@gaoxiaoyunwei2017
2018-05-22T07:18:46.000000Z
字数 5282
阅读 1778
阿里巴巴规模化混部技术演进 --- 蒋玲·阿里巴巴
豆沙包
作者简介
蒋玲(玲昕)
阿里巴巴-系统软件部-技术专家
大促自动化备战产品负责人
电商规模化混部项目负责人
大家知道阿里巴巴集团ER侧,我们做了产品化的设计,包括阿里巴巴最近谈到的弹性平台,希望做一键的产品。我今天的分享从以下四方面阐述,重点在前面两个:
第一,阿里巴巴混部探索简介,这在行业内比较新颖,体量达到一定规模的公司才会研究这个技术;
第二,混部方案及架构,我们在做混部的方案和架构,更面向运维方面的架构提炼;
第三,混部核心技术,我不会做太多的展开,只是给大家做启发;
第四,未来展望。
一. 阿里巴巴混部探索简介
混部背后的思考和出发点源自于不断增长的业务和资源成本,我们要用业务资源堆业务需求,还是不堆,损失用户,二者之间是平衡的问题。
1.1 为什么做混部?
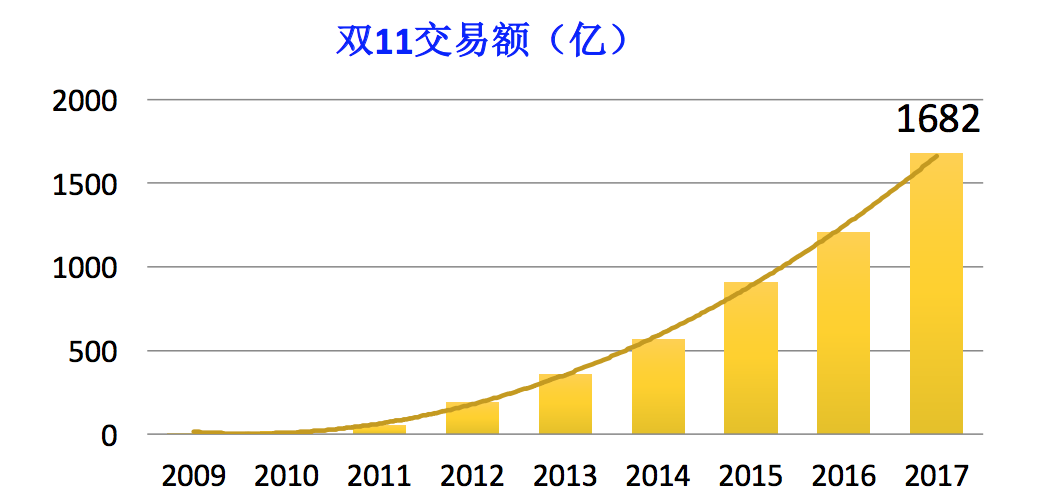
上图这些数据在运营商有披露,2009年开始做双十一活动,这是交易额,曲线增长图比较漂亮,但是让技术人员和运维人员比较痛苦。这张图给的是交易的曲线,相信业界同行有做电商平台,大家知道我们做促销活动,压力往往来自于开卖的第一秒。
阿里巴巴在线业务的双十一零点峰值流量,秒级交易创建量跟这张表基本吻合。从2012年往后的年份开始,基本是双倍。可以看到在线侧发展如此快,主要跟我们促销活动密不可分。
当前,大数据存储KPB级、日均百万级任务。业务在增长,现在问题在于在线型业务和离线型业务,在基础设施层储备了大量的资源满足此业务的需求。这两种业务有很多特性、不一致和产生的不一致,需要有独立的数据中心支撑。大家的业务板块不一样,有不同的方向。万台物理机,如此大体量,每个数据中心都万台以上级别。
虽然我们有这么多机器,储备了这么大的资源,然而线上表现并不乐观。我们在线业务数据中心平均资源利用率日均仅在10%左右。
正因为这些背景条件,我们探索了混部技术的方向。我们分析不同的业务特性,发现有些业务表现出资源复用的可能性,尤其是峰值复用的可能性,这是混部技术的过程。
1.2 何为混部 ( Co-location )

不同类型业务混合部署(资源整合),如果我们仅仅把两种业务放在同一台机器上,并没有太大的价值。如果一半归你,一半归我,整合两个数据中心,这不是混部的最大价值。
混部最大的价值在于通过无中生有的方式,让数据共享出现竞争,优先保证该保证的人。
我们希望通过调度和隔离的手段进行资源共享和竞争,我们的核心目标是保证不同服务质量要求的业务。中间是原生业务,里面用了大部分资源。现在混部要做的是给你一个机器,把所有业务放进去,这是无中生有的混部技术的本质。
1.3 在线离线混部

在线型业务,在混部技术里主要描述的场景是交易型业务、支付型业务、浏览型请求。在线型业务的特性是实时性,对实时性的要求非常高,以及不可降级。如果你慢慢买,让你等半天,你会离开。让你重试,你也会崩溃。在线型业务,尤其像我们做电商的,趋势非常明显。伴随用户作息时间,白天高、晚上低,白天买买买。电商平台比较大的特性是日常流量相对大促而言并不高,大促当天的秒级创建是平常的百倍以上,它具有很强的时间场景性。
离线型业务,开始讲的是计算业务、算法运算、报告、数据处理等业务,业务类型相比于在线而言,可以称之为时延不敏感,它可以等待一定的时间,大家提交的作业和业务,本身的处理时长在分钟级以上,甚至有小时级、天级。它可以接受重试,我们更关心的是谁帮他重试。用户重试不可接受,系统帮你重试,用户是无感的。时间场景性没有在线那么强,白天比较低,凌晨比较高。大家提交一份作业,凌晨跑,第二天早上收报告。因为这些特性,我们从信息的获知上可以看到,在线业务明显具备更高的优先级和资源抢占能力。这是混部的背景信息。
阿里巴巴在做混部探索的历程

阿里巴巴在做混部探索的历程,2014年提出混部技术;2015年做线下测试和原形模拟;2016年大概上200台机器,让公司内用户做小白鼠,第一批用户跑了一年时间。内部用户适用,线上落地有效后;2017年生产环境小规模混部,达到数千台物理机级别。我们面向外部用户,也支撑了刚刚过去的双十一;2018年,我们希望是规模化铺开的一年,我们希望技术本身带来收益,我们希望打造万台体量的级别。
阿里巴巴规模化混部成果
- 混部规模达数千台,经历双11交易核心场景验证;
- 在线集群上引入离线计算任务(在离线):日常CPU利用率 10% -> 40%;
- 离线集群上部署在线业务(离在线),支撑双11大促数W笔/s交易创建能力;
- 混部环境下对在线业务服务干扰影响小于5%;
有一个说法,在线混部和离线混部,谁给机器,谁就是老大。离线给机器,在线跑交易。我们交易创建秒级的创建量,官方数据是37.5万笔每秒。混部集群做到万级每秒的交易体量,用离线资源支撑。
节约这么多资源,是不是经常挂?
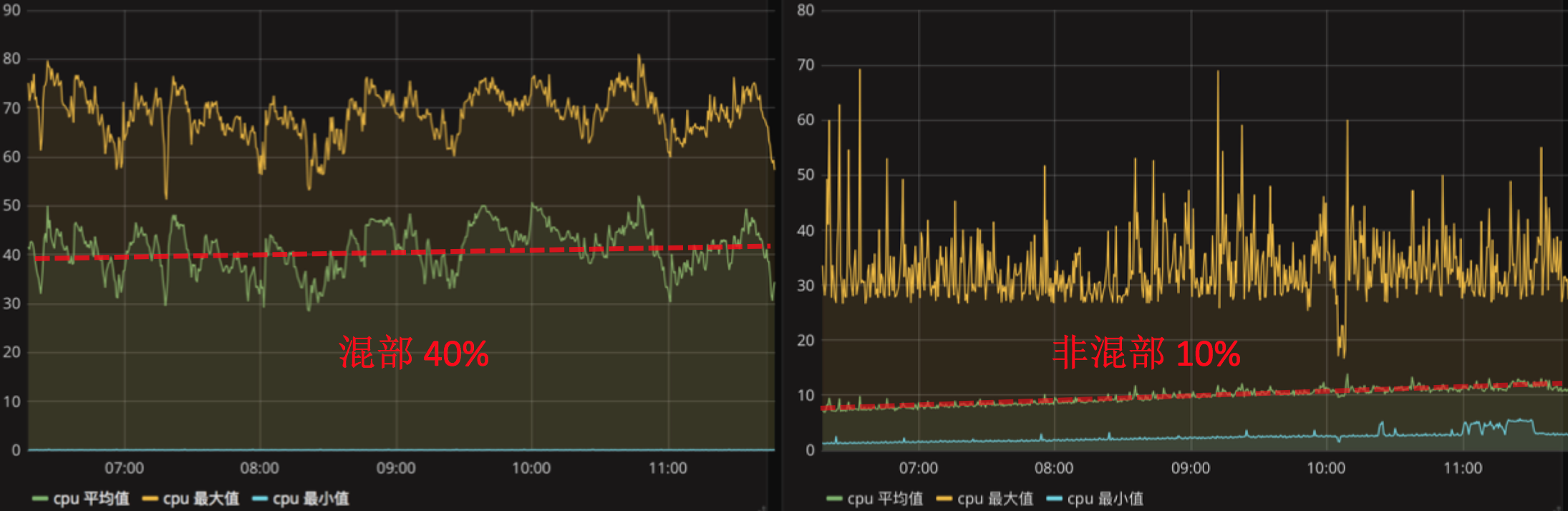
这是截图数据,这是真实监控系统的数据。(右图)这个代表非混部场景,时间点大概是7点到11点左右,在线中心利用率是10%。(左图)这个代表混部场景的数据,平均在40%左右,抖动性比较大,因为离线业务本身具有比较大的波动性。
二. 混部方案及架构
不管是业务体系还是运维体系都是比较新的场景,里面涉及方方面面的东西,信息量比较大。
下面简单介绍整体框架,混部场景业务部署策略,如何分配、放置,以及中间会引入技术点,比如对象存储分离、资源如何无中生有。混部场景下的业务运行策略,分为大促和日常两点。
2.1 混部整体架构
混部的本质:
第一,合并资源,整合资源,既可以给A用,也可以给B用。
第二,我们要做到很好的资源调度与分配,阿里巴巴集团有资源调度平台。在线侧资源调度系统称之为Sigma,业务资源调度是Fuxi。调度层要做的是以原有的模式进行资源的交付,这时候混部最大的问题是我要做仲裁,什么时候给什么样的人什么资源,给离线还是在线。我们会引入0层,资源调度层有好几层,我们把集群调度管控称之为1层调度,因为它是1层调度以下,所以称之为0层。0层主要负责协调双方调度的资源管控和资源分配决策。我们现在可以分配机器和资源给不同的业务,分配完后,运行时无论是在线业务还是离线业务,它跑在一个物理机上,如果它一直占着怎么办。这时候用到隔离,最底层通过内核保障,我们做了很多内核特性的开发,支持不同资源隔离、切换和降级。归根到底是为了保证业务的优先级和SLA。
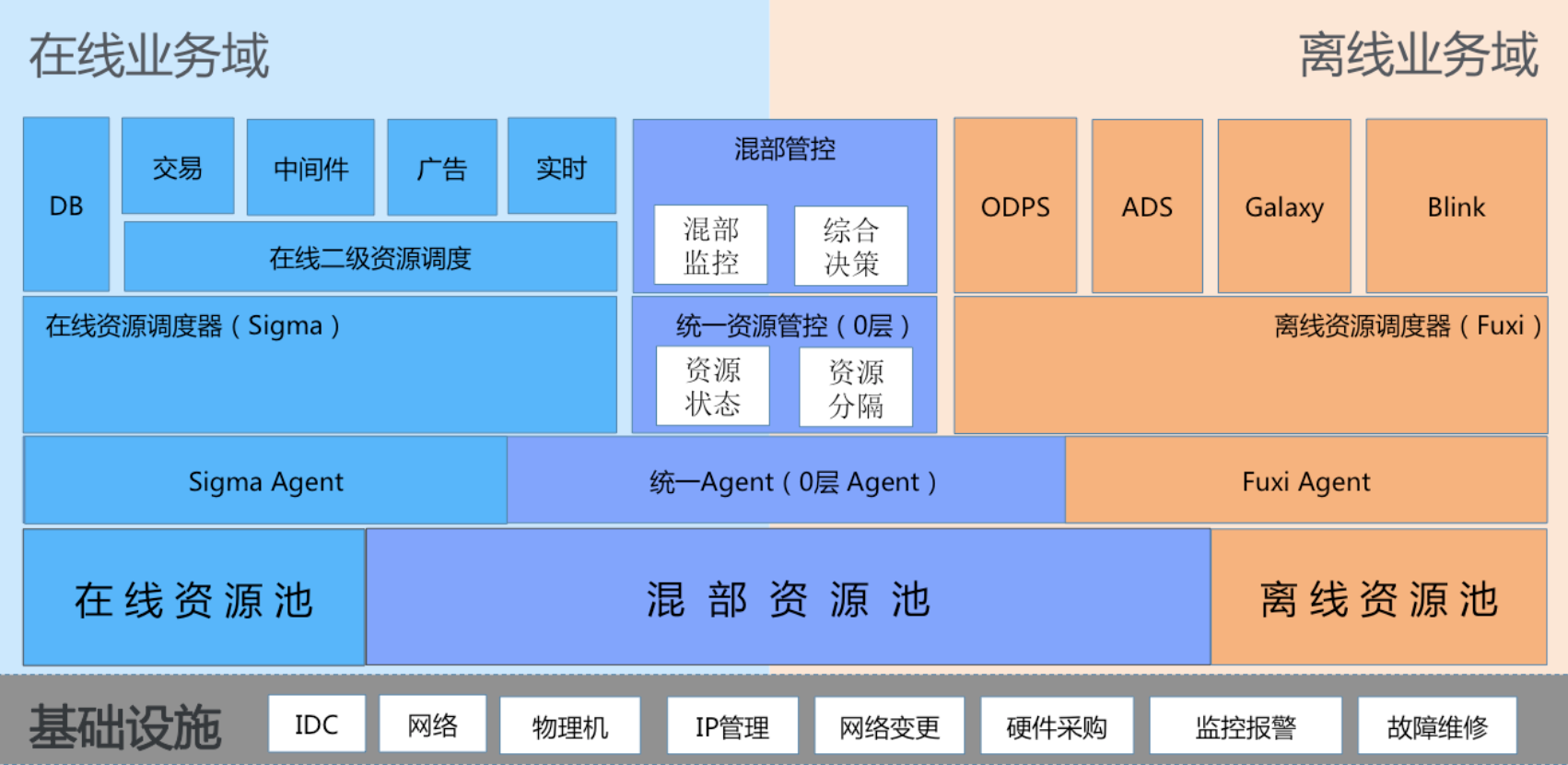
上图的架构分为明显的层次性,最底下是IDC,数据中心是通的。不管上层怎么用,你都这些机器里。上面是资源层,我们要做混部,必须打通池子,把资源放在一起管控。往上是调度层,分为服务端和客户端。我们是集中式资源管理,会有服务端概念。在线是Sigma,离线是Fuxi。我们假设中间做协调和仲裁做了0层,它有自己的Agent,上面是统一管控层的资源状态监听和配置。往上交付给业务,Hippo对我们来说是二级资源调度。混部管控主要做的是混部模式下,提出新业务运行的机制,它涉及底层资源的配置,我们需要上层管控台进行混部场景下的业务监控和决策判断。
2.2 混部场景在线业务部署策略

混部场景在线业务布局策略,三地多单元。在线侧,我们把自己的业务根据交易场景,尤其是买家的购买场景,进行全链条的梳理。我们把买家相关的所有服务闭环到一个处,一个处定义为一个单元。它能做到的事情是买家交易行为在这个单元内闭环,这是其架构上的设计。混部架构也是基于单元化能力做的,这是我们面临的第一个问题,要把资源整合,布双份业务。每个业务对资源的诉求完全不一样,这是我们面临的第一个挑战。
经过分析和实践,我们遇到的第一个麻烦是IO,强调IOPS。计算存储分离技术是我们集团演进的技术,由于我们恰好有受益,本来单机存储,部署计算任务时,磁盘无法满足在线业务的服务要求,所以这批机器都不能用了。我们借助计算存储分离的力量,我们去年并没有这么做,我们今年小规模验证了这个场景,计算存储分离后,我们有存储中心的概念,它会提供不同的存储能力。在线业务肯定要求高,量不需要大,但一定要有保障IOPS能力的存储服务,这是我们引入的点。
2.3 混部集群资源分配
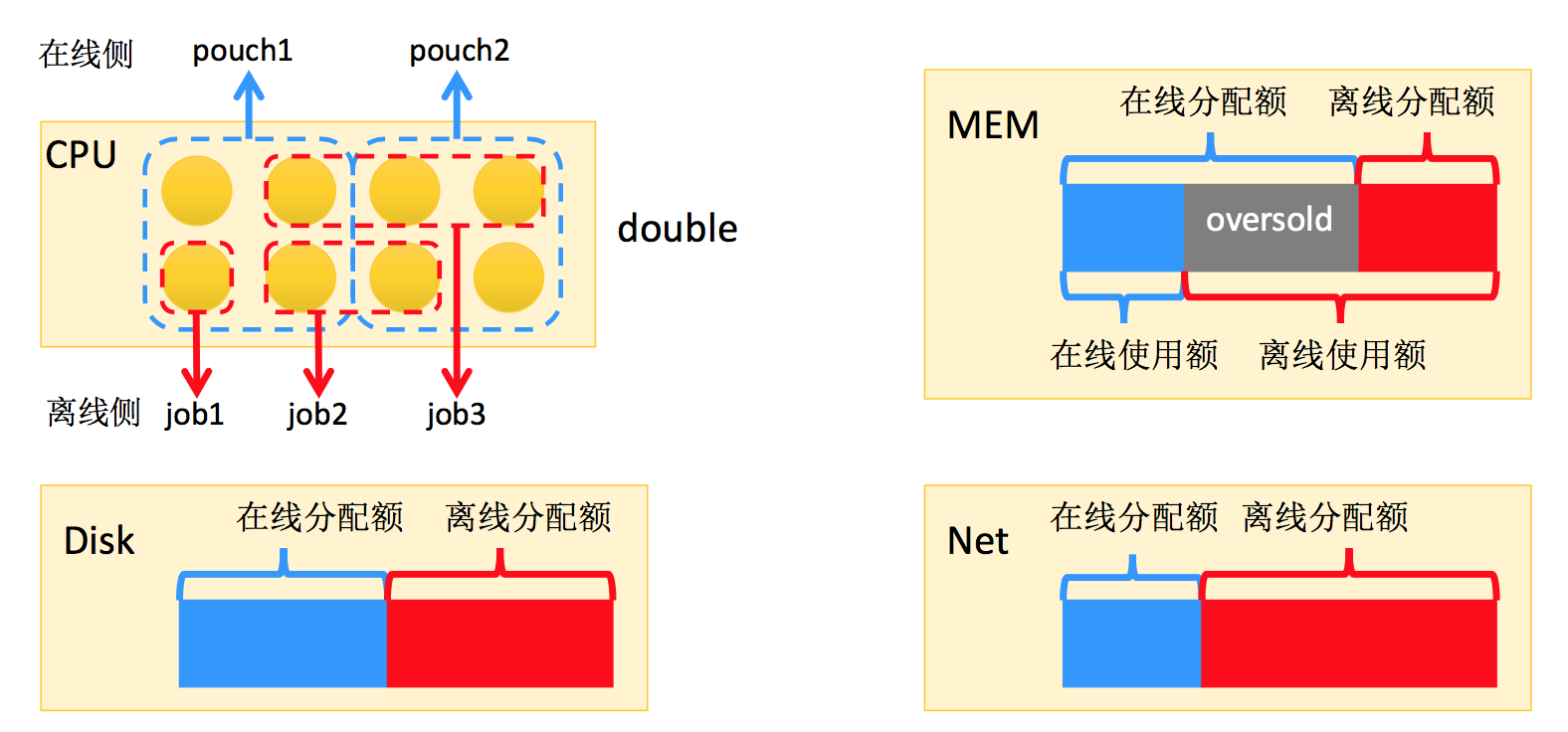
说完架构后,我们看资源。如何做到无中生有,明明是一个CPU,如何变成两个?
从资源的角度来看,资源主要是CPU、MEM、Disk、Net。CPU内核以时间片尽心分配,资源利用10%,在线无法利用起来。你该用的时候会拿到,但你无法保持持续的高压力,这是在线业务的状况。离线有超强的能力,来多少用多少,这是可行的大前提。关于CPU资源,我们有两个调度器(Sigma和Fuxi),我们集团主流业务以Pouch容器做分配,Pouch容器会划定一定的CPU资源,分配给容器,它可以用到。这时候我在混部技术里,Sigma会认为整台物理机都是我的,它分出去一份。这时候离线Fuxi调度器认为这台机器也是我的,它会把CPU资源作为可分配资源,做到Double,二者都觉得这是自己的。大家认为自己肯定分多了,关键在于核心技术内核隔离的层面,通过CPU内核隔离进行处理。MEM和Disk比较悲哀,资源消耗型,给谁就是给谁了。
关于内存,(右图)蓝色和红色的部分,资源分为在线分配额和离线分配额,给离线系统进行分配。我们公司以Java语言为主,哪怕没有请求,反正我一定会做。我们在MEM上做内核监听,看内存实际开销量。虽然分配给在线了,只要你用不完,我照样拿出来划给离线。离线会把可以被降级的业务分配上去。今天不展开Disk和Net,因为当前不是瓶颈点。
如何无中生有,这是正规的挑战机制,混部技术追求的极致是资源的充分利用,不该用不要用。
大促资源退让机制:站点快上快下
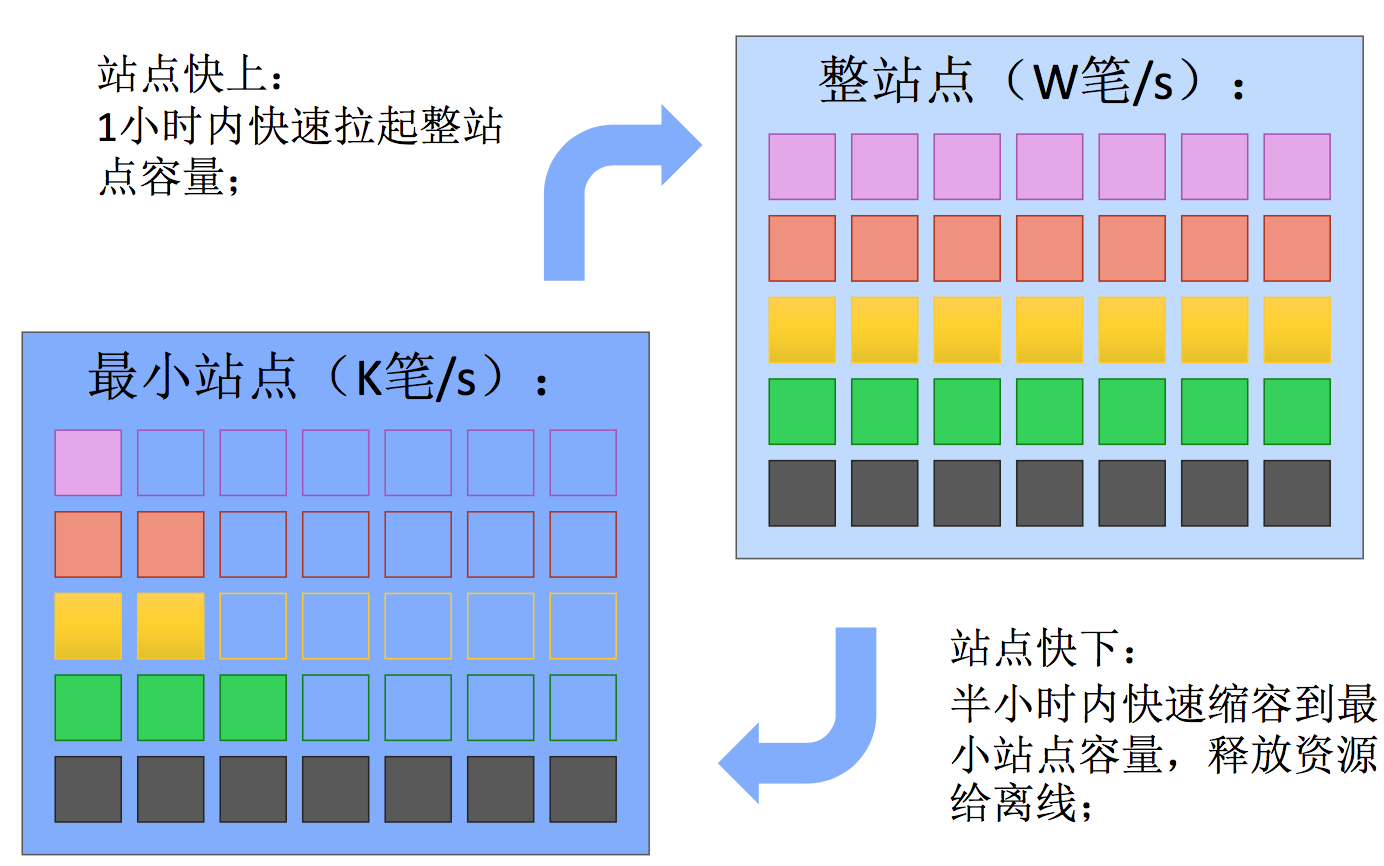
在线型业务特性决定我们有可行性,如果把这两个方块图,我们内部电商线做了容量管控,我可以规划站点以一个业务目标为单位,交易创建是我们的核心指标,以交易笔数作为指标,整个站点在大促时要准备万笔每秒的量级。日常会规划比较小的容量储备,可能是千笔的级别,十分之一的容量储备进行准备。每一行代表的是一个业务,每个色块代表一个业务,根据自己的业务特性进行伸缩概念。这是有规划的伸缩,以整个站点为角度,可以把不必要的容量进行整体缩容,以达到充分释放资源,离线可以在此基础上拿到更多的资源,这是快上快下的机制。
快上快下:不同场景下的资源分配
我们站点快上从低容量到高容量,时效是一小时内做完。快下,从高量级到低量级是半小时级别,主要为了应对大促等场景,我们把混部站点运行模式变成机制,从建站建成最小的单元,如果有需要可以迅速拉起到比较高的点位,持续几个小时。剩余时间,90%以上的资源会被离线吃掉。
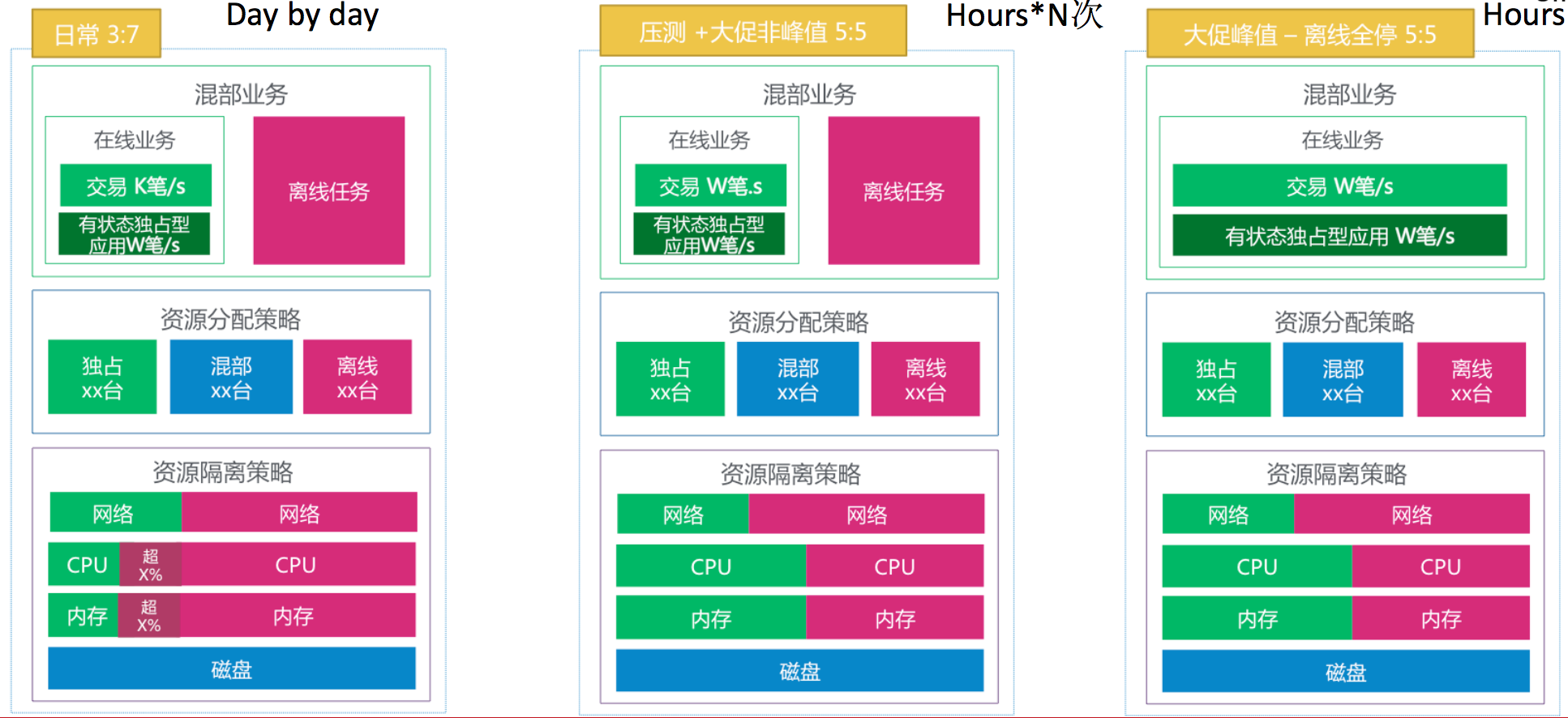
上图资源分布的情况,日常情况下,红色代表离线,绿色代表在线,它会争抢资源。压测和大促时会让离线退让。我们准备工作时,他可以争抢。大促当天,我们为了拿到稳定性保障,离线会做业务上的降级。
日常资源退让机制:分时复用
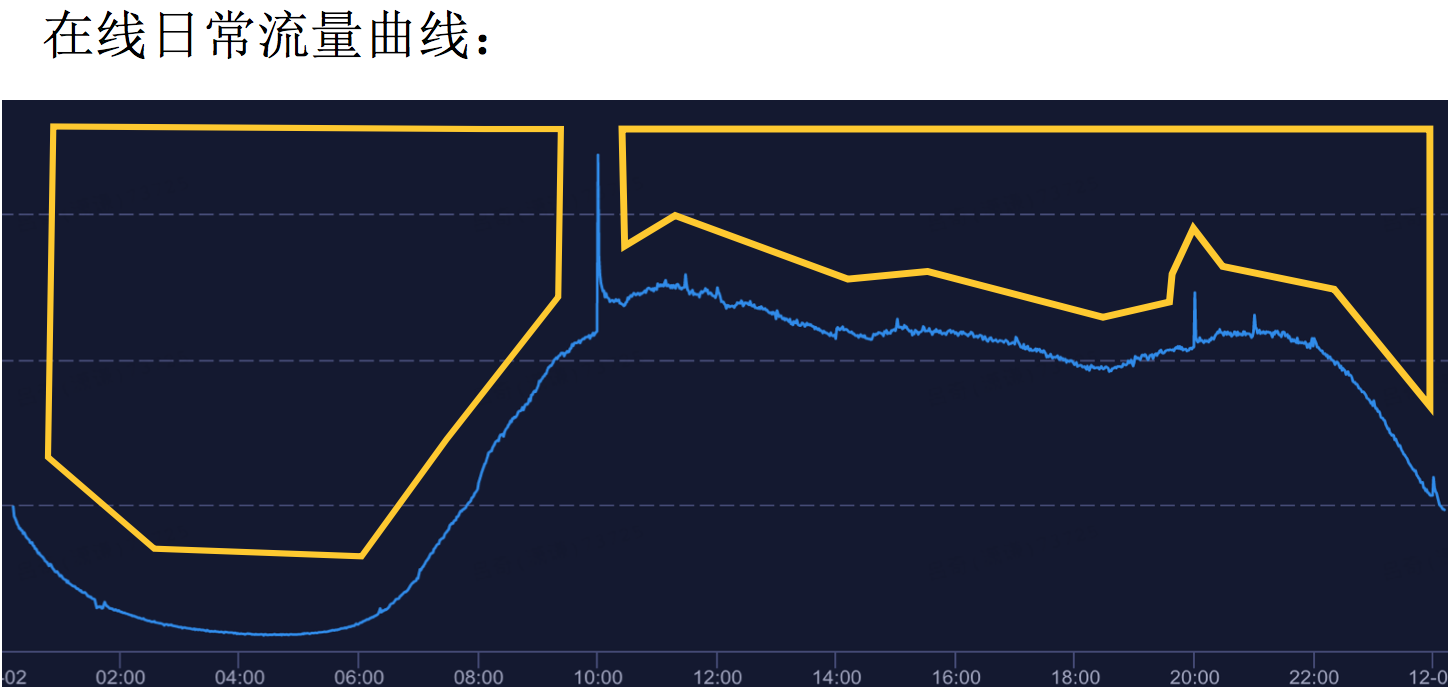
上图是日常资源退让机制,在线业务表现出每天的周期性变化,凌晨会出现低谷,我们针对每一个应用做更小力度的使用。
三. 混部核心技术
核心技术主要分为两方面,一是内核隔离,做内核的同学可以搜索资料。我们在内核做的隔离,不管是CPU维度、IO维度、内存维度、网络维度,我们都做了比较强的特性开发。无论是超线程队、调度器、三级缓存都做了CPU隔离特性。二是内存隔,离以CGroup为主。我们有内存带宽通道隔离特性和OM优先级的制定。网络层面除了做单机流量控制,还做了网络全链条层分服务等级,做到全链条的保障。
3.1 Memory动态超卖
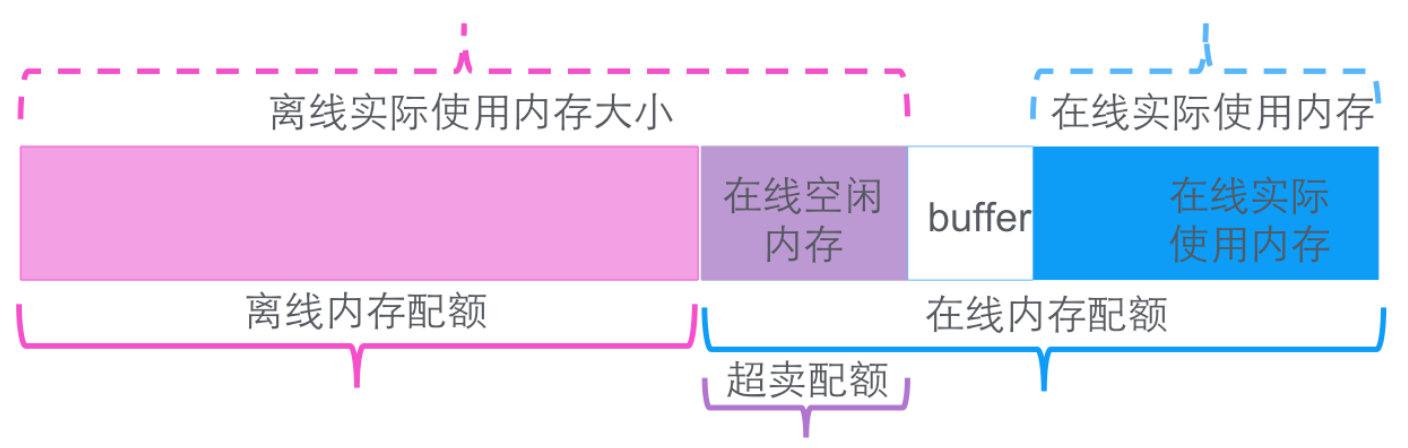
在分配基础上,离线可以抢在线。红色代表离线,它可以看到在线有没有空闲,如果空闲,照样吃过来。它实际使用量比分配划分的量大。
关于调度技术,主要是应用画像,基于应用画像描述资源调度,资源调度的重点是装箱和亲和互斥规则。站点快上快下机制叠加。离线集群关键在于如何做到分等级任务调度、动态内存超卖、无损降级。
3.2 在线资源调度sigma
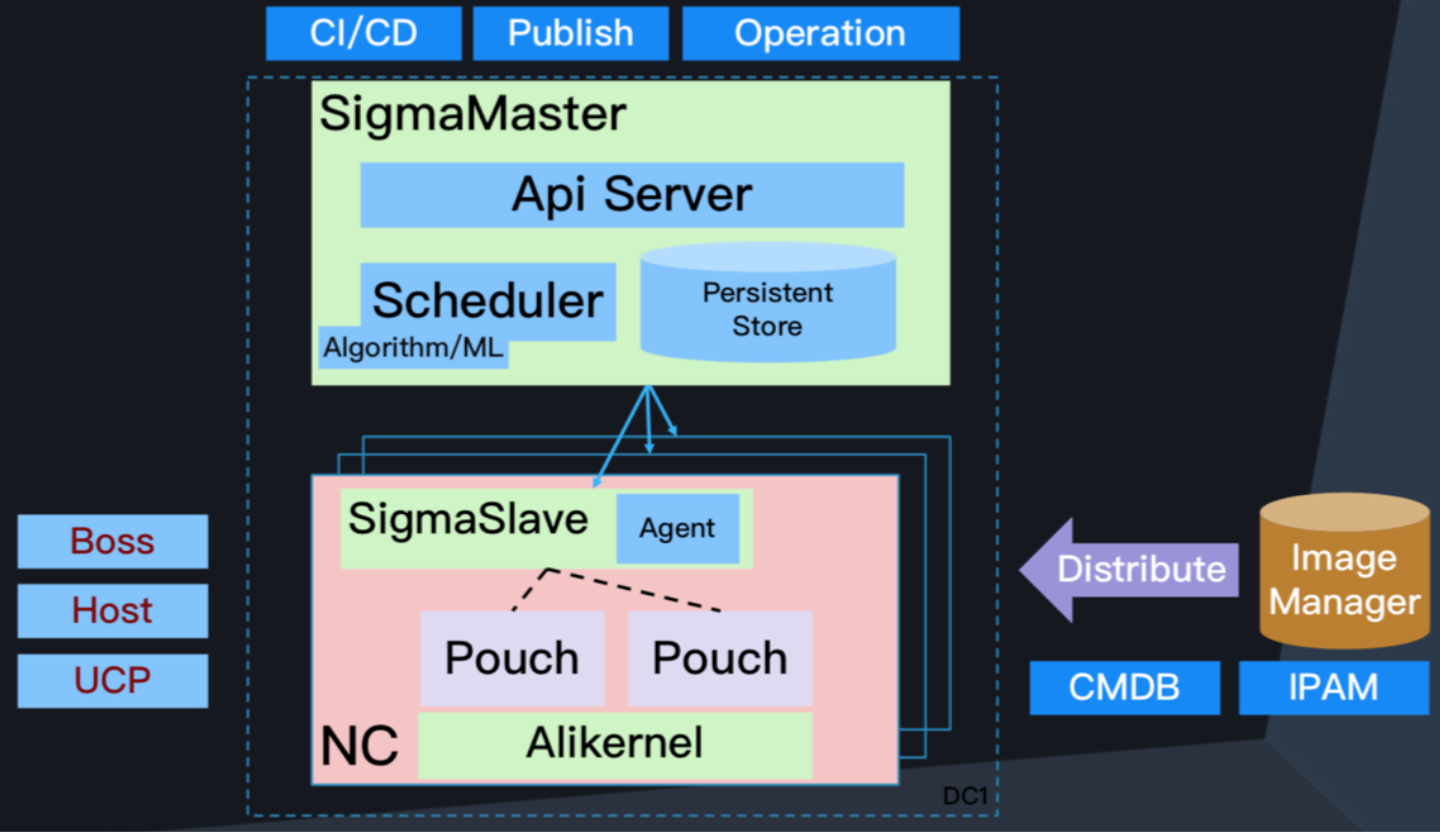
这是在线一级调度Sigma的架构图,我们做的版本是基于Kubernetes API,也是基于阿里Pouch容器做的。这是离线Fuxi调度,主要基于Job调度。
0层调度,无论是Sigma、Fuxi还是0层,他们都会同步,该怎么分配就怎么分配。
四. 未来展望
未来展望,主要是规模化、多元化和精细化。
规模化,我们今年会做到万台级别,这是量级的飞跃,我们希望把混部作为集团内部基础能力,节约更大的成本。
多元化,我们希望支持更多的业务类型,刚刚一直描述在线业务和离线业务,我们还有很多其他的业务,希望有更大范围的业务类型、更多的硬件设备。我们希望可以打通云上资源,阿里云跟公司内部是一个公司,资源可以复用。
精细化包括业务资源画像、调度等。
