是时间,Y轴是大小,大小的单位是1兆到9兆,9倍的变化,1个G到9个G,都是90%的突发,但是意义是不一样的。希望通过一条曲线,能动态的有些容忍度,曲线在流量很小的时候很陡,越往后的时候曲线越缓慢,数学比较了解的人知道是用对数函数实现。y=w*1n(x+b),b一开始放在外面,放在外面的效果不如放在里面的好,放在里面的影响大一些,w表现斜率。
四个算法同时应用的时候,对于平稳的数据占DC出口的80%很OK,用算法解决是很好的。还有一种数据,用时间窗口切它,在一个里面很难切出相似的情况,这种情况下比较难优化,也比较头疼。
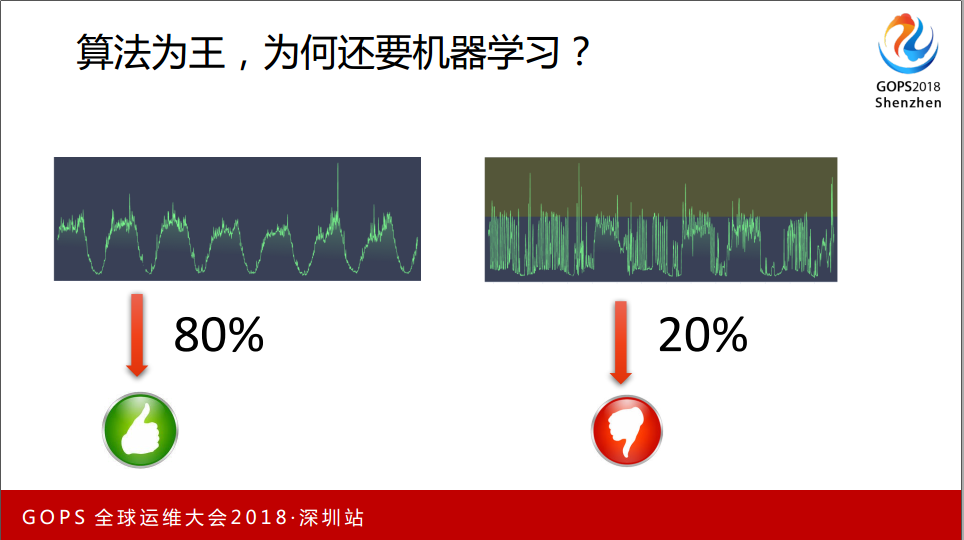
三、机器学习
面对上面说的比较难优化的情况,工程师会想办法解决它,我们看到了当前流行的一种方法-机器学习。
3.1 机器学习架构
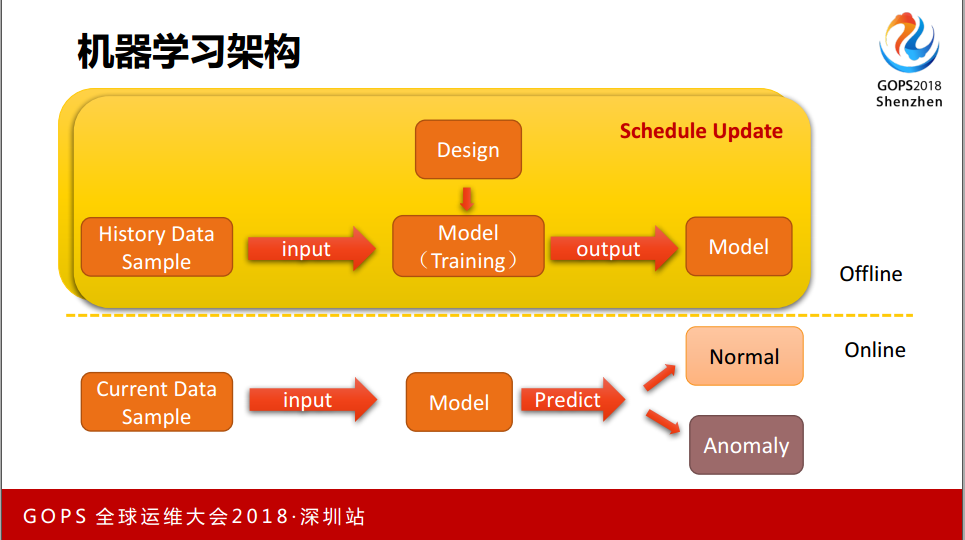
考虑到机器学习,看一下架构,希望通过一些设计的 Model ,不是上个月和这个月是一样的,有可能业务变化的,上个月没有频繁的抖动,这个月真的变了。它的发布方式和用户的架构改变而造成流量图是在变化的,上个月的趋势是这样一条曲线,下个月就变成来回抖动的情况。拿到训练后 model ,输入模型以后,模型能告诉我是正常还是异常的,上面的部分因为训练需要一定的时间,也不满足实时处理的要求,我们把它放在 Offline 上进行。
3.2 学习方式对比

学习方式的选择也做了一些尝试,先说一下有监督的机器学习,一般要求正负样本的比例是1:1,而且有人工标注,通过标注可以有效的做算法提升,实现整体的提升。无监督是不需要考虑正负样本的比例,不用做标注能自动从信息中学到一些有用的信息,但是也需要一些调参,这个得根据工程师的结论不断的手动调整这些参数。
3.3 特征提取
输入一些特征和原始数据的信息,我们怎么抽取这个特征呢?
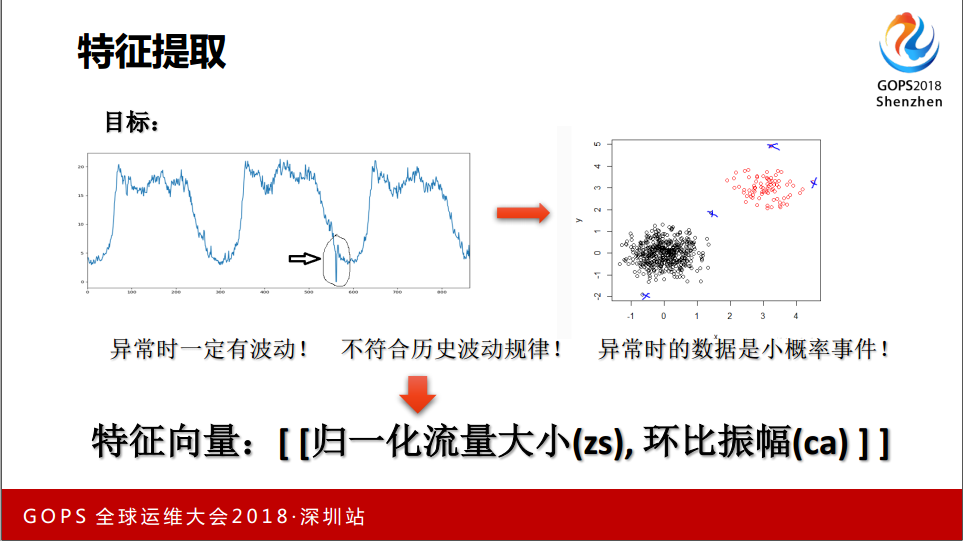
这两张图的目标是通过这种数据,一下子接近0的数据,实际上是分类的模型,要把它从正常的数据中抽取出来。这是两个正常的,蓝色的是正常的,离得比较远的是离群点。
特征出现的时候一定是有波动的,平稳就不叫异常了,如果这个数据时时刻刻都是这样波动,我们认为就是正常的,异常的时候一定是小概率事件。特征向量,我们也做了一些尝试,最终是数据归一化流量大小,我们是在分位数的概率分布,在这个分类数波段一般分布的概率是多大,还用了很多同比周期的数据放在里面,效果最后测出来总不太理想,目前还是采用直接拿大小和正负作为特征。
3.4 Model选择
接着我们需要放在Model的选择,一种是经典聚类 K-Means ,一开始有一个数据集,要定义分几种类别,然后进行计算,设置最大的循环次数,输出样本集的中心点,每个分类的中心在什么位置,每个数据进行打标,它是什么样的情况,下面是循环的计算,最后计算出我的中心点的过程。
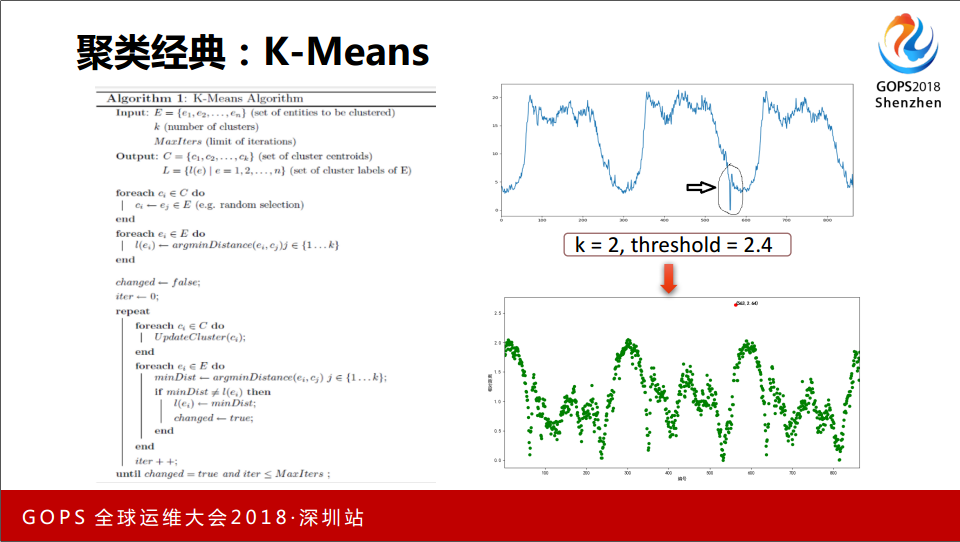
计算出中心点之后怎么知道输出异常呢?往往需要在这里面设置一个阈值,通过最后的训练我拿到的是每一个类别簇的中心点,要判断异常的时候需要设置一个阈值,超出和中心点的欧式距离,大于这个距离多少我认为它算是异常。我们测试的时候阈值设置2.4完全可以分开,绿色的部分都是正常的数据,波动一看就是一个红点。
接下来分享的是独立森林,算法来自周志华在2011年 Isolation-based Anomaly Detection 通过切蛋糕的方式看谁先被切出来,随机切100次,几次就把B切出来了。A分了很多次还是分不出来,最后才分出来,随机建立一些树的方式,把小的放这边,大的放这边,最后看每棵树里变的次数,越短代表越异常。
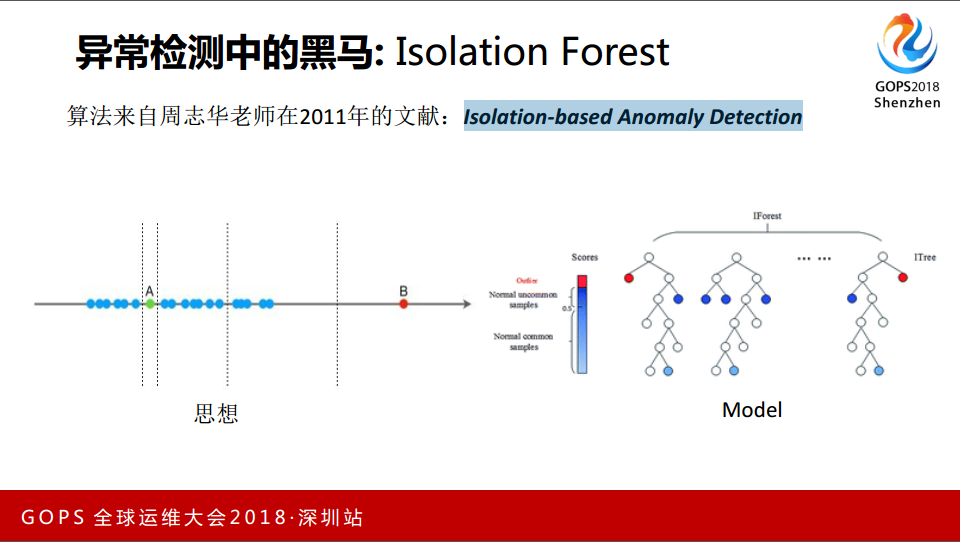
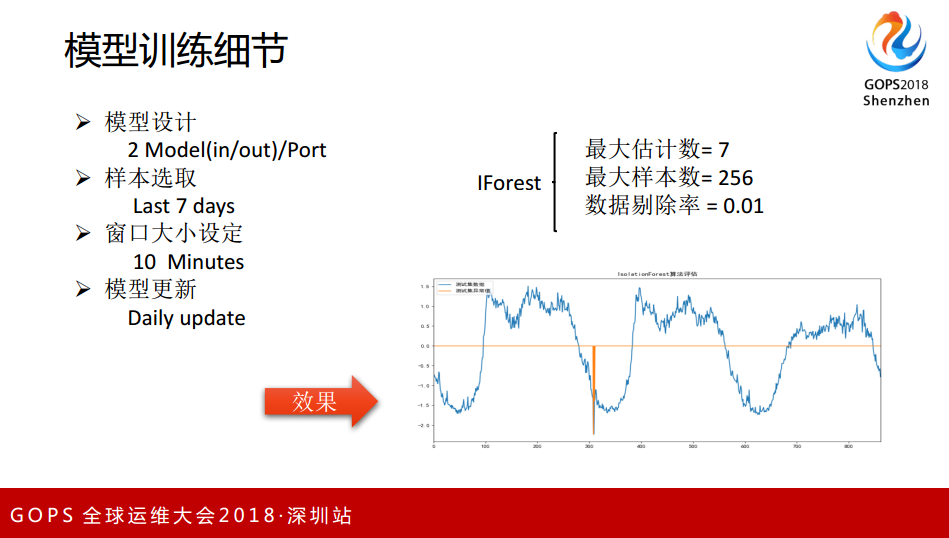
比较两个方法,目前我们拿到的数据特征还是比较少,之前同比和环比的特征还是比较少。我们做分类的时候,如果特征比较多的情况下 K-Means 比较好。分类的设定 K-Means 要剔除一些异常的样本, Iforest 不需要。在易用性上,我们认为 Iforest 更好一些,最后我们选择的是 Iforest 。

每个业务中心数据的场景不一样, INPort 和 outPort 也不一样,我写PPT的时候是360个 Port ,模型是720个,也就是 Port 的方向就是一条曲线,每个曲线对应一个 Model ,窗口大小选择10分钟,模型更新是每天更新一次。
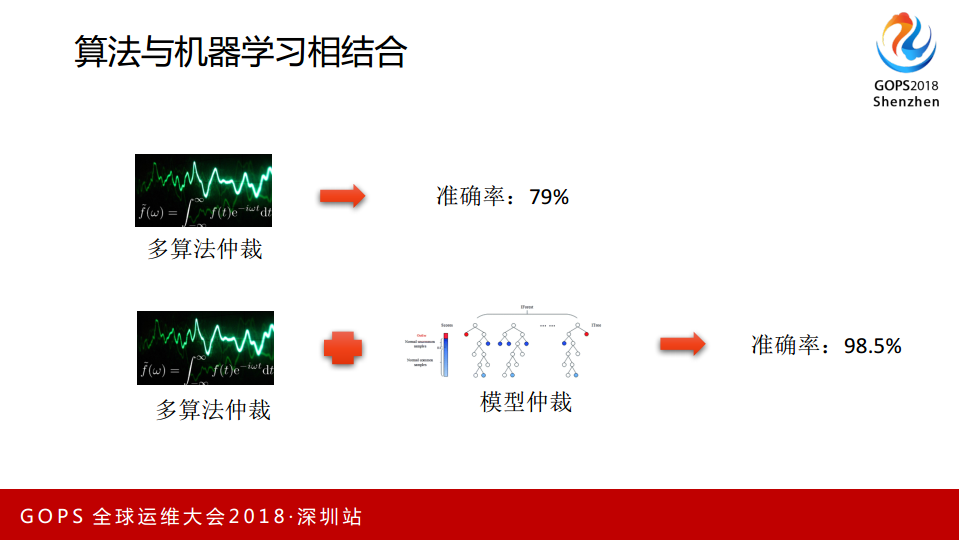
如果说我用前面四种方法进行仲裁,仲裁的概念就是多种算法进行投票,四种算法中符合两个以上出现异常,算法就是异常,这种情况下准确率比较低。多种算法仲裁的情况下,再加上机器学习,最后 Model 的判令,准确率能提高到98%以上。
四、当下与未来
异常检测可以检测出来了,但异常出现的时候,如果不能定位是哪儿的业务做这个意义不是很大。
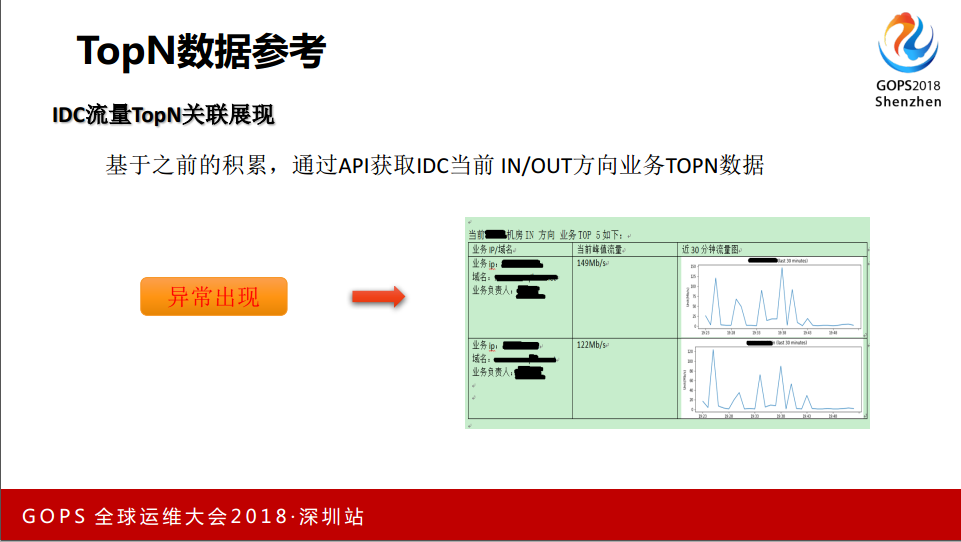
基于之前的积累,我们把数据中心在出口上进行分割,流量镜像可以获得完整的数据,写了一些C语言的开发,能够知道这里面哪个IP跑得比较高,哪个跑得比较低,出现异常的时候,告警里面可以调用API拉一下 TopN ,突发的时候看 TopN ,陡峭的时候是看不了的。
前两天我们刚改进一版,知道哪个业务的哪个IP,这块变成的协议类型,知道是TCP还是UDP类型。找到对应的业务人,直接给业务人发邮件,至于他处不处理是业务说得算,如果这个异常突发2个G一定要通知我,我们再给业务打电话。
还有一种判定方法是 Pearson 相关系数,两条曲线的相似度,如果小于等于0.3是不存在线性相关,0.3到0.5是低度线性相关,0.5到0.8是显著线性相关,大于0.8是高度线性相关。
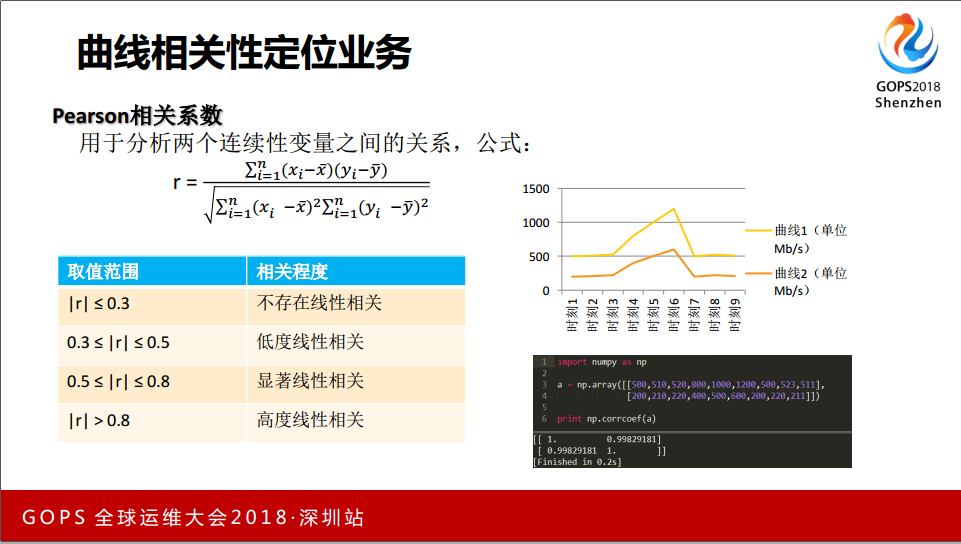
出口流量出现曲线波动的时候,我们要抓取IDC相关 Port 的曲线出来。我们做了千里眼,平台上一点会帮你算一会儿,不用人去算。真的出异常有一个很大的波动,这是哪个业务?可能看流量图,一个图一个图去点,应该是这个业务,点一下千里眼功能,所有的 Port 过一遍,有可能是这类业务。
网络发展了几年以后,我们把一些监控项做得非常细致, Port 百分比,流量丢包、品质监控等都做了。这些监控缺乏合理的关联,希望通过图谱的方式把它存起来,当发生故障的时候能通过关联找出最根本的原因,或是携带出的关联关系,一眼可以看出是什么原因,也是想在故障预测方面做一些内容。
在发现故障之后能不能有一个行动预案,最后我们通过一些方式提前预案设置好命令,能不能自动的做一些处理。
