@gaoxiaoyunwei2017
2018-07-27T07:32:48.000000Z
字数 9311
阅读 1947
如何落地全球最大 Kubernetes 生产集群
毕宏飞
作者简介
鲍永成
前言
京东数据中心里边的 JDOS 也是京东数据中心操作系统,随着数据中心规模不断的扩大,我们需要对数据中心做综合的考虑。所以一开始就先说数据中心的层面,大家知道数据中心里面有服务器、网络、技术软件,还有就是部署一些业务。
随着技术的发展,有一些集群管理、编排加进来。JDOS 1.0是基于 openstack 跟 docker 技术站实现的,它解决的问题就是随着服务器规模的增多,管物理机这种情况是越来越不太适合现在的发展。后来我们就做了基于 openstack 容器来管理这么多数据中心的资源,我们是直接跳过了虚拟机这一代,虚拟机在京东有些场景下是不适用的,特别是在一些高性能的情况下,如秒杀等,它的响应是不能满足我们的要求,我们也是随着业务驱动来做。2016年初,我们开始使用k8s,那时候我们上的是1.5版本,现在线上跑的是1.6的版本,不是大家想象的新的版本,后面我会继续解释这个情况。
京东的发展之路,一开始把容器当成虚拟机来用,原来所有的技术栈不用做太多的变化都能用上容器,这一步非常的关键,至少让很多研发人能够适用。在原计划过程中也会发现很多的问题,原来的业务10个物理机就够了,现在需要两百个容器,对人的定位和架构还有基础设施运营、负载均衡都带来极大地挑战,所以我们就构建了所谓的容器生态。
容器生态是什么?我们会把技术设施的软件运营、负载均衡、存储等等都给它IPIO化,通过IPIO可编程来驱动。运营不再像以前那样走各种流程,完全是点一下就发布了,目前通过IPIO的方式。
再往后 Kubernetes 时代来了之后,基于 Kubernetes 做了集群的编排,在整个京东的 JDOS 发展过程中,它们只是生态中的一环。大家不要说作为 PaaS 里面全是 Kubernetes ,光有 Kubernetes 不一定玩得转。比如日志怎么搞?监控怎么搞?不是来了一个新的东西冲上去就可以了。
我们从2013年建的团队,2014年大规模上线到现在运营了四五年,基础的一些东西搞得相对来说比较稳定,也达到预期。现在的重点是在资源的调度,随着数据中心规模进一步扩大,资源的调度会提上日程。它的威力还是非常大的,能够带来很多成本的节约,还有一些业务的弹性,后面我会重点介绍这一块。
今天我的分享主要有以下四个部分:
1、Container Eco System
2、化繁为简 K8S重构
3、大规模集群运营
4、巡检与可视化
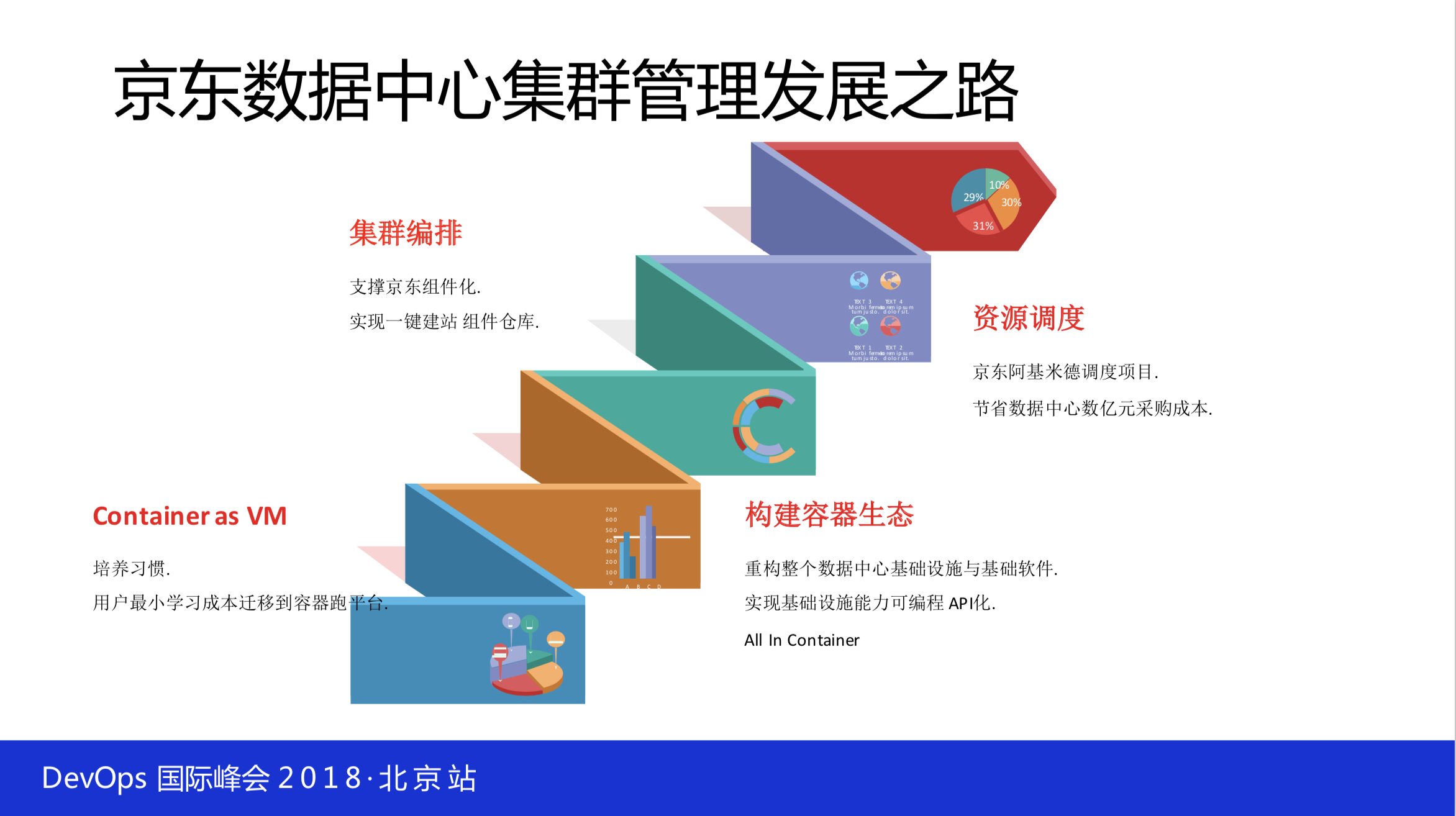
一、Container Eco System
先说说第一块是所谓的生态系统,不管你是用 Kubernetes 还是用什么,你的域名、负载均衡、分布式可控系统、镜像中心、日志、监控,这些东西都是围绕着容器生态往里面建。

比如说,如果公司里面原来已经有监控系统、日志系统,那你要跟它做很好的对接,可能需要改东西或者不改都有可能。但是你要想到这一点,不能说拿过来什么都可以改,这也是不现实的。
1.1 system架构
下图是我们部署的结构,这应该还是比较简单。给大家提一点,我们 Kubernetes 集群建的是很大,再大依然装不下所有的机器,现在是有几十个 Kubernetes 的集群,每一个集群有大、有小。大的能达到上万台,三个物理机房大概一万台做 Kubernetes 集群,也有小的在不断地建,也就是三四千台、四五千台这样的。
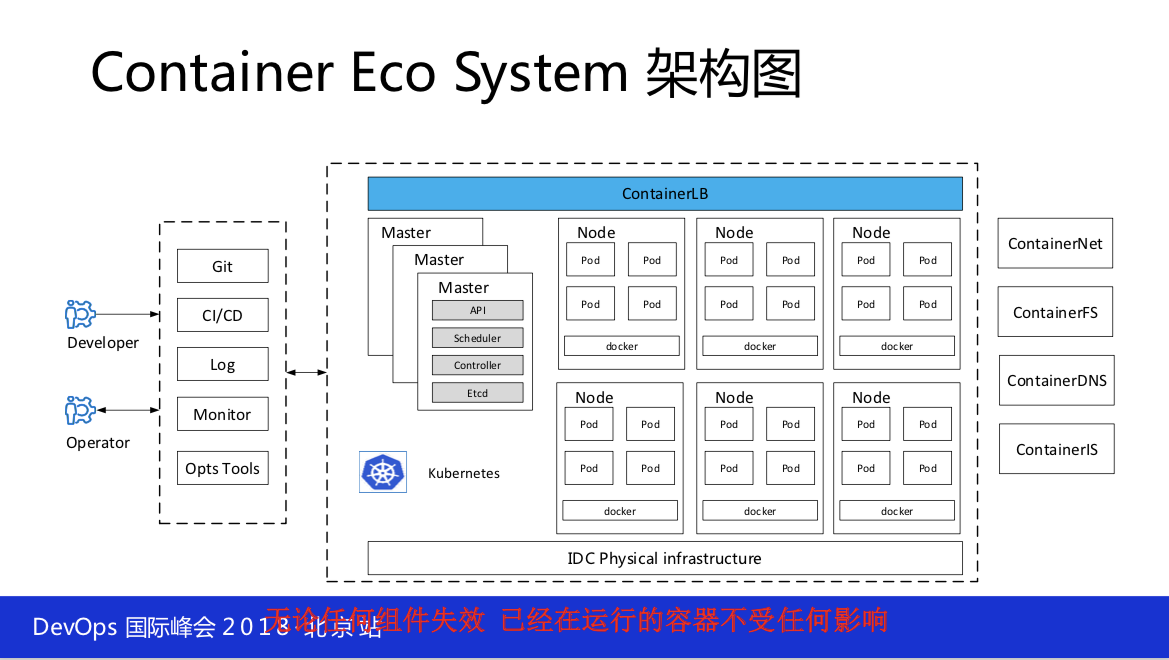
这里提一点,上图的红字要记住。所谓的基础设施架构与技术就在这一点, Kubernetes 不能代表基础设施,上面支撑的是业务,下面不管你用的是什么技术都要确保你的可靠性,暂时先不说性能,可靠性这一块你要特别的注意。所以说你用 Kubernetes 的话要确保即使任何组件的失效,上面已经运行的容器不能发生任何的变化,这一点如果大家已经在做 Kubernetes 集群的话回去可以做这方面的准备或者说是一些方案。比如说,你把 etcd 停掉24小时会发生什么,把api停掉会发生什么,这些都要做,否则一旦发生故障是没有那么快的时间可以解决的。
1.2 Container DNS
Container DNS,它只做DNS解析,也有一些很多其他的功能,但并不是那么的完备。
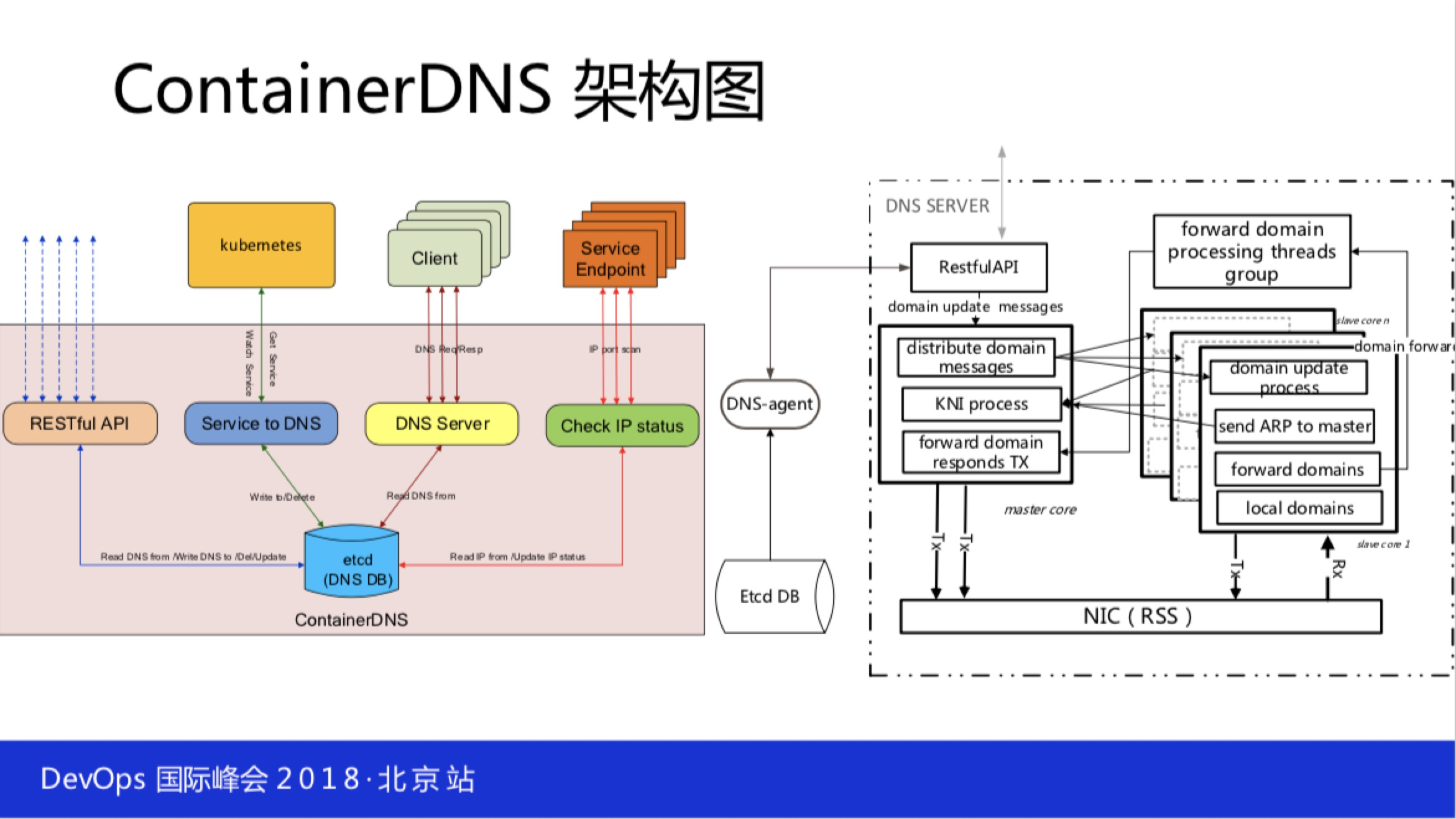
比如说它能不能跟 Kubernetes 做一个很好的对接?它能不能钩在 Kubernetes 的 etcd 上直接做域名的发布解析的变更。能不能分布式部署?比如说你有三个数据中心,三个地方都要布你的域名解析,每个数据中心都有,那你原数据的同步等等这些问题。所以说,软件分布式的思路可能解决这个问题,你可以三个数据中心钩在一个 etcd 集群上面,任何一个域名发布几个中心都是同时发布感知到的。
这里面我们还做了一件事情,这是开源的,现在的性能很普通,它是可以扩容布很多个,今年年初改进了一版用右边的图做DNS的解析部分。性能非常好,单实例是可以做到800万QPS的,也就是整个数据中心布三台完全够了,2400万QPS。

一般延迟是在15微秒到1毫秒左右,但是我们新做的DNS解析性能非常的稳定,会是你原来延迟的一半,而且特别的稳定。
1、3负载均衡
负载均衡,传统的负载均衡像LVS或者其他的,这说的是四层加七层的方式。就四层这一块而言,你还得适应。为什么叫 Container LB,其实就是适应容器计划的架构,它也要能够感受到 service 变化来通知它发生变化,这样才能自动发布,不再是以前人去挂流量,不然 Kubernetes 的特点你就用不上了。你不能用 Kubernetes 里面的 service ,它是不能作为生产环境的,很多东西都不能做生产。
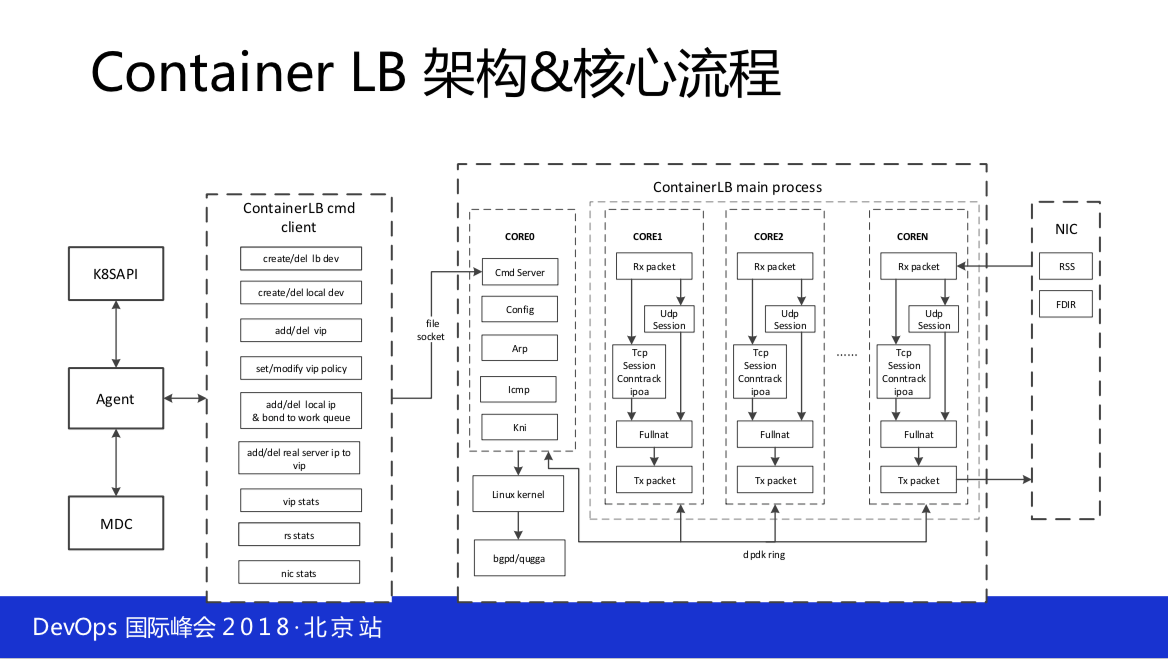
比如说,包括现在的 kube-dns 做生产也会有很多的问题。 Kubernetes 并没有承诺的那样子开箱即用,但是对我们的帮助也是非常大的。至少它把最新或者最好的数据中心管理理念以代码的形式输出给你,按照它的模型,比如说 service 的模型、 deployment 的发布、副本rs的控制等等还是非常的有用。
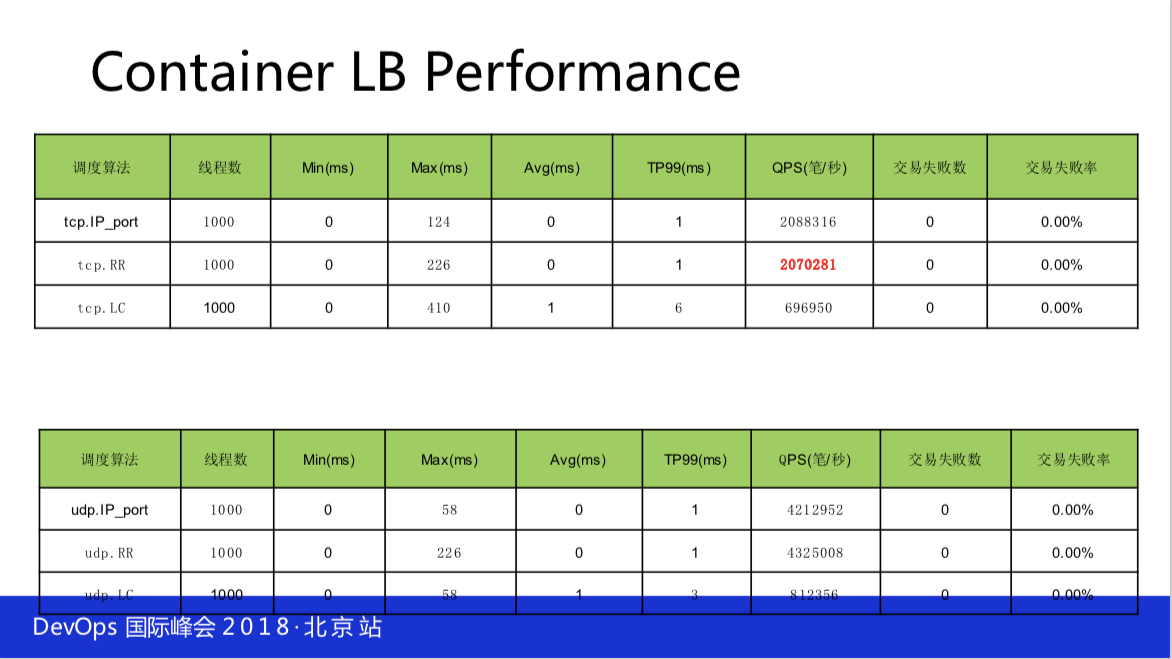
这个是我们的两边性能,Container LB Perfomare,也是开源的。
二、化繁为简 重构K8S
刚才提到 Kubernetes 有大集群,也有小集群,为什么大集群?两千台集群不是挺好的吗?规模挺小的两三千个也是可以的,问题是你要建几百个就很难受,人力、物力跟不上,管理成本特别的高。 Kubernetes 它是一个开源的东西,你只看到了上面的这一部分非常美好的一面,其实它下面还有大量的东西,如果你不去掌握它的话,可能出问题的时候基本上就抓瞎了。

在 Kubernetes 的早期发生过很多的故障,有的时候发生了一些故障,故障优先级都没法定,倒掉的可能性都会有。大家一定要记得,你要做严格的测试跟 预案。

- 第一,严肃负责。k8s拿过来,不管你改它还是不改它,你都要对它认真负责做严格的测试。生产环境是严肃的环境,任何开源软件必须经过亲自严格测试。所以说,你要在你的环境上做适当的测试。
- 第二,化繁为简。k8s提供了很多的功能,它是从 Google 里面找出来的,不管是 Google 的应用开发水平还是技术设施水平都远远高于现在的水平,这大家是要承认的。所以它提供的东西并不能够满足你现在数据中心的现状,这是大家注意的。你要用它需要的功能,比如说我就要弹性或者是业务弹不起来就要跟你弹,这就行不通了,所以说要有变通和实事求是。
- 第三,规模哲学。大集群的主要原因是运维成本的问题,我们运维几十万台机器其实就两个运维。
- 第四,可运维性。运维自动化跟可视化的东西。
做集群不管是大规模,还是小规模都要做四件事情:

第一,规模预估
第二,性能瓶颈
第三,稳定加固
第四,功能定制
2.1 规模预估
你是建两千台的规模还是建五百台规模,你先要有预估,然后看有没有什么稳定性的问题。还有一些基本的测试,如果你有1000的规模,假设你有25000个pod的级别,15000个 configmap ,其实远远不只这些,我们密度比这高得多。
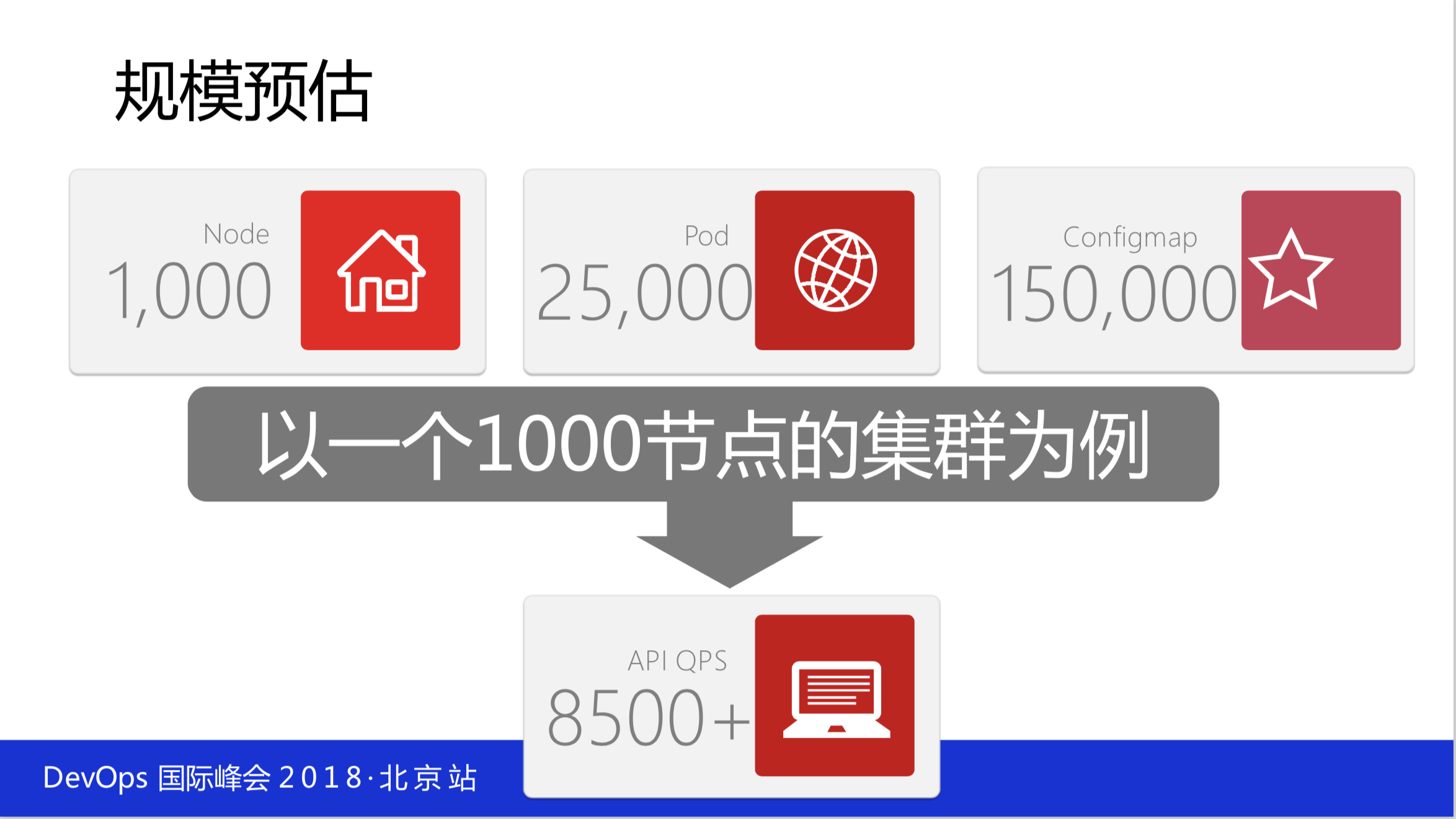
早期是大容器,现在全是小容器,按常规的来看,QPS要达到8500,就是它的API的处理能力。如果你的 etcd部署在很烂的机器上是扛不起来的,不要看它说五千台还是多少台是没有意义的,要看你承载了多少个容器和多少个 configmap 。
可以从细节做一些优化,比如说API的相关参数,可以限制单个API的处理能力。这要做一个规划,你一千台的规模用了10个API,每一个API处理850个QPS,所以你要进行规划。还有 Docker 的优化,DM尽量使用单独的盘,共用盘时DM参数需要根据盘容量优化使用native cgroup driver,设完 Kubernetes 之后全是内核在干活。

Docker 的隔离性也还可以,但是你部署的业务密度到一定层面的时候,互相影响还是有一些的。我说的影响不是大家理解的限制它的CPU是用4个CPU阀值,它就是乘以4,不是这样的。比如说内存用到4G就触发OM这种是非常的简单。我说的是比如上面跑了10个容器,9个容器跑得性能还可以,CPU达到50%,但是会影响另外的一些容器,它会有个别的性能会差。为什么会差?在内核而言,内核不知道容器的存在,看到的是一个个进程,比如说在一台机器上看到的进程是1,但是在内核来看就是一个进程,可能在内核里的进程是一百,可能是两百这样子。所以调度还是在内核里面进程的调度。
比如说,有一些容器它在大量读文件,这个时候整个操作系统触发 cache 回收的话,整个内存是全部被锁住的。虽然很短是毫秒级的,但是这个时候建一个连接过来是它是 flock 住,等内存能够工作的时候才能继续往下走。这个数据会产生一个毛刺对业务来说,所以这块你要特别的注意。怎么做?完全杜绝是不可能的。本质上天生就是这个样子,你就要对业务的进程设优先级,核心系统保障就好了,至少来找你的人不是核心系统的人来找你。
上图右边提到的节点资源预留特别重要,不能把你节点上的资源都提供,你自己还要过日子。你的 Kubernetes 的进程、网络进程、日志收集进程、监控进程,这些进程都需要资源,不能把它用完。 Kubernetes 里面虽然有,启动的时候 Kubernetes 可以保留资源,但是我告诉你去看一下它的代码,一直到现在最新的1.11,CPU的 zero 什么都没干,它写了一个不知道怎么干,然后 return -1是什么意思?就是 return 了一个 None 。也就是你的 limit 设置的大于数组机的CPU总核就会把机器打包,我们提了一个 path 可以把它合进去解决这个问题。虽然你一万台机器一周可能只打包一两台,但它可能会形成一个雪崩项。
系统参数的优化,大家知道原来一台物理机上跑两个业务,现在是一台物理机跑50个,这个时候操作系统的内核会被放大。比如文件服务,原来一台物理机设20万、10万就够了,现在是不够的,要设到100万、200万。包括内存的回收机制等都要做相应的调整,根据你业务的负载。否则你业务上去了性能会非常的差,当然你的业务并发量不大可能感受不到的话,正常的业务是有现实感受的。
2.2性能瓶颈及优化
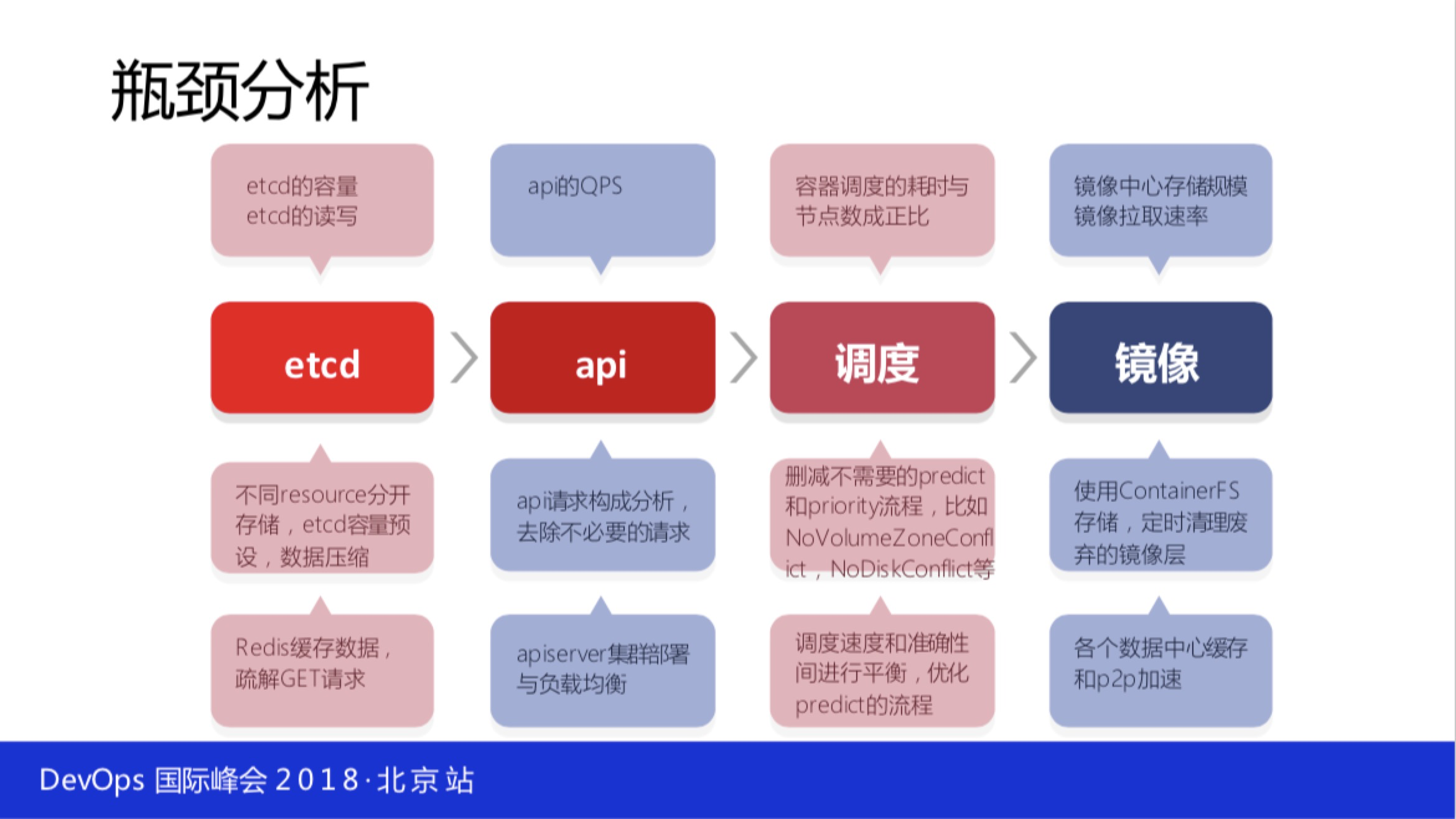
- etcd:etcd 是最大的性能瓶颈。
- api:api本身是没有作用,最终还要落到 etcd 里面去。
- 调度:Kubernetes 的调度性能是非常的差,它的性能与你的规模成反比。这是什么意思呢?当你有一千台的时候性能会衰减10倍,当你有一万台的时候基本上没法看,调度一个pod得要一秒多,这是不能接受的。
- 镜像,生产环境是严肃的环境,长期以来会有大量的镜像,这时候在分发的时候可以采用CDN技术,就可以解决下载的问题。规模大了会用P2P的技术,规模不大是不需要的,一两千的时候用P2P是没有意义的。上一两千台的时候要有10个镜像,10个节点上P2P有什么意义?我们有的时候有一些业务比较变态,一个核心系统可能就是三千个容器,这种会有P2P。正常情况下几十个副本数是不需要P2P的,技术不能过渡的滥用。
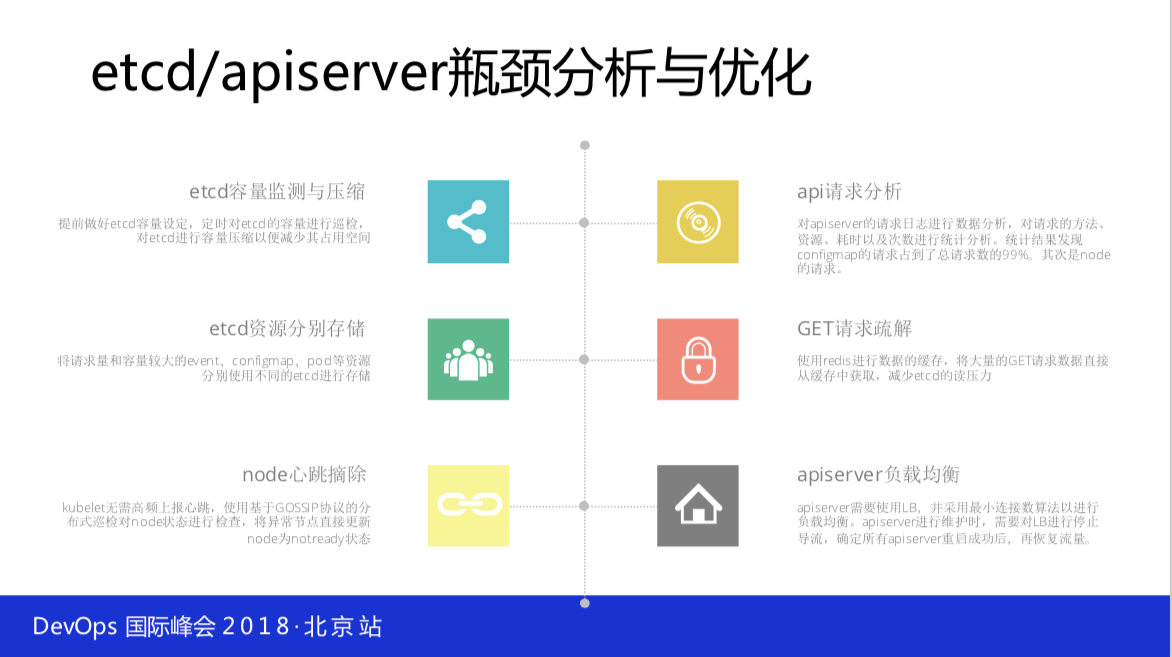
这是分析性能,etcd 有好几次直接宕掉,恢复没办法恢复。在生产环境使用要像数据库一样做好运维的方案、预案这些东西,比如说数据的备份、快速恢复。告诉大家一个小窍门,现在我们是这样快速恢复的,搭若干个空的 etcd 集群,当有 etcd 集群出现问题的时候,我们会把数据直接拷到空的 etcd 集群,把这些域名直接拿过去快速恢复。就地恢复会有很多的问题,当时的状态各方面的太不确定了,最好的方式是集群小可以不用 etcd ,现在基本上 etcd 依赖已经很小了,就是用 redis 还有 mysql 把它给去除掉。etcd 是个好东西,但可能还是我们的时间有限,对它的掌控不是那么的完美,但 etcd 又那么的关键,数据都在里面,这是非常大的一件事实。
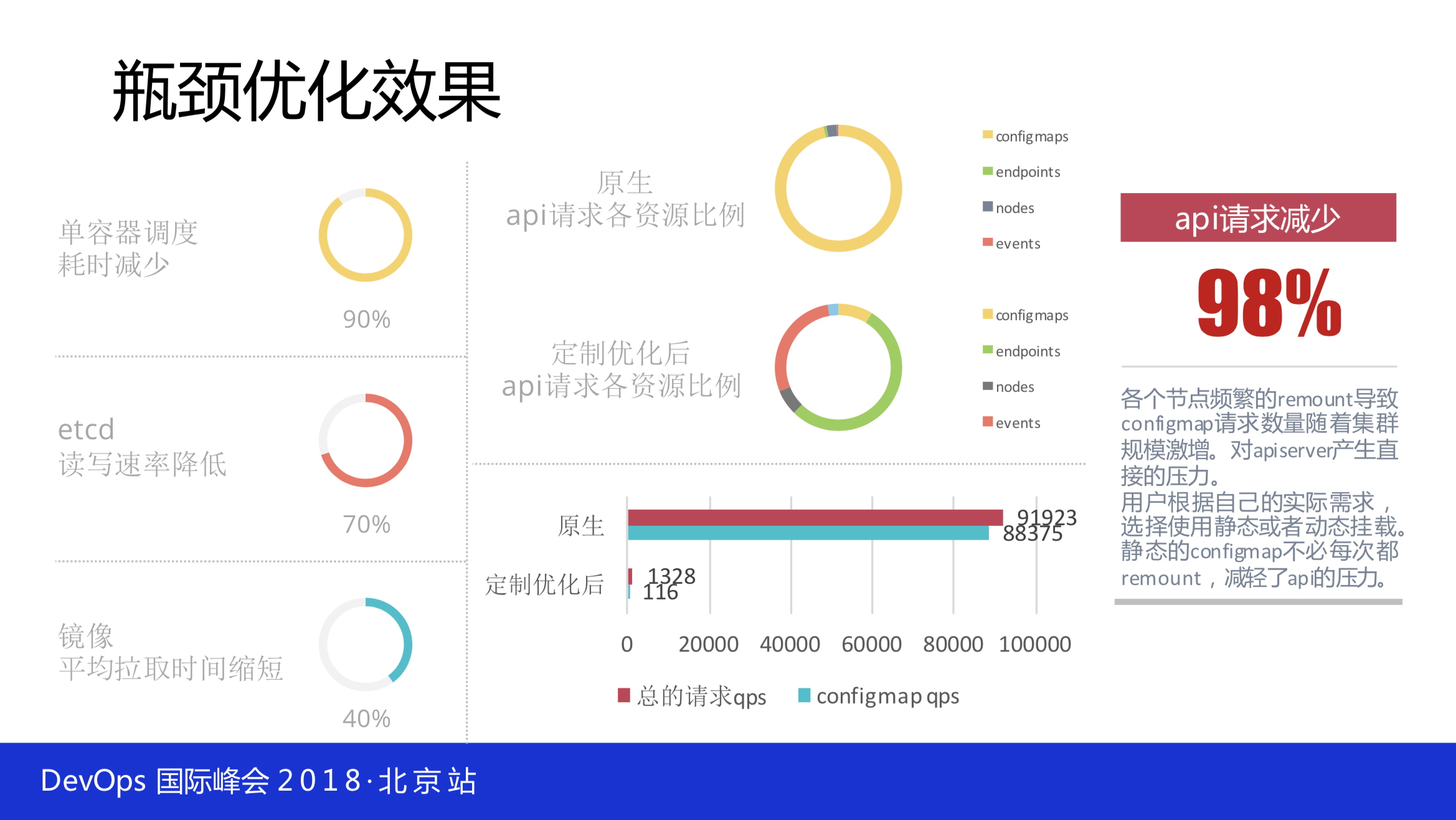
还有像API的负载,不可能只布一个,要布很多个,前面要导负载均衡,让你的 Node 连上它。它是长连接,连接不断。它不是短链接,下次就会均衡。整体对API的分析也很简单,你会发现大量的请求是 configmap,这个 configmap 请求数量随着集群规模激增,对 apiserver 产生直接的压力,用户根据自己的实际需求选择使用静态或动态挂载,静态的 configmap 不必每次都 remount ,减轻了API的压力。API请求减少98%都是 remount 的进程。
2.3稳定加固
谈到稳定性,我们必须要说的是以下四个点:
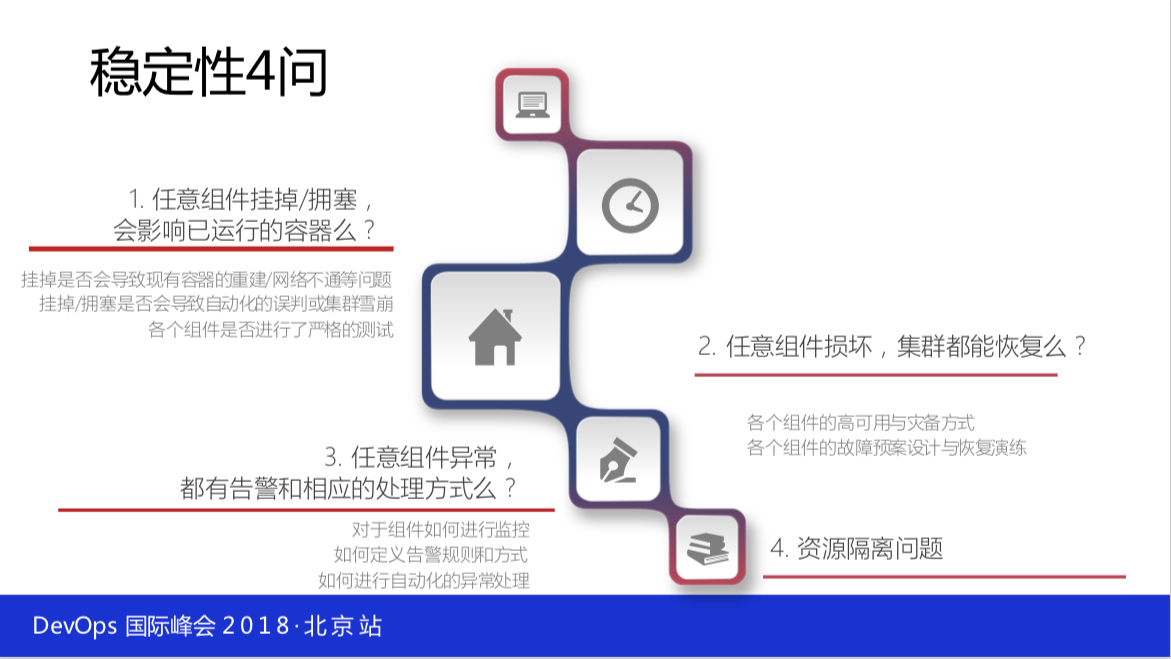
- 任意组件挂掉或者说不响应等,你已经运行的容器千万不要受到任何影响,这是守则。你要做这个容器的话必须这样,否则没办法往下走。
- 坏了要把它修复好,不能坏了放那儿,所谓的坏了是不能上下线,不能创建新的、删除旧的,但是已经运行的已经提供服务的不能出任何的问题,但仅仅这样是不够的,还得要把它修复好。所以用之前要做很多的预案,比如说 etcd 坏了怎么修复?API怎么快速扩容?k8s有问题怎么快速重启等等这些问题。
- 任意组件异常还得有告警和相应的处理方式,不能自己还不知道。
- 资源隔离的问题,你要规划你的控制节点用哪些资源。
除此之外,你还得贴近一些需求,之前说了 Kubernetes 是从 Google 里面出来的, Google 的软件开发水平和基础设施都是比较强的。但是实际的生产环境会有很多非常有意思的需求,比如说有一些人在容器里面拉了大的模型文件,很多的模型文件很大,有可能是4G或者是8G的模型文件,但是升级的时候只升级了 service 的代码,如果这个时候再去拉8G的文件加载,上线一次会很痛苦,花几个小时都有可能,那号称你上线快的会被人挑战。
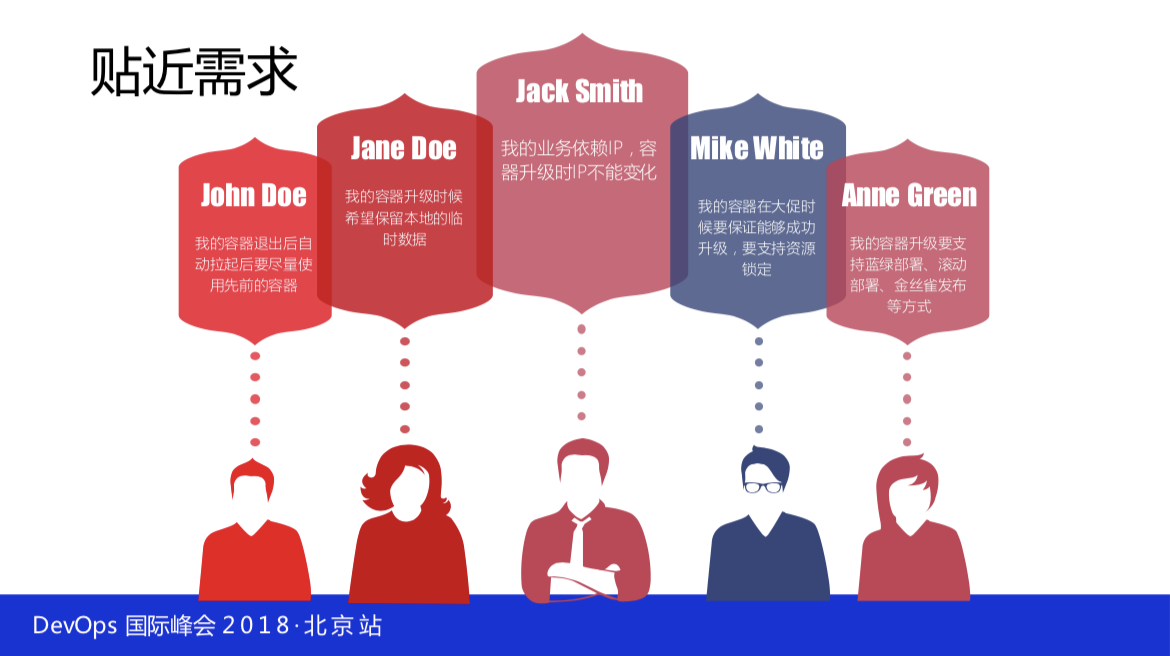
John Doe,我的容器退出后自动拉起后要尽量使用先前的容器。
Jaen DOE,我的容器升级时候希望保留本地的临时数据。
Jack Smith,我的业务依赖IP,容器升级时IP不能变化。
Mike White,我的容器在大促时候要保证能够成功升级,要支持资源锁定。
Anne Green,我的容器升级要支持蓝绿部署、滚动部署、金丝雀发布等方式。
你选择保留IP的方式上线,那就要先销毁一部分,比如销毁两个上两个这样维度上线的方式。如果你对IP的保留方式不够可以直接上10个新的不变,再把新的全部干掉也是可以的。
2.4功能定制

Kubernetes 里的策略还要做一些定制,比如说,节点被重启的情况,你先拉起的是新的调度过来还是拉起老的?这都是一些策略的定制。我们是先拉起老的,后拉起新调度过来的。
Rebuild 的功能是就地拉起,类似刚才说的那个功能。这个有什么好处?

- 第一,它是创建Pod最快的方式,有一些核心系统,一个系统是三四千个容器,你调度上线性能也会拖慢,因此它就地升级,能够达到镜像上线的好处,验证的成本会降低。
- 第二,继承之前 local 数据盘数据。在数据中心里面依赖B,在上线之后性能测试之类的已经做过严格的压测,达到在数据中心比较优的状态,不要轻易地去破坏它。比如说你有一百个容器,在两个房间,不一定会放在一个房间。两个房间是什么意思?跨了核心,要再绕一个核心才能过去。如果这个时候原来在一个屋里Pod的,正好依赖一个业务也在这个屋里Pod,这个时候会达到性能平衡的状态。这时候弄50个扔到另外一个Pod,会发现原来一百个都是平的,突然发现这50个稍微高一点点,业务会来问你这是什么情况?然后你盘查会有大量的时间精力。当然会影响一定调度的敏捷性,但是有办法能够解决的。
- 第三,整个容器里面的网络是至关重要的一环,一个Pod一个独立的IP,这样子会导致一些问题。比如说,数据中心的IP的数据量会极度的增加,原来我们IP段规划了几年,被我们提前5年消化掉。整个社区的网络架构,大家也是清楚的,我们用的不是叠加的网络,这样的性能会达到最好,但是有一些问题是规模受限于 etcd ,出去跟进来的路由是两个路由,有可能能进不能出,所以我们自己写了一个更简单的,它就是一个进程负责添加路由、删除路由。
我们现在能做到的是一分钟能够分配15万个IP。创建容器的速度有多快?就靠镜像。如果我们提前通过P2P分发的话,创建容器的速度也能达到一分钟15万个容器。
三、大规模集群运营

Google 的 Borg 是单集群,是10K+一万台, Kubernetes 是号称5000台,其实在1000台的时候 Kubernetes 就有问题了,可以自己亲测一下。我说的是要跑一些业务,模拟一些业务也行,你不能说随便挖几个Pod不干活,那没有什么的压力。 JDOS1.0 是6000台,两个物理Pod,现在 Borg 是有3个物理Pod。
四、巡检与可视化
日常的运维我们只有两个运维,我们把日常运维大概分为以下四个点:
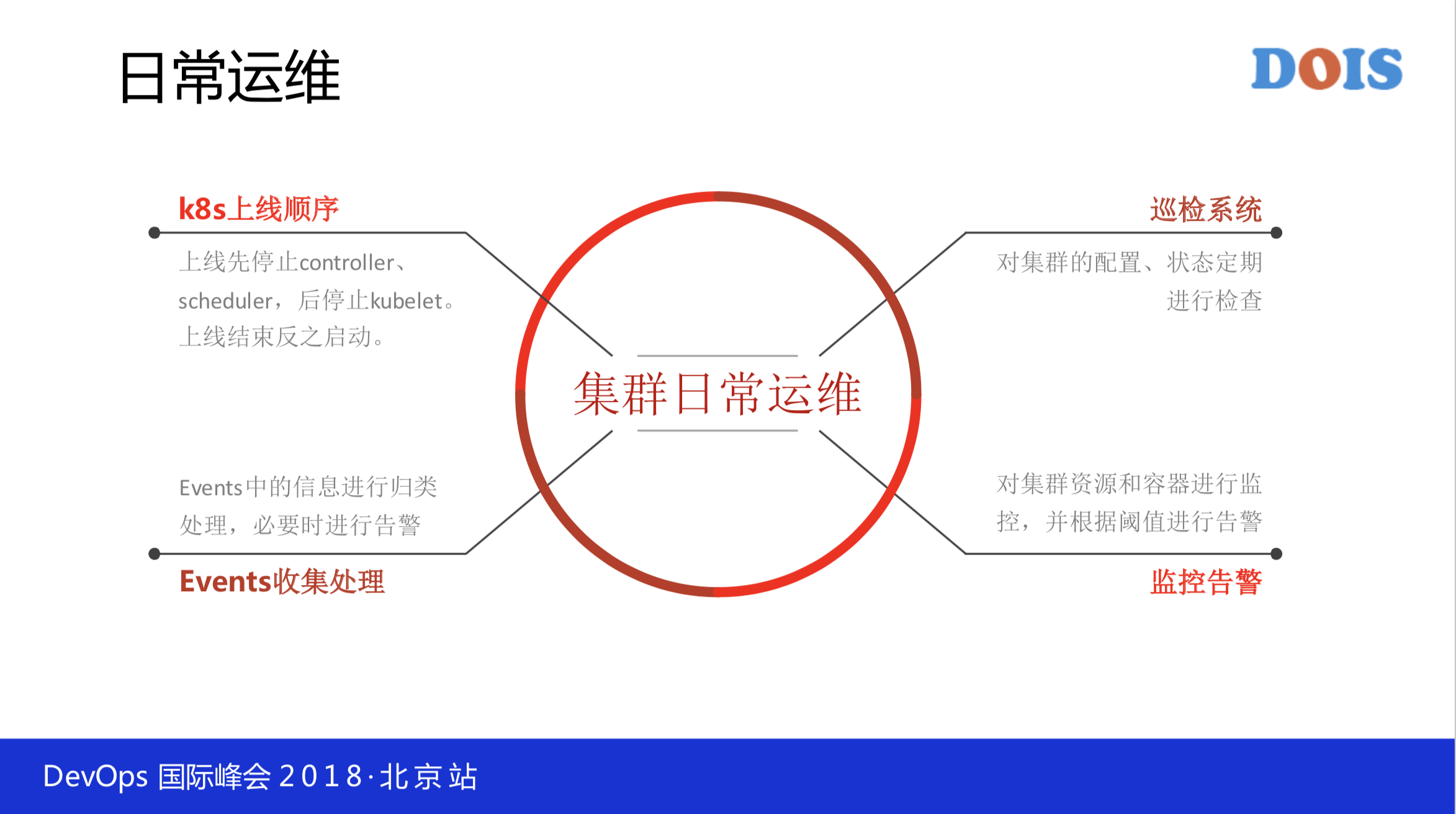
第一,上线的时候先停止什么,后停什么都是有严格的要求,线下可以做好测试,否则上去手忙脚乱会导致一些故障。可以这样理解,在线上的任何操作都是固定的流程,规模实在是太大了,这是非常的关键,怎么讲?测试环境可能会测不出什么问题,但是还要走严格的流程,基础设施的上线也要走灰度。我们给研发来做测试环境的机器也有好几千台,不是基础设施就没有灰度,也要有灰度,你不能上去变更就麻烦了。它先停哪个,后停哪个,该做哪步操作都是有写下来的,不能随便的变换数据。
第二, Events 中的信息进行归类处理,必要时进行告警,把它收集下来分析比例和出现什么状况。
第三,巡检系统,对集群的配置,状态定期进行检查。
第四,监控告警,对集群资源跟容器监控告警。
4.1巡检系统
生产环境每台 Node 都是它应该的状态,从内核参数开始到日志写多少,到进程数有多少,到 Kubernetes 的版本,到网络的情况等很多很多的东西,整个给线上做X光扫描一样,机器大了之后两个运维不可能都看的。为什么做这个事情?大家都是做一线生产运营的很容易疏漏的是什么?有时候业务方说这儿有个小问题帮我看一下或者怎么样,然后你上去再帮它做线上 debug ,有可能改了某个参数,有可能一忙或者是下班了就忘了,线上就很容易触发一些你不可预期的问题。

从这儿来看,我们不仅仅检查OS层面的,还会检查 Kubernetes 层面的,还会检查整个的生态,包括 etcd 的整个状态,内核里面的日志也会检查,还有一些其他的服务。检查完之后会发出一封巡检的邮件,它是一个概略邮件,主要的一些列在里面,剩下的异常的列出来。比如说有一些物理机上面的进程超过了一万或者其他事件,发现了这些后,运维再去统一的查看,可以减少人力。
之前的巡检是用 ansible 来做的,因为它太慢了,后来又改成了它驱动。但是这样的巡检还是慢,因为它从一个中心向这么多个目标机去发起还是慢,然后我们就用了所谓的协议去做线上的节点和状态的判断和巡检。大家回去可以玩一下,这个开源软件还是蛮爽的就是 Serf 的这样,它基本上可以在两秒把所有的节点都巡检一遍。它是怎么巡检的?它是病毒传染的方式,比如说你设60个传染点,向某一个节点发我要巡检,这个节点会给周围60个节点去发,这60条物理机的每一个节点会向其他发,速度非常的快。
4.2可视化意义
我们会对API、生产环境的性能、请求日志做分析,大家一定要对 Kubernetes 里面的日志做分析,这是最好的提升途径。我们会把它的历史数据等等可视化出来,比如说每个节点上面资源的分配情况什么之类的都是可以看得到的,还有API请求响应的时间等等都会拿出来,整个集群的状态、性能好不好,状态正不正常就能一目了然。
还有调度用时,调度到底消耗的怎么样?调度是不是正常的?是不是排队等等,这些都要能够可视化,不然运维怎么都干不完那么多活。

4.3资源调度
接下来说一下重点,随着前面这些基础的东西做完善之后,数据中心的规模已经足够大,所以我们做了资源调度的阿基米德。
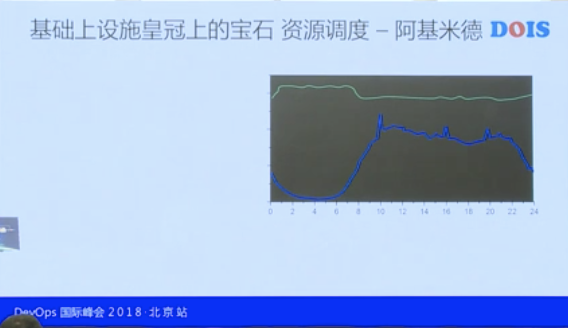
这张图蓝色的这条线就是凌晨1点到凌晨6点业务的低谷,白天的时候业务流量慢慢的攀升,然后达到平稳。上面一条绿色的线是大数据的云计算的线,就是它的资源使用。大家看到中间会有一个巨大的坑,这个坑全是人民币,可以烧很多的钱。
还有大家也比较清楚的一点是绿色的,业务去申请的时候会说,我这个业务很重要,我得要一百个容器,每个容器都得是4核、8G内存,其实上线之后每个容器用一个核都不到。这个时候怎么办?再跟他去谈吗?不用,你用 Kubernetes 就可以解决这个问题,通过调度把资源剥离走就行。他不需要那么多,再上线的时候不设到4核,反正它也用不了那么多。
做调度这个东西是非常复杂的事,没有大家想的那么的简单。你要做调度的话首先得有数据分析,我们是有阿基米德仿真器。去年花了几个月的时间在做仿真器,我们能做一个在不消耗很多资源的情况下,把生产环境上所有Pod的数据和 Node 节点的数据导到仿真器里面做整个的模拟。比如说我们改了一下调度算法,再重新调度一次,看一下现在均衡的程度怎么样,下次又改进了,又可以这样模拟一次,跟着生产环境模拟是不行的。

现在看到CPU主流的分布都是在20到40之间,其实CPU不是越高越好,大家一定要明白这一点。如果把CPU达到90%,业务反而不如CPU60%的时候,大家应该都有这种感受。CPU不是业务的目的,是衡量调度器和调度项目收益的,其实非常的简单,每个公司每个季度每年都要买机器,你可以跟老板说不用买机器,不要说CPU提升多少,这都没有意义。大数据可以把机器给你干完,但是有什么用?
调度的用时,我们线上有很多的自动弹性伸缩,还有大数据往里面调。其实每一个都是有大量的创新、销毁动作,会有团队24小时帮我们盯着这个图,一旦有调度延迟特别高的会调度出来,晚上就会有人来介入,原来是人打电话,最近发现打电话给我的是机器。
我们调度器的架构非常的简单,其实就是基于 Kubernetes 的调度性能,现在平台可以支持第三方的调度插入,我们其实也是这种策略。我们把阿基米德的调度器放在旁边来对接,这个 JDOS-Master 跟 JDOS-Node类似于 Kubernetes 的api跟 kubelet 。
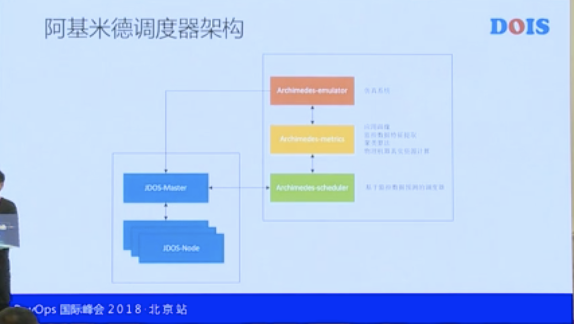
然后我们看上面的两个黄色的东西,一个是我们的仿真系统,为什么花了大量的时间去做仿真系统?不是仅仅验证你算法好不好,而是要让仿真器帮我们来训练,你每天的调度任务,有一些是真实的调度去调,仿真器也在调,只是仿真器调度的结果并不直接反馈给真的调度器,放在那儿我们再做对比,对比产生新的模型和新的调度策略会真正发放给绿色的调度器。
