@gaoxiaoyunwei2017
2018-12-25T07:39:57.000000Z
字数 3243
阅读 1411
见微知著数据库应用的浅谈
彭小阳
前言:众所周知对于IOTP的交易系统最重要的操作就是数据库的CRUD的操作,数据库层面或者SQL优化的程度,对于整个系统的应用并发处理是起到至关重要的作用。
很多朋友都会碰到这样的问题,某个朋友的数据库层面运转非常稳定,SQL处理能力也很强。当业务发展一定阶段之后数据库出现了错误,SQL语句性变差,导致处理能力变差,比如说资源的问题、环境的问题以及数据库设计的问题。
今天我们选择某个核心交易系统核心数据删除的逻辑设计优化案例。我们的目标也是说通过一些介绍了解业务发展的不同阶段,我们旧数据的删除逻辑是如何演进的,以及不同演进过程当中有哪些设计优化的经验。我分为以下四个部分做分享。
一、案例背景

首先我们看一下背景,这是一套核心的OLTP的交易系统,我们看一下最重要的是需求背景,这套应用背后有二十几张关联主子表,表中数据过期数据要即使清理。
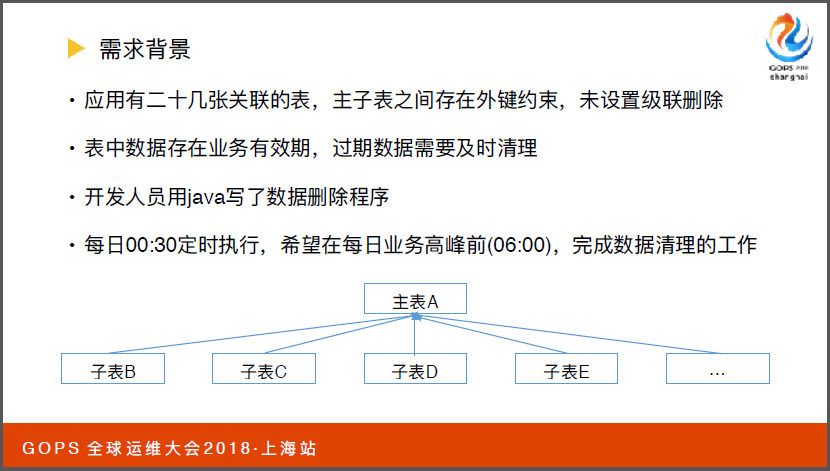
开发人员用java写了删除的程序,我们希望每天六点之前完成数据清理工作。
二、问题描述

接下来看看业务的问题。相应数据删除执行时间在变长,前面最开始三十分钟到两小时、五小时、十小时等。

经过分析有一张5000万记录的子表B,删除资料率比较低。主表A会有2000万数据存储七到两天的数据量,子表B关联到的是主表的ID。子表B每天删除七百万,对于它的删除逻辑,对于主表A来说需要从子表找到需要删除的阶段。

同时因为主表A下面有一系列的主表,我们最开始设计是按串型的设计逐一删除每一张主表,再删除子表。
三、细查深剖析

我们会从几个阶段来看看针对数据删除的逻辑我们是如何严禁的,如何采用不同的方案做优化的。

首先阶段一业务投入初期,业务量非常有限,开发人员使用SQL语句就可以,通过A表筛选出来七天之前的ID记录,然后和子表B做一个关联删除B表中的数据,同时有一个(英文)参数,目的避免大事故的产生。
因为子查询当中只存在十天的数据,它采用了扫描的方案,我们根据之前的数据量的预估推测,它需要执行七百次的扫描,这是完成数据清理的操作。这个阶段来说业务量有限,数据库的配置比较高。

其实从业务需求来讲,任何SQL满足都是可以接受的,但是它的隐患非常明显,我们对一张大表执行了全表扫描,它的危害执行时间会随着数据量的增加而增加。

我们到了阶段二,业务量有增加了,这时候SQL执行时间也变长了,为了提升效率我们做一些优化。我们第一个思路就是能不能少做一些事情,它的存储就是在主表A中要删除数据的ID级别,通过中间表C再和子表B做关联,它和阶段1是什么差别吗?阶段1是做7000万数据的扫描,现在只需要做200万的扫描,同时并发执行 多数张子表的删除。

相比阶段一它把对于子表的删除由串型改成了并型,它的性能一定是略有提升的,但是问题还是有,他还是对两百万的表大型了全表扫描,它的执行时间还是随着业务的推广逐渐增加的。

到了阶段三,这个时候业务发展比较迅猛,业务量接近中级的状态了,这时候夜维时间超出了需求,现在的优化目标就是能不能避免子表全表扫描的操作,我们通过上传四步操作来看一下,首先创建了中间表C以及pkid。

同时将ID对应(英文)数据也存储中间表C当中,然后再去做B表关联删除,原先的是通过(英文)限制删除一万条记录,现在把一万条记录融入到内部。

比如说第一次的时候子查询pkid的字段是一到一万一,接下来就是一万一到两万一。通过业务上的评估,C表当中有一个IB,对应子表有两到三条。虽然和之前相比数据量增加了,但是量级上基本上是可控的。
这个阶段我们做的方案个通过pkid的索引避免子查询的全程扫描,带来问题对B表的删除数据多了,相应的次数减少了。如果按照我们最初的分析,这种方案应该是比较完美了,可以解决我们之前暴露的问题。

实际的话现实和理想是有差距的。我们在上线当晚就报错了,我们从日志当中看到它抛了一个01555的数据这是一个非常经典的数据号。它的原因就是在做数据检索的时候,有些数据变化,我们需要从UNDO来做查询需求,如果SQL执行空间比较长,UNDO被其他覆盖了,这时候就抛出01555的错误。
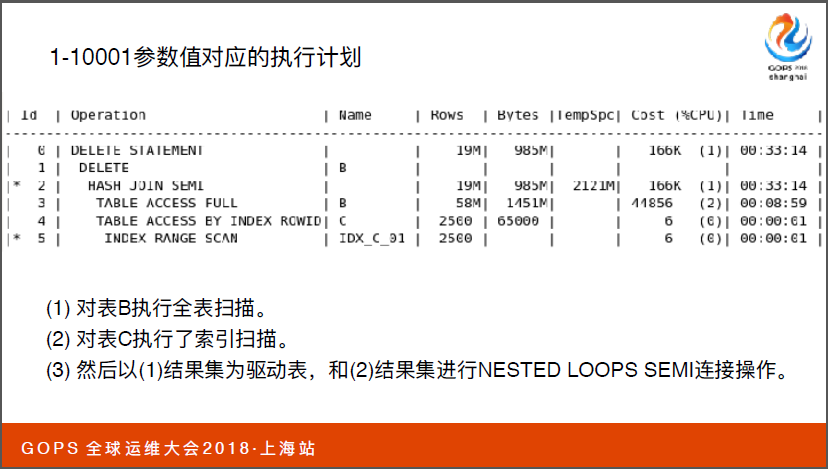
对于C表它采用了索引范围扫描,用到了索引,但是对于子表B它执行了全表扫描,正是因为全表扫描才指引SQL执行时间非常长,才让EV执行程序出现了错误。

现在问题来了是不是因为子查询一万数据太多了?后面我们查询把子查询缩小到五千、两千五以及十一个数据,它依然没有改变。我们常识 1910001到1920001的参数值发现变了,它将两者进行循环连接,这才是我们真正需要的执行计划。
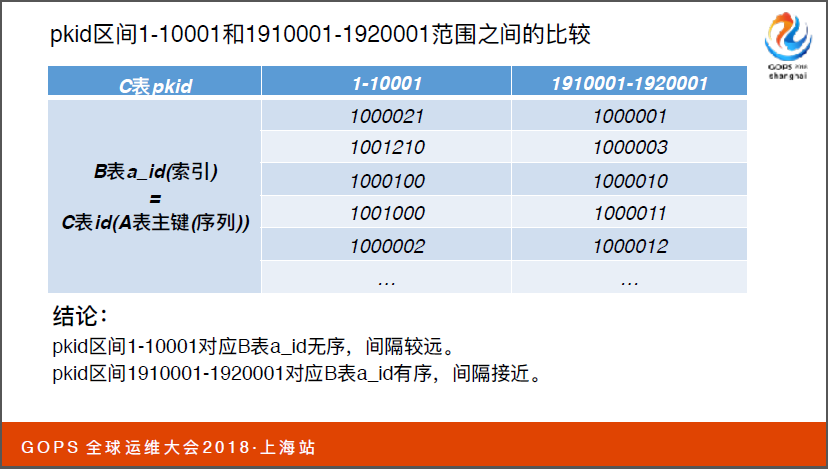
现在问题又来了,我们在分析一下这两个阶段之间它对应到A表需要删除的a-id字段数据是非常有序的,比如说左边是1000021右边是1000001。这又能说明什么问题呢?我们联想到它的含义就是数据块中的相似程度。当我凑索引的节点去回表,同一个索引的节点去找数据,对应不同的数据块。
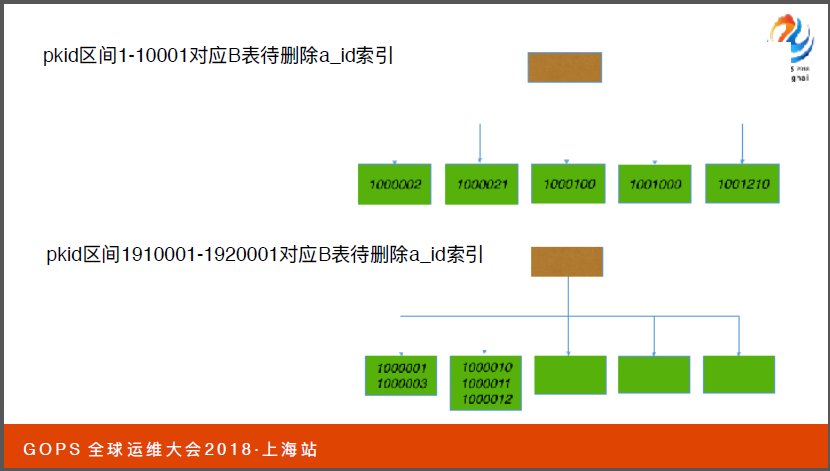
我们通过图来理解一下,这个图是非常完美的情况。如果我们通过索引节点回表访问数据的话,这是比较高的展示,我们需要读取索引节点需要三次的(英文),它需要访问数据,达到我访问需求的成本就会更高。
11G以上的优化器是CPU,再回到我们的案例上,我们可以大胆推测pkid分布在不同的索引数据块上,1910001到1920001的数据块上成本的消耗低很多,所以这一块对区间值选择了不同的计划。

现在我们明确原因之后,我们看看如何改造和优化?其实目标尽量让B表一次删除的时候a-id字段相邻。现在构造C表的时候,希望在删除B表是DID间隔很近的目标。它的执行计划是我们认为比较高度的执行计划,它对子查询的C表做了一个PKID扫描,然后通过子表B也做了扫描,然后进行删除操作,过这种调整让PKID的区间值无论哪个范围之内都达到这样的目的。
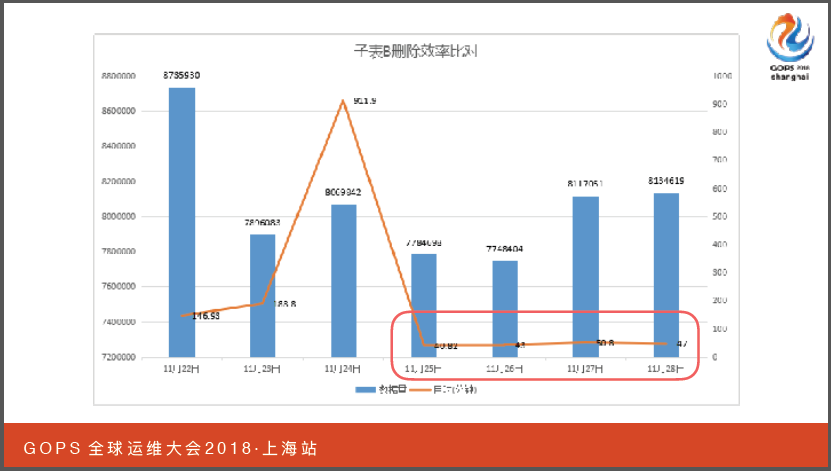
从数据比对来看,子表B在优化之前都需要两个小时到三个小时的时间,基本上保持五十分钟就可以完成数据的工作。
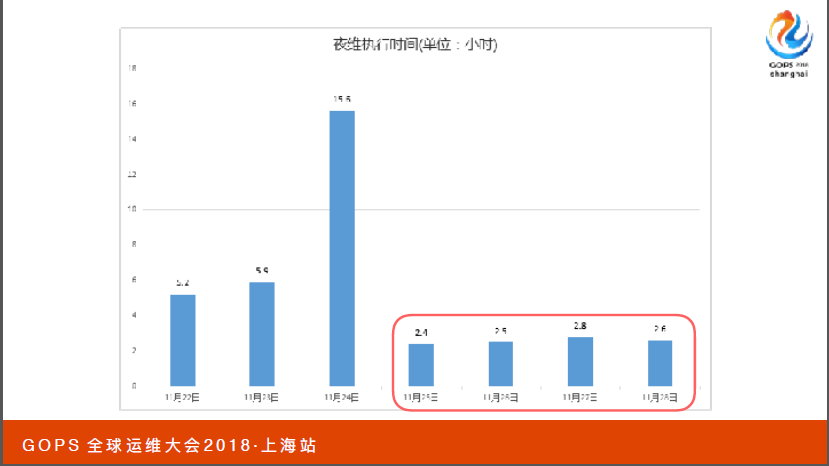
子表B是属于优化主要矛盾,解决主要矛盾之后它相应夜维执行时间也有下降,原先需要四个小时以上的时间完成清理,保持两个半小时时间就可以完成所有数据清理工作。
之前我们对后期删除的过程做了一个严禁的说明,
四、总结回顾

最后我们简单总结回顾一下之前的问题。首先我们投产初期只要SQL语句符合需求在执行时间上就可以。之后暴露扫描的隐患就会脱离出来,我们通过串行改并行方式希望缓解,这时候我们增加了pkid索引的方式。
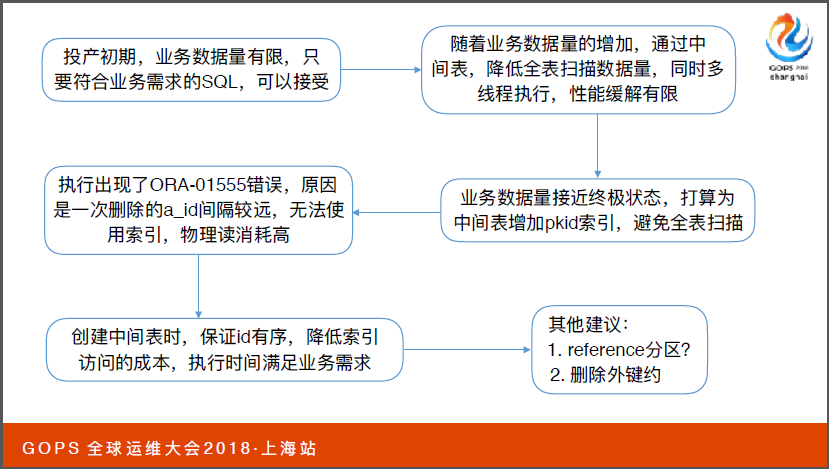
实际过程当中pkid它的数据分布变成了乱序的方式,进而导致使用索引扫描的话成本值非常高,导致了它直接使用全表扫描出现了155的报错。明确了原因之后解决方案也很简单。我们通过(英文)排序来降低索引访问的成本。
其实对于优化的方式来说方式有很多种。是否可以删除外界因素,对一些表增加冗余阶段。其实有时候做优化的时候,最容易理解、最熟悉、最容易操作了,毕竟技术还是为业务服务的,通过这些案例我们也做了一些思考。

第一点有人说好的架构不是设计出来的,而是演进来的,对于SQL写法来说也是如此,对不同的阶段有不同的优化方案可以实施可以做。
第二点,在优化过程中,首先抓住主要矛盾,出现性能问题的时候它会连续暴露一系列的问题,我们不能眉毛胡子一把抓,我们要明确其中主要的矛盾作为首要的目标去解决。
第三个就是无论对于开发人员还是架构师来说,我们不能把数据库当做一个黑盒,我们理解越全面、越深入越可以理解和发现问题。最后一个就是对于数据库的设计和SQL设计的话,它执行时间一定会随着数据量增加而增长。大会的主题就是自动化运维。在业界有了一些审查工具出现了,它可以帮助开发人员提供一些解决方案。

这一块我们团队也在做这方面的探索,包括现在正在自研和测试的数据库审核分析平台,我们起的代号叫Sherlock,帮助我们的开发人员以及DBA开发数据库,通过DevOps的理念辅助整个数据库包括SQL开发的工作。以上就是我今天的分享。
