@gaoxiaoyunwei2017
2019-05-30T10:07:59.000000Z
字数 4885
阅读 1545
全球最大呼叫平台监控实践之路
北哥
讲师简介
王漫雪
- 中移在线服务有限公司 技术经理

本文跟大家分享下中移在线做监控的心路里程。将按照四个方面进行展示:
- 背景---全国集中维护、全球最大
- 出路---选择开源
- 转型---几个问题
- 蜕变---AIOPS在监控报警方面的尝试
1. 背景---全国集中维护、全球最大
我们是做10086客服系统,有多少人是移动的用户?有多少人给10086打过电话?有多少人关注过10086的微信、微博,在上面查过话费办理过业务的?上述这些服务都是我们公司提供的,可以自豪地讲,我们给大家的也是生活当中必不可少的服务。
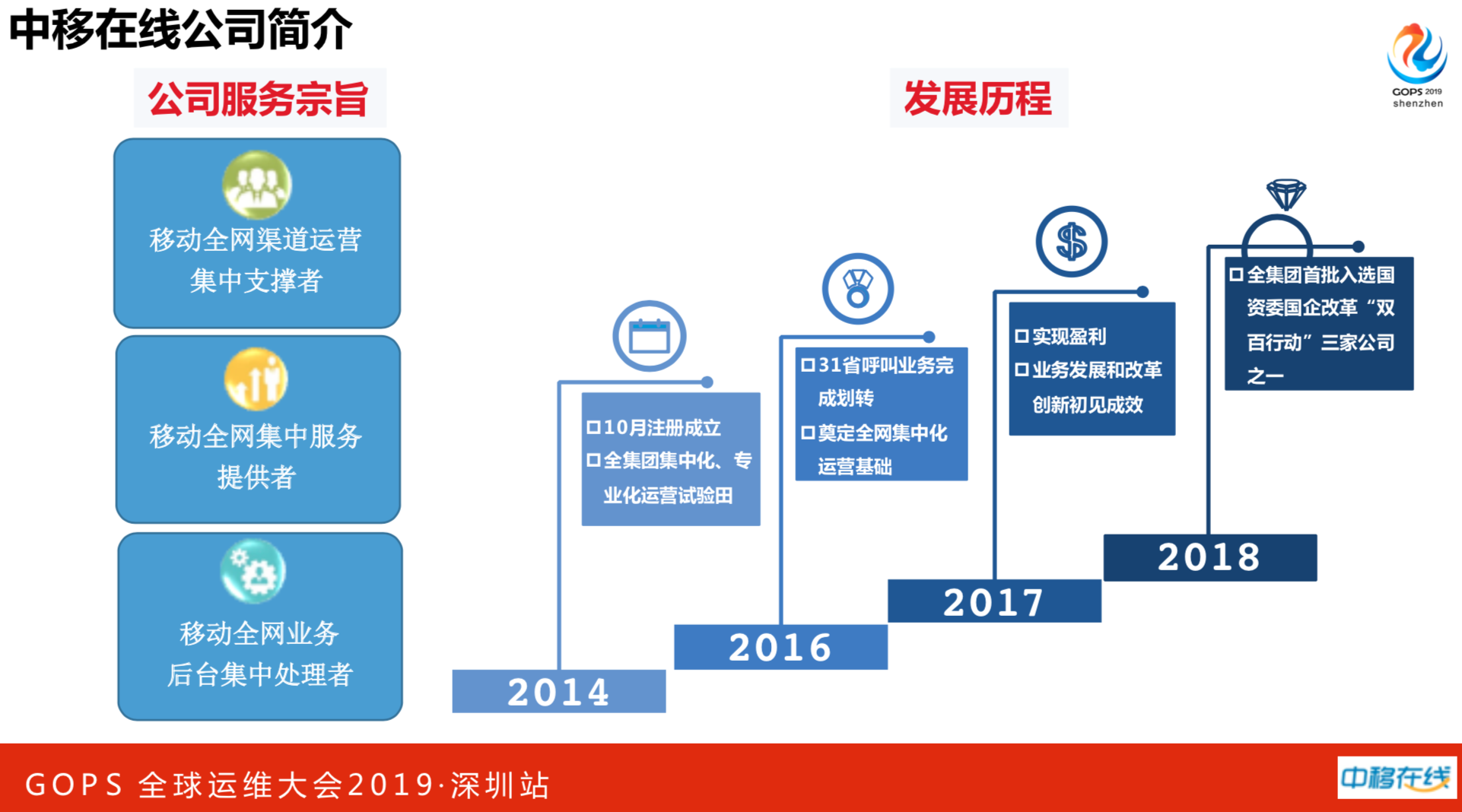
我们公司是2014年10月注册成立,全集团集中化、专业化运营试验田。客服系统是总部统一建立,31个分公司使用。另外值得一提的是2018年完成盈利,官方报道一年收入100多个亿。
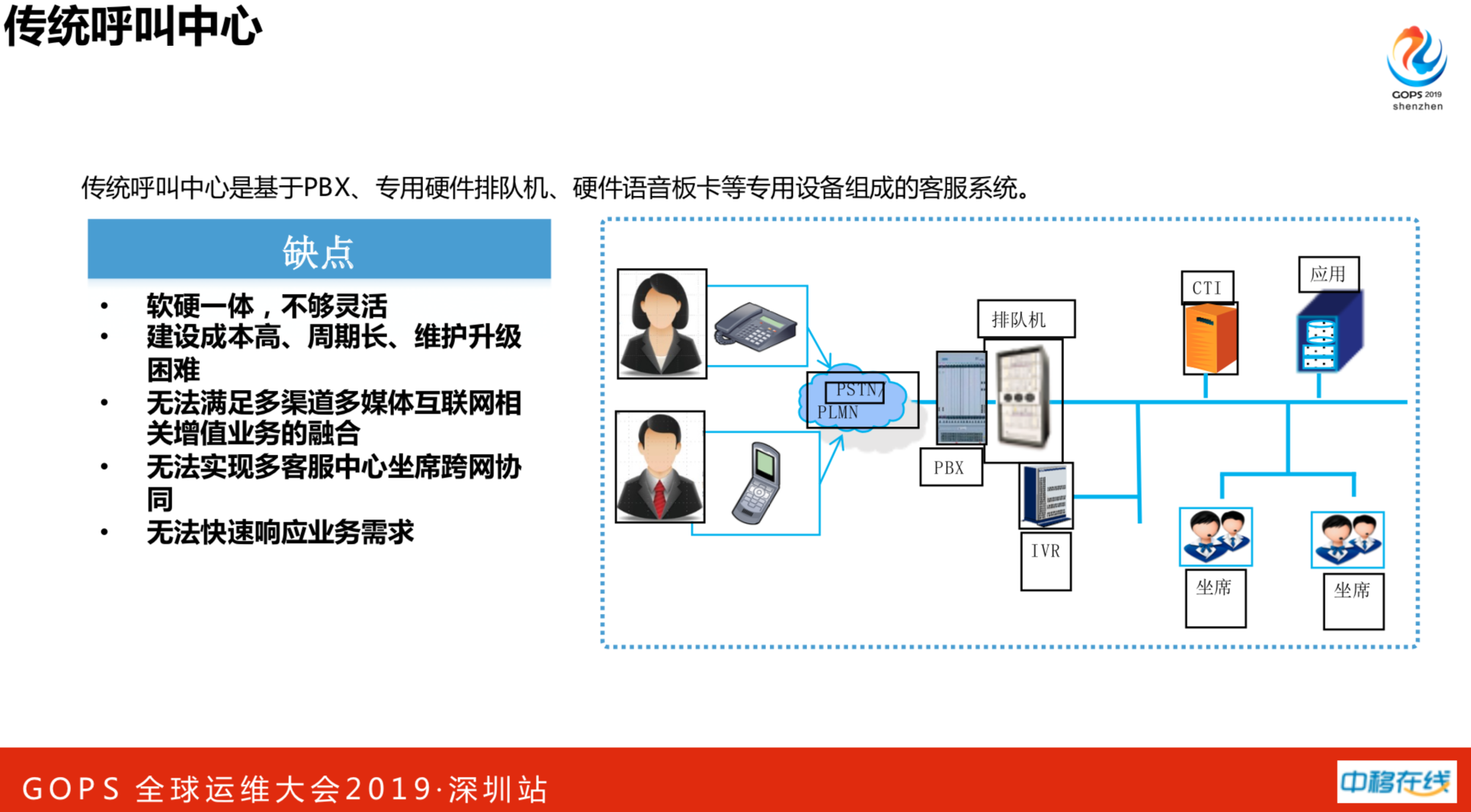
传统的呼叫中心,都是硬件设备,核心自主产权不属于中国移动,都是厂商做的。传统呼叫中心是基于PBX、专用硬件排队机、硬件语音板卡等专用设备组成的客服系统。有很多缺点:
- 软硬一体,不够灵活
- 建设成本高、周期长、维护升级困难
- 无法满足多渠道多媒体互联网相关增值业务的融合
- 无法实现多客服中心坐席跨网协同
- 无法快速响应业务需求

很多硬件设备都过了老旧更换期,有一个厂商说设备要更换了,给我们开出7亿价格,老板问我给你1亿是否干?那肯定干。接下来我们建了一个新形态呼叫中心,具有以下特征:
- 纯软件:全媒体CTI、IVR、互联网接入网关、软交换、中继网关、媒体加速服务、用户终端
- 富媒体:支持传统语音、文本、图片、视频、短语音、微信、微博
- 智能化:与人工智能(AI)、大数据技术结合,应用于IVR、机器人应答、质检、外呼等
- 集中化:接续、CRM、分析、质检、话务监控等集中化。
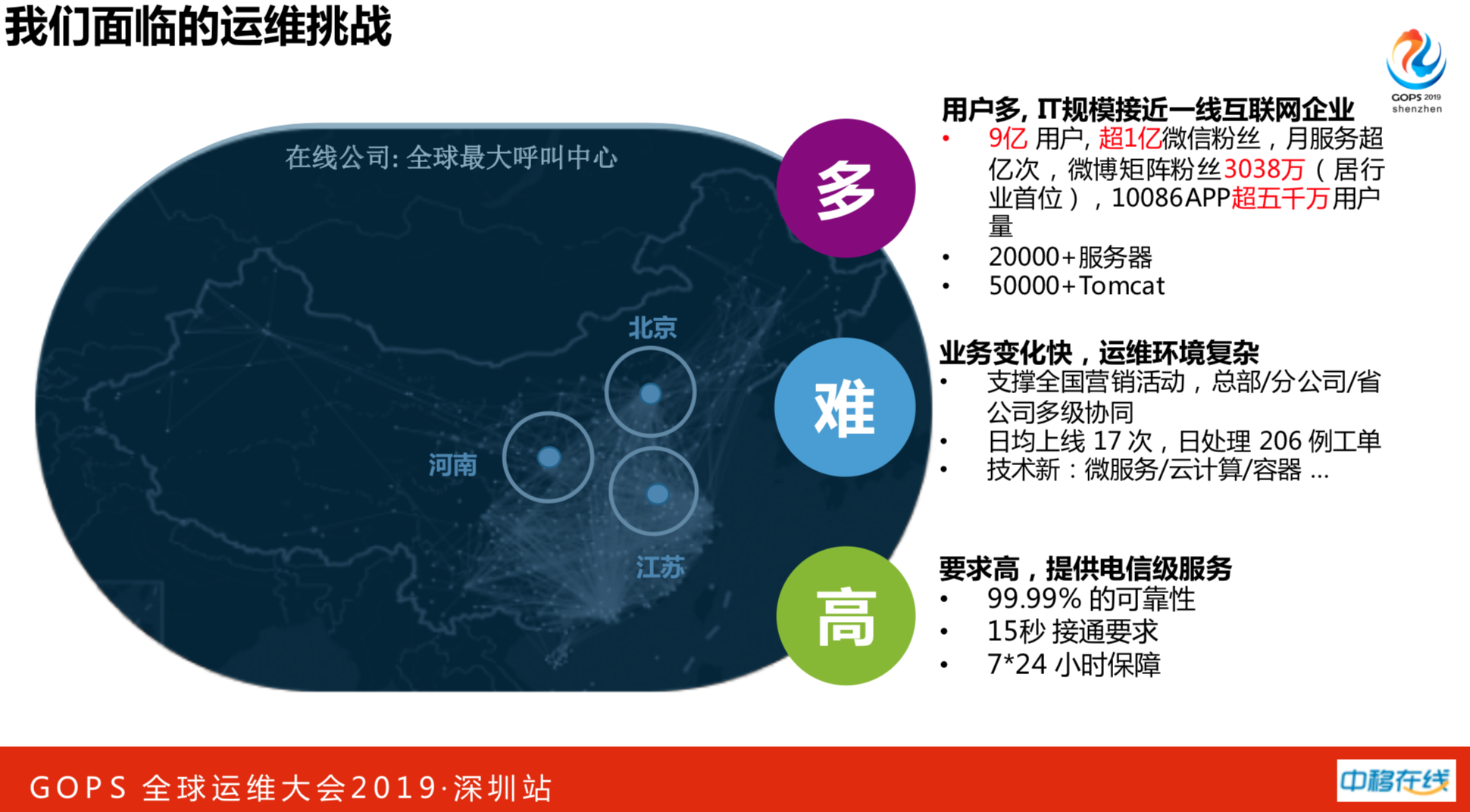
我们现在面临的运维挑战和压力很大。
- 第一是用户多,IT规模接近一线互联网企业。我们中国移动最新的数据如下:
- 9亿用户,超1亿微信粉丝,月服务超亿次,微博矩阵粉丝3038万(居行业首位),10086APP超五千万用户量
- 20000+服务器
- 50000+Tomcat实例
- 业务变化快,运维环境复杂。
- 支撑全国营销活动,总部、分公司、省公司多级协同
- 日均上线 107 次,日处理 206 例工单。
- 技术新:微服务、云计算、容器
- 要求高,提供电信级服务。
- 99.99% 的可靠性
- 15秒接通要求
- 7*24 小时保障
以上多、难、高对我们压力是非常大的。
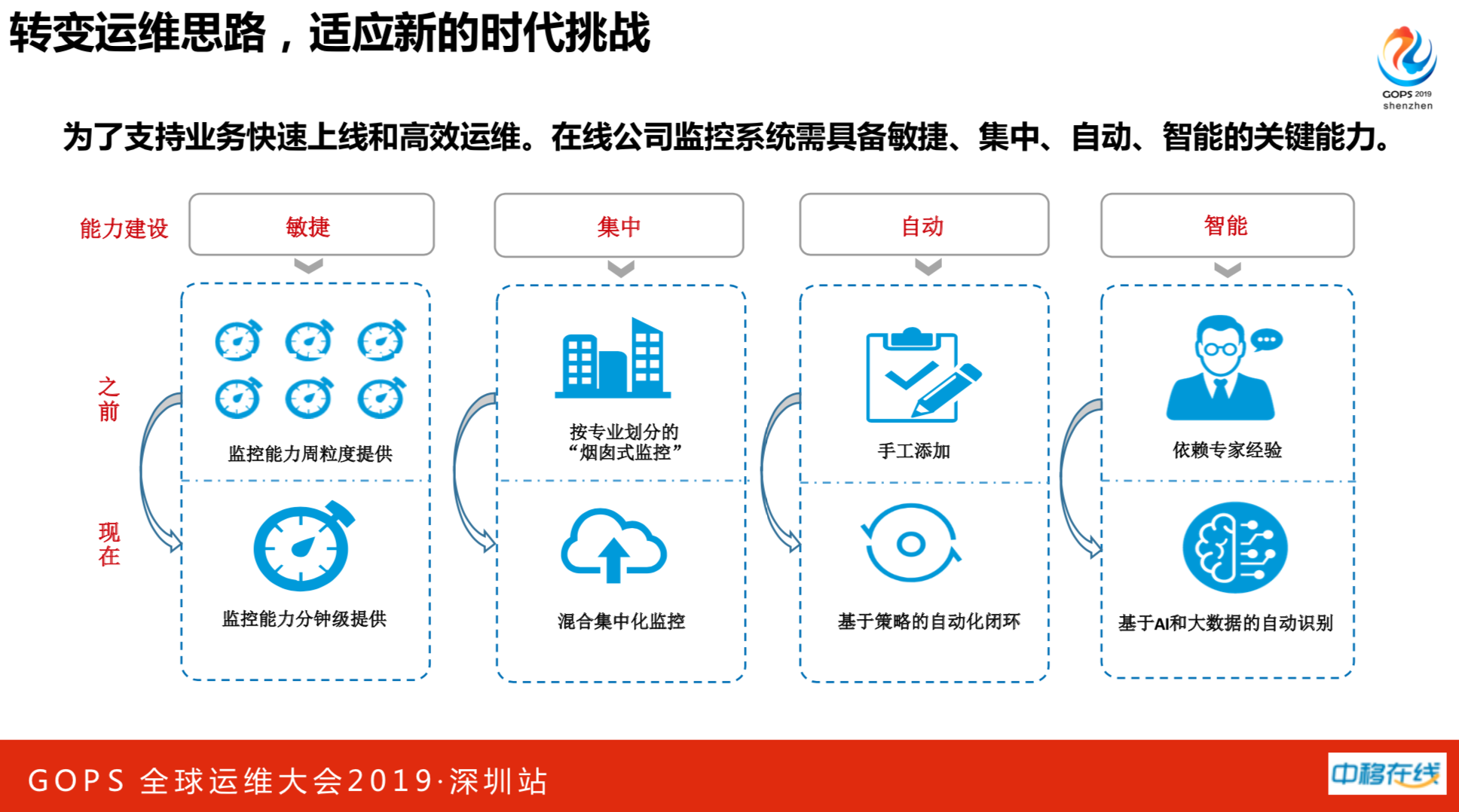
公司是新成立的,当时运维面临最大的一个挑战是建监控。大家知道国企,尤其是运营商的国企,办事情都是厂商在干活。厂商的监控是怎么回事呢?可能提需求一周才能给交付,31个分公司,监控指标和频率差异性不一致。另外全网量太大了,监控也必然大,需求都加不完。因此对新监控系统提出了四点要求:敏捷、集中、自动和智能。
2. 出路---选择开源
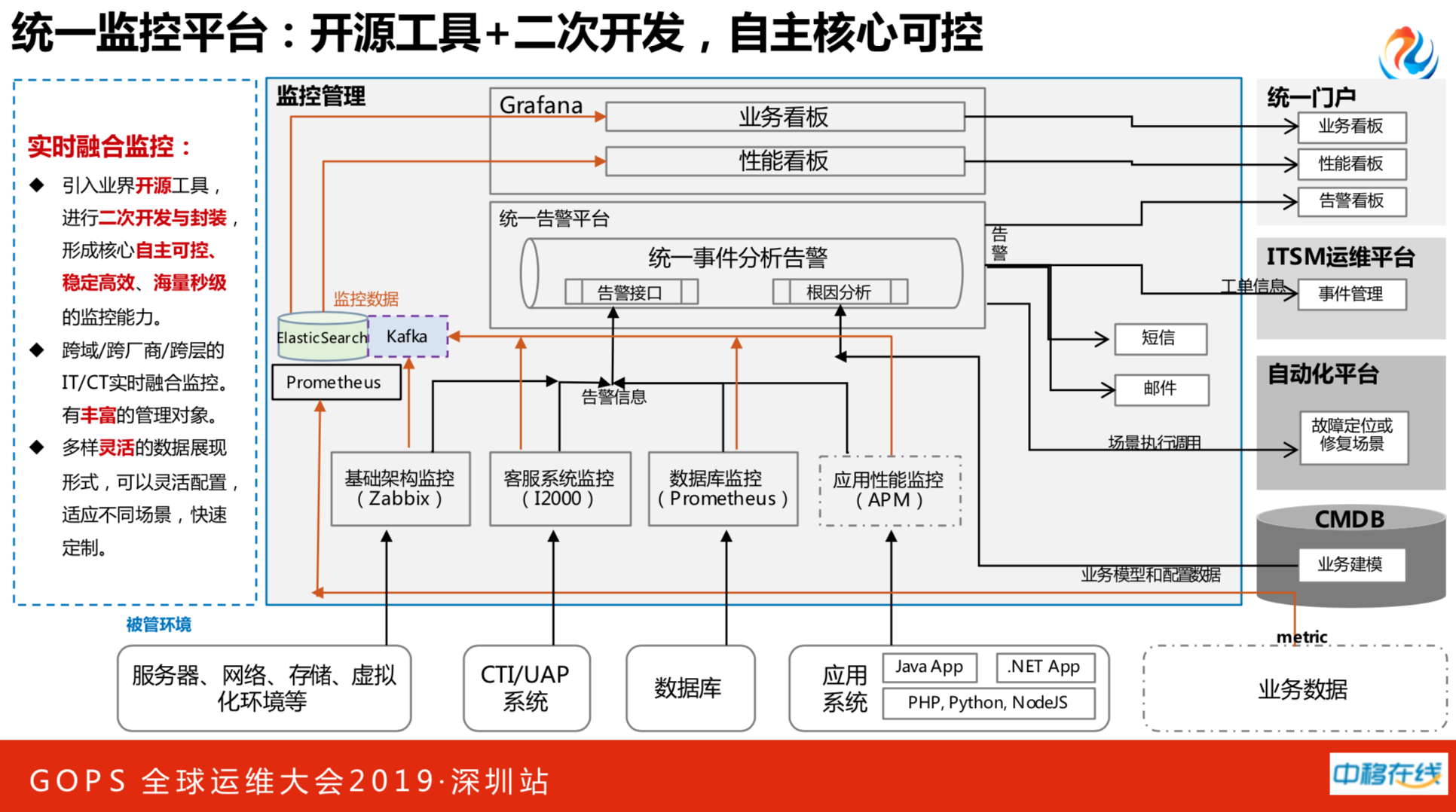
怎么改造现有的监控系统呢?选择开源方案,尤其是监控行业,有非常多很成熟的开源系统。我们统一监控平台是使用开源工具,并进行二次开发,形成核心自主可控。我们做了跨域、跨厂商、跨层次的融合监控。多样灵活的数据展现形式,可以灵活配置适应各种不同的环境。
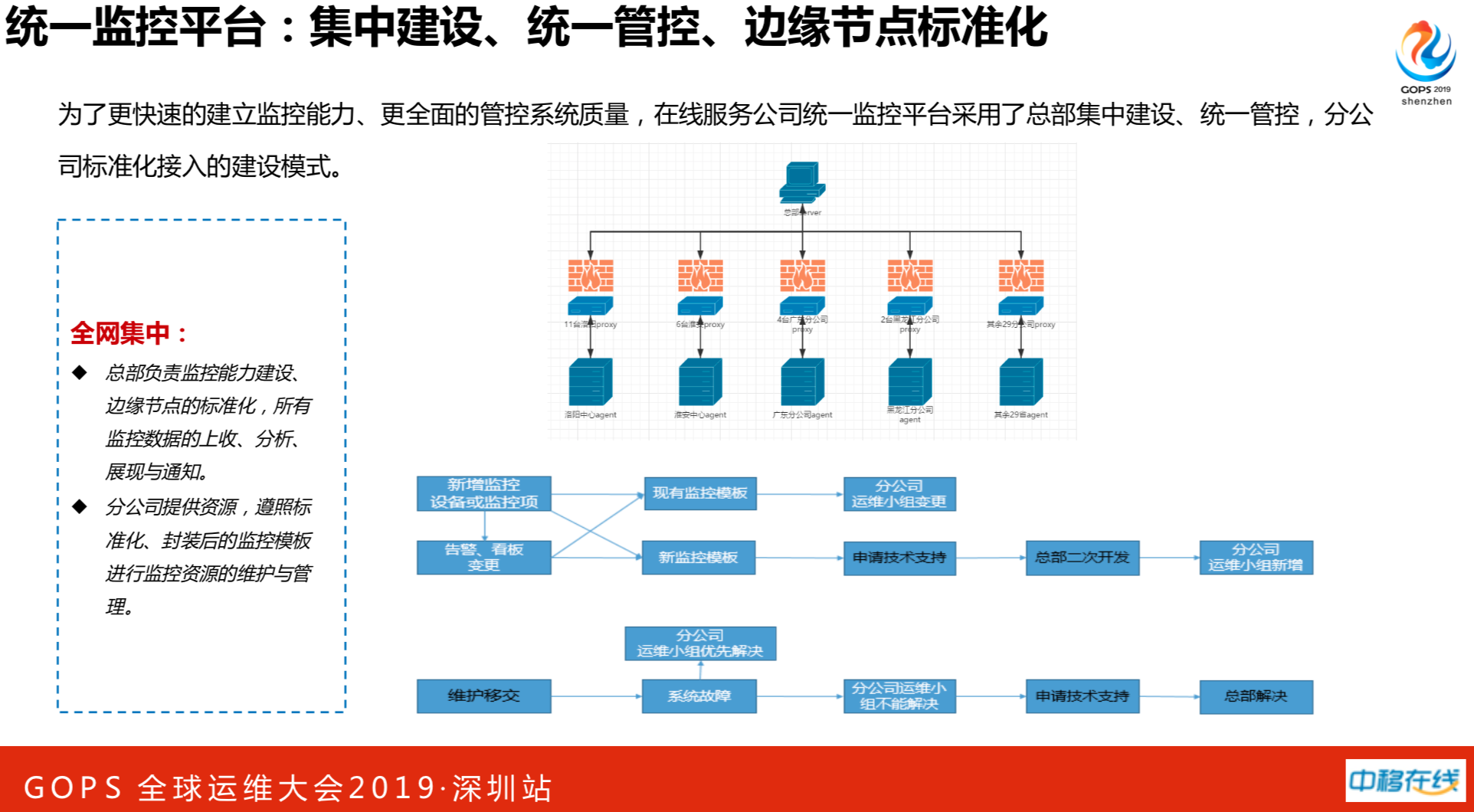
我们做了全国的集中化,也就是31个分公司统一做了一整套的监控系统,为了更快速的建立监控能力、更全面的管控系统质量,在线服务公司统一监控平台采用了总部集中建设、统一管控,分公司标准化接入的建设模式。做了很多标准化的事情,如主机层面、网络层面等等,各个监控项、模板、代理等遵照标准进行封装。

半年的时间,基于成熟的监控能力,我们2万台主机设备入网,2000万监控项,90万触发器,一天产生30万报警。

这是我们使用的一些开源软件系统。
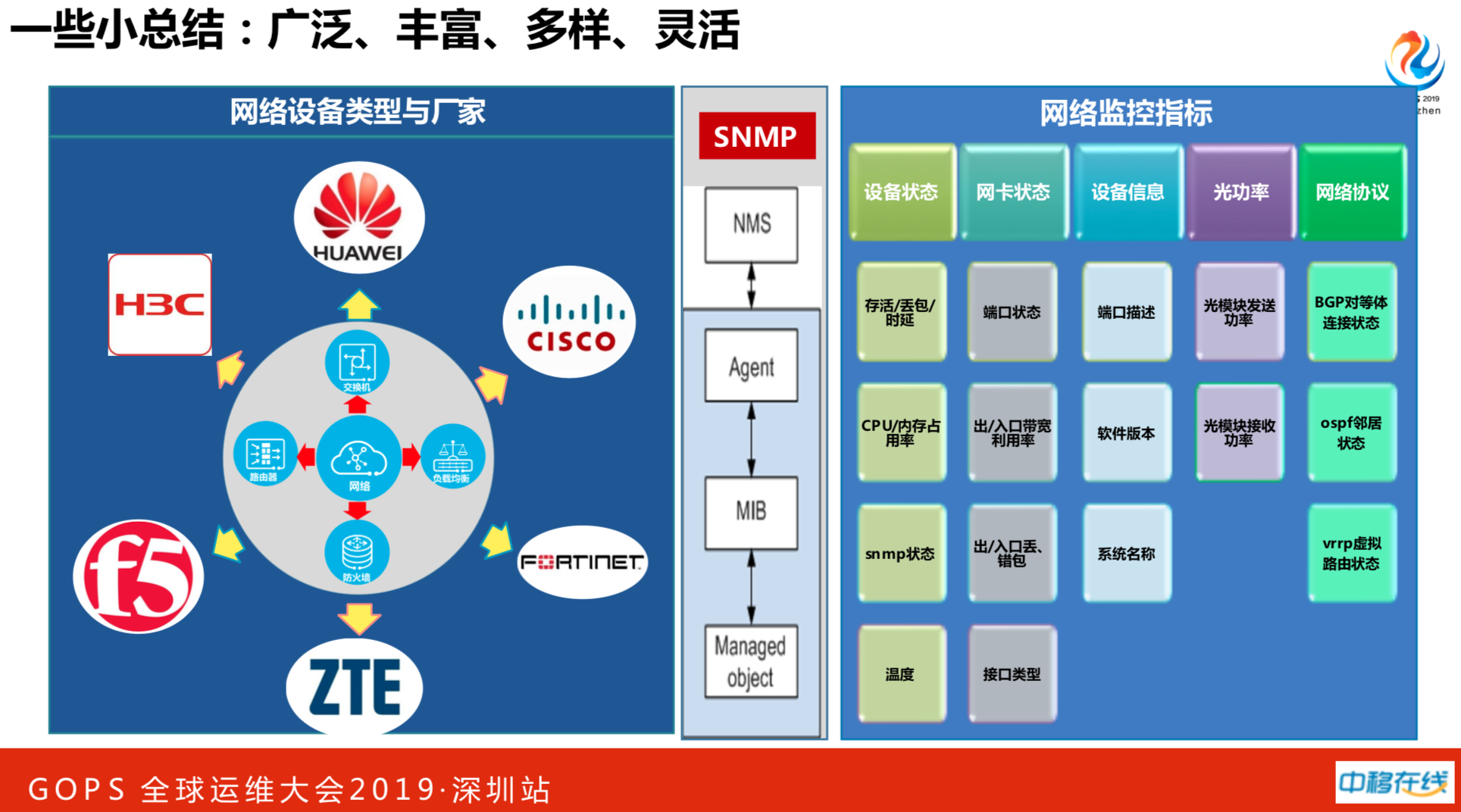
中国移动都是集采,没有一个网络设备能跑定天下,因此我们做了很多兼容。
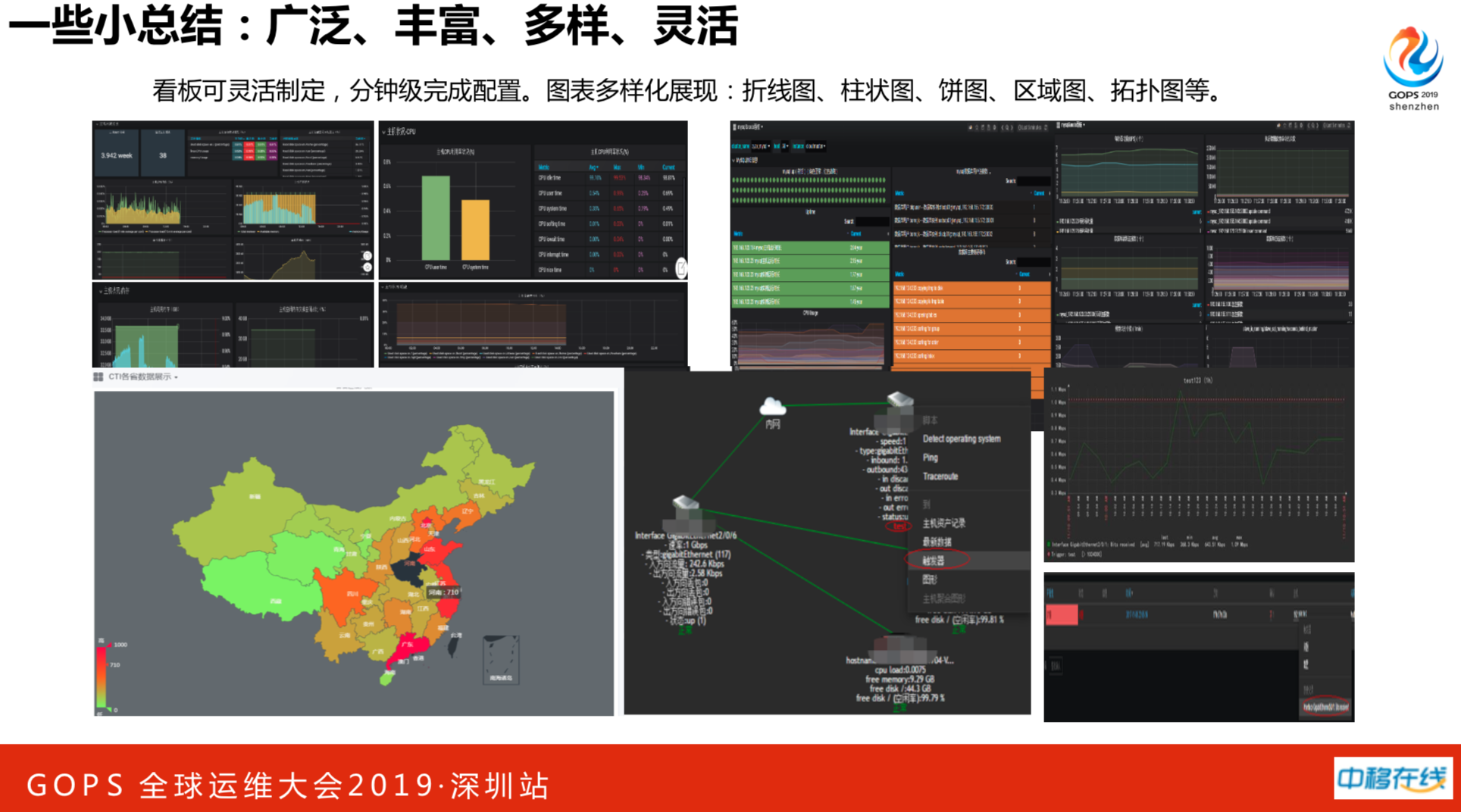
这个看板可以灵活定制,针对不同的业务系统和不同的省分公司,都可以分钟级完成配置。

接入31个分公司的全量主机,这对zabbix系统是一种考验,200万监控指标,肯定要做优化的。最后发现做了很多优化并不理想,还不如花点钱做硬件的升级。比如说数据库方面,CPU、内存、IO、连接(最大连接数、超时时长)、数据一致性、强烈建议采用数据库SSD硬盘。主机参数、内核参数、TCP协议栈参数、信号量/IO(Zabbix启动失败不释放信号集)。还有nginx、php参数设置。以及Zabbix的优化,比如说视具体需求配置启动模块和进程数,禁用自动发现,采用脚本调用api实现,禁用housekeeper,启用数据库表分区,禁用server直连agent等。

这个是真实案例,当我们监控数据超过150万,第一次发生故障,zabbix系统一直在重启。监控系统和报警系统是所有业务系统里面最重要的。经过分析现象如下:
- 发现大量消息队列积压(超过20万),且呈现雪崩效应。
- Preprocessing manager 负荷长期为100%。
- Zabbix server主机反复重启,却无法启动成功。
右上图是zabbix官网对于pre-process耗尽的说明。
解决方法:
1. 在zabbix server所在主机再单独部署一个proxy节点。
2. 将之前由zabbix server直接监控的所有proxy所在主机的agent节点,全部转到新增proxy管理。
3. 降低server的pollers、java pollers、pingers、trappers等进程数配置。
4. 增加zabbix server的自监控项配置项及告警( Pre-process进程占用率及zabbix_server.log的异常关键字告警)。
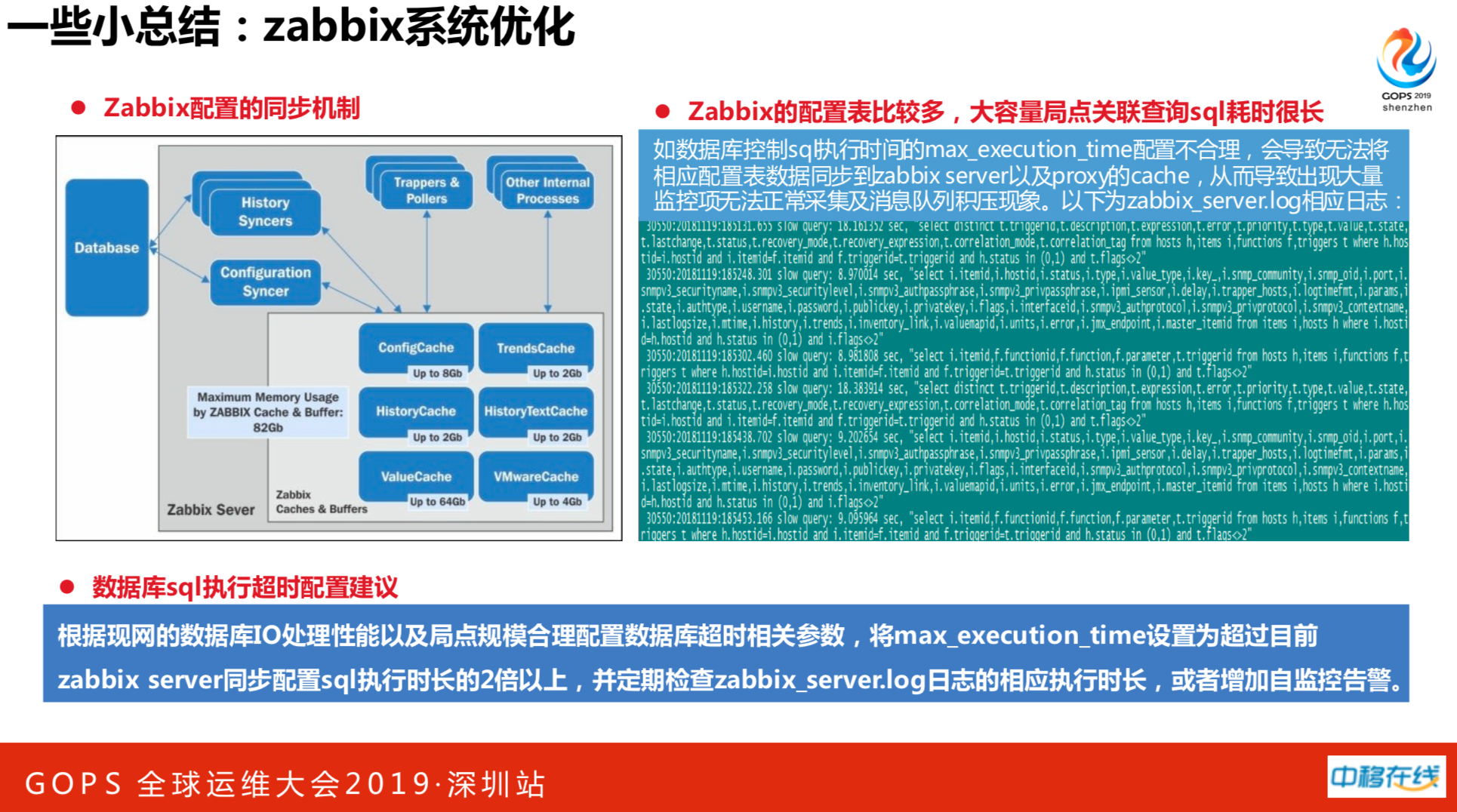
这又是另一个真实的案例。在监控数据到200万的时候又挂了一回。主机选用代理模式时,肯定会涉及到主机在server上同步配置。监控机制会定期查server的数据库。当指标过多时,zabbix数据库会关联查询很多东西。这时候大容量关联查询SQL耗时会很长,可能会超过max_execution_time值,就会放弃的,永远执行不成功。最典型的是新增数据项,会发现底层的代理怎么样都采集不上去并且还会积压消息队列。
建议如下:根据现网的数据库IO处理性能以及局点规模合理配置数据库超时相关参数,将max_execution_time设置为超过目前zabbix server同步配置sql执行时长的2倍以上,并定期检查zabbix_server.log日志的相应执行时长,或者增加自监控告警。
3. 转型---几个问题
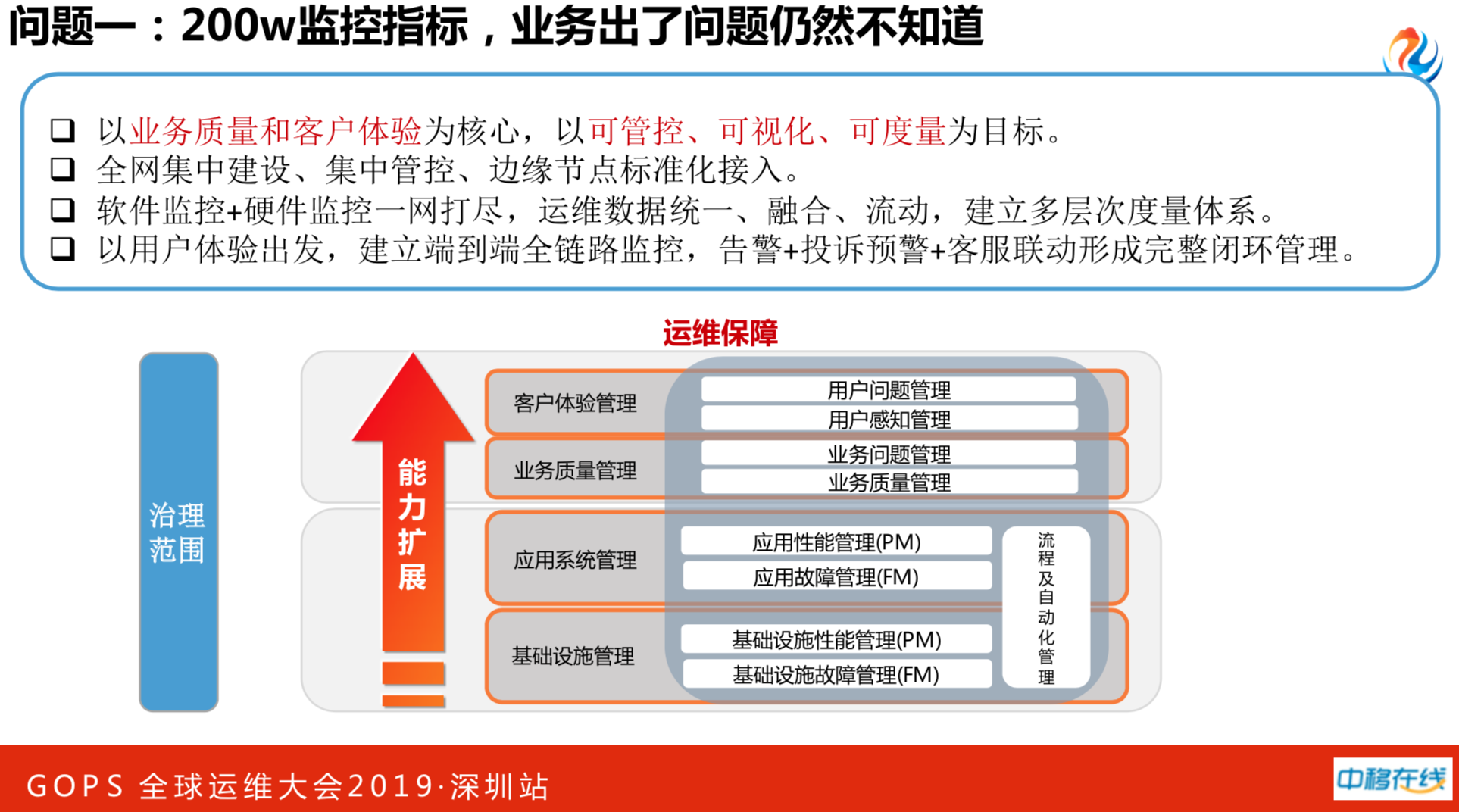
即使做了这么多优化,依然还有很多问题。其中最尴尬的一个问题是拥有200万监控指标,业务挂了依然不知道,用户报的比监控快,这是监控的问题。后来发现我们以前做了基础设施的管理和应用设施的管理,用户质量和用户体验是空白。接着扭转了思路,不为业务服务的系统不是好系统,不为业务服务的运维不是好运维。我们以业务质量和用户体验为核心,以可管控、可视化、可度量作为新一代业务的目标。以用户体验出发,做了端到端的全业务链监控。

左边是应用性能监控,可以把用户体验、前端交付、网络切片等这些事都给整合了,实际上在用这套东西时,没有想象中的那么好。后来我们从日志侧进行弥补,这个东西成效比较快,是无切入式的,你把插件装好就能搞定,但是这个追踪不是很完备。又从框架层入手,加入全局追用ID,通过日志平台进行监控。
右边是关注业务质量监控,我们根据谷歌的五项业务环节指标来一点点梳理核心业务系统,到底有哪些核心功能,优先考虑业务监控,再技术监控。
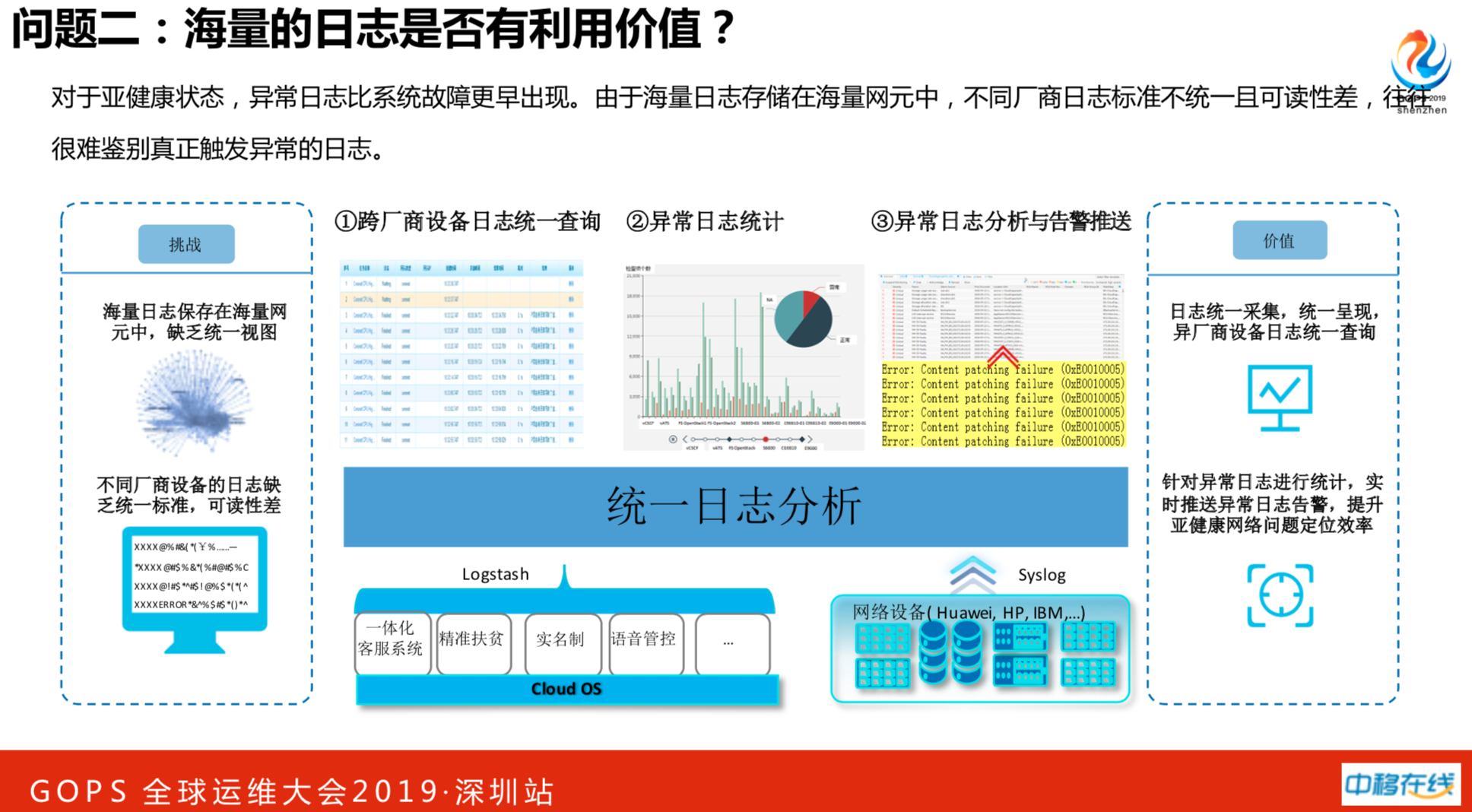
比如说用户登陆不了,有一些是做优化嵌入不了,可能有些业务系统在亚健康状态就需要处理,没有必要等到真正故障时才介入。做日志监控也有隐患,我们设备跨厂商的,业务和网络设备的日志都全量收上来,做了全总部的日志平台,异常日志的统计,异常日志的分析与报警推送。针对异常日志实时推送告警,提升对亚健康网络问题效率。

这是我们的一个场景。接口平台,我们有31个分公司,每个分公司要跟省公司进行交互,每个接口平台跑3千个接口。如果统计这个接口的调用量、成功率和失败率,用zabbix做监控的话,需要加入2480万的监控指标。我们在200万时故障了两回,突然加到2480万的监控指标撑不住。后面尝试使用prometheus,要做一个监控项,必须有一个监控项在数据库,利用prometheus灵活的自定义babel功能实现数据采集和动态图形展示。

管控资源对象有容器云、业务监控、数据库、应用、中间件、物理设备等等。运维数据分析平台,比如日志通过flink进行实时的数据处理和分析。对于zabbix和prometheus性能的监控数据,我们会送到大数据平台,每天每小时出报表。同时还做了一些智能化的应用。在上层运维场景做了一些小应用,通过接口提供对外数据监控,为重要业务做量身的定制。
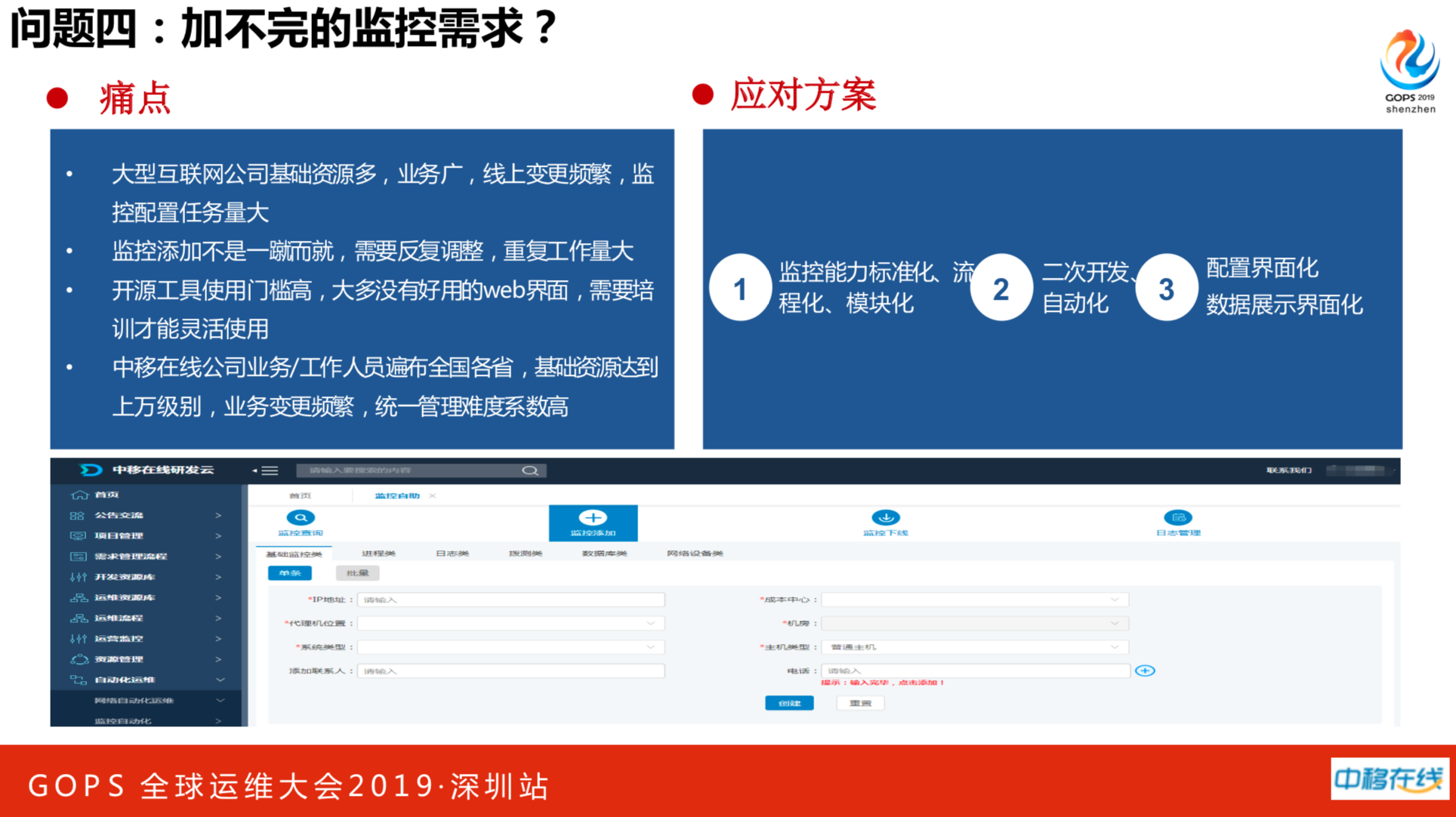
做完新的监控系统以后,又遇见新的问题,每天都有小惊喜,跟技术没有多大关系,纯粹是添加监控的思路。我们场景比较特殊,总部支撑31个分公司的需求。每个分公司一天提3个需求,一天就可以接100万,任务繁重,再加上降本增效,这是很难解决的问题,还是得自动化。因此在推广监控时,把监控能力标准化、流水化、模块化,接着二次开发自动化,实现配置界面化和数据展示界面化。这时候可以把31个分公司负责监控的同事开个会,需求至少减少50%以上。
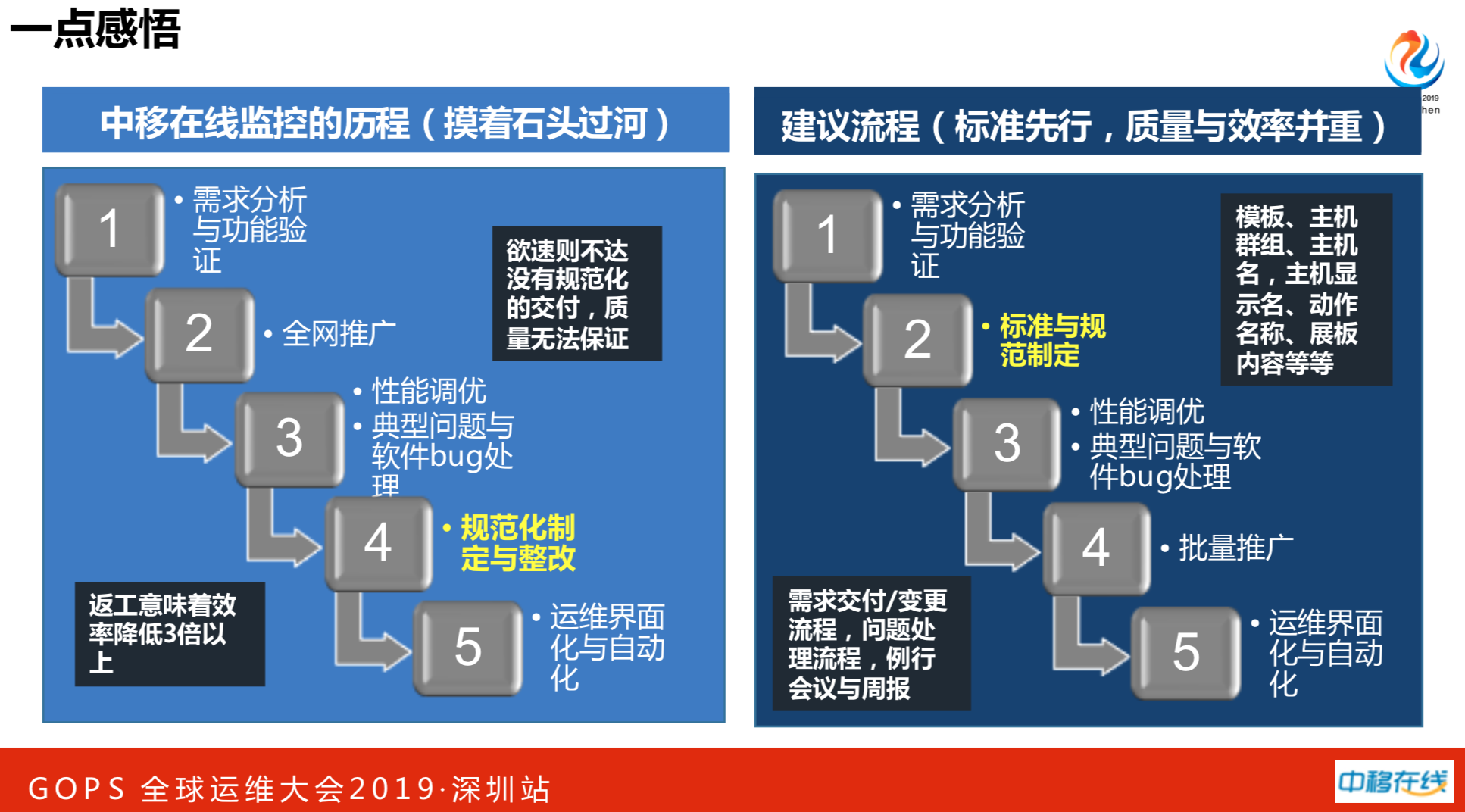
在做标准化路上时,我们的历程是摸着石头过河。推的时候没有做标准,以速度和效力优先。后来发现搬起石头砸自己的脚,花了很大的力气进行返工,这是很大的教训。建议大家,先做需求分析和功能验证,制定标准与规范,最后才能批量推广。
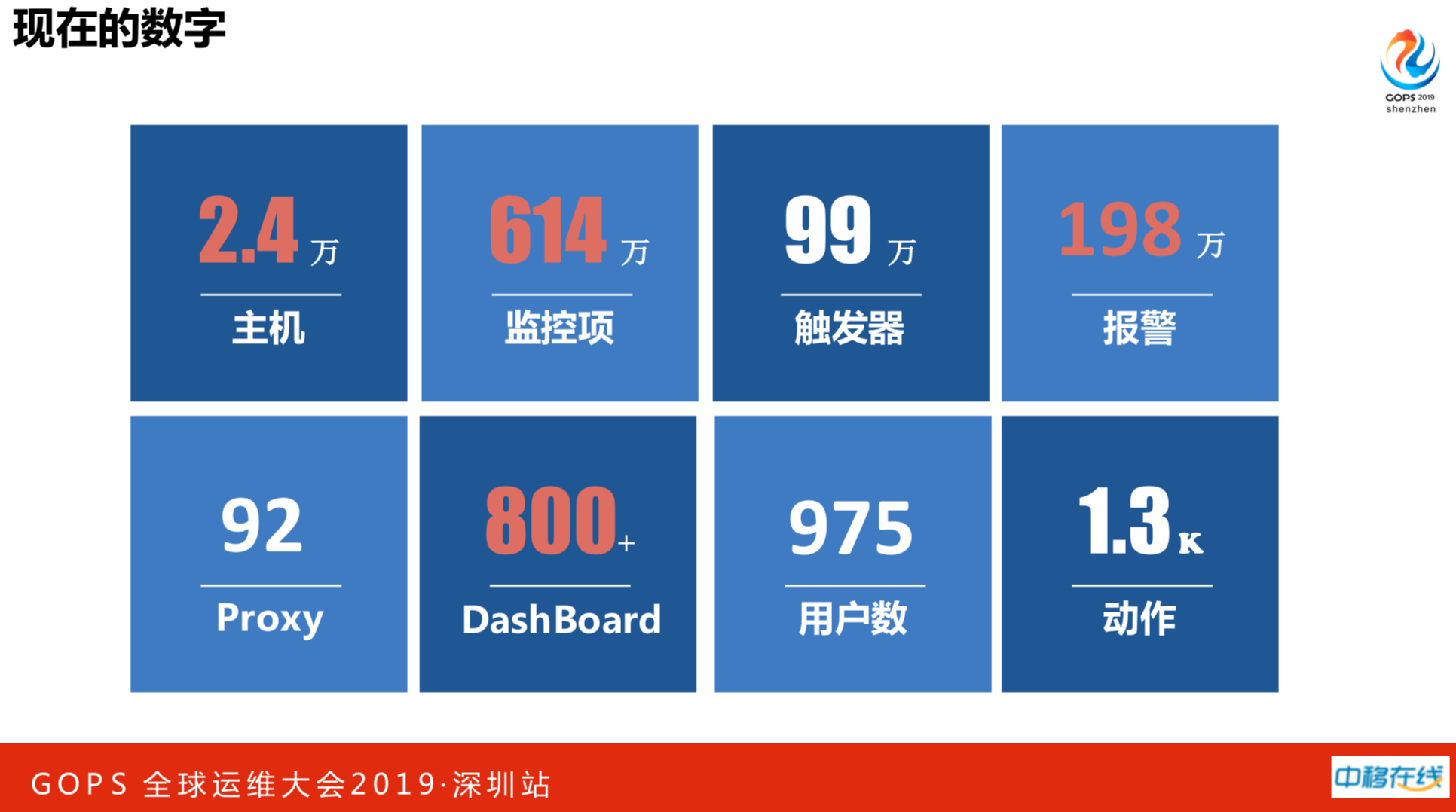
现在我们2.4万主机,614万监控项,99万触发器、198万报警。
4. 蜕变---AIOPS在监控告警方面的尝试

当前主要矛盾在于海量的告警系统与有限的专家。老板说:小王监控要多而全,一个问题都不能放过,少一个监控没有监控出来,就是你的锅。底下的小兄弟们天天吐槽说:王姐,你每天2千万报警短信,把人看吐血了,我是人,我要休息。
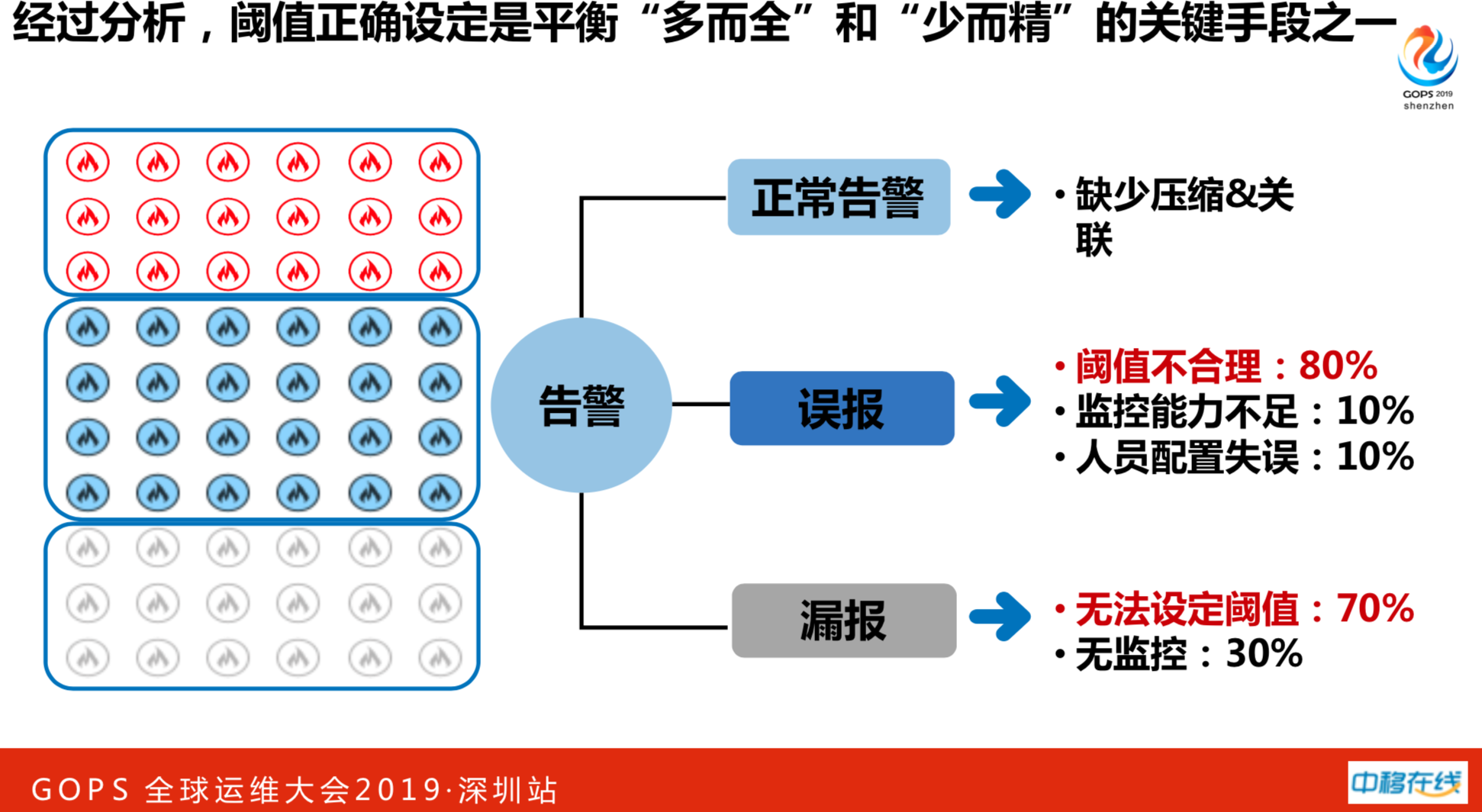
解决问题要数字化思考,经过数据分析阀值正确设定是平衡“多而全”和“少而精”的关键手段。
- 正常报警缺乏压缩与关联,正常要做调用关系的压缩。
- 误报警有80%是因为阈值设置不合理。
- 漏报有70%,业务员不清楚应该设一个多大的报警阈值,出的故障之后才会想起这个事情。
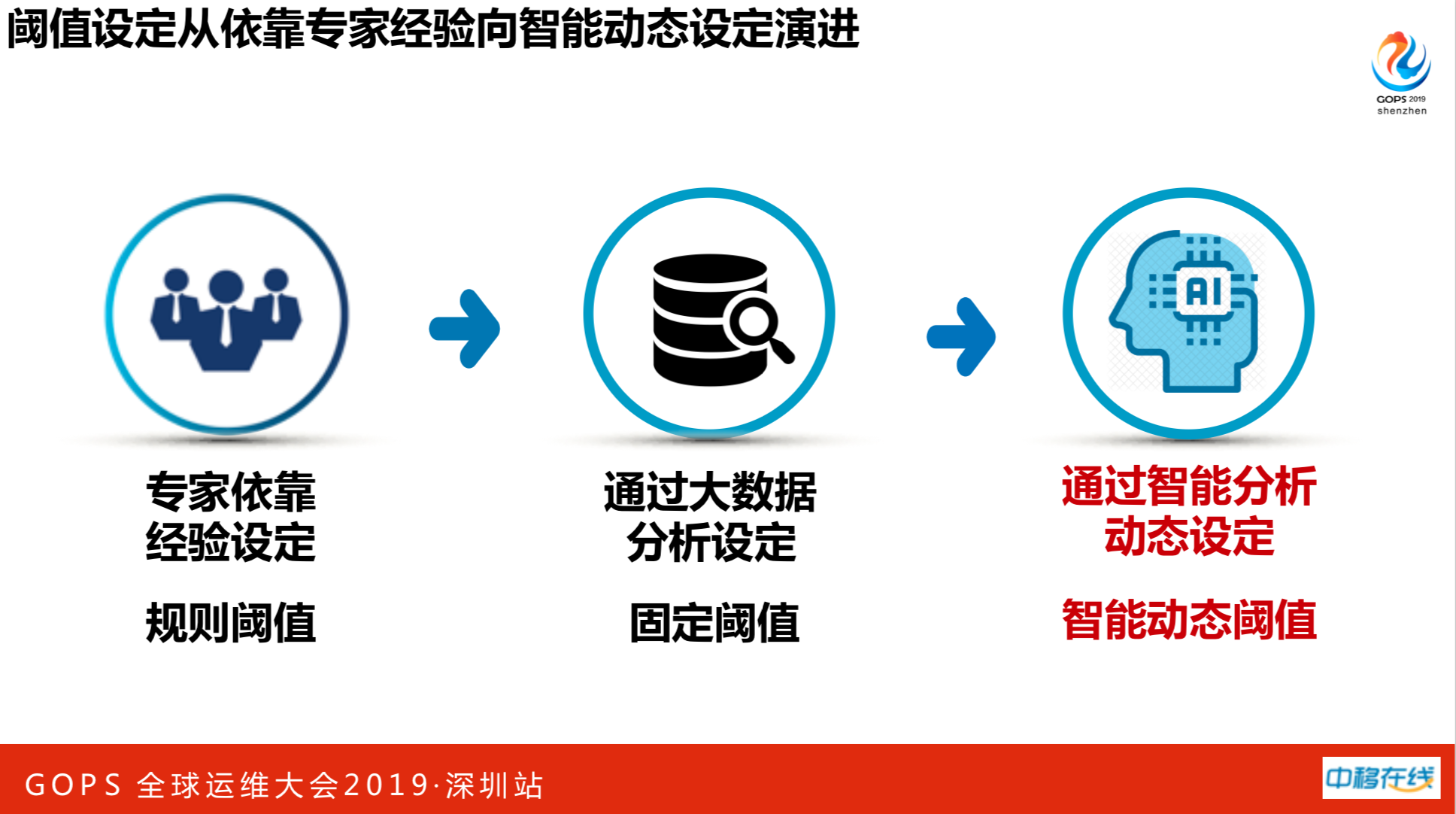
如何解决上述问题呢?正常告警关联压缩智能化。一旦设定了一个合理的告警阈值,可以解决70%至80%的问题。依靠专家经验设定规则阀值,如网络设备CPU利用率超过60%就应该报警了,该扩容了。后面是通过大数据分析设定固定阀值,这也不能完美解决。每个业务每天有不一样的波峰和波谷,在业务高峰的时候,可能会触发误告警的,这就需要通过智能分析动态设定阀值,随着变化而变化。
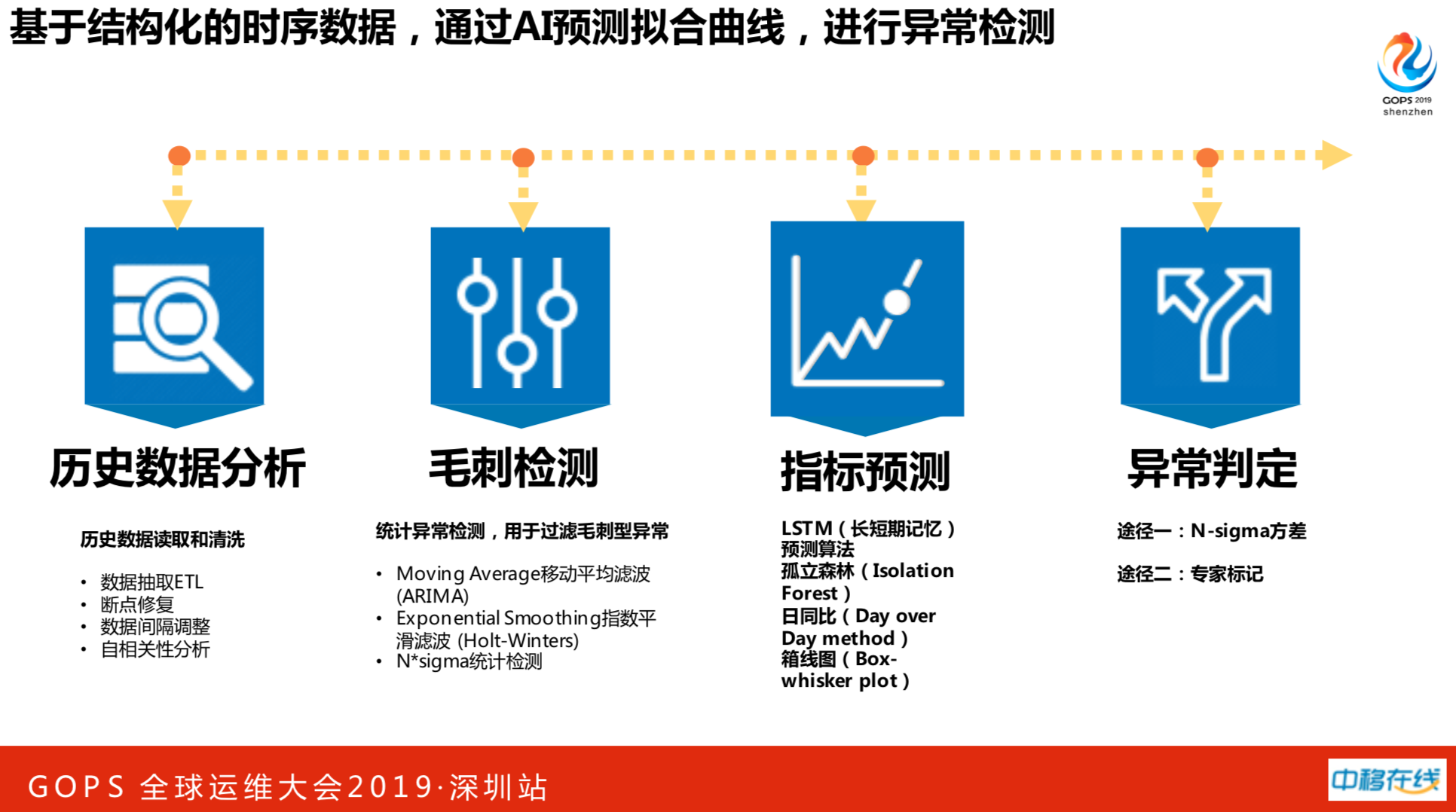
我们想实现随着业务量变动的可变化的阈值。从人工智能算法入手,通过历史数据读取和清洗,经过数据间隔的调整和历史性分析,把异常的毛刺检测剔出,然后使用开源人工智能算法,根据历史数据预测未来的趋势。以用户登陆量为例子,查看历史三个月用户平均登陆的趋势,获知明天每个时间点上,用户登陆量大概是多少。监控会把每分钟登录量进行对比,如果预测数和当前数差值很大,证明实际发生跟预测有很大差距,这时候产生的异常值报警比固定值报警要准很多。产生异常报警之后,进行故障处理可能会发现不准,准和不准的过程是数据标注的过程。人工智能要有计算的能力和算法。在一次次判断过程当中,实际上是对算法进行优化,会越来越准,形成良性的循环。
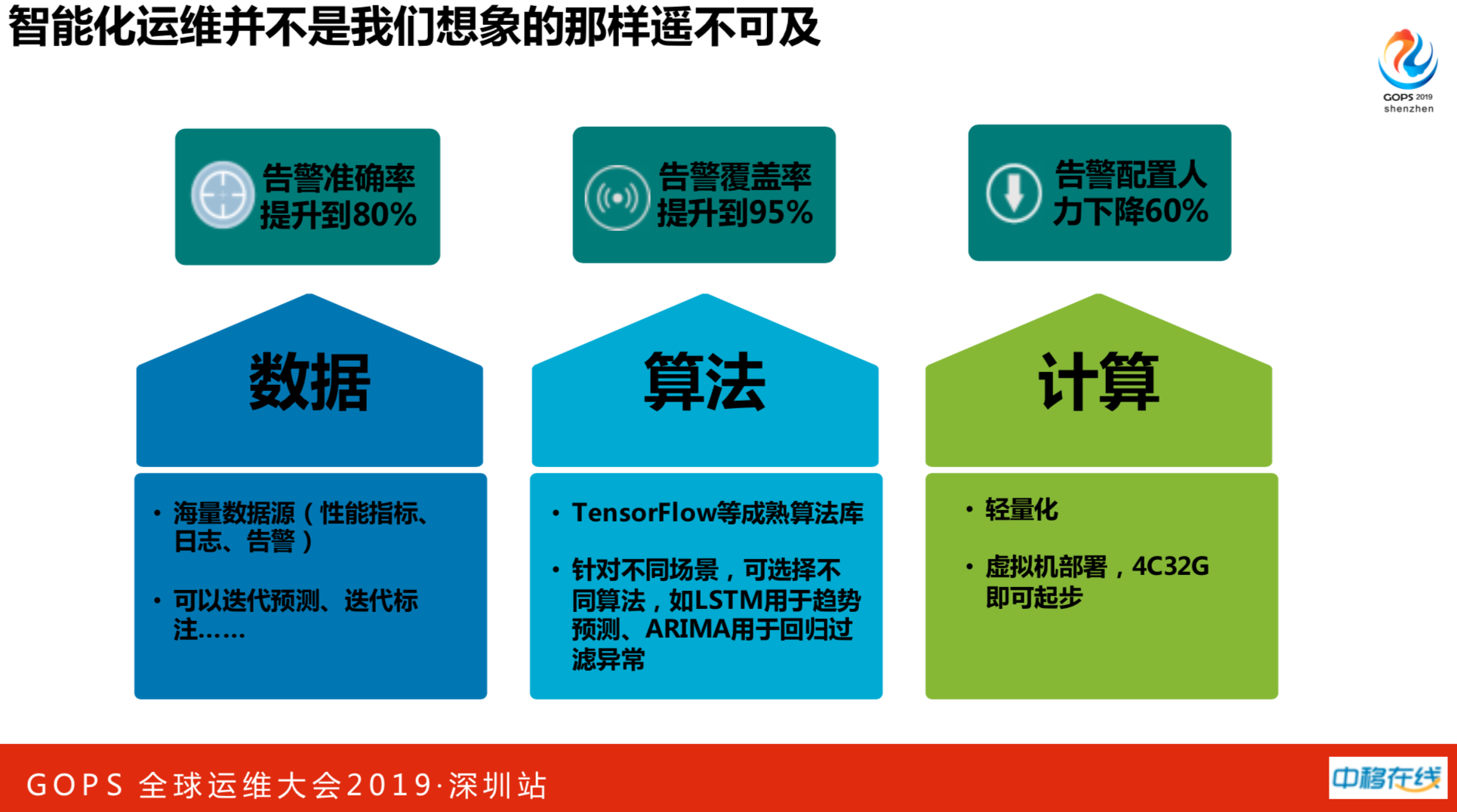
智能化运维离我们并不遥远,有三大要素:数据、算法、计算。
数据有监控数据、报警数据。我手下的兄弟有搞算法的,并不是高档的算法博士,看两天算法就写出来的,然后再实践,不需要对算法有多么深的理解。由于我们是对结构化的数据做计算,不像人工智能非常热门的领域,如图像识别、语音识别,我们是轻量级的应用不需要投入GPU服务器。

上述内容主要是在运营领域,人工智能投入的很少的。在日志异常检测、告警压缩和关联、告警规则生成,容量管理、性能管理等都可以智能化实践。希望针对智能化在更多运维领域落地开花,运维并不是从传统才能走向智能,有很多场景是可以弯道超车的。
