@gaoxiaoyunwei2017
2017-10-26T10:01:35.000000Z
字数 2741
阅读 1198
基于分布式数据库的全文搜索系统
刘策
文档修订日志:
| 版本 | 修订时间 | 修订内容 | 修订人 |
|---|---|---|---|
| 1 | 2017-01-20 | 初版 | 江和慧 |
目录
前言
设计思想
分布式表设计
架构
文档索引过程
文档搜索过程
例子
例子假设以下信息
索引
搜索
总结
前言
开源的全文搜索项目中,lucene应该是最流行的,实际项目中必须是多个lucene共同提供服务,所以在lucene之上,分布式的全文搜索项目(如solr, elastic search)大展拳脚;但他们有个缺点,将文档和文档生成的单词信息放在同一个lucene中,搜索的时候需要到所有的节点上去搜索才能得到完整的结果;基于此,文档和单词信息的存储策略需要调整,经过探索,基于分布式数据库的全文搜索系统应运而生,此系统核心在于存储的改进.
设计思想
使用分布式数据库存储数据,而非lucene,主要包含用于存储文档的文档表,存储文档经过分析之后的单词表,存储单词基本信息的语料库表
文档表和单词表使用不同的均衡字段实现精确定位,文档表使用文档id,单词表使用单词id
使用sql的来实现搜索条件的与或非等逻辑
分布式表设计
| 表的描述 | 字段描述 | 均衡字段 | 备注 |
|---|---|---|---|
| 文档表 tab_doc | doc_id 文档id doc_url 文档地址 doc_download_content 下载的文档内容本身 doc_content 已经分析和存储的文档内容本身 doc_download_status 下载状态,0表示未下载,1表示正在下载,2表示下载完成, doc_downloadtime 下载完成时间 doc_parse_status 分析状态,0表示未分析存储,1表示正在分析存储,2表示分析存储完成 doc_parsetime 分析完成时间 | doc_id | 存储文档的信息,文档的内容可以作为文档是否新增或者更新的依据,文档时候可以重新获取到可以作为文档是否删除的依据。 |
| 单词表 tab_term | term_id 单词id term_name 单词 doc_id 单词所在的文档 term_freq 单词的频率 | term_id | 存储单词的信息 |
| 语料库表 tab_corpus | term_id 单词id term_name 单词 term_idf 单词的逆文档频率 | term_id | 存储语料库,term_name进行了冗余. 可以定期同步搜索引擎的语料库, 也可以使用自己本身这套系统定期生成,文档总数就是tab_doc的文档数,单词的文档数就是单词表中某个单词的记录数, 无论哪个都得定期的更新或者同步, 到底使用哪个依据使用情况来决定. |
其中tab_doc的状态字段意义:
doc_download_status
为0: 表示初始状态,还没有开始下载;
为1 :表示正在下载,就是说某个线程查询时,这个值为1,则跳过下载;
为2 :下载完成的时候,更新记录,表示下载完成;此时下载内容,下载时间也会更新。
doc_parse_status
为0 :表示初始状态,还没有开始分析存储;
为1 :表示正在分析存储,就是说某个线程查询时,这个值为1,则跳过分析存储;
为2 :分析存储完成的时候,更新记录,表示分析存储完成;此时分析存储内容,分析存储时间也会更新。
架构
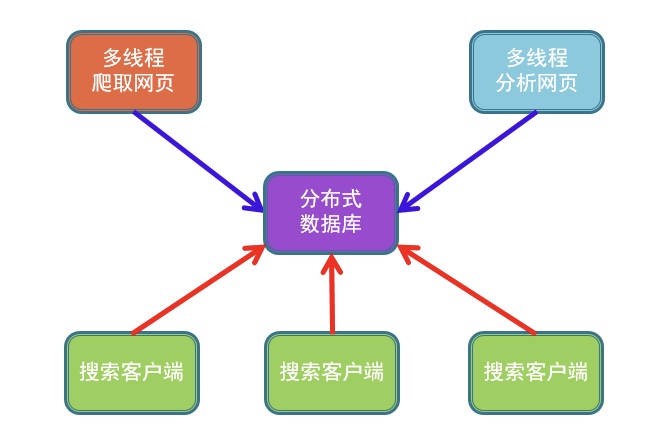
文档索引过程:
包括下载和分析存储
1、多线程下载过程:
根据文档地址得到文档id,查询文档表,看是否有这个文档id的记录
没有,插入初始记录(文档id,文档地址,空,空,0,空,0,空),(标识11)更新doc_download_status=1,开始下载,看下载是否成功
成功,更新doc_download_status=2,下载内容,下载时间也会更新
失败,更新doc_download_status=0,下载内容,下载时间不会更新
有,查询doc_download_status的值
0,从(标识11)开始
1,跳过这个文档的下载
2,看下载时间是否是 定时更新下载的周期 (如一个月)之前
是,从(标识11)开始
否,跳过这个文档的下载
2、多线程分析存储
查询文档表中的记录,查询 doc_parse_status 的值
0,(标识12)更新 doc_parse_status=1,开始分析存储,看分析存储是否成功
成功,更新 doc_parse_status=2,分析存储内容,分析存储时间也会更新,然后将分析存储的单词结果(单词id,单词,文档id,单词频率)插入到单词表中
失败,更新 doc_parse_status=0, 分析存储内容,分析存储时间不会更新
1,跳过这个文档的分析存储
2,看分析存储时间是否是 定时更新分析存储的周期 (如一个月)之前
是,从(标识12)开始
否,跳过这个文档的分析存储
文档搜索过程:
1、对用户在搜索客户端中输入的关键词进行分词,得到单词和单词之间的逻辑关系(即与、或、非、及三种逻辑运算的任意组合),针对每个单词到对应节点的单词表中搜索;
2、根据单词表的文档id和单词逻辑关系计算结果文档id的集合,并且根据文档id提取文档内容;按照文档id进行分组,所有单词的频率逆文档频率之和构成文档的得分(为了说明清楚,得分的计算方法比较简单),文档按照得分从高到低排名;其中:单词的频率逆文档频率为单词的频率和语料库中单词的逆文档频率相乘结果。
例子
例子假设以下信息
节点数为100,编号从0到99
爬取的文档数为1000万
语料库是基于100亿个文档建立,共建立1000亿个单词的信息
文档的id通过使用文档地址的md5,取md5的4个长整数之和,作为文档的id
单词的id通过计算单词的md5,取md5的4个长整数之和,作为单词的id
为了示例,选择3篇个文档和8个单词作为演示用
文档的id和主要单词的id
索引
文档表的数据如下:
经过分词,统计单词的出现次数,得到单词表的数据如下,(出现次数为0的记录实际不存在,仅为说明)
语料库,收集的文档数10亿
搜索
例如用户输入 “ 机器学习开源 “
第一步对用户输入,得到两个单词和单词之间的关系
机器学习 并且 开源第二步对每个单词进行查询,得到如下的记录
第三步,根据单词之间的关系合并文档,并且计算每个文档的得分(得分=每个单词的得分之和,每个单词的得分=出现次数*逆文档频率)
第四步,根据文档id查询文档内容,按照得分从高到低返回给用户,并且搜索词高亮显示
总结
目前的流行框架(包括solr,elastic search)数据是存储在倒排表中(比如lucene),并且是按照文档分布在不同的index实例(或者lucene实例,机器节点),所以搜索词必须到所有的节点上查询;基于分布式数据库的全文搜索系统核心就是为了解决这个问题.
这个方案数据存储在分布式数据库中,因为文档表和单词表使用了各自的均衡字段,所以查询搜索词的文档会定位必要的节点,查询文档的时候也可以准确定位节点,提高了性能;
这个方案剥离了下载,分析,存储,查询模块,使得可以配置各个模块,增加了灵活性。
