@gaoxiaoyunwei2017
2018-08-03T02:40:21.000000Z
字数 10765
阅读 2362
企业级容器云平台GaiaStack
luna
作者简介:
罗韩梅罗老师,来自腾讯。她今天分享的是腾讯基于Kubernetes企业级容器云平台GaiaStack,罗老师一直致力于统一资源调度平台的开发运营,承担过腾讯资源平台的资源调度子系统研发,目前主要专注于开源系统分布式数据仓库和分布式资源调度平台等领域。
我是做过自研的台风的子系统叫脱卡(音),脱卡是后来的名字,更早的名字是叫T—BOX。我们一开始在容器的选型上用的直接是GaiaStack,也是因为之前做过T—BOX,直接熟悉背后的设计理念。今天的分享主要分为这三个部分,首先简单地介绍一下GaiaStack。
GaiaStack简介
GaiaStack是腾讯基于Kubernetes打造的容器私有云平台,这里面有几个关键字,第一个是腾讯。我们是在腾新内部所有BG所有业务都有在Kubernetes上去运营,第二是基于Kubernetes Docker,另外还有是私有云平台。从名字里面可以看到GaiaStack Docker,对应于Open SDK。

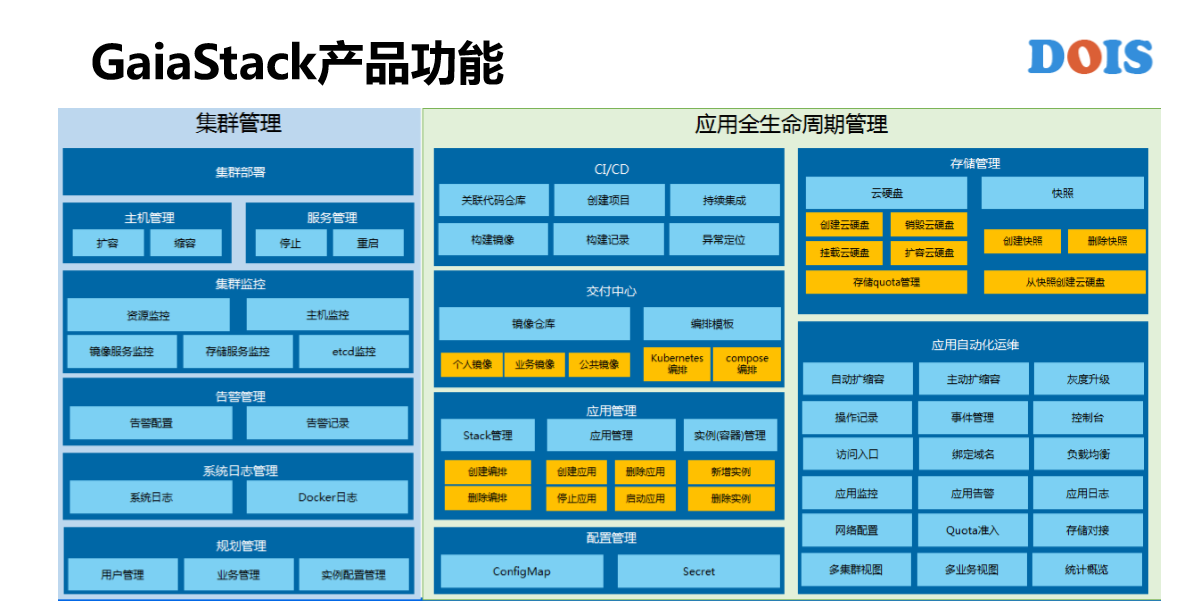
GaiaStack产品功能分为两块,一块是集群的管理,集群的运维人员去做的管理操作,包括集群的部署、监控、告警管理、日志管理,还有一些规划管理等等。下面是应用的全生命周期管理,而应用的全生命周期指的是从代码开始一直到区域应用的发布部署,到应用持续运维的过程。我们经常会把重点放到应用的全生命周期管理这一块。
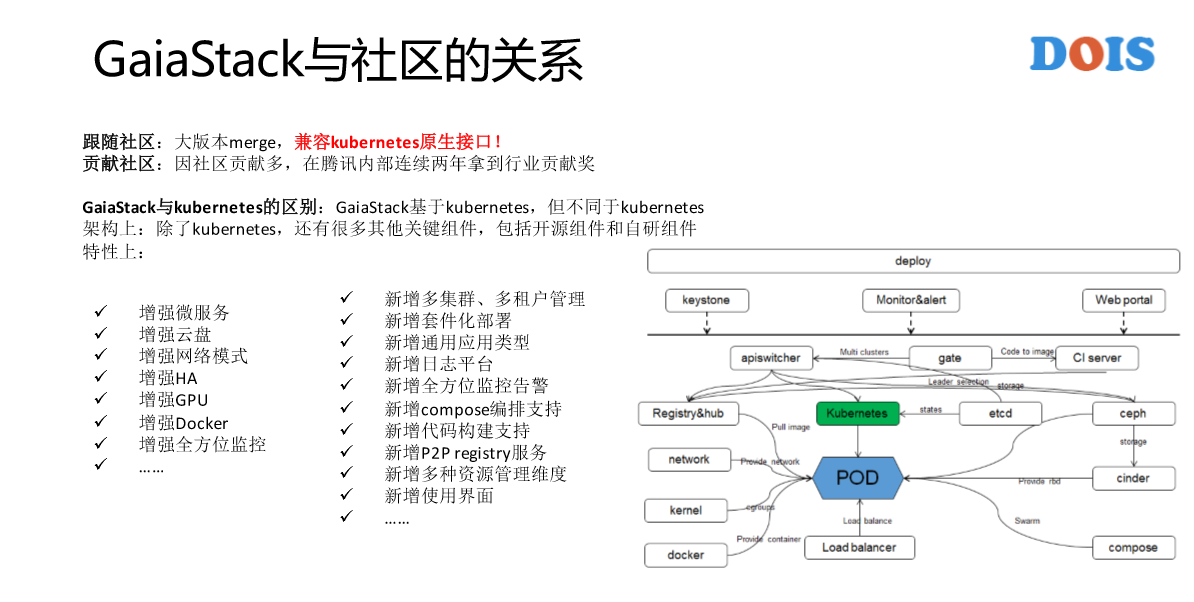
GaiaStack的部署架构,总的部署架构分为三个层次。为什么会有这样的划分?是因为在每一家公司,包括腾讯在内,我们都会管理全国很多的IDC,很多的集群,所以一定是有多集群和IDC的管理方式。但是我们希望所有的用户都是一个入口,所以有一个最上层是Global的方式,还有一些用户管理以及Docker Hip都会放到这个层。
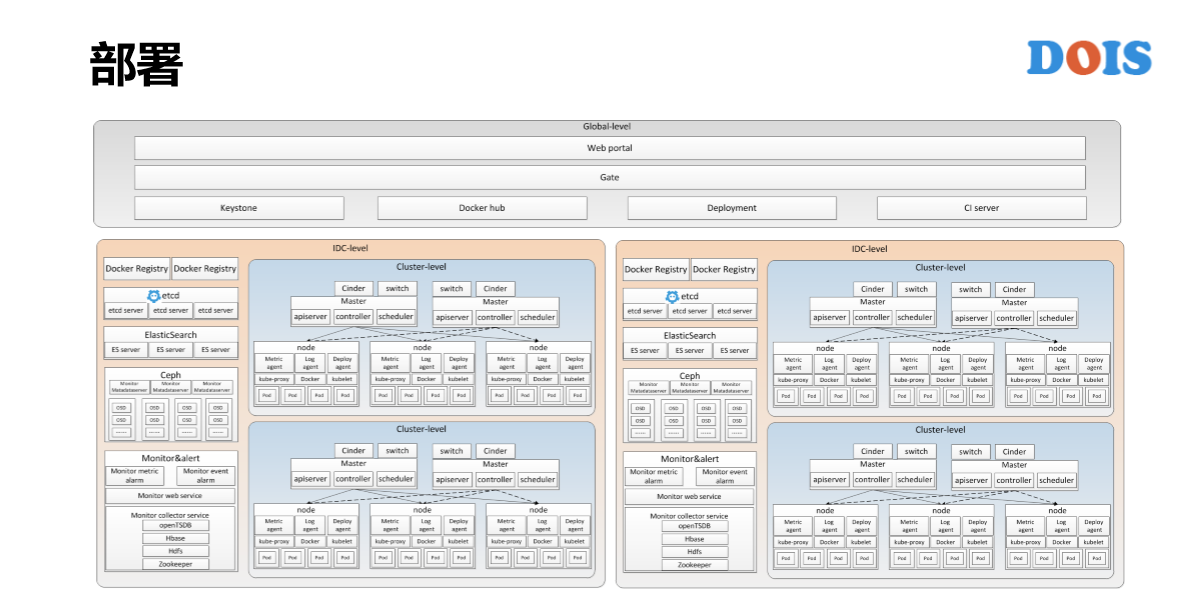
我们知道在IDC内部以及跨IDC网络环境差异非常的大,我们会把一个IDC里面的多个集群可以共享给公共的组件放到IDC层次。这个时候大家可能又有一个问题说,为什么一个IDC里面所有的集群还要在多分集群,为什么不能放在一个里面?我们知道腾讯在天津的一个IDC有10万台服务器,我们也知道Kubernetes的单集群规模只有几千台。所以说IDC里面多集群一定会存在的。另外,有一些业务的专属集群,有一些是在线的、离线的单独集群,也会存在一个IDC里面有多个集群的情况,我们会把一些监控告警的模块、一些存储的单元会放到IDC这一层。最后这里面那一层是GaiaStack层,这一层是通常的K8S的集群。
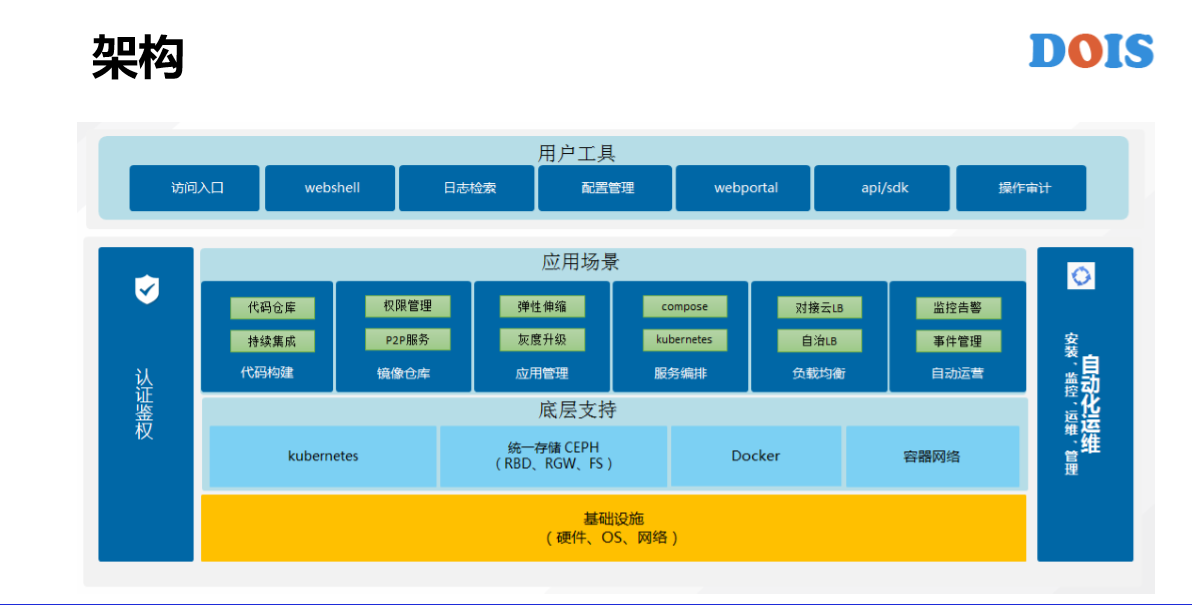
接下来讲GaiaStack的应用场景,从做T—BOX到GaiaStack,对它的定位都是操作系统。既然是操作系统就不应该对上层的应用做挑选,而是应该所有的应用都能够在我们系统上去进行。我们讲的时候会带来另外的一个概念是微服务,最近的几年是非常的火爆,所以说GaiaStack并没有说把应用场景局限在微服务这一块。我们除了微服务业要支持有状态的利用,离线计算、GPU应用、科学计算等应用的场景。
为什么说GaiaStack现在支持的不够好?从我们做T—BOX经验来说,虽然说Docker已经很复杂、很庞大了,但是仍然有很多的东西没有去解决。比如说对一个统一的资源管理调度平台来说,它的优先级抢占是哪一个平台才在K8S里面出现的?这其实是蛮基本的。比如说对于离线计算,K8S现在的调度期性,大家现在心里应该有数知道是多少,我们也做过腾讯大数据的资源平台,至少要差两个数量级。这就意味着在大规模的离线计算里面调度器是很大的瓶颈,会导致数据使用率或者是下发的资源率得不到有效的保证。
还有对GPU的应用,我们也看到说K8S是支持GPU,包括前面的离线计算。在实际情况里面,比如说在腾讯云里面TIY机器学习平台上,底层用的资源管理平台就是GaiaStack。我们为了支持斯巴克(音)应用不知道解决了多少个Bug,增加了多少个功能。
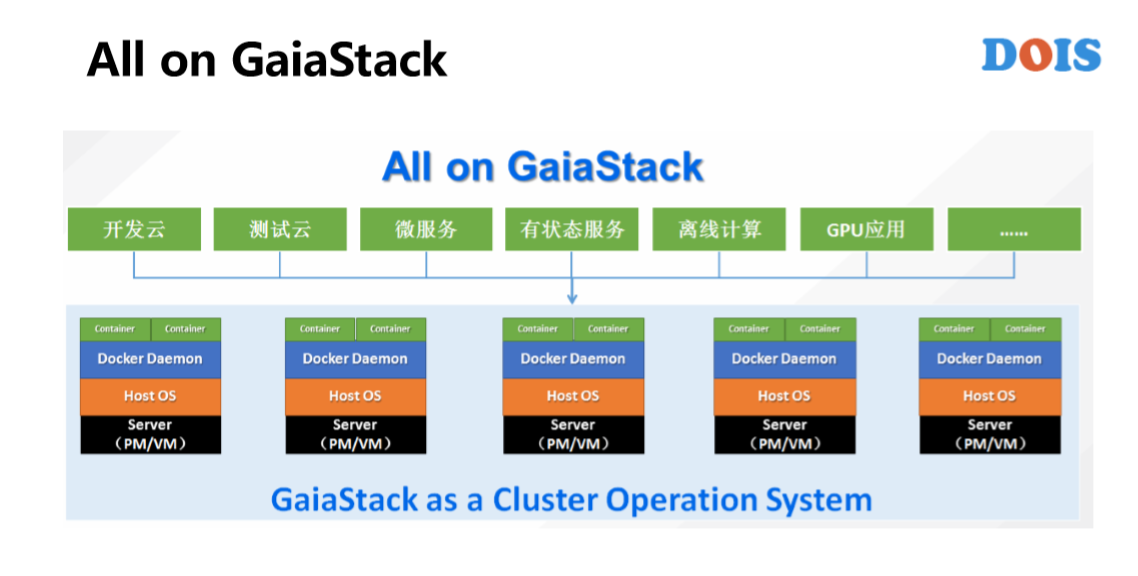
在这里讲一下AII on GaiaStack的背景。我们知道在Google几乎所有的应用都是在BOX上面去运行的,没有区分是在线、离线,有状态还是微服务的。BAT本来在Docker出现之前都有各自资源的容器平台,容器也不是刚刚才有的。我们的目标还是说让各种类型的应用都能够在容器平台上去运行,而微服务本身是非常好的架构,所以说它对底层平台的要求会低一些。比如说它可以有损,比如说它的实力之间是没有区分的,比如说它是无状态的。所以说,反而对很多的一些创业公司或者是一些中小型企业用K8S就足够了,但是对于真正的企业级场景还要做蛮多的东西。
GaiaStack应用全生命周期管理
接下来讲一下GaiaStack对应用全生命周期的管理,我们从开始来讲就是CICD,这块反而是GaiaStack没有去做重点投入的点,我们只是能够简单地去关联代码仓库,然后去做这样的持续集成,然后自动的去构建对象,只是这样。因为腾讯其实有更复杂的DevWork流程,我们只是在GaiaStack这块做最简单的功能,而更负责的DevWork流程是跟已有的产品去做直接的对接。
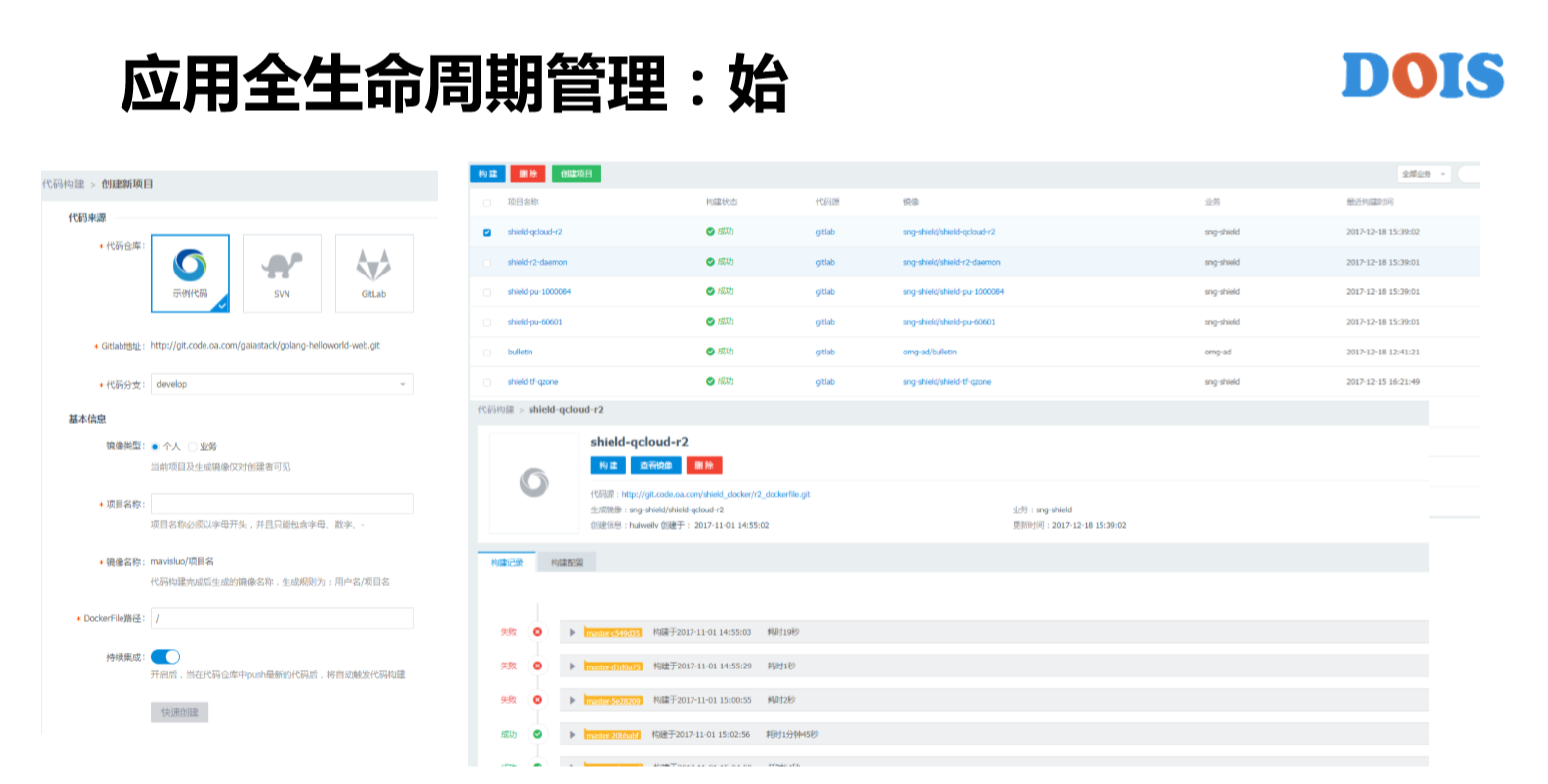
从代码连接地方生成出镜像之后,我们就进入了交付中心。GaiaStack的有两个,一个是镜像仓库,一个是模板。镜像仓库包括有权限管理、导入功能和自动扫描功能,还有编排模块,比如说右下角这块有各个应用的关系示图。在编排模板之上又演化出了服务市场之类的产品和组件,应用管理又分为三个层次。比如说Stack、APP,这里面腾讯的某一个产品是游戏的业务Stack,下面有每个APP跟实例。
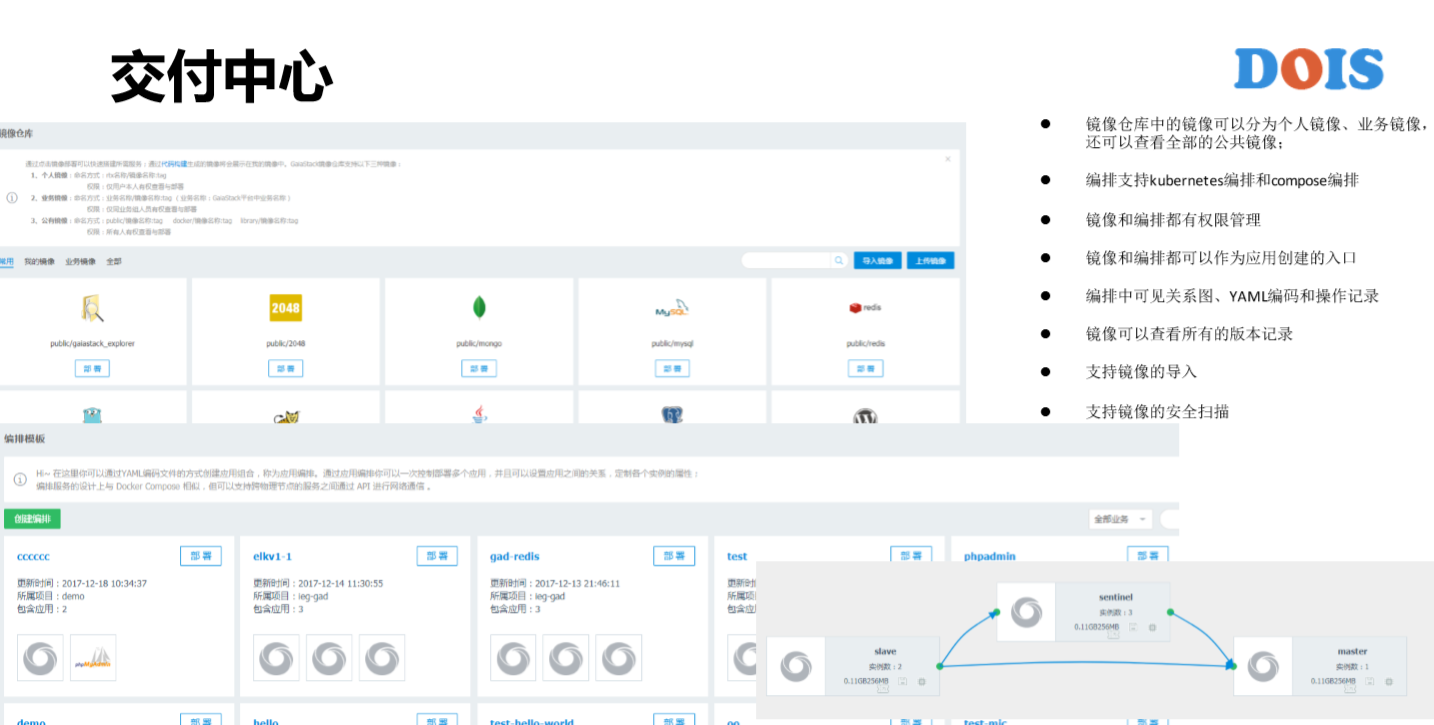
这块讲的点,比如说对APP的操作。我们看到不仅仅是支持简单的提交或者是启动、删除等等。GaiaStack这块增加了停止、启动、复制等操作。这也是长期的平台对用户积累过来的需求,比如说复制,很多游戏在线业务都是用前台提交的方式来提交应用的,我们知道应用的属性有多少?其实有大几十,甚至上百个,它有的时候要去验证只是改变一两个属性,那其实复制是一个蛮好的操作,可以复制一个已经结束或者是正在运行中的应用,然后把所有的属性都复制过来之后,直接在改它想改的属性即可以。

配置管理主要是ConfigMap跟Secret。比如说,最近把腾讯专有云所有的应用都迁移到ConfigMap上来,只用了4天的时间,他们有很多的配置。前两天看到某一个配置跟它关联的应用有16个,所以从页面这块,如果你修改配置能够很清晰地看到跟哪些应用可能有一些关联。

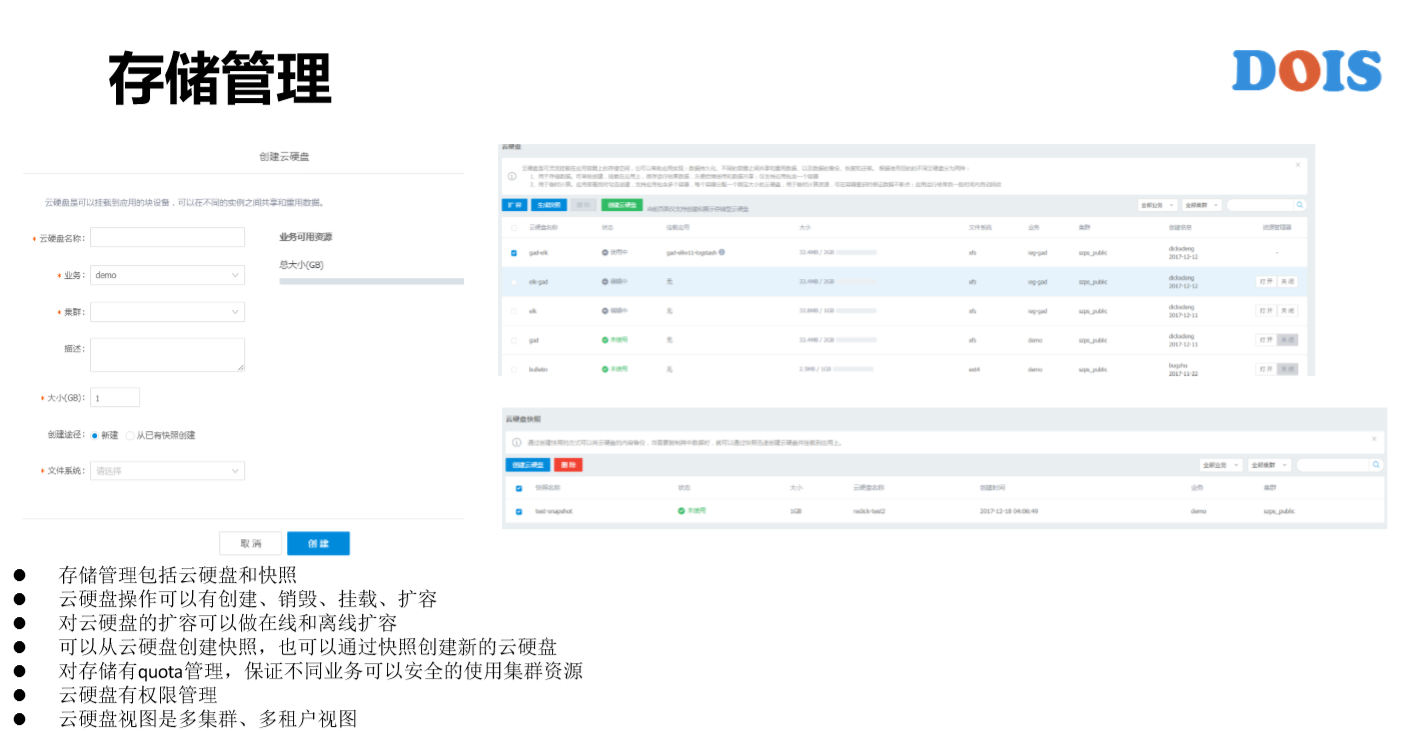
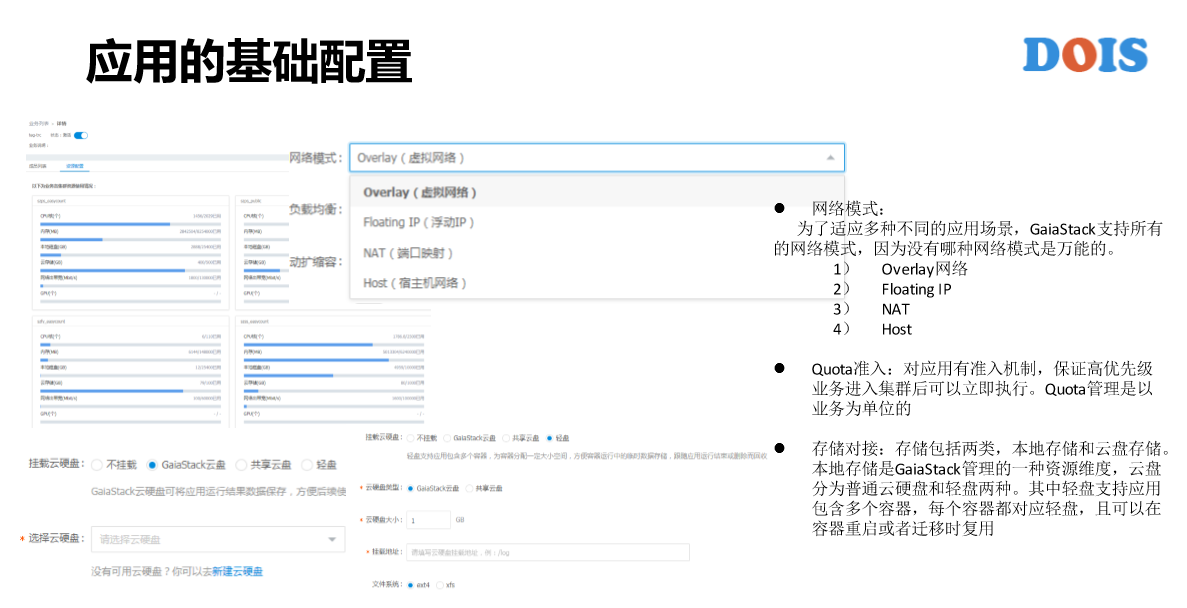
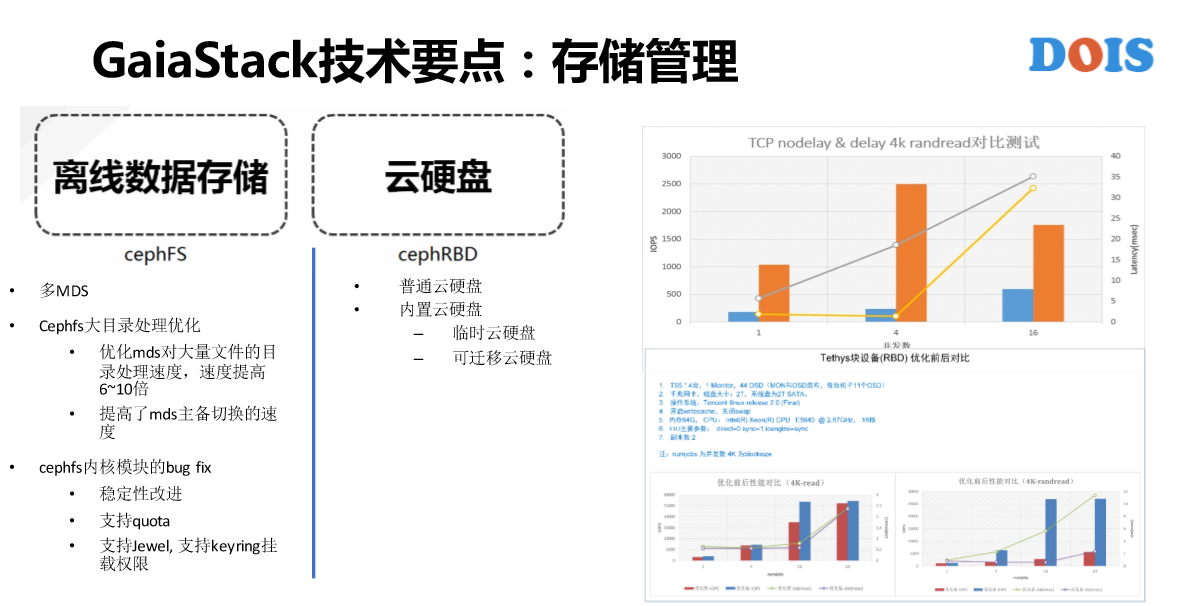
然后就是存储管理,存储管理这一页是比较简单的,只是针对与分布式存储或者说是云硬盘。GaiaStack跟K8S有一点是说,第一是所有的资源都可以纳入Quota管理,第二是我们的云盘可以去创建快照,也可以根据快照创建云盘,并且可以支持离线扩容和在线的扩容。
接下来,如果我们通过平台把应用提交到平台之上,就是简单地对应用完成了它的部署。这个时候远远还不是重点,是对应用做常见的操作。GaiaStack的特别之处,比如说以缩容为例,对于一个微服务去缩容,由10个实力缩到5个,缩到的5个是哪5个?其实是系统自动地去替我们决策,而我们不知道是哪几个。因为GaiaStack现在也是私有云,通过腾讯云对外部的客户去推广,我们去交流过的有一些银行,还有一些游戏的行业,他们会讲说,即便我是微服务。如果这个实例正在有交易、正在处理,如果说这个实例正在有游戏玩家连接,那我希望删除的是那些没有影响的实例,所以这就是GaiaStack能够做到的。
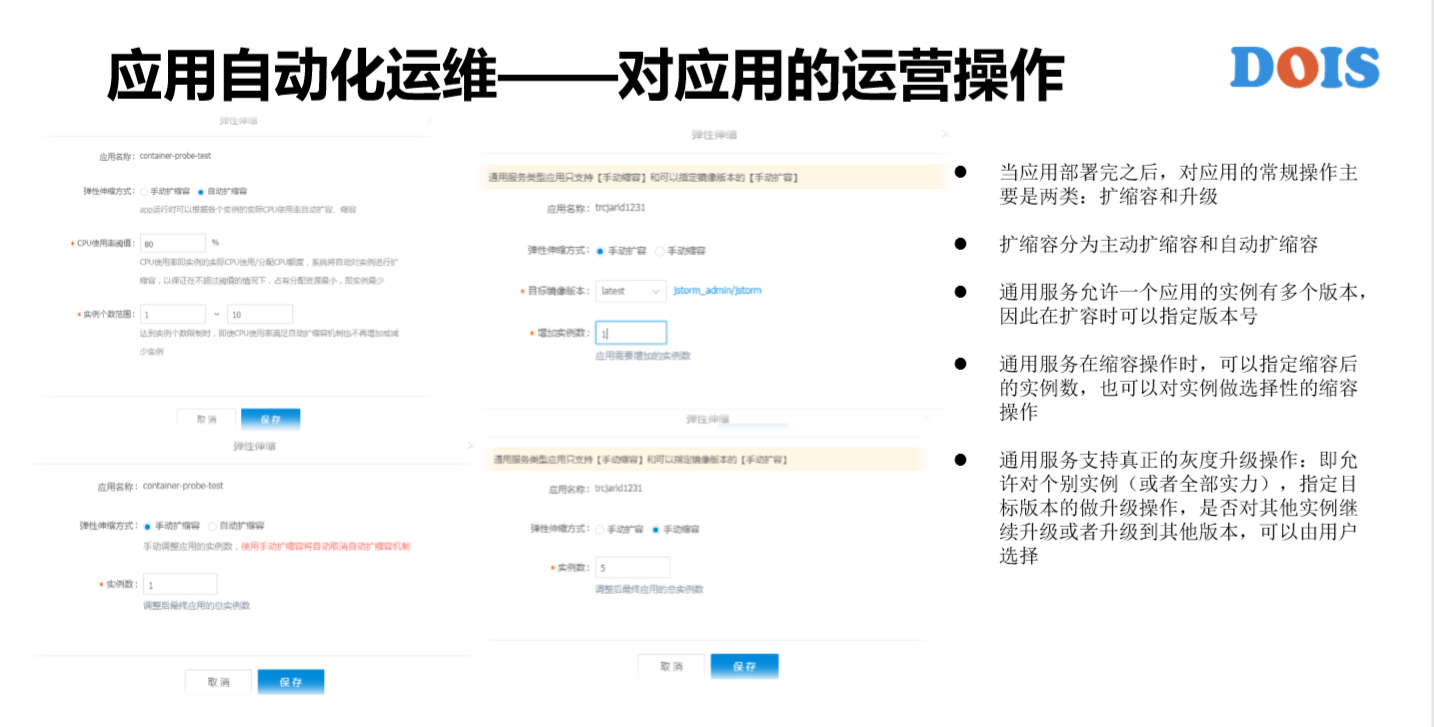
在腾讯内部说的非常多的概念叫做灰度升级,我刚才进来的时候在走廊里面也看到灰度升级的理念宣传。所谓的灰度升级,每一次版本的发布不可能保证,版本即便经过了测试也不可能说是完全没有任何Bug的版本,所以说比较安全的运营方式是对运营做灰度的升级,有问题可以回馈。
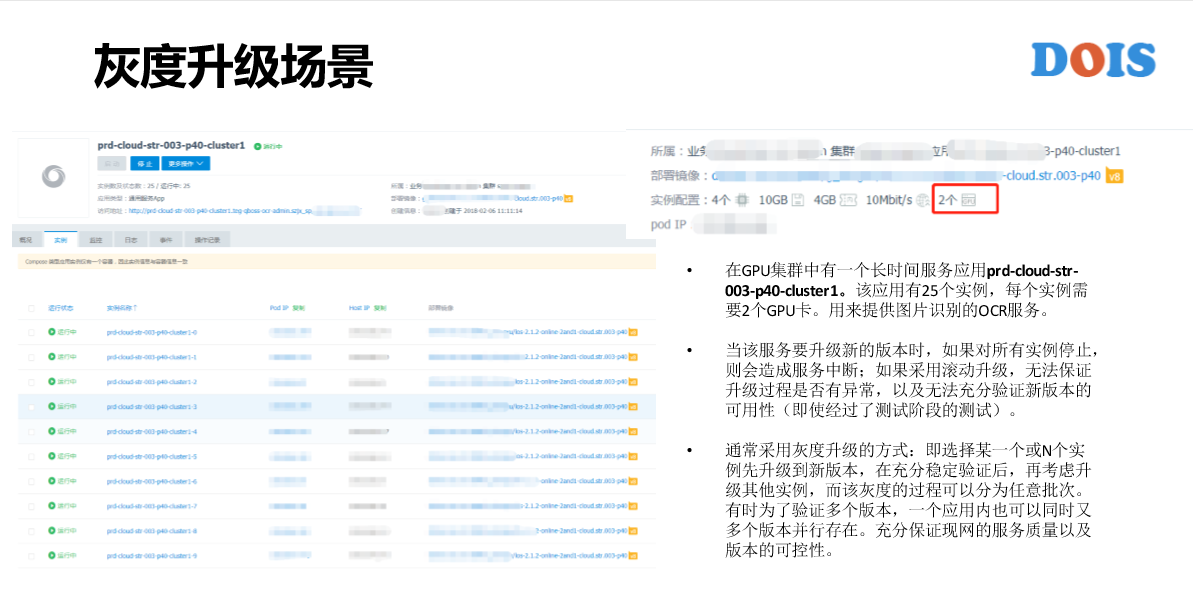
K8S最初的时候是灰度升级,现在没人这么叫。所谓的滚动升级,还是APP有10个实例,把它从V1版本升级到V2版本,升级过程是每一个实例一个一个去升级。也许每一个时间点,APP里面有两个版本同时存在,同时存在的两个版本是不稳定的状态,它的稳定状态仍然是要么灰度全部是V1的版本,要么全部升级成功是V2版本。真正的灰度升级是什么样子?比如说实例数有几千个,可能第一次升级的时候只想升级10个实例,让它运行一周、两周,甚至更多的时间。然后第二批升级20个实例,我再让它去跑一段时间,然后可能第三批就把所有的几千个实例都给升级到了,所以这才是真正的一个灰度升级。
这是我们线上的例子,它是GPU的应用。虽然是GPU应用,但它并不是离线的,它是长时间的服务应用,是用来提供图片识别的服务。我们可以看它有两个GPU卡的资源需求,有25个实例。这是我去看到它的事件列表,可以看到在2018年2月6号的时候,它是V7版本开始运行,然后2月9号9点多的时候,由V7版本升级到V8版本的触发,接下来马上触的是V8的版本,这是GaiaStack能看到的是灰度升级。
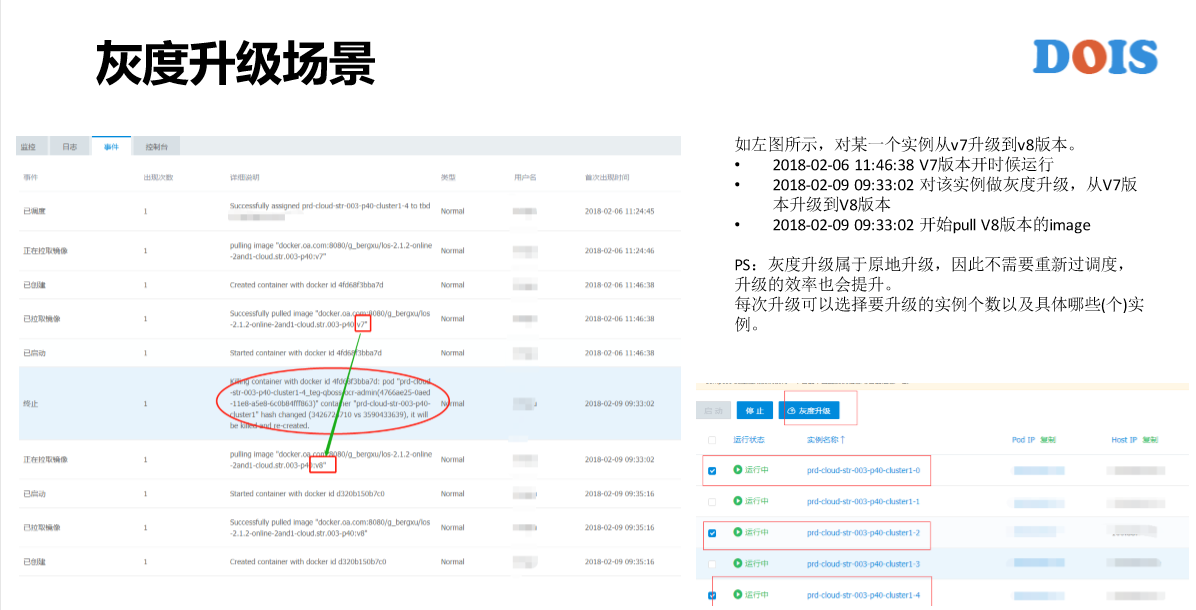
从这一页PPT里面能看有几个点?第一个点,能够看到这个实例所有的历史事件,因为升级前跟升级后是两个不同的Pod,原来的Pod不见了。但是在这儿能够看到V1—V8版本的整个历史过程。另外一点,我在升级的过程当中并没有去过调度器,就是说没有去再走一次调度。理论上,升级是销毁原Pod,创建新Pod,然后新的Pod没有Host,所以要重新调度。
没有过调度有什么样的好处?第一个好处,是否调原资源。我们知道任何调度都不一定是成功的,比如说有资源碎片的效应,可能每一台机器都剩了两个G,但是你的Pod需要3个G,任何一个机器上都不满足,因为整个集群也是动态的场景。
另外,启动一个Pod之前是要做一些准备工作的。如果是原地升级就不需要再去做这样的准备。第三,前一个Pod或者是旧的版本,有可能会有中间的数据或者是日志或者是一些状态,那我原地这些全都在。我们看一下这个图里面右下角灰度升级的设计,可以任意来指定一个或多个实例来进行灰度升级。
接下来,如果对应用提供自动化运维地手段,第一个是对应用的探查,比如说我们能去看操作记录,操作记录其实还是蛮重要的。比如说以前做台风的时候自研平台,有一天有一个人给我打电话来投诉我们说,为什么我提交的应用被你们平台删掉了?我说这个是他们自己删的吧,看了一下操作记录,他说,没有,那个时候是晚上,他已经下班了。后来我们再查一下IP,他是以前做测试的时候放在机器上的某一个脚本自动地去删掉,所以说我们做基础平台的人要给自己一个自证清白的机会,也能够帮助用户去做审计的检查。操作记录蛮重要,比如说这页里面可以看到,这是我什么时候创建了这个应用,什么时候去升级,什么时候扩容,什么时候缩容都能够看得到。
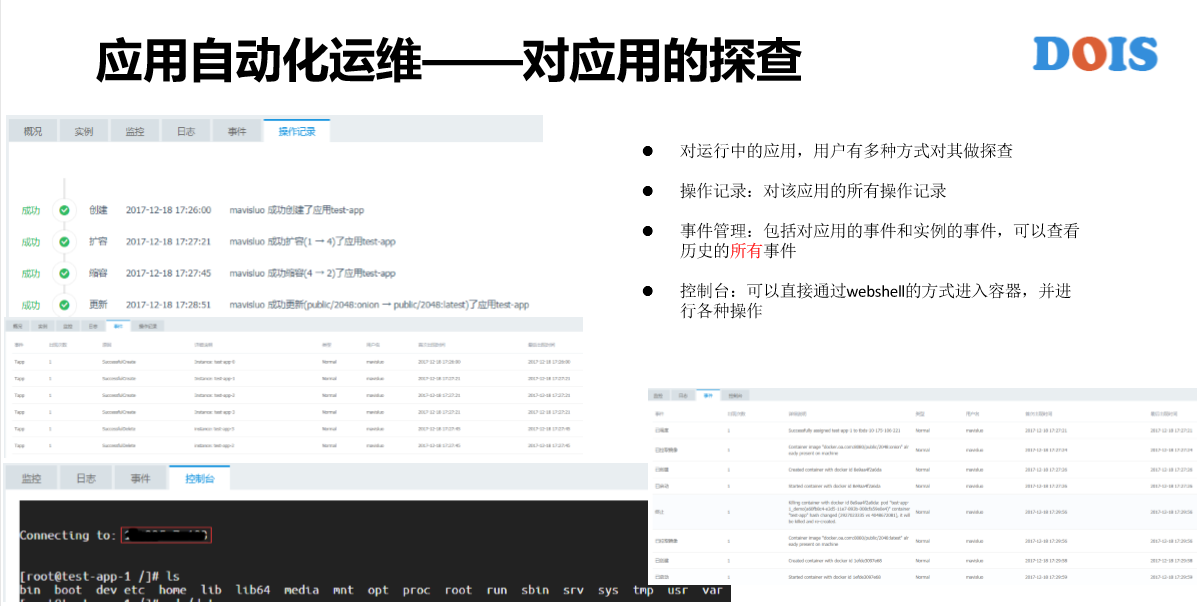
还有刚才讲的事件管理,本来我认为是辅助的东西,但在一些场景里面又是非常的关键。比如说配置成事件保留多长时间?不管你保留多长时间。我们很多时候是长时间的在线服务,大家没有问题的时候不去看,有问题去看的时候有可能事件已经不再了。另外,比如说在科学计算集群里面,一个APP要跑几千个实例,同时跑很多APP,而且它还要超发,我们知道超发的时候调度是一直失败,每一次失败去刷事件,而且这个压力是在哪儿?如果APP非常大的话是同时起很多的实例,同时启动结束去Pod都是同时的,所以说事件对ISD(音)是当年就被刷掉坏掉的设备。这个事件本来是辅助的,但其实用不好或者是某些场景下不做优化还是蛮致命的,UECD对于GaiaStack来说是最关键的。控制台也是最关键的,很多的容器产品都有控制台,只不过GaiaStack控制台看起来没有任何的校验。
接下来是对应用的探查,把应用提交到平台之上是希望用户不要以为说扔进了一个黑盒子,我们能够去看我的应用。怎么去看?有几种方式。第一个是有访问入口,为什么有访问入口概念?K8S给普通的用户去用还是有一些门槛,他可能要创建APP才能够去访问。GaiaStack给每一个APP都做了默认的访问方式,所以我们能够看到访问入口,但其实也看到其他的有一些产品也做了访问入口,我们这边有不一样的点,除了有对应用的访问入口,还有对某一个实例的访问入口。可以通过应用的入口点击,可以看到应用通过负载均衡之后的入口,所以背后服务给你的实例未必是哪一个,所以有时候没办法去定位哪一个问题。但如果说这边每一个实例都能够看到它的入口,这个页面就比较方便了。
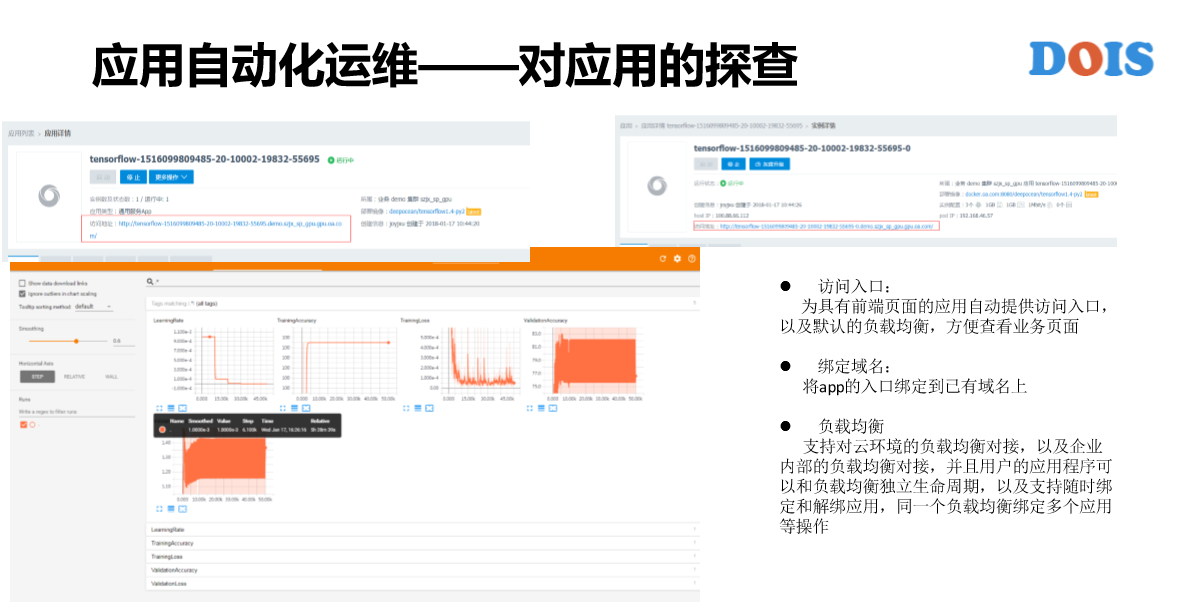
负载均衡这一块讲一下,GaiaStack在腾讯内部有两款负载均衡,GaiaStack是跟这两款负载均衡产品是做对接的。现在TGW也可以伴随着私有云一起出来,我们可以在私有云的场景下跟TGW,在公有云腾讯上也有CLB也去做了对接。另外,对于企业内部来讲,如果已经有成熟的负载均衡产品也可以去做。还有GaiaStack提供的对负载均衡的使用方式,我们是有几个点要去说的,第一,负载均衡可以跨集群。第二,可以跨应用,多个应用可以绑定到一个负载均衡上。第三,对负载均衡的操作可以是实例级别。也可以说把一个应用绑定在负载均衡之上,可以对其中的某一个实例给它解绑以及重新绑定等等的操作。
如果应用出现一些问题的话,我们要能够对应用做故障定位。有几个方面,第一个是监控,GaiaStack提供的监控还是蛮多的,这块只是对应用的监控。其实我们对系统也有蛮多的监控,我这块举几个例子,比如说GaiaStack有一个监控是说叫集群的可用性监控,这是一个什么概念?我们的一个集群里有多少个节点?我会定时的去提交一个探测非常轻量级作业或者是APP,让它在每个节点上都有实例来运行,然后来计算它的可用性。可用性的定义就是运行中的实例数除以总的实例数,如果不是100%有可能是某一个节点出问题。集群整体的可用性监控更像是说,我只是看整体的可用性的情况无法定位原因,也许是我提交APP的时候出错,也许是某一个节点运行的时候出错,也许是调度器有问题,也许是其他的原因,这是GaiaStack运维同事高度去关注的点。
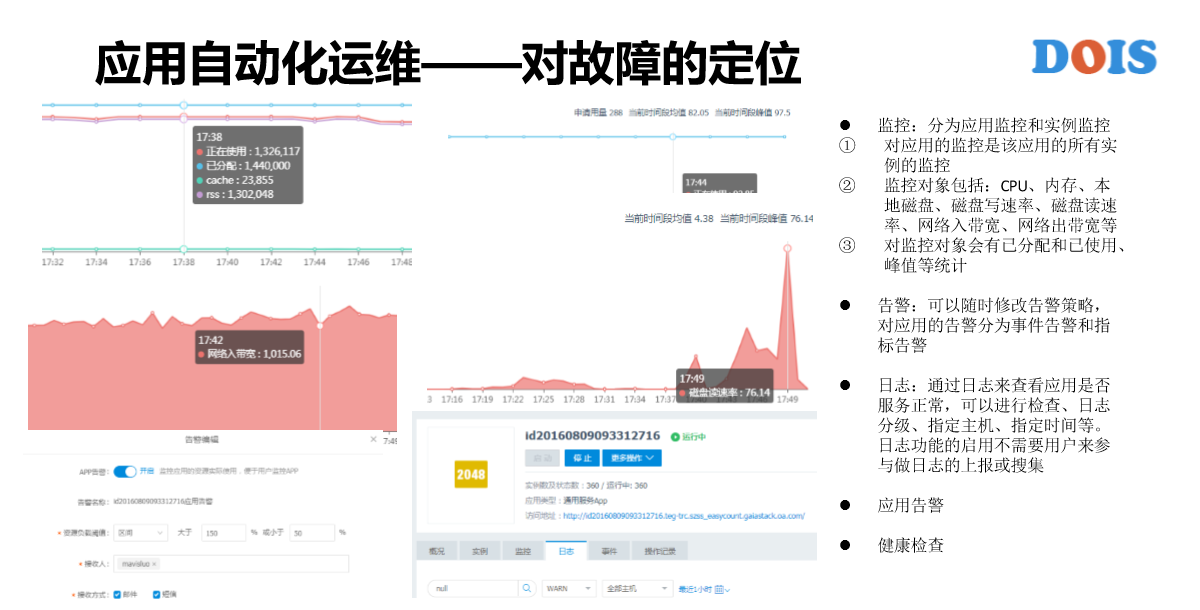
再比如说,我们还有监控项是在每一台计算节点上去做对账。因为计算节点上面的资源都是被GaiaStack去纳管的,如果说有在我们之外运维或者是有人去提交一些东西做些破坏性的东西,这是不可控的。有可能造成的结果也是比较严重,举个例子,我们最近在对接一些业务的时候,因为比较多的业务,对接的人也比较多,每个人都知道我们的密码,因为是在调试的过程当中所有人都能当机器。我们就发现有些参数被改,有的时候我们的路由表被删了,有的时候我们的数据被清了。所以说我们要有每个节点的审计。另外,可能每个节点上会定期的去Docker非常轻量的容器。现网运营说Docker卡死了,机器不动了,经常是这样的说法,但这种需要更多的一些探测手段。
还有就是告警跟日志,这一块的日志指的是应用的日志。我们对应用日志的管理是有几个方面,首先,对页面这一块能够去直接查看日志。第二是对日志搜集和全文解锁的功能。第三是提供对应用的日志服务,并不需要对日志做什么样的改造。第四是日志占本地磁盘,GaiaStack后面会去讲有去管理本地磁盘的容量。所以说,日志也纳入了GaiaStack的资源管理体系当中还有数据,就是说日志跟数据是有区分,只需要用户在提交作业的时候指定数据就好。
应用的基础配置是有分三个点,我们提交一个在线业务是希望提交完之后能够在可预期的时间之内给它运行起来,但是如果说准入是在Pod级别去做的话就有问题,这么做是最简单、最好实现,但是在线的业务占入资源很难释放,这跟离线集群不一样。所以说如果说有问题有可能需要人工去干预,这时候更希望在准入控制这一块立即得到反馈,而不是提交完整个APP之后部分Pod才能得到反馈。
GaiaStack关键技术
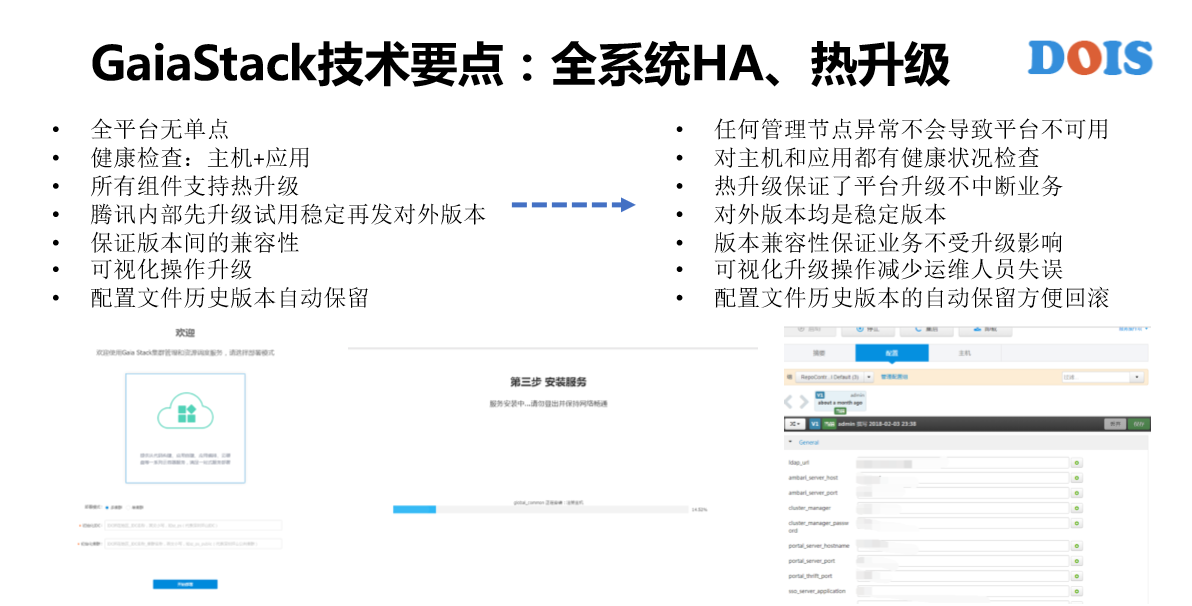
最后一部分讲一下GaiaStack的一些小的技术点。第一,全系统的HA、热升级。另外,这块有一个点是跟大家强调一下的,K8S是不保证版本之间有热升级的,所谓的热升级是什么概念?系统升级上面的应用是否完全不受影响。那K8S不做这种保证是可以接受和理解的。
比如说,微服务的应用在上面去运行,这个集群有几千台服务器,我们可以一个一个去升级,即便是一台机器上面的容器重启,那对微服务没有什么影响,没关系,意义不大。从1.7版本升级到1.9版本,我们发现容器重启了。但容器只是说重启,它还在,没有丢。这对于微服务来讲OK,对于有状态的应用、在线服务,甚至一些离线业务都是不可接受的。
比如说,我们的科学计算集群,他们在做H266的新标准制定,他们有的时候一个作业要跑两三周,所以如果我们一次升级给它所有重启的话,意味着可能两三周的计算完全丢失要重新计算。所以说,GaiaStack也要保证一个是热升级。GaiaStack的组件是一个月一个版本随便升级,上面的应用完全不受影响。不受影响,我们做了很多事,应该是在2015年初的时候,那时候知道DockerDv有一个问题是单点,DockerDaemon单点,而且那个时候DockerDaemon不稳定,有很多的Bug,然后经常有障碍。我们解决Bug或者增加新特性的时候要去升级,只要升级意味着上面所有的容器都会重启。这对我们来讲不可接受。所以我们向社区提交了最基础的热升级的版本,就是把DockerDaemon做了热升级,同样可以对K8S做这方面的操作。
另外,腾讯内部有非常多的集群。我们每次发布新版本的时候,一定是在内部集群先去试用才会对外发布对外的版本。另外,GaiaStack也是私有云产品,所以我们做的部署的产品,像安装Windows操作系统一样,这边输入有安装的服务进展,如果说哪一个环节有问题都会给我们对应的提示。这是GaiaStack的本身配置,我们可以在页面上查看、修改,也会有配置的版本管理,如果回退也可以回退。
做了这样之后最大的感受,也许K8S对大家的运维已经蛮复杂了,加上GaiaStack就更复杂了。所以说,我们有了这个东西部署就蛮快,其实也能够降低学习成本以及减少运维的操作,这一块有一个例子是说,我们有一个服务商,一个从来没做过容器的服务商,我们给它一篇文档,它用6个小时的时间把GaiaStack整个部署的情况完全学会,集群就部署起来了,其实蛮快的。
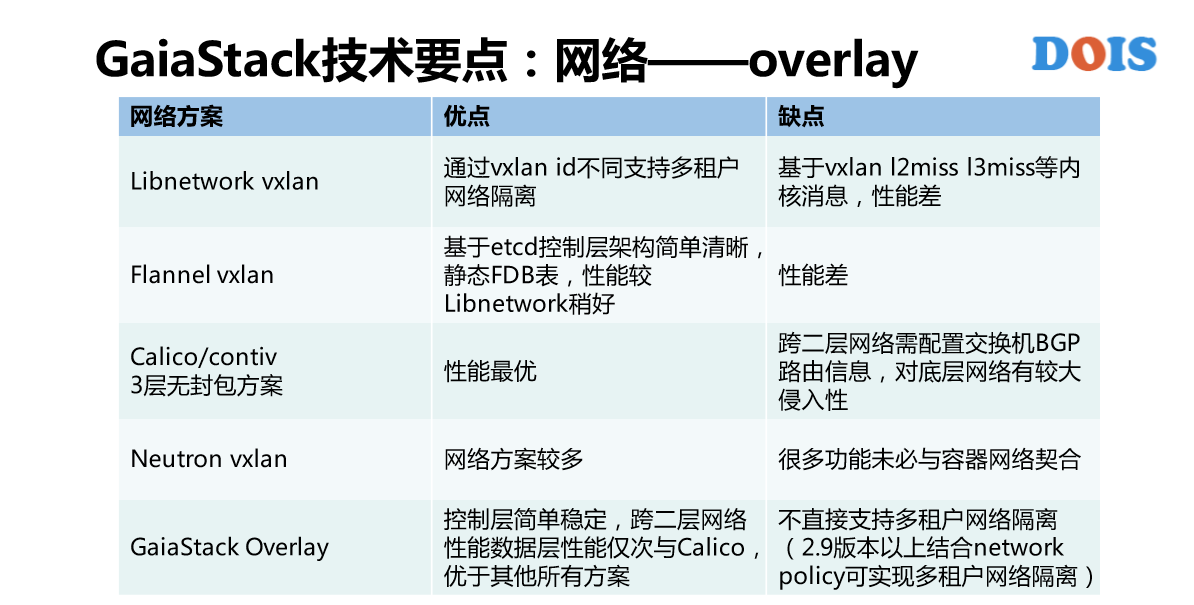
重点讲一下网络这一块,对于Kubernetes来说,很多的使用方或者是厂商都对网络这一块一定是重点。为什么?因为Kubernetes提供的还是CNI的标准,很多实现是没有的或者是没有一个标准的实现。GaiaStack这一块的考虑是,我们实现了所有的网络模式,具体来讲就是系统的网络模式。为什么做这样的设计?还是那句话,我们想做的是AII on GaiaStack,每一种应用,并没有说哪一种网络模式是适合所有的应用,而是说只有最适合自己的那种模式。
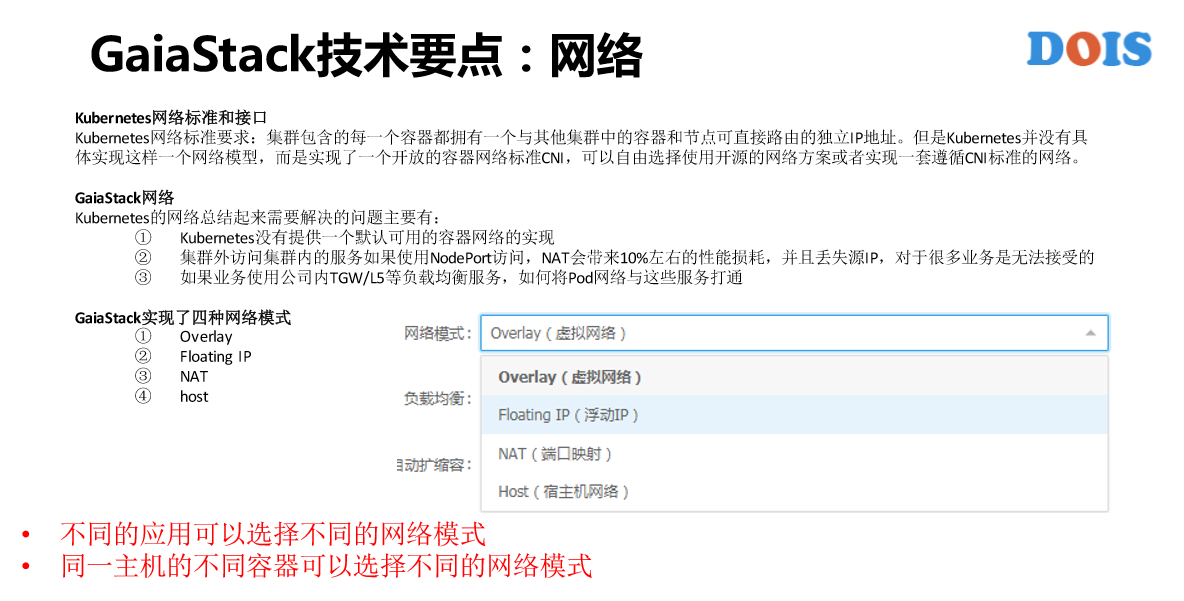
比如说Host模式好处是性能比较好,但是它有端口冲突的问题,比如说NAT一定程度上解决了端口冲突,但是它性能不佳。比如说Floating IP,每一个Pod有自己的独立IP,没有端口冲突的问题,也可以直接跟其他的物理机上或者是主机上的进程去直接通信,但是它的问题是占据了IT资源,这个IT资源非常的有限。比如说Overlay网络也是每一个pod一个IP可以避免端口冲突的问题,但是Overlay内部互通与外部互通。
比如说,离线的作业直接上到Overlay就好,反正是作业之间通行。但也不是绝对,不同的环境有不同的推荐方式。比如说,我们在腾讯云上或者是在腾讯的黑石上,他们给每一个物理机分配的网络就直接是VPC,所以说我们是跟他们一起去设计这个网络的。我们容器也需要它的VPC的IP,所以说在黑石这一块或者是腾讯云的VPC里面,我们的Floating IP没有IP资源的限制,所以说会给它更好的资源推荐。这块实现的是GaiaStack的自研网络插件,可以做到不同的应用直接选择不同的网络模式,另外同一个主机的不同容器也可以选择不同的网络模式,也就是在一个主机上可能有几十个,甚至几百个容器在跑,每一个容器都可以自由的选择网络模式。
第二,GaiaStack技术要点上有哪个考虑点?自营性。GaiaStack没有使用Calico是什么?跨二层网络需配置交换机BGP路由信息,所以不具有朴实性。我们这块的使用方案是参考了Contiv,没有二层也完全没有分包、解包,这是GaiaStack对网络设计的第二个点,性能一定要最好。这是我们的一个对比,最下面就是GaiaStack Overlay的方案,有一个缺点是不直接支持多租户网络隔离,但是2.9版本结合了network的policy来做这样类似的实现。
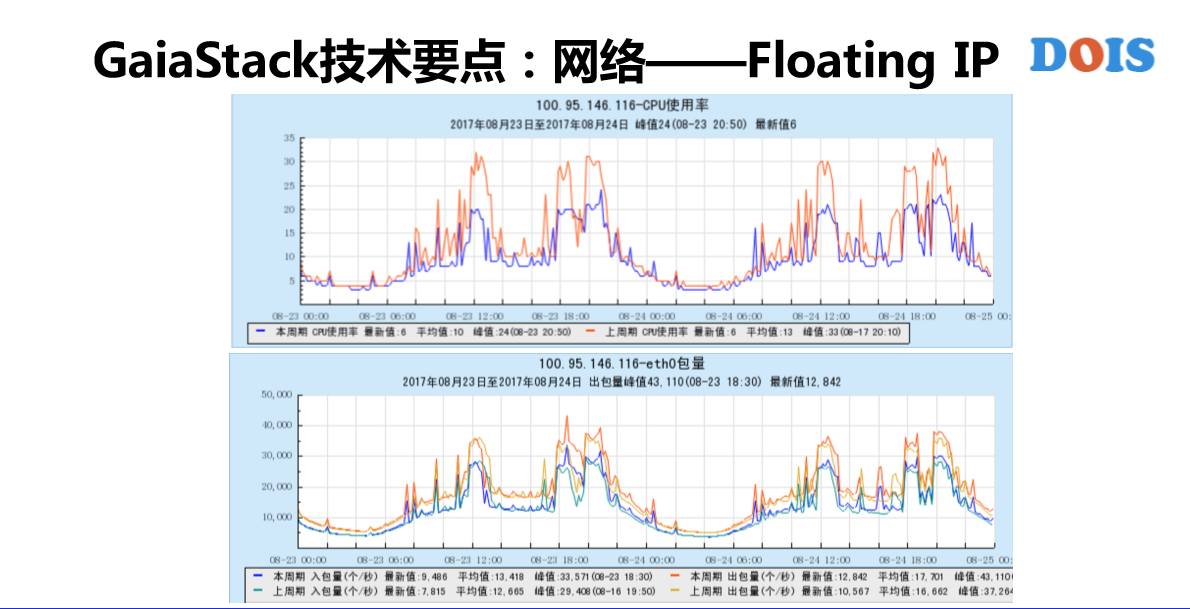
第二个,Floating IP支持三种网墙,但是在腾讯90%以上都是有SIVA的支持。这是上了新的支持之后看到的业务图,在它的业务最高峰期的时候,我们的包量大概增加了6%,但是CPU使用率却降低了1/3。对Floating IP的支持看到了蛮多的实现,GaiaStack这块也做了非常多的优化。举例,我们的VF的终端,本来默认可能是在一个盒上,在网络繁忙的时候这一个盒就是瓶颈。所以这块给做了负载均衡到不同的盒上,还有就是网络出带宽的控制,因为Kubernetes本来没有做网络带宽的控制,但是GaiaStack要做。做还是蛮麻烦的,如果没有Kubernetes的网络容器化,每家容器都做了, 来打标签就好了,很通用、很成熟。但是引入了各种网络模式之后,有时候有的场景下打的标记给丢失了,所以说网络出带宽一定要跟网络模式一起相去做配合。这也是我们去做的。
下面讲一下资源管理,GaiaStack有几个理念,第一个理念是把所有的容器都要纳入管理。大家听到比较多的是容器的一些好处、优势,我这块泼一个冷水,在私有云和公有云VPC隔离之下,这一块可以先暂时的规避。另外,它的另外的缺点是资源管理维度不够充分,我们知道用容器也好、用虚拟机也好,一个终极的目标或者它的价值是什么?是想让各个业务来共享主机的资源。那如果共享的话,隔离一定是前提,否则就有可能说,比如说以内存为例,我的代码有内存泄露,我申请两个G,可能用50个G都有可能,OMQ的时候,可能Q的不是我,有可能另外的容器申请的更多,它申请了60G,现在只用了58G,这是合理的,但它不是我。所以这就是共享下的不安全。任何一个资源维度,如果没有去做控制的话,其实都会有问题。
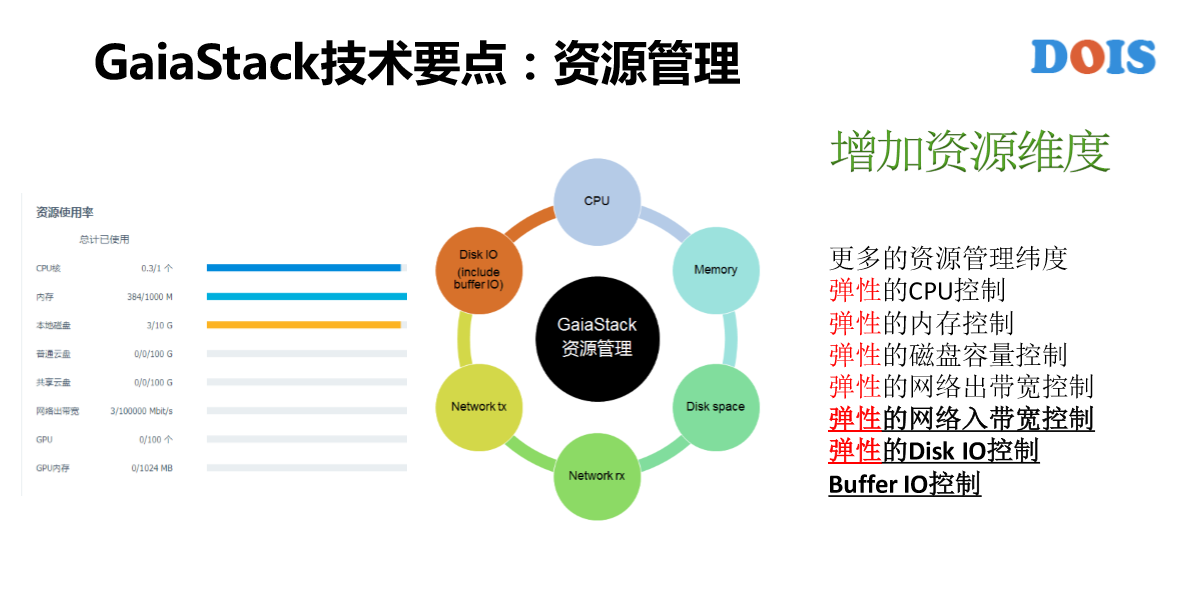
举例,我们以前在做广告业务的时候,某一个广告有8个集群,4个在线、4个离线,他们自己觉得太浪费资源了,想合并到一起,变成4个在线、4个离线,分布在4个地区。这样的话,如果说那时候只有CPU跟内存的管理,这样会导致一个什么后果?离线会很大程度上的影响在线服务,这是不可接受的。所以我们在2013年的时候就给他们做了网络带宽的控制,还有Disk IO的控制。Disk这块增加了资源维度,除了增加资源维度之外还要求所有的资源管理都是弹性的,弹性就是借用。就是说其他的没有用到的控线资源我可以去借用,有借有还。
这是网络入带宽的控制,网络出带宽的控制还是蛮成熟的方案,跟大家提网络入带宽。在容器这一块对资源的控制隔离主要是使用Cgroups。可以看到我们的设计目标,第一个就是资源保证,第二个就是弹性的概念,第三个、第四个不讲。这是一个实现。
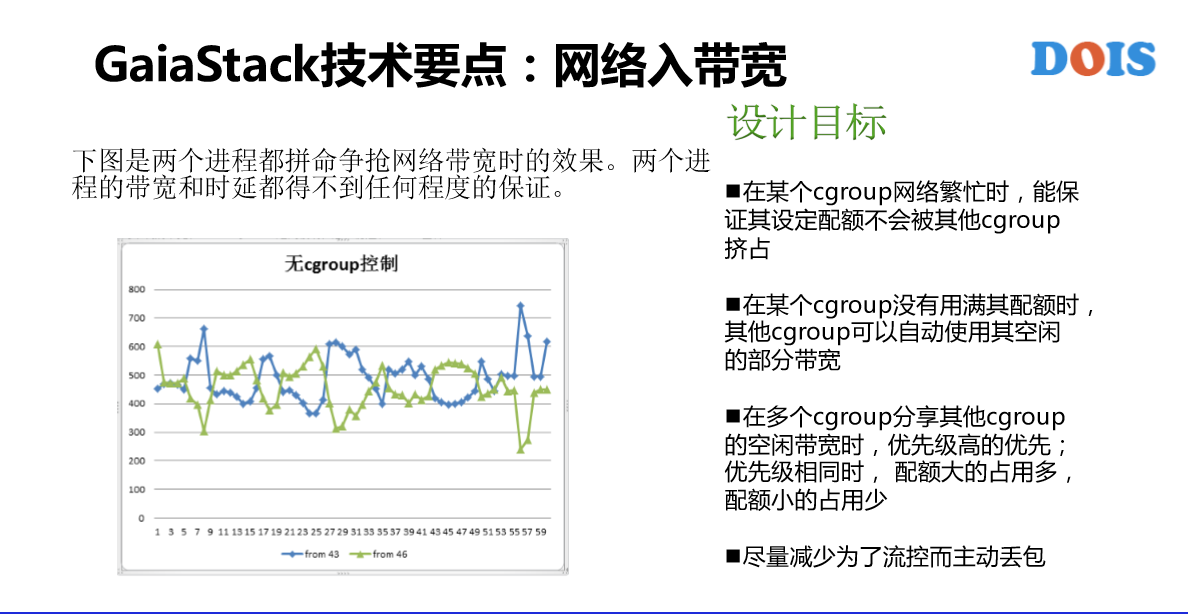
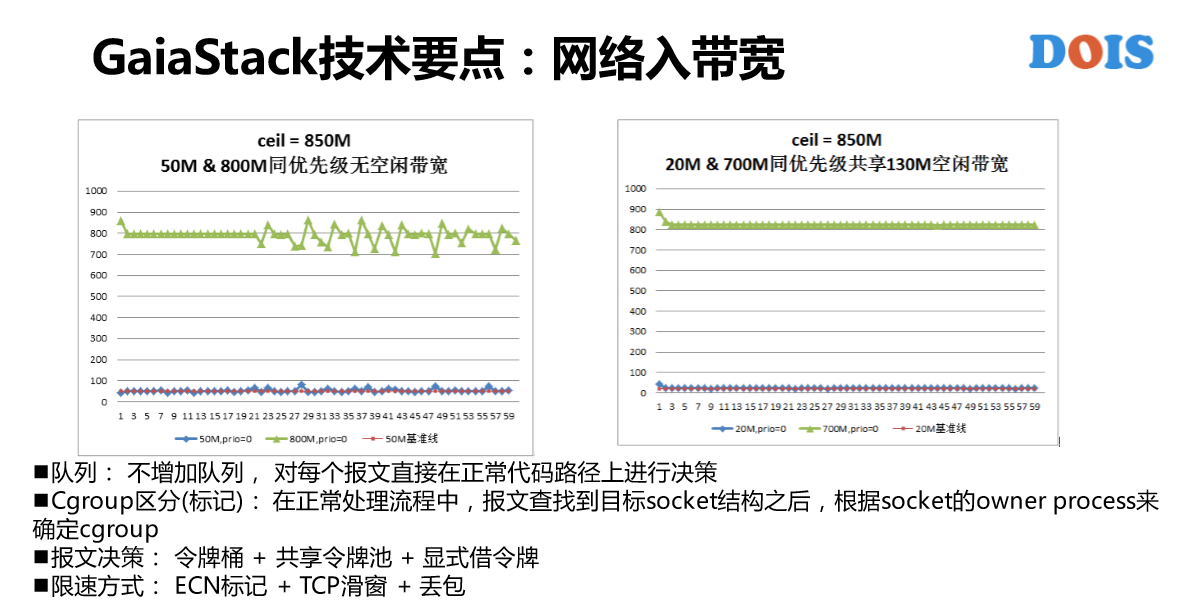
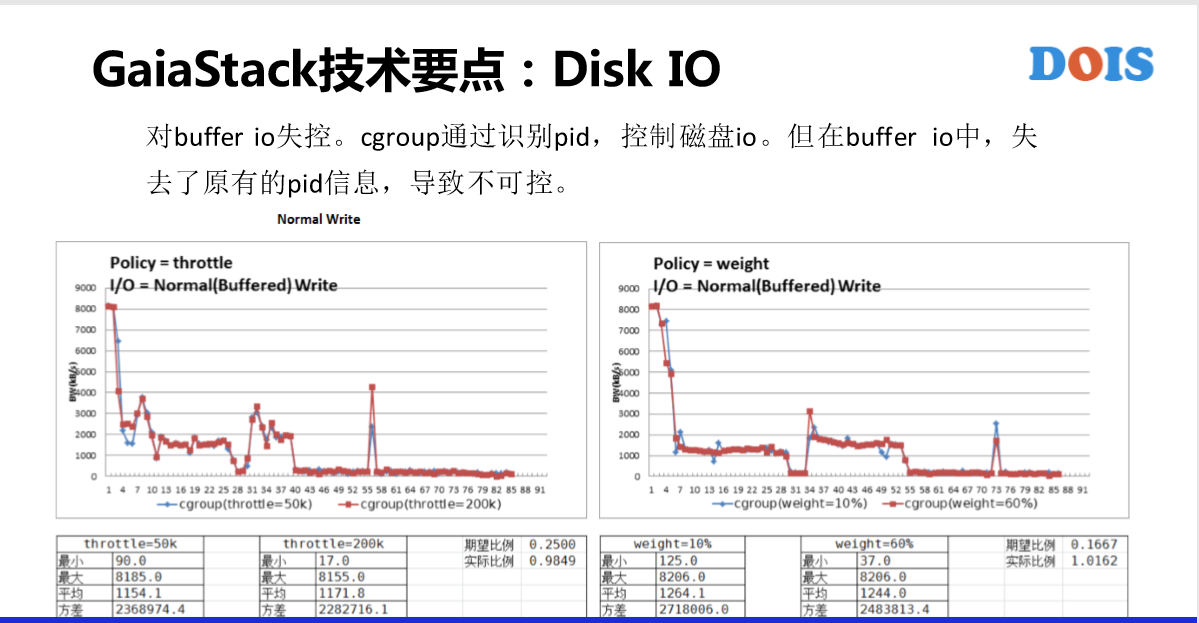
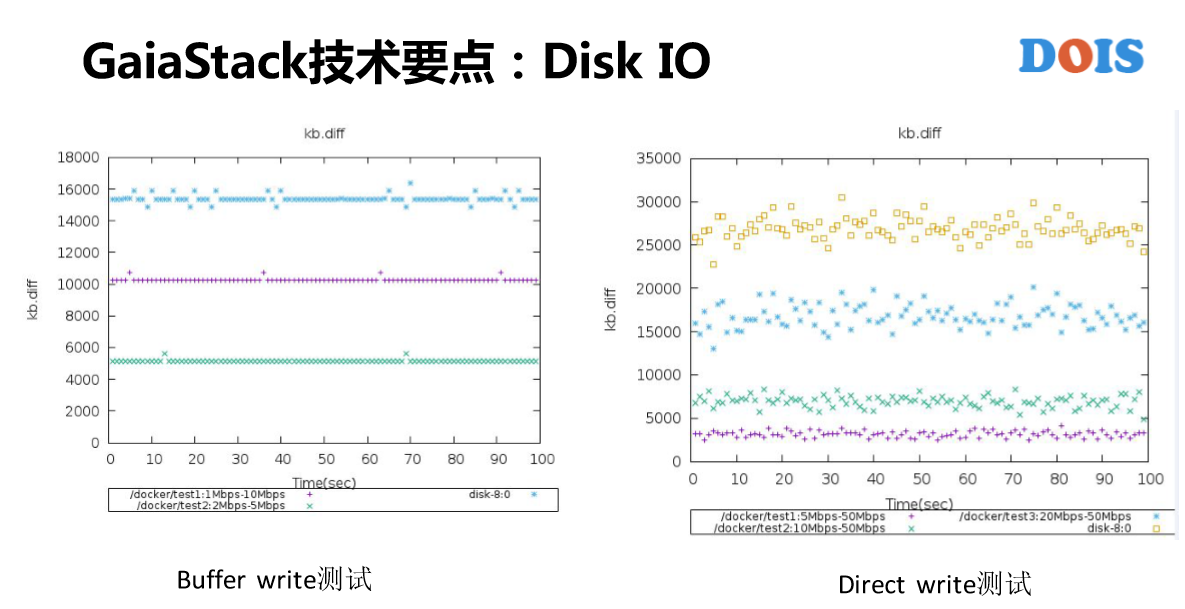
Disk IO网络入带宽有不同的一些点。在Cgroup里面是有子系统,跟网络带宽不一样。但是看到几乎没有什么人用这个,原因有什么?有两个点。第一,8核IO失控。第二,Weight CFQ,这块是对在线服务蛮有损害的,就是说它并不是一个一个的BIO、BIO的去控制,所以说某些时候有可能导致在线的服务质量得不到满足。
下面是存储管理。GaiaStack把本地磁盘的容量、管理也纳入了管理的资源维度当中,这块实现的目标是说,提交应用的时候可以来指定需要多大。这块的好处是跟原来的PV是不一样的,比如一个磁盘有100G,我可以给10个需要10个G的Pod去用。
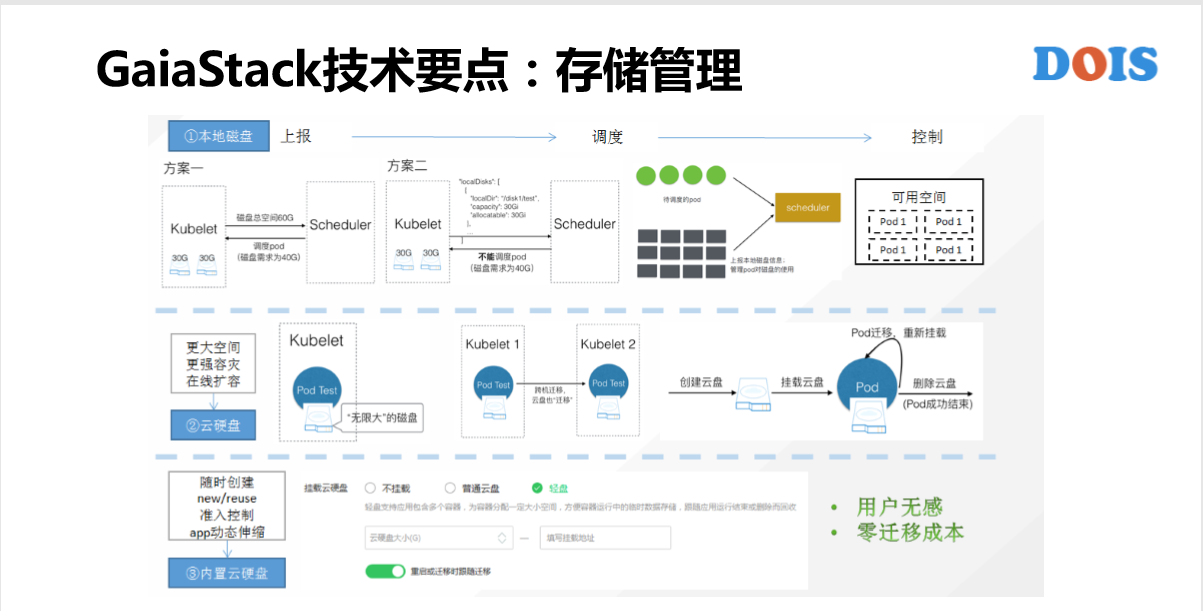
关于云硬盘,我们有普通云硬盘,然后有内置云硬盘,有共享云硬盘,有独占云硬盘,每一种都有场景,用的还非常多。存储底层用的是CephFS,为什么选择用CephFS有性能的优化,有一个项目名叫Fix,支持了Fix的需求。我们有做底层的GaiaStack系统所需要的人才。
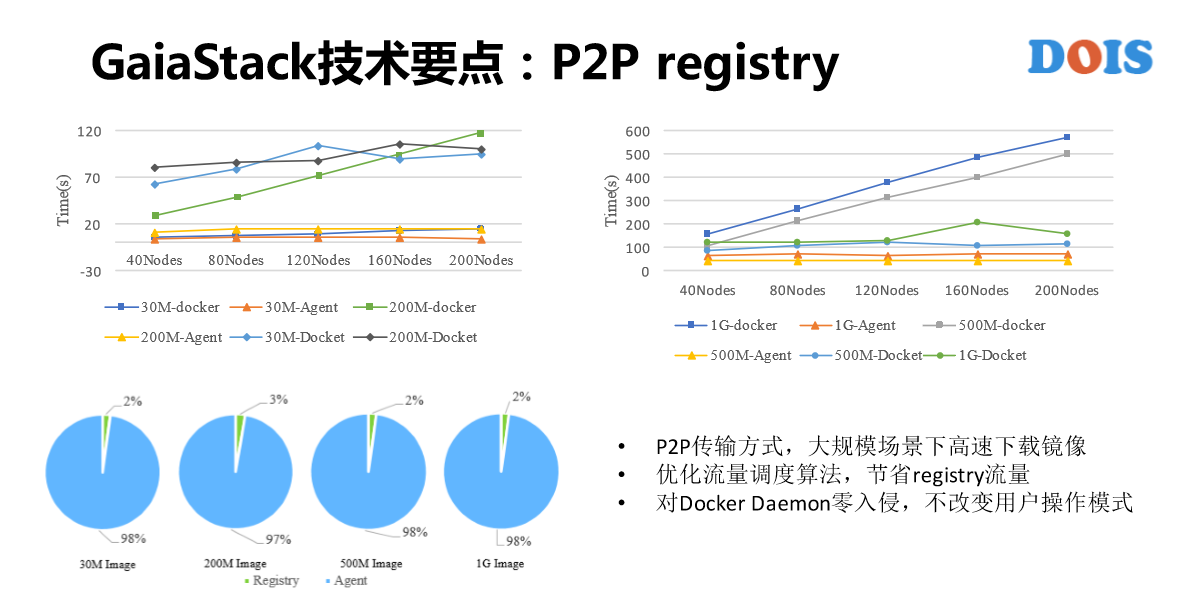
在容器的概念里面,我们需要很多的场景,对存储的需求。比如说,镜像仓库我们用了IGW,比如说共享云盘用了FS,比如说普通云硬盘用了RBD。
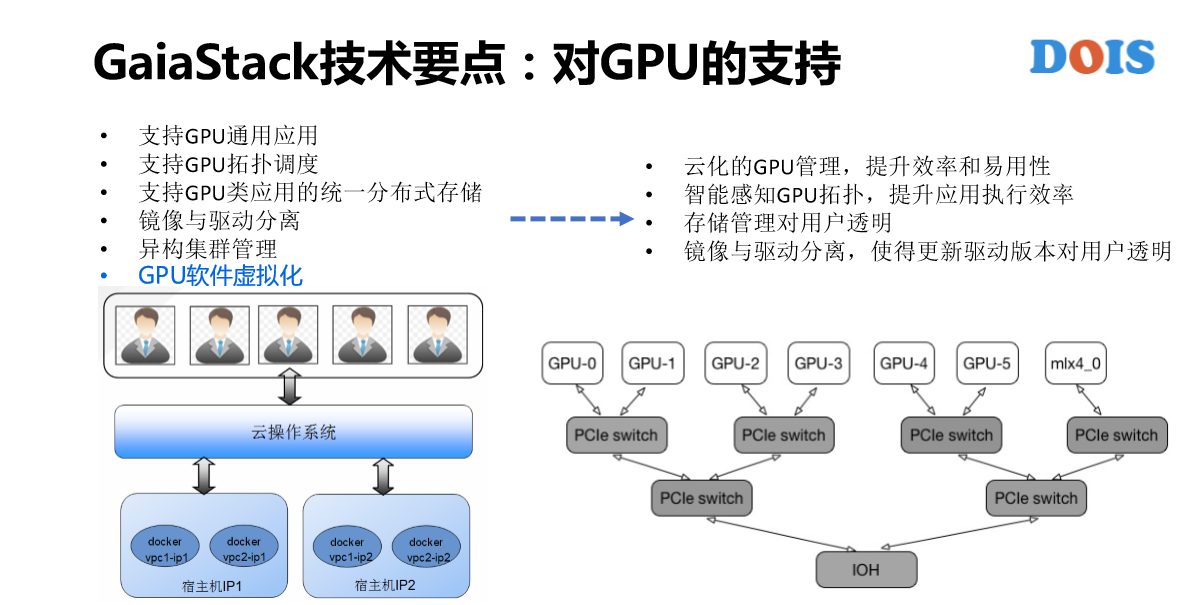
我们从2009年开始做容器,总结了腾讯十几年的运营经验,总结了新的类型叫Tapp,原来以为只需要我们自己用就好了,结果发现大家都需要。这是对GPU应用的支持,在2015年GaiaStack开始支持腾讯的GPU集群,我们做了蛮多的工作,这个也是跟K8S不同的点。比如说举几个简单的例子说,有一个Pod需要两个卡,我给它分配GPU0和1,给它分配0和5性能是完全不一样的,所以需要有拓扑的管理和控制调度。

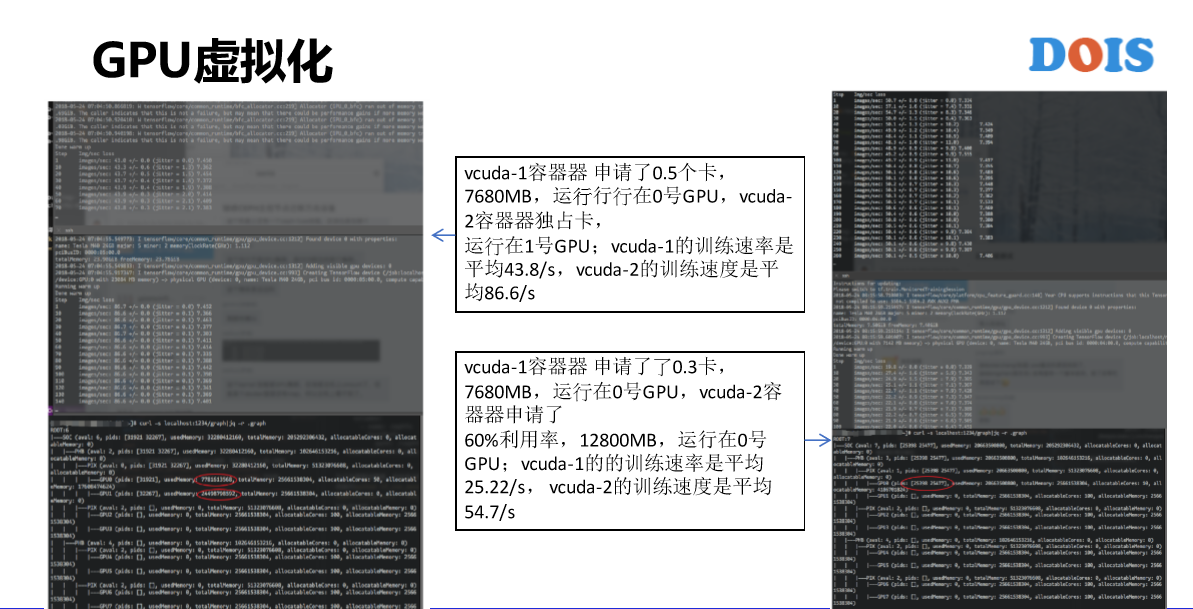
另外,我们从2015年开始做GPU集群,比如说英伟达发布的新的GPU型号频率太高了,所以说,很快集群就变成了异构的集群。对于CPU来讲还好都是一个核,什么样的型号差别不是特别大,但是对GPU来讲影响比较大。所以我们不仅是GPU卡也有型号。正在做的事情内部已经上线了,但是没有对外发布,就是GPU的软件虚拟化。GPU有硬件虚拟化,大部分企业采购的没有软件虚拟化,但是因为GPU太贵了,资源实在是太宝贵了,所以我们也对它开发了虚拟化的概念。我一个Pod申请卡的力度未必是一个卡,而可以是0.1个卡,0.2个卡这样子。比如说左边的这个图,第一个容器申请了0.5个卡,第二个申请了0.3个卡,可以看他们的分布。
最后讲一下GaiaStack跟社区的关系。大家可以感受到GaiaStack好像做的有点类似于原来做的自研的云平台T—BOX这样子,是不是跟Kubernetes完全没有关系了?这就是我们跟社区的关系。第一,我们会跟K8S的每一个大版本去做Merge,所以有非常多的Merge工作,这背后就要求所有的实现保证Merge工作是非常的顺利、快和轻量,所以很多的实现都是以插件的形式做的扩展。第二Kubernetes的原生接口全部支持,如果不支持意味着我们失去了Kubernetes生态圈的很多东西。比如说有微服务的框架跟GaiaStack直接对接,比如说等等其他的。另外也有积极的贡献社区,但是并没有以团队的去贡献。比如说这边有Docker社区,还有很多其他自研的组件。
这是我个人的微信,我们的目标是AII on GaiaStack。谢谢!

