@gaoxiaoyunwei2017
2019-04-24T06:10:34.000000Z
字数 4028
阅读 1439
超大型运维平台的面向终态设计
北哥
讲师简介
乔斌
- 技术专家

本文主要讲面向终态的框架设计,以业务背景、架构详解、现实问题和眺望未来四个方面进行阐述讲解。
1. 业务背景

上一代运维系统建设的思路是将运维操作串接成自动执行的流程,这是以前运维大家通用的建设思路,扩容就能解决问题。现在绝大部分都是基于流程式了。

系统运营稳定,一定要基于线上环境是稳定的。单机的环境是稳定的,运行一百次、一千次、一万次都是这样的。但是,运维系统不一样,有主控者,有受控对象,通过控制者发命令,运维系统控制受控对象,再反馈,中间不断的提问题,最后输出,这是理想化的结果。实际上控制者是有干扰的,受控对象也有干扰。运维系统运行结果会受环境的影响而波动的。
比如监控日志从下游拉取,下游的机器随便换三五台很正常,超时也很正常,是30秒还是50秒,有算失败就算故障。但是过了30秒又正常了,这就是有干扰。这个干扰导致了线上运维系统是不稳定的。基于这样的不稳定,故障没有办法避免,就一定要建恢复的系统,以此解决故障的问题。
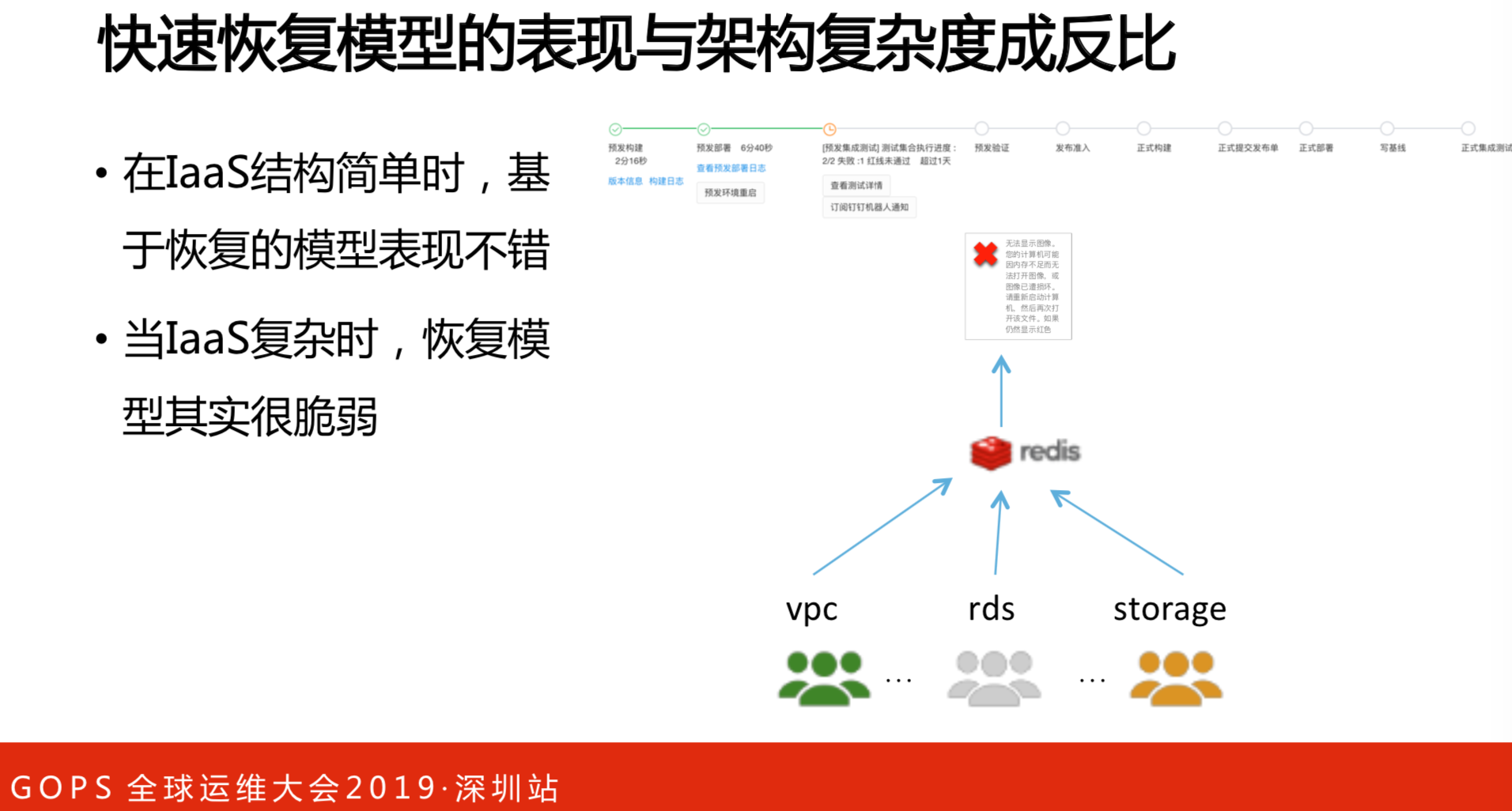
快速恢复模型的表现与架构复杂度成反比的关系。在IaaS结构简单时,这是基础线,恢复系统不会出现什么问题。但是,当基础设施复杂的时,这个假设就不成立了。这是一个真实的案例,一个云产品开发出来,一定会依赖于很多团队的。实例、网络、存储都恢复了,但是,网络协议不能恢复。一个基础设施的云产品是由不同开发组成的,保不准哪个环节出现问题。既然假设不成立,一次性的成功率就显的很重要。但是,又很难通过直接一种办法把一次性成功率提高。如果告诉你成功了,这是蒙人的。你的病这么复杂,现在给你一个药,吃了就好了,怎么可能的事。

终态是迭代提升成功率的有效方式,有点像测试。测试会告诉你期望结果是什么样的,还有现实结果又是什么样,中间就是不断的提BUG并反馈上去了。希望结果是事先设定的,真实结果又是可以考察的,监控系统就做这个事情,中间剩下的事情就是不断的完善。只要不断的完善Action组合,一定会得到真实的结果。因此,可迭代模型是必须的。
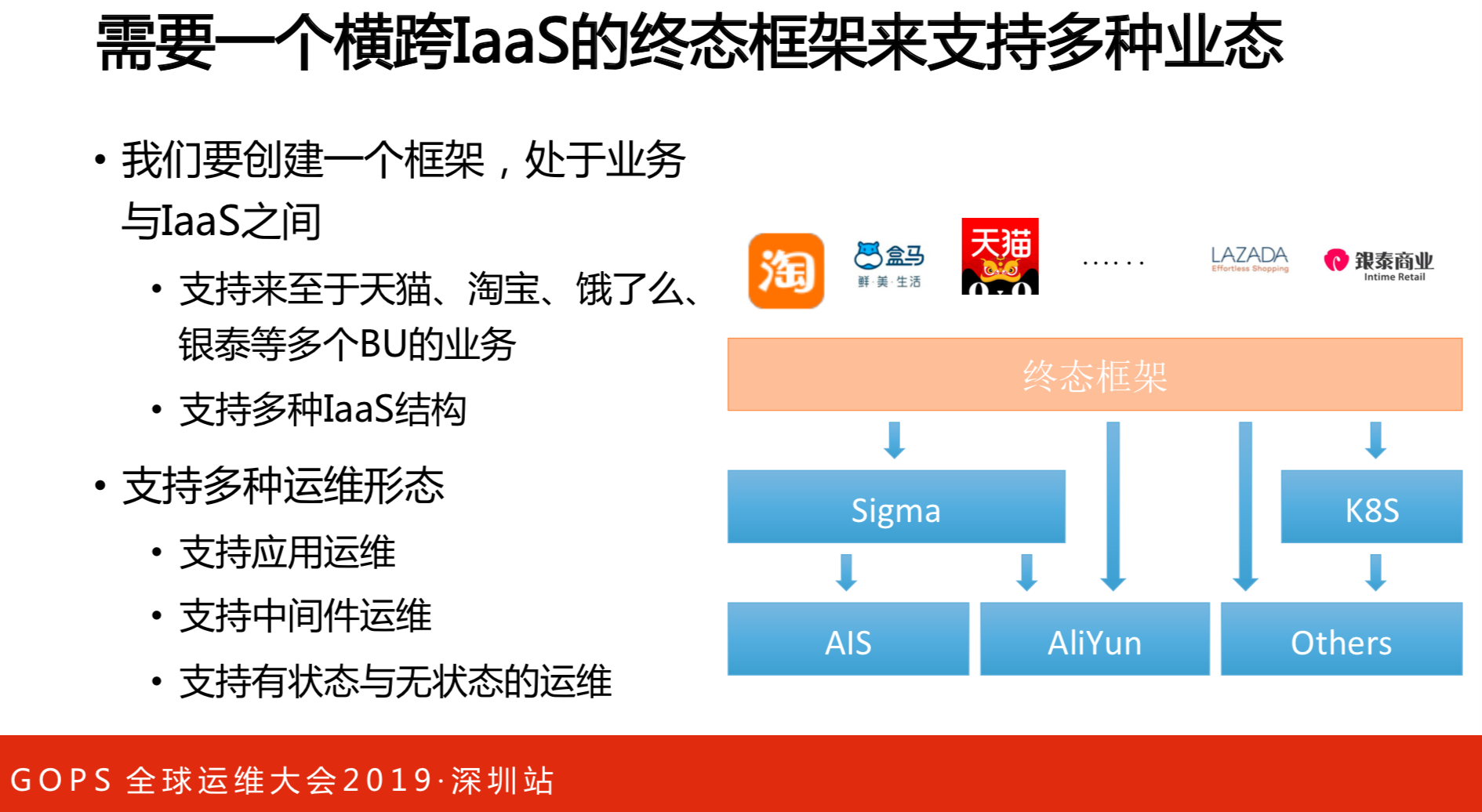
结合具体的业务,我们需要的模型横跨不同的基础设施,能够支持不同的业务,并且能够支持不同的运维形态。大家从框架的层面来看,要让一个运维运转,这些都是必不可少的因素。
2. 架构详解
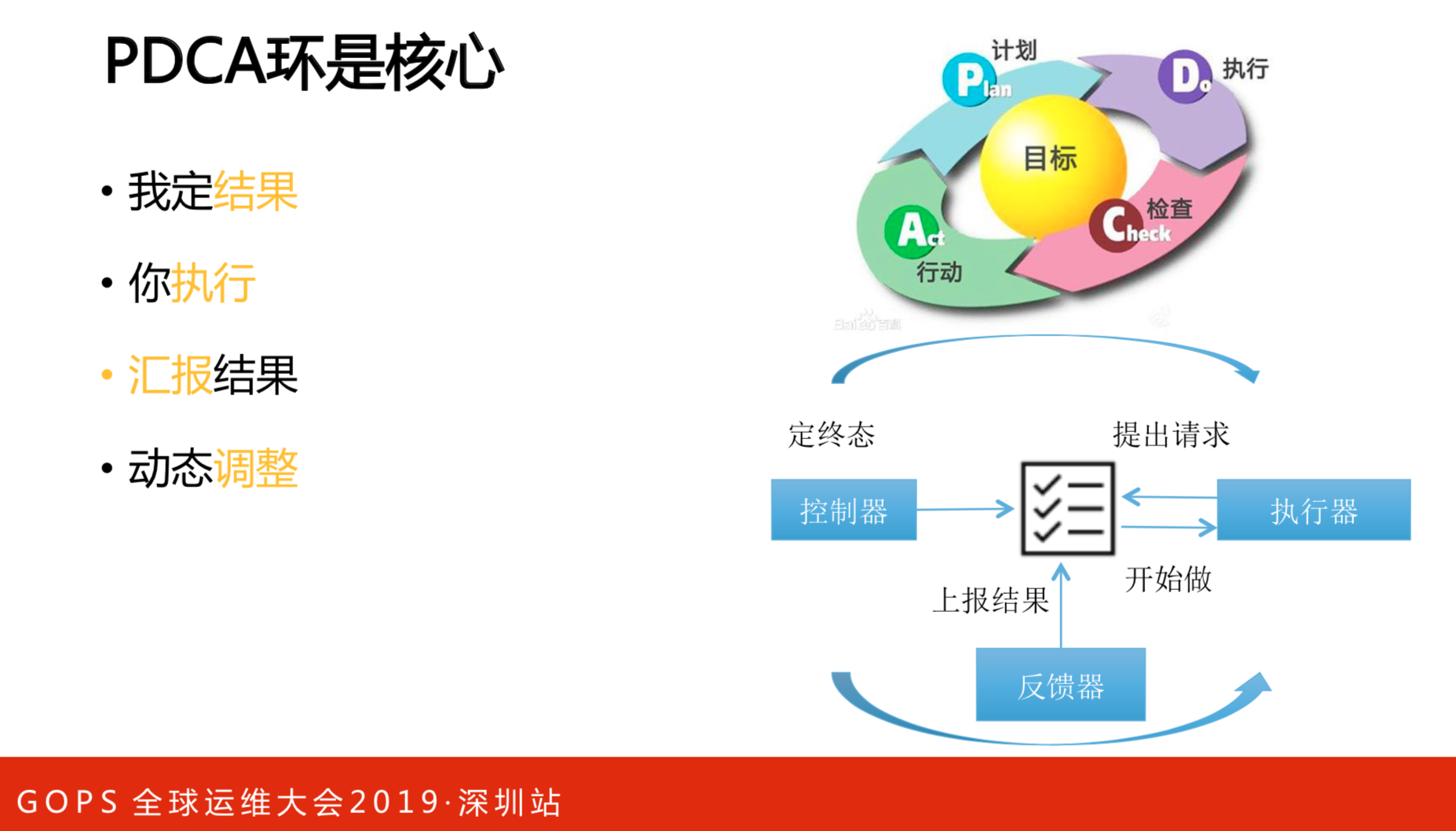
架构看似很复杂,其实很简单。阿里是很资深的团队,老板是很人性化的,只注重结果,中间爱怎么干就怎么干,这是个人自己的事情。这有点像PDCA环,中间是目标,外面就是计划、执行、检查和行动。控制器定终态,之后提出请求,然后执行器。一定要看线上的环境是否能执行原来的计划,如果批准了就可以做,做完之后上报结果。跟大家日常团队管理和做事的方式一模一样的。
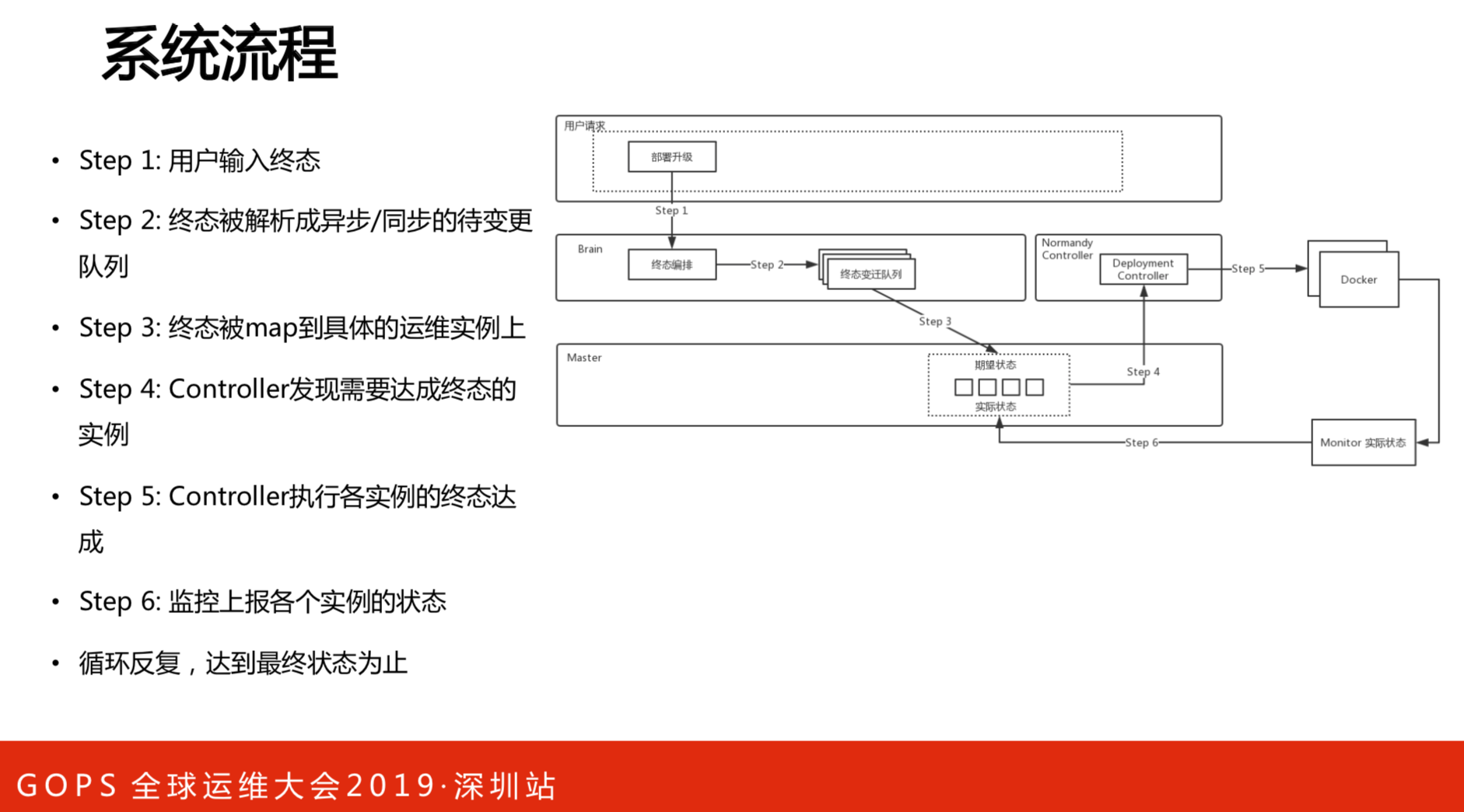
系统的流程如图所示。举个例子,用户要做升级,先提出部署升级的请求,以终态来描述,多少集群机器要变成什么状态,通过编排之后,变成要变迁的队列,然后通过很多执行者来执行,做完之后发命令给Docker升级,再汇报结果,至于结果对不对由第三方来检测。
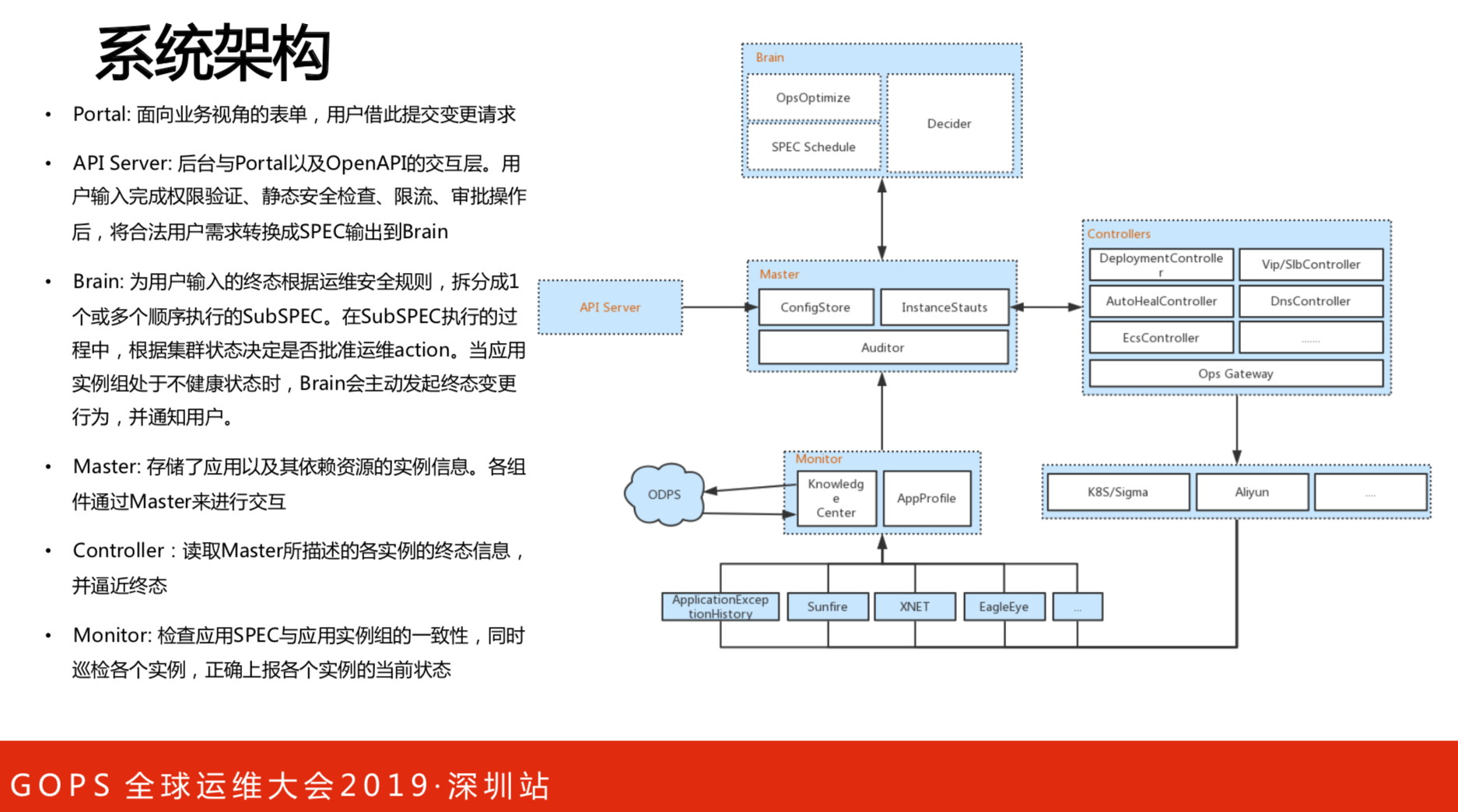
架构方面阐述下重点。从API到Master之后是Controllers执行。监控的指标有两个:一个是知识库,知识库决定完成之后,最后的这些指标根据经验值什么是正常,什么是不正常。另一个是用户画像,用来定义业务,网络抖动、监控或者接口是否正常,所有指标被定义在应用画像里,然后用这些综合化的指标打分,来判断上到容器是否正常。
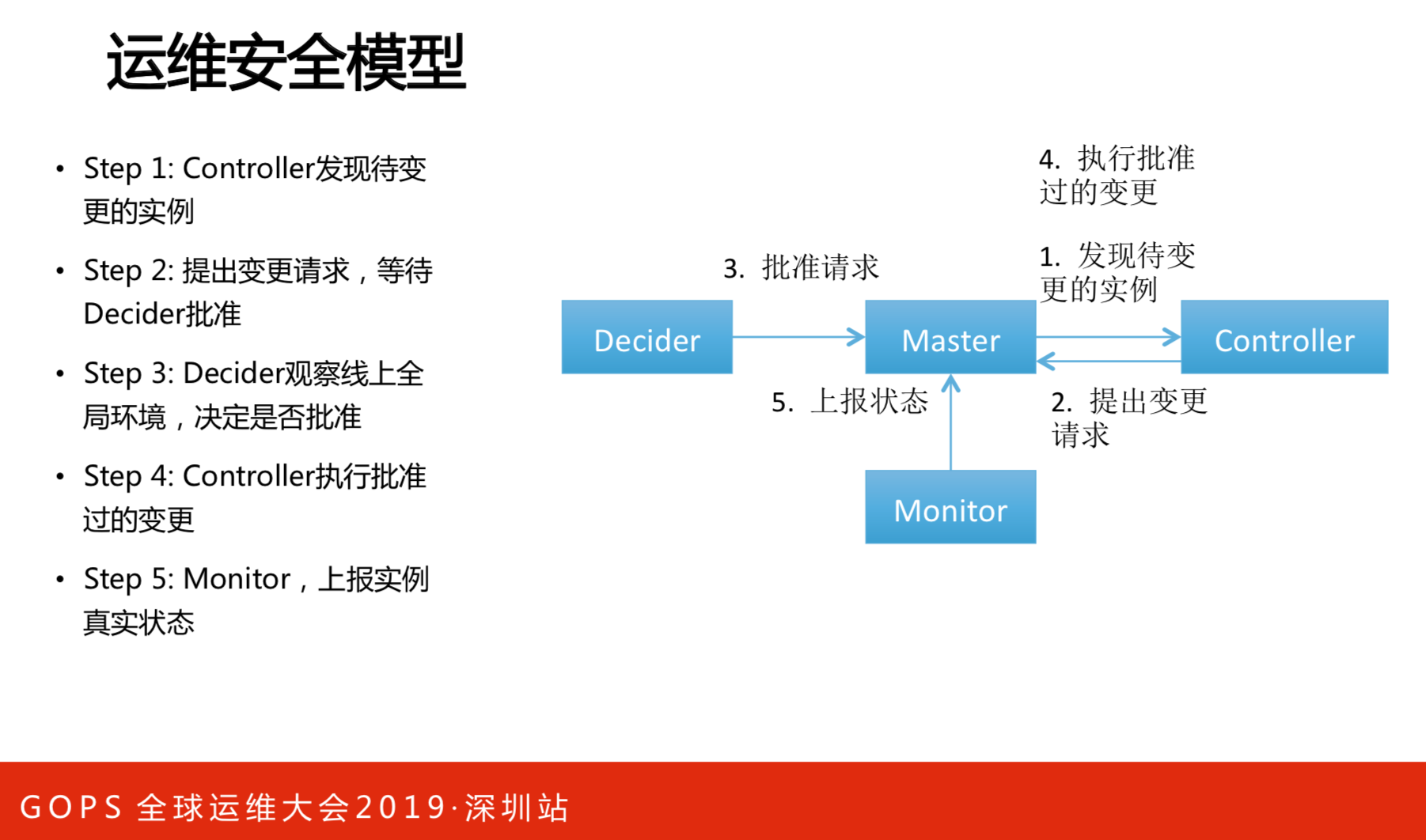
Brain的核心是通知实例变成什么样,再提出请求,就像下棋,要下赢要走几步。但是,每做一步的时候要观察线上全局环境,Decider就是观察者,提出变更请求需要得到Decider的认可,以保证环境的稳定性,这就是安全的模型。
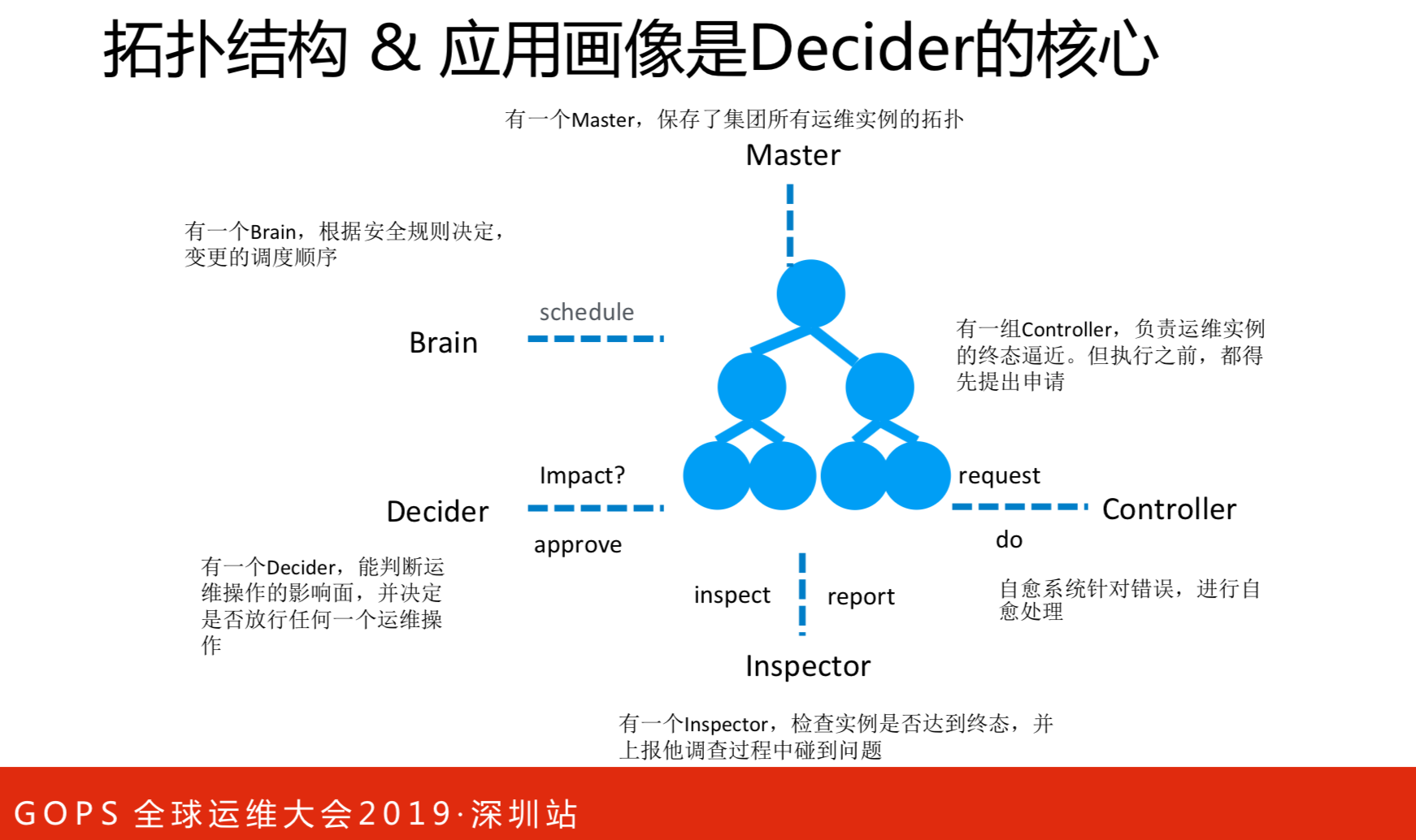
这是架构的演示示例,实际情况会更简单一些。要改的点不仅仅是两个容器,要运维的对象是VIP的对象,要根据链路往下看,看是否会影响到下游。过程如下,Master要看运维实例的关系,这样才能改变问题,它发的请求,它做判断,再看能否执行。可以就开始做,不行就上报。把错误上报上来后,有专门的执行者来做修复。执行器有的是管部署的,有的是管修复的。最终是把这些点逼近最后的终态。

模式也是很简单,无非是设定终态,最终达成终态,中间谁做都行。这么大的框架,肯定不是一人之力可行的,个人不可能有这么多的资源来实现所有的领域,而且中间会涉及到与其他系统的交互。但是,对于我来说,谁来做是不关心的,谁做都行,我检查就好了。

异构系统都是具体的业务问题,架构实质上是很简单,无非是落地的问题。落地的难度在于以下几点:
- 企业的应用是异构的多样性的,有很多的特性,如C++、GO等等
- 历史包袱
- 业务优先
- 一揽子解决方案
- 诸多限制,我们就四五个人来做,这就是限制
复杂在于真正面对的时候。
3. 现实问题
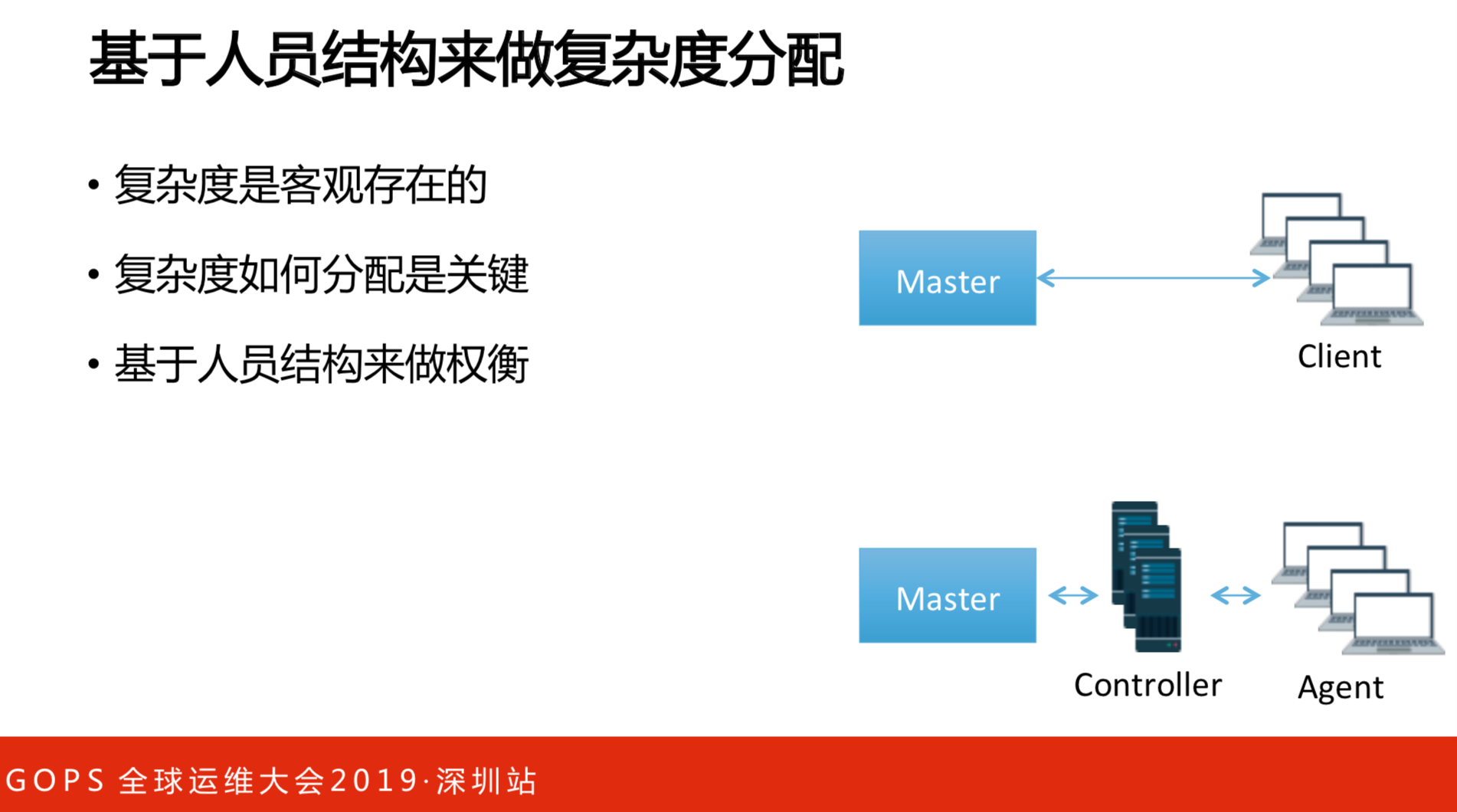
面对业务的时候,现实的问题蜂拥而至,首先看做规划的时候人员的问题。我们之前考虑过两种模型:
- master-client模型。问题在于集团有几百万个容器,几百万个轮巡,需要多大的团队才能开发这样的系统?Client也是有这个问题,有很多的版本,就算版本兼容了,不同的脚本跑,会导致运行的结果不一样。Client得专门找一个团队。
- master-Controller-agent模型。通过Controller可以做一些优化,Agent已经经过验证的。
要利用现有的资源做这样的事情。首先得要考虑有多少人,再才考虑做多少事。
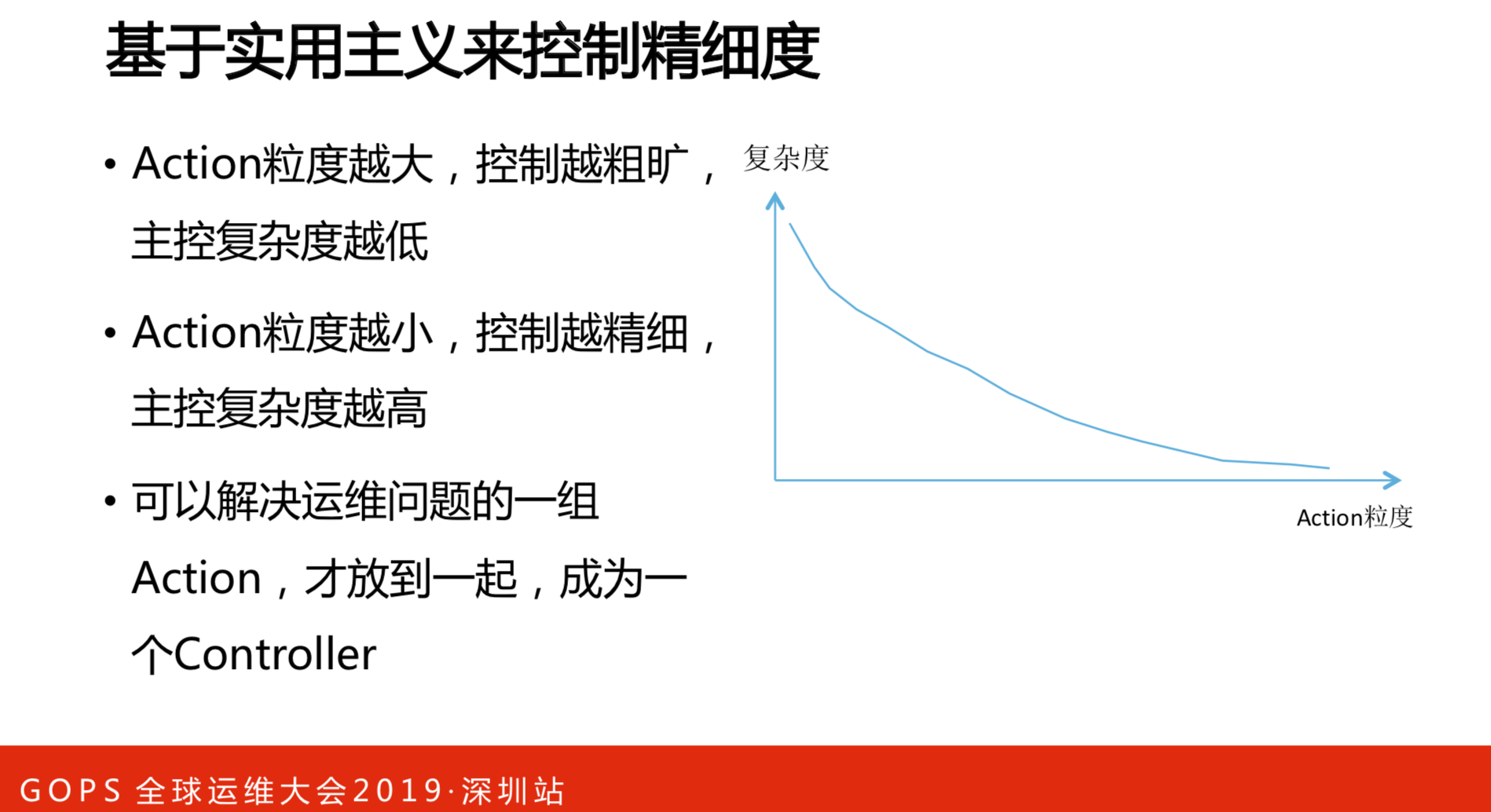
从运维的角度来说,最后的执行器是控制粒度越细越小,与复杂度呈反比的。
- Action粒度越大,控制越粗旷, 复杂度主控复杂度越低。
- Action粒度越小,控制越精细, 主控复杂度越高。
- 可以解决运维问题的一组 Action,才放到一起,成为一个Controller。

把控制者和执行者的问题解决之后,就有业务的问题。
- 对于同样一个Pouch分组,我要扩容5台时,并不关心机器。但在缩容时,要指定机器怎么办?
- 日常环境蓝绿时,我只选择蓝绿部署方式就可以了。但线上部署时,我一定要先部署CENTER.unsh分组,然后再部署CENTER.unshyun分组。怎么办?
- 机器自愈、机器置换时,我一定要用某台机器来做置换,怎么办?
这就是理想和现实的差距。
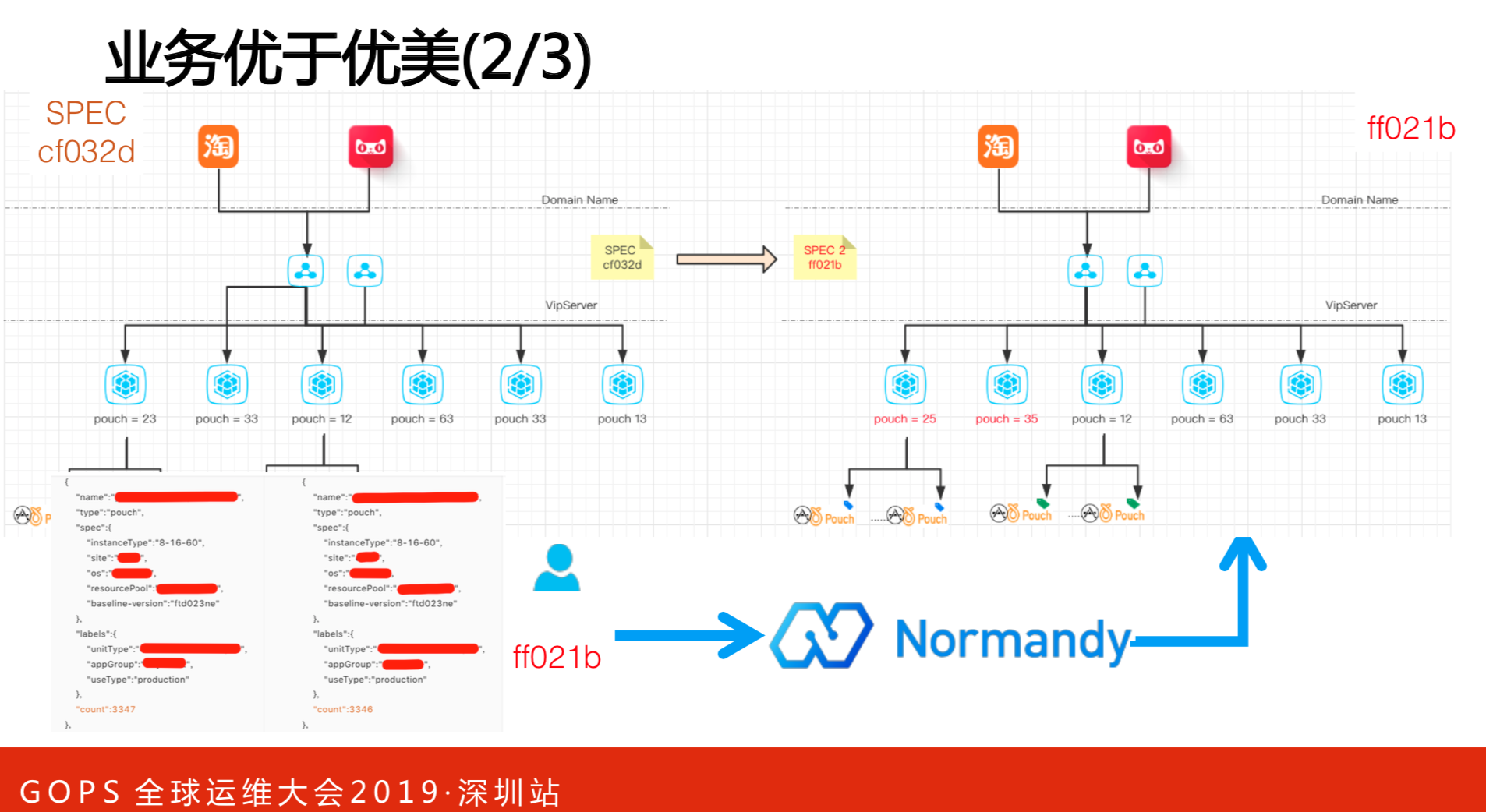
这是架构。从3347变成3346台,把配置更新就可以了,无非是推不同的配置版本,升级完就可以解决的。但是,实际上不是这样的,就像上面提到的,要指定机器缩容,就引用运维参数,以此解决系统运维的行为。
要分两部分:分配的结果和用户指定有行为的过程。因为有状态了,用户自定义的工作就变多了,怎么解决自定义工作的收敛问题?总有一部分人选择用无状态的方式运作,有的人选择用有状态的方式运作,以数据的方式做驱动。
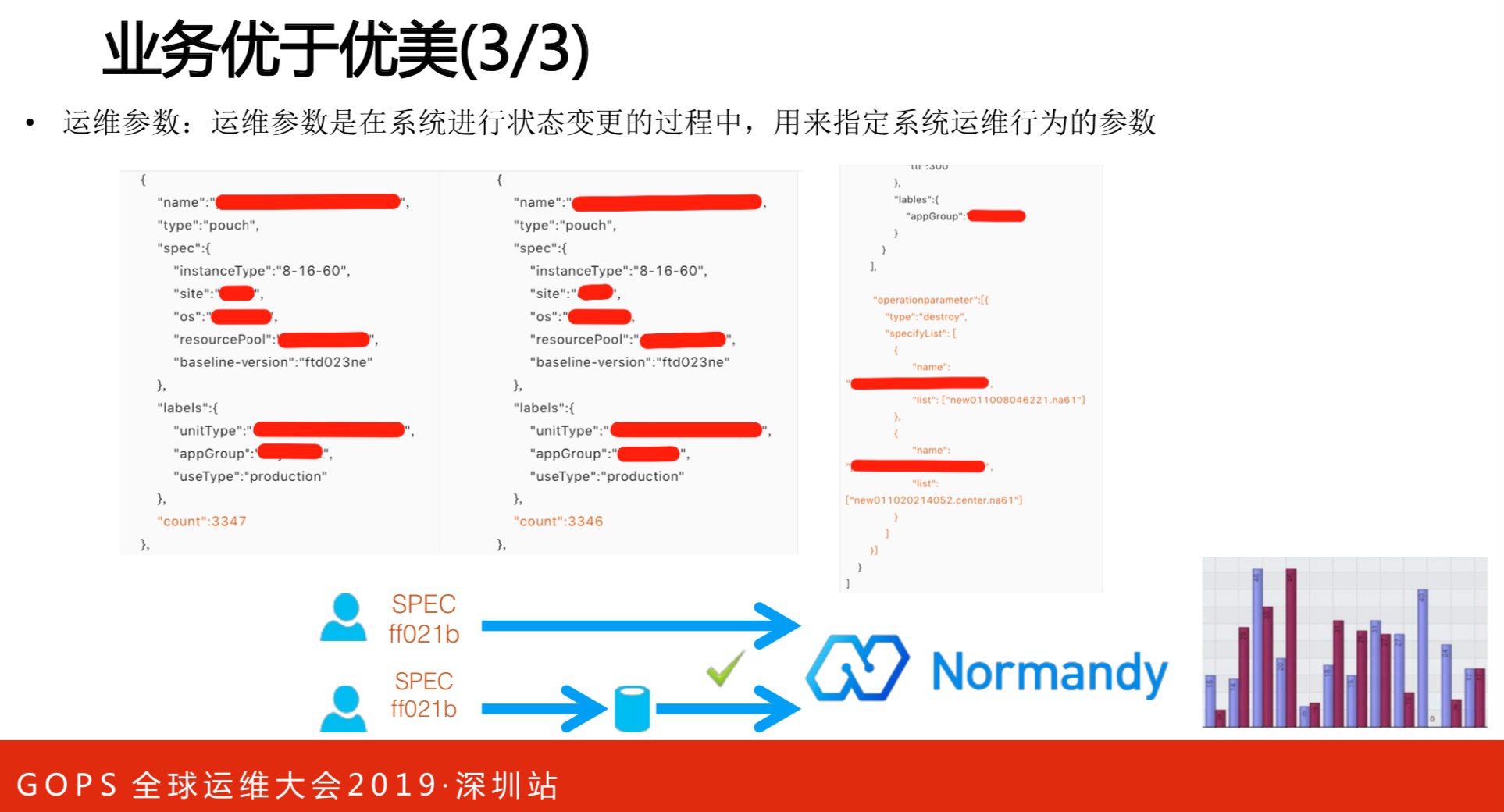
运维参数是在系统进行状态变更的过程中,用来指定系统运维行为的参数。

应用是无状态的,运维是有状态的。应用从最开始提交版本到最后部署上去,这个过程是无状态的。但是,运维的过程是有状态的。无状态是结果,有状态是过程,要让架构支持终态的结果和有状态的过程控制,比如能让用户重载行为,才能支持有状态和无状态。
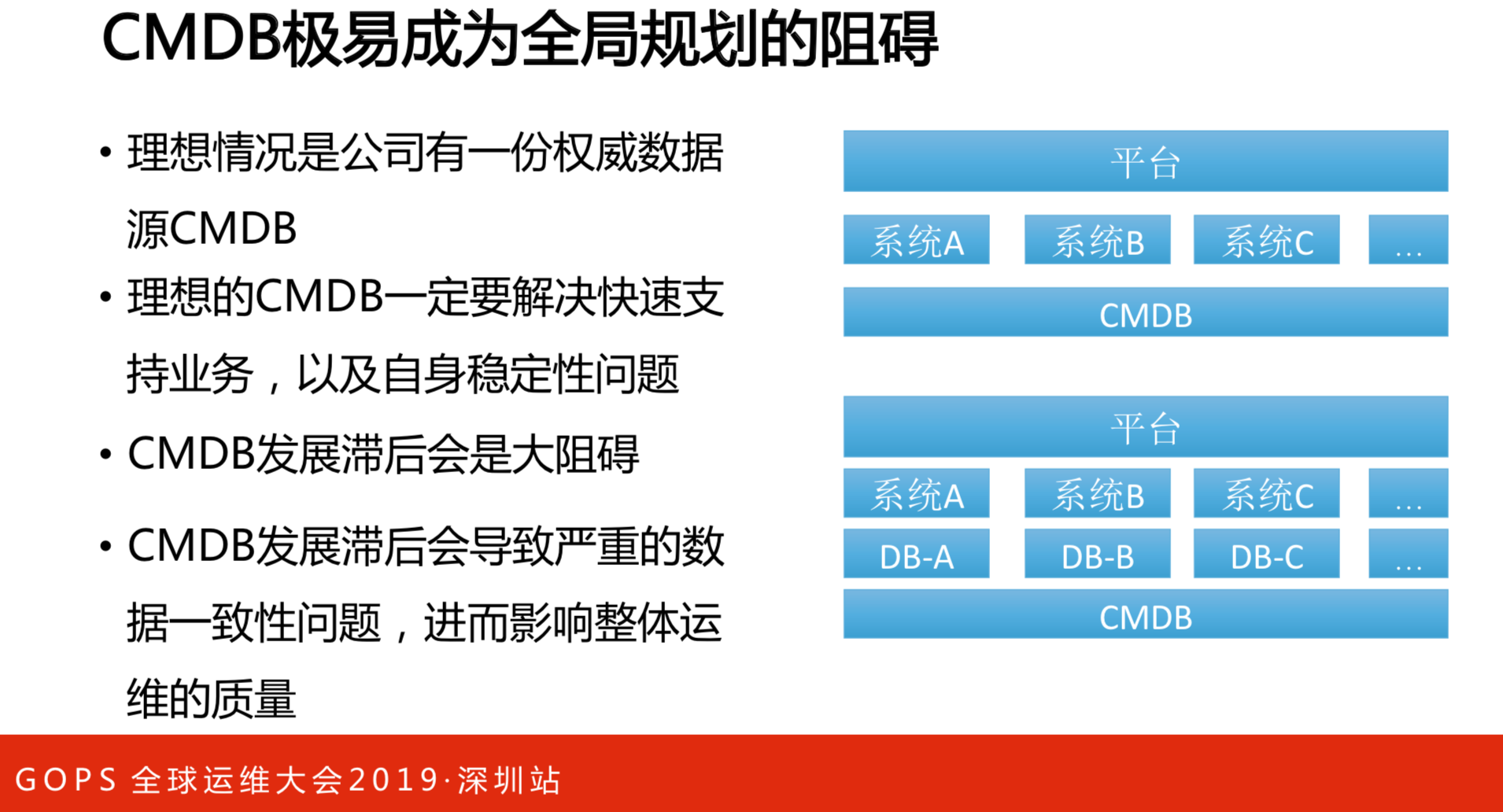
能支持所有系统的时候,会成为阻碍,所有的部门做到极致,需要专门的人做专业的事。我有一个平台框架在最上面,跟下游不同的系统做交互,大家的数据源都存在CMDB。在做全局判断的时候,只用看CMDB数据源就可以了。如果要想做个理想的状态,CMDB必须支持快速的业务,因为下面的团队都会对CMDB提要求,要是支持不了业务,他们就会自己搞一套,这就出现某个系统的数据要同步,最后很难保证质量。如果保证不了CMDB数据的权威性与质量,就一定做不了CMDB系统。
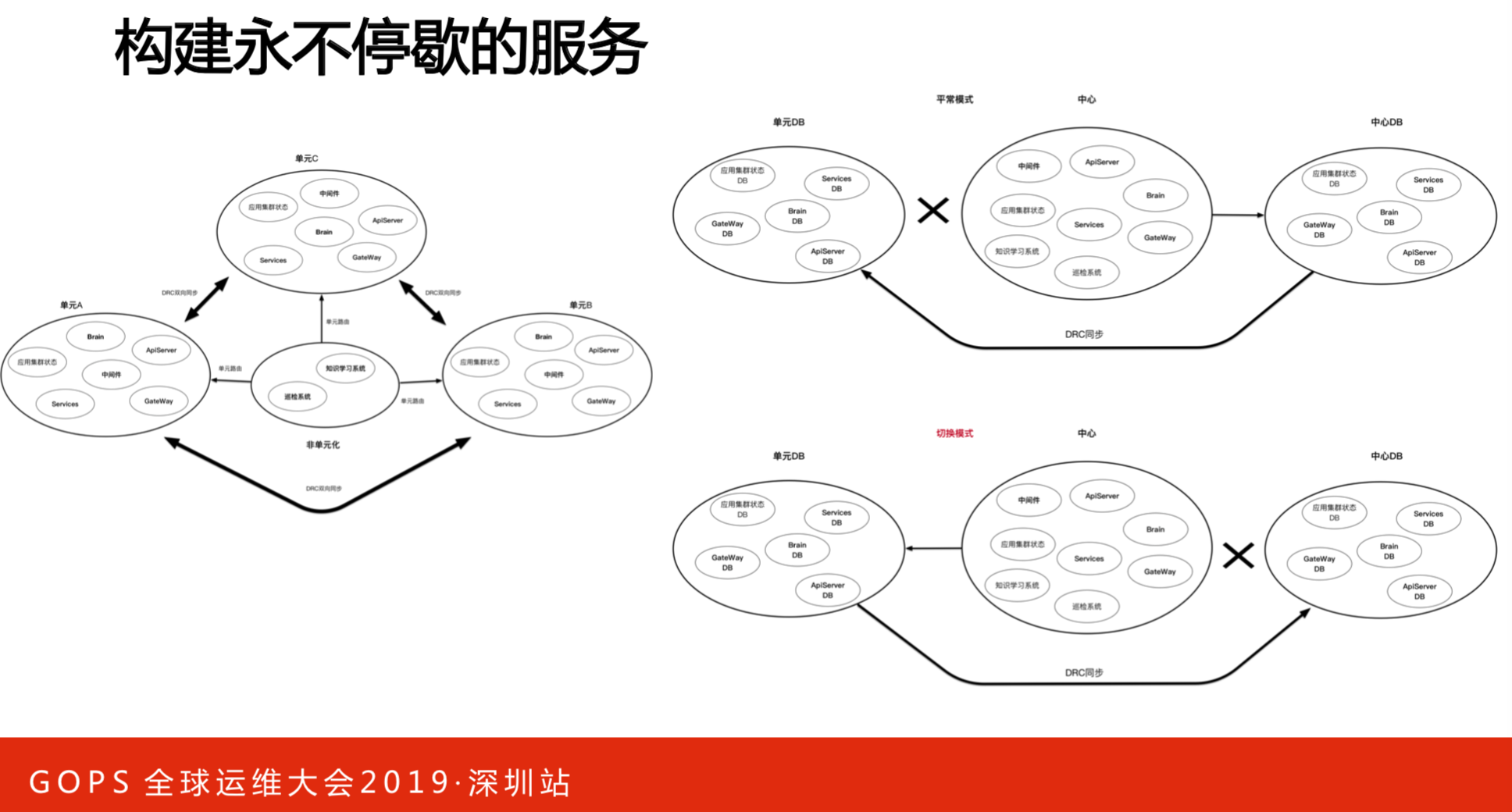
构建永不停歇的服务,应用都是容器化的,三个机房点挂一个点了都可以,但是数据库不能挂,要做同步机制,有主和备,挂了之后可以切过去,这个模式实行起来比较简单。用单元化的模式,要保证三个数据中心的数据同步。
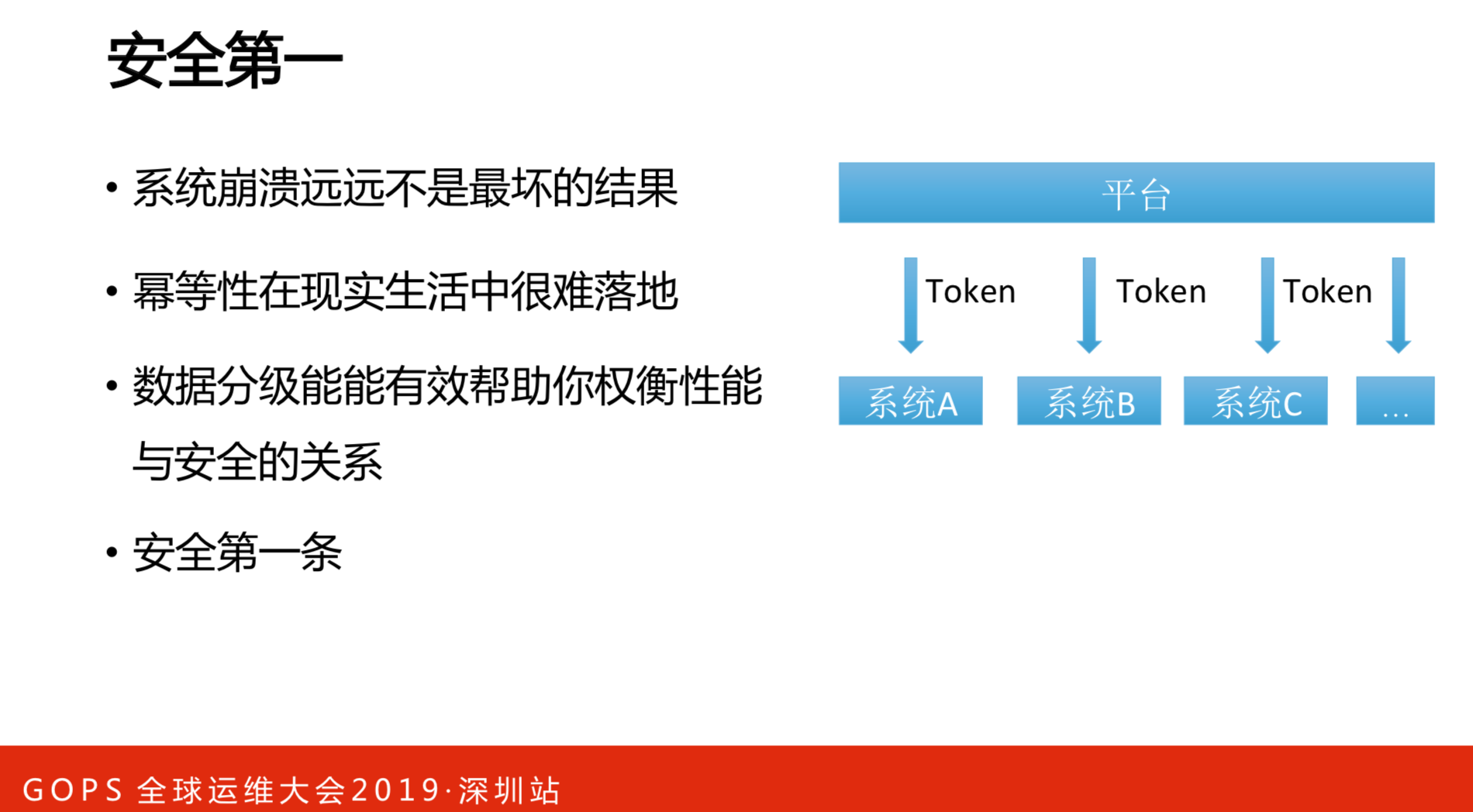
做完之后会发现,系统崩溃不是最坏的结果,最糟糕是两个数据库切换的时候,中间有100毫秒的延迟,有序恢复系统的时候,差了100毫秒的数据错了,这比崩溃更坏。
幂等性在现实中很难落地,一个平台有很多系统,要做幂等性就要有Token,但是,业务不是统一的。
需要做的事情就是把数据分级,哪些数据是可以丢,哪些是不可以丢,无非就是先跑一遍,看看真实的状态。还有一些强一致性的数据,就做强一致。
安全是首位的。
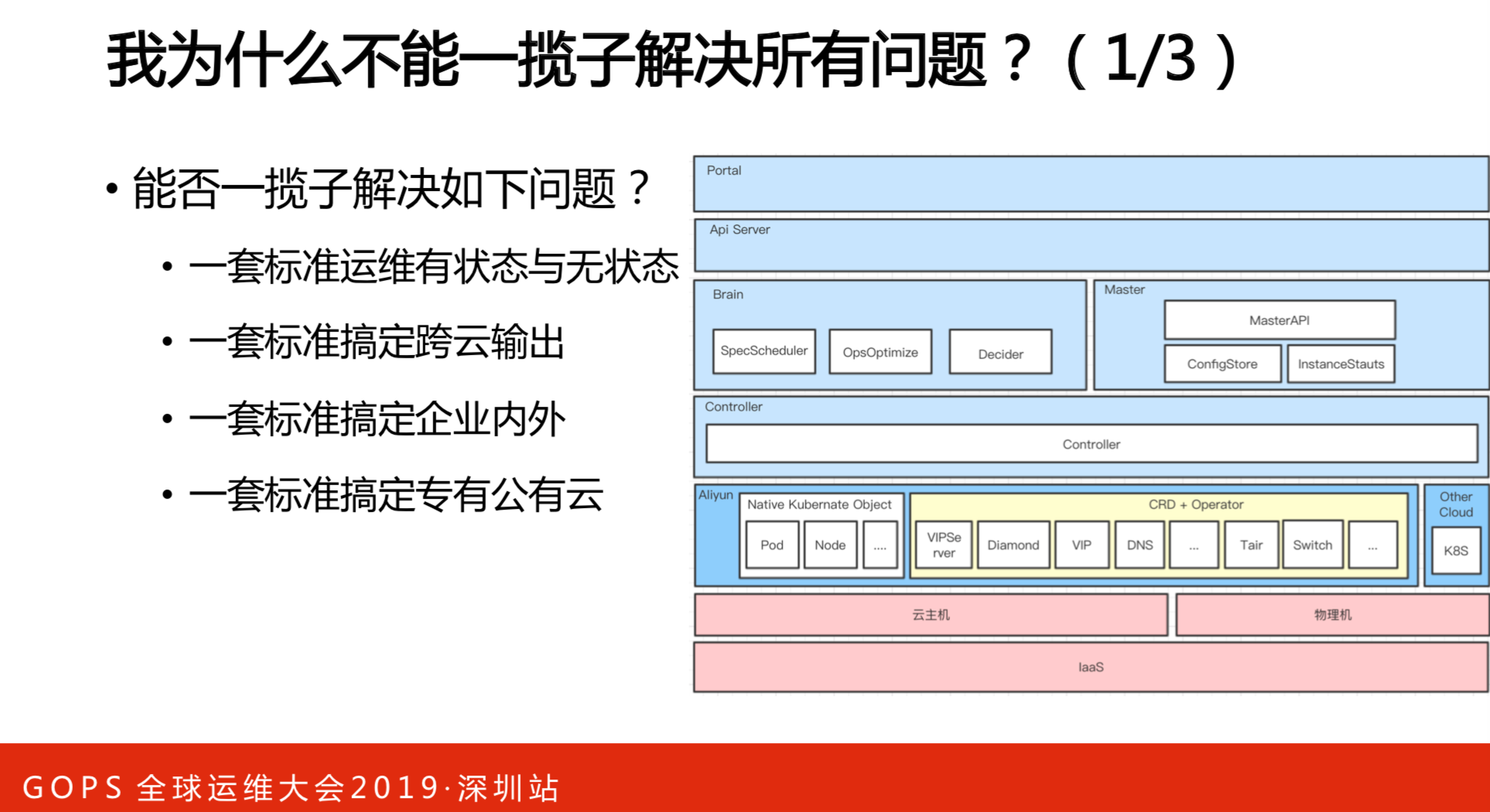
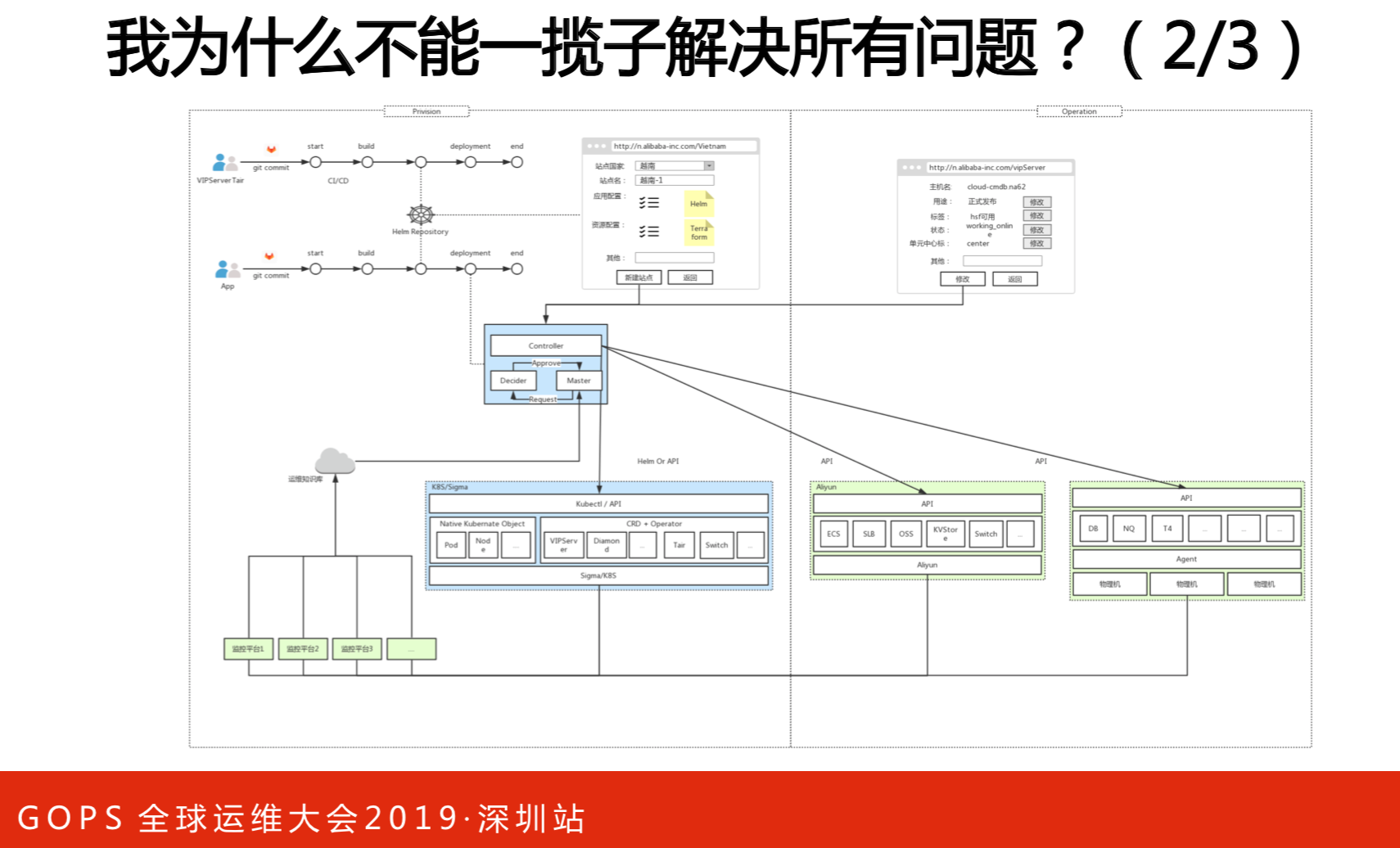
为什么不能用和强推一套标准?不行的,标准是什么?标准做的什么事情?标准做的是复杂度的再分配。右图是战国时期的地图,秦始皇统一中国的时候做了车同轨书同文。现在大家都车同轨,就可以到处运维和部署了,复杂度最简单了。路谁来修?同轨谁来做?就是各个国家来做了。因此,标准建立是没有任何的问题,只是做了复杂度最分配。现实中我们是选择业务优先,做一套标准还不成熟。在集团上完云之后,基础设施比较统一的时候,我们再考虑做这个事情,选择标准一定要先定标准,否则做不了。
4. 眺望未来
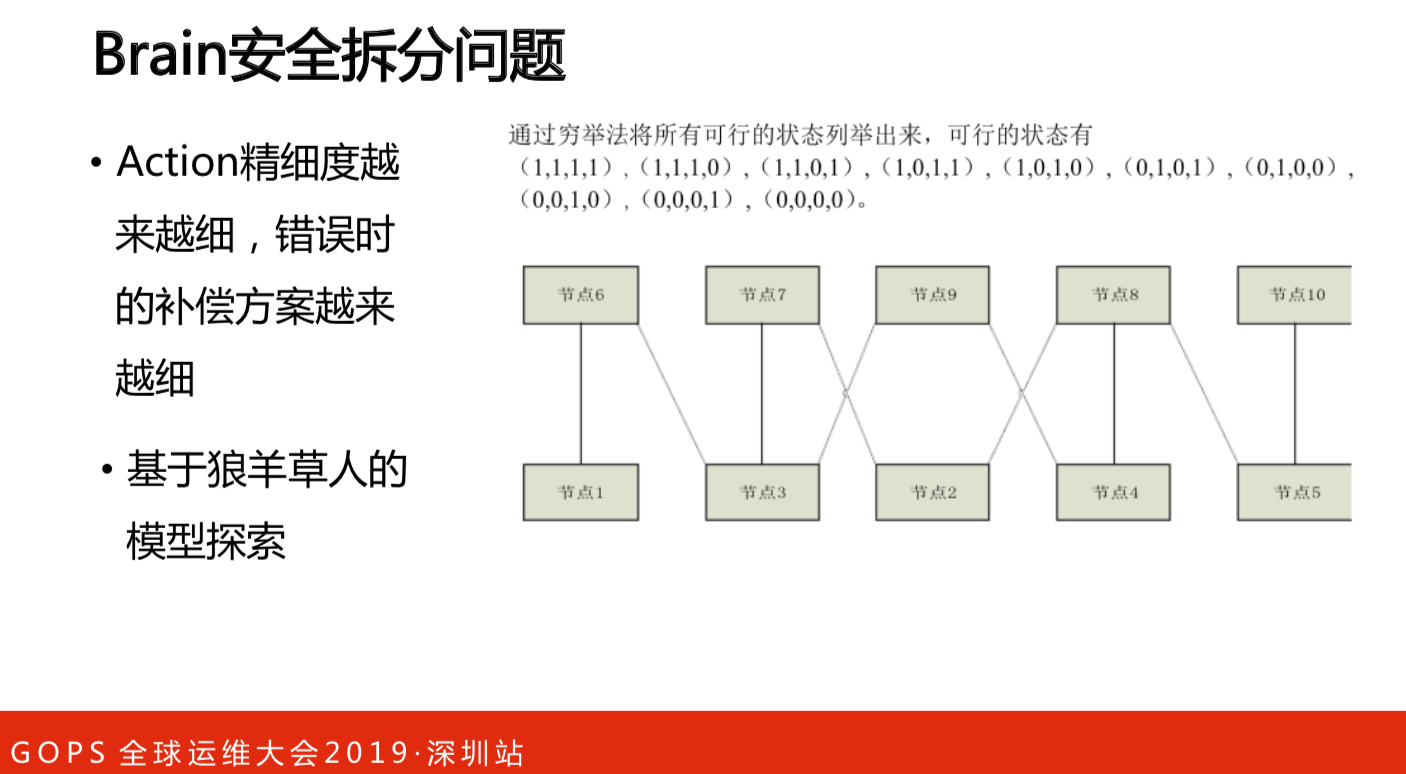
我们想做一些智能化的内容,这是之前想的不太靠谱和难以落地的思路。之前的思路是升级的时候不能重启,但是升级的时候可以扩容,有点像狼、羊、草、人的模型,最后形成一张图,图是最优路径,按照路径索引,觉得特别不靠谱。把数据清洗、对齐、用AI、套用模式、再来常识和迭代,从运维发展角度来看,这是做不了的,老板估计都换好几个了。

原理就是两行简单的代码,这个地方出现异常的时候,调用一个函数找到正确的人,”请联系XX答疑“你答疑就好,能自动化就自动化,不能自动化就人工答疑了。在人工智能的时候,过分依赖于机器,其实我们身边的客服和技术支持同学,绝对是比深度学习更有力量的。人工智能需要做很多次分析才知道根因,客服一看就知道了是谁的问题。在长久的工作过程中,早就已经知道了某种类型的错误根因是什么,而人工智能需要很长的时间推导。语义分析框架是希望把知识库开放出去,让运维的技术支持的专家能够根据情况来分析是谁的问题。
聚沙成塔的框架是我的展望,我爱聚沙成塔的人类智慧胜过机器人智慧。
