@gaoxiaoyunwei2017
2019-04-29T07:44:01.000000Z
字数 4228
阅读 1657
云计算时代携程的网络架构变迁
白凡
分享:赵亚楠
编辑:白凡
我来自携程,今天给大家分享的题目是云计算时代携程网络架构的变迁。先做一下自我介绍,我是2016年加入携程的预算团队,现在负责携程云平台的网络与充足开发系统,工作内容是网络与分布式存储开发。网络不包括数据中心网络,数据中心网络有另外的同事。

第一,介绍一下携程云平台;
第二,介绍一下网络的架构;

0. About Ctrip Cloud
介绍一下携程的云平台,携程的云平台开始于2013年。这几年经过发展,我们已经把Cloud的所有服务打造成为携程数字操作系统,是Ctrip系统。在公有云上介入了亚马逊、腾讯等等厂商给业务系统提供虚拟机和容器。

这是我们网络架构演进的一个大概时间线。首先2013年开始做,到了2016年开发了L2的网络,集成到了统一的SDN方案,使用单套的方案同时管理我们的虚拟机、应用物理机和容器。在公有云上也有相应的方案,与私有云打通。
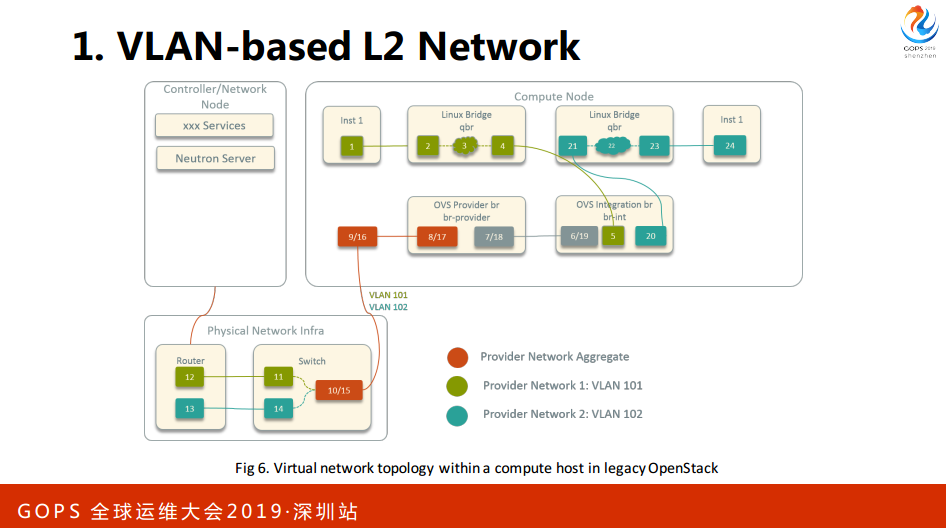
1. VLAN-based L2 Network
这个时代对于网络提出的需求,性能不能太差,比如说涉及到延时的指标。二是隔离技术。三是实际的IP是可路由的,我的IP在进出的时候都不能做封。四是安全性的要求并不是太高,假如说我们可以牺牲安全性带来比较大的安全提升,这是比较有用的。

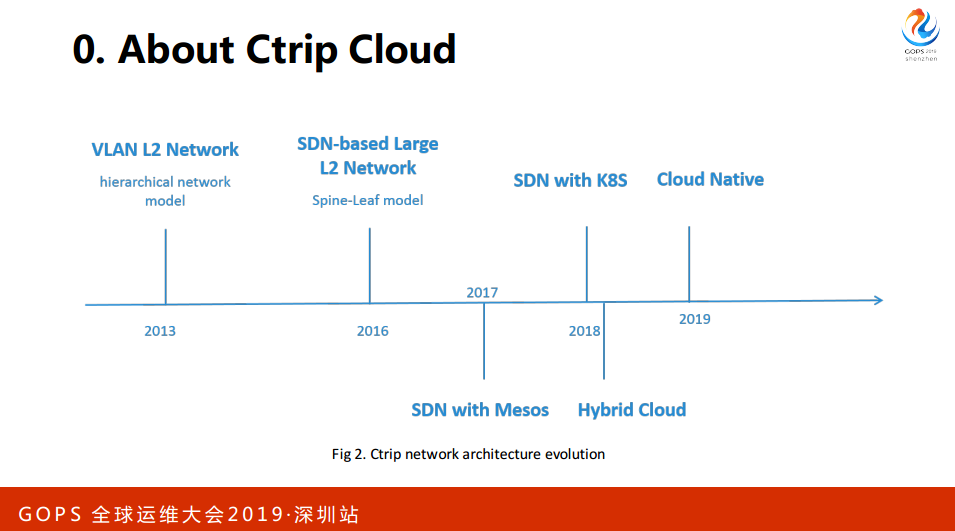
看右边这个图,在虚拟机内部是2层机的转换,这种方案的特点,所有的网关是配合硬件设备,所以需要有一个硬件的配合,并不是全软件的方案。
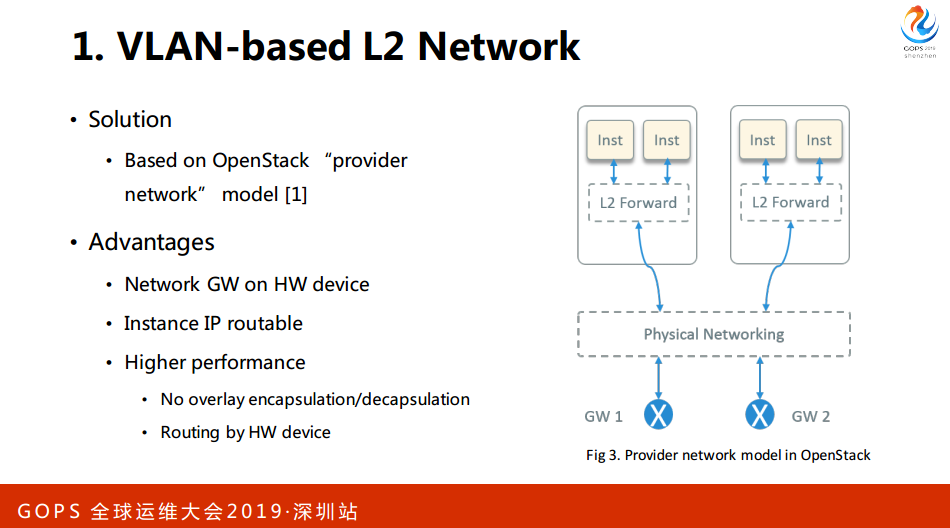
其他一些方面,我们二层的隔离就是OVS。我们网官在硬件设备上,我们也不用DSCD,最后我们去掉了Group。
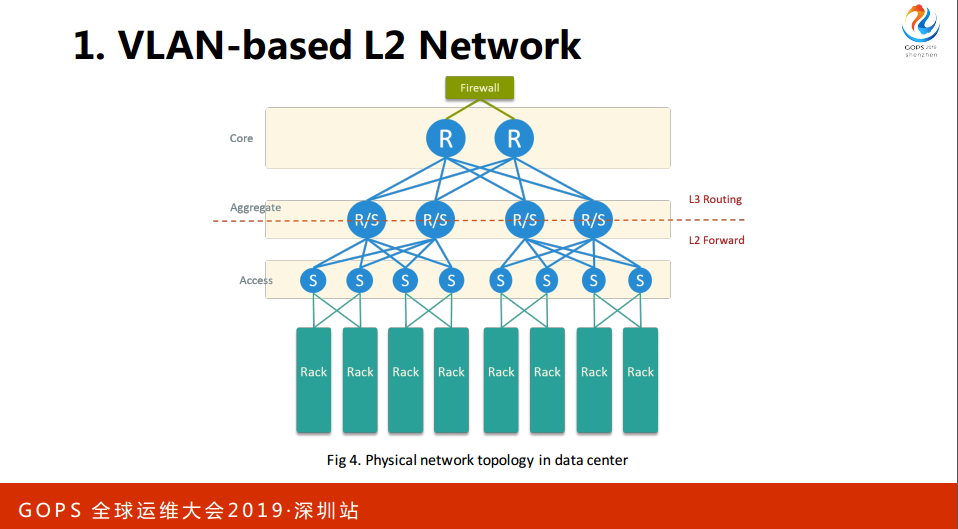
这是数据中心的硬件网络,这下面是一台机架,上面是典型的接入汇入核心的架构,每个服务器有两个网卡,直连两个交换机,高可用。汇聚和接入走的二级交换,核心之间走的三层的路由,所以网关在核心上。刚才是宿主机外部的,现在是宿主机内部。
最后总结一下在低端网的提高,我们简化了Opnestack的架构,经过架构的简化之后,对于刚开始做私有云的团队来说成本是比较高的。
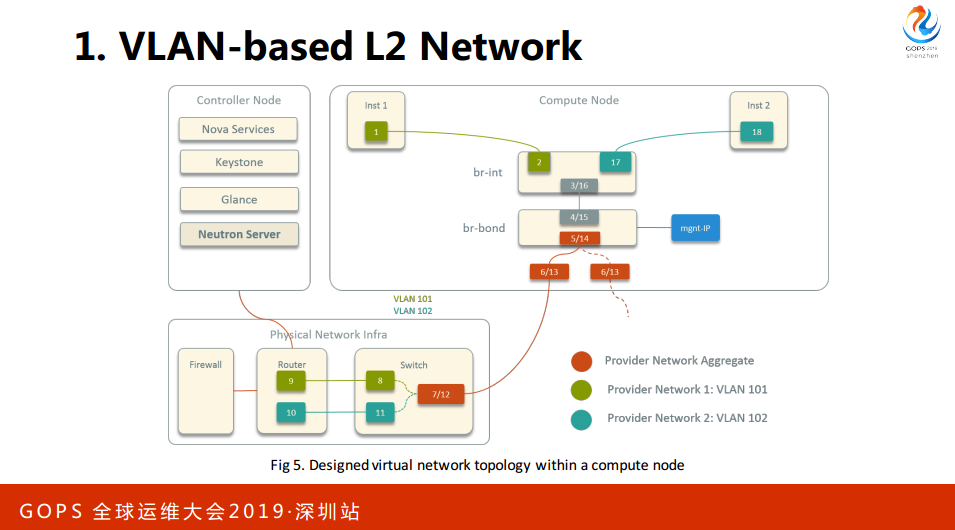
我们从原生的24条简化到18条,延时会更低。
最后是实际的IP是可路由,对于外围的跟踪和监控是很方便。不足是需要安全组,安全组就是Opnestack的主机放火墙,它在安全性上比较强一些。我们通过防火墙来设置规则,部分弥补了这个问题。部分实现网络化,涉及到核心交换机,虽然说这个操作频率是比较低的,但是风险很高,因为新出了故障会影响到整个网络。

2. SDN-based Large L2 Network
2016年左右第一代网络遇到一些问题,做数据中心的同学比我们更清楚,三层网络的可拓展性不太好,所有网关都在硬件核心设备,核心会成为潜在的性能瓶颈,核心故障会影响整个网络。VLAN有一些新的限制,网络到了之后会放洪,会有4096的限制,在此期间携程收购了一些公司,公司网络与携程有打通的需求,公司网络与携程有一个不一样的对待。最后希望网络资源交付更加自动化。

根据以上的这些需求,我们联合数据中心网络团队一起设计了一套新的硬件+软件的大A层方案。我们的硬件客户从原来的三层模型演进到了两层模型,这种模型最大的特点,full-mesh是两层连接的,第一个点leaf节点。
第二个点,易于扩展,任何一层有新的瓶颈,有带宽瓶颈需要加一个新的设备去互联。最后所有的设备都是活跃的,任何一个设备挂掉的影响会小很多。
在数据平面是VxLAN,控制层面是MP-8GP-EVPN,如果大家有兴趣可以参考这个,这都是细节的东西。这个架构是分布式的网关,所有的连接节点都是一个网关。最后这套方案在物理上是多租户的。
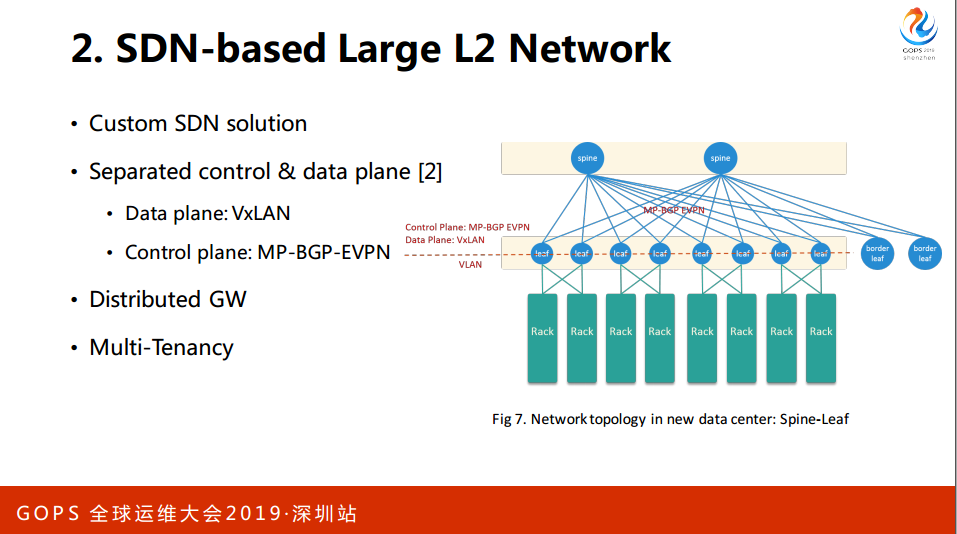
在软件开发上,我们首先开发了自己的SDN控制器,这是集中式的控制器,所有的控制节点。流程Server这里除了开发插件以外还有一个流程机,这是我们真实的一个状态的监控,能够在状态下开户。

如果哪个平面出了问题容易在第一时间定位,加一些CPI来定位。这里有下面几个组件,创建一个虚拟机的入口,一个创建实力的请求会调度到一个结算节点,这个节点准确的服务会申请IP。
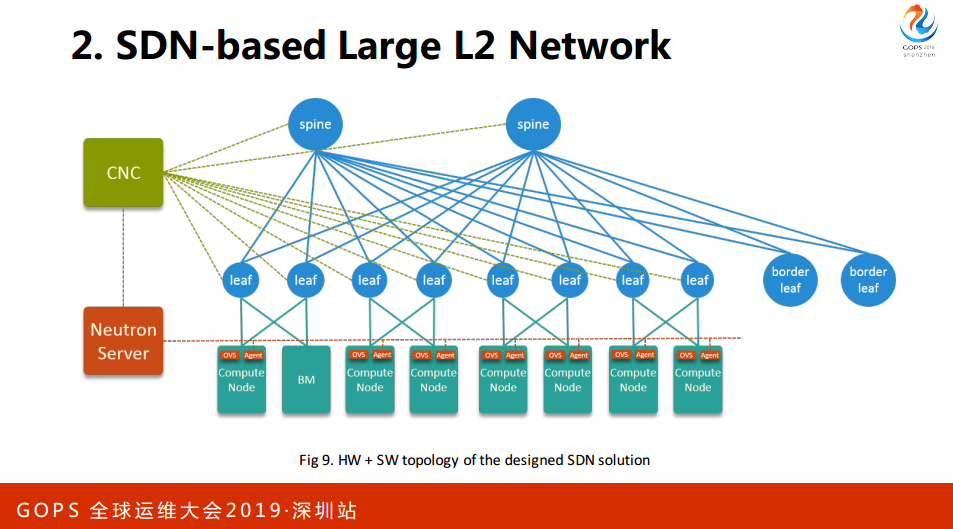
这个请求完成之后会通过一定的方法达到CNC的Plan in,接下来IT的资源回会给电脑,电脑拿到数据以后会创建虚拟网卡。这个网卡会用到OAS。回到刚才那个图,现在有一个实例调度到刚才的,形成一个虚拟网卡,Agent监测到虚拟网卡,会经过物理网卡,道理历史节点,这个路就通了。
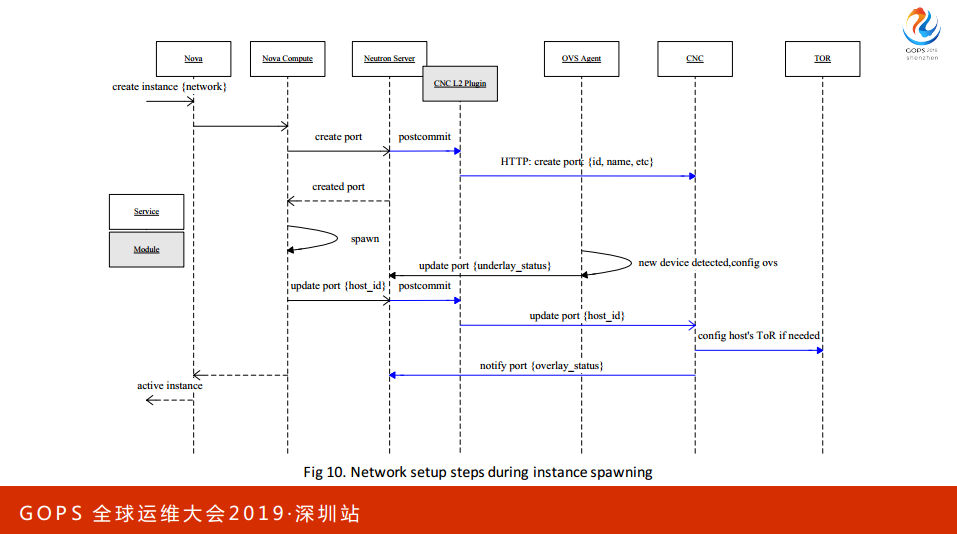
总结一下SDN,硬件是三层网络渐进到2G模型,物理上的转发路径比原来更短,分布式网关到集成式网关的瓶颈。连接会使故障范围更小,整个方案易于水平扩展,软件上开发了控制器,能够动态地向物理设备去下达配置,整套方案是虚拟机和物理机的交互。这一套展示虚拟机。

3. K8S & Hybrid Network
最后这套方案是支持一个真正独租户的稳定机,到了2017年的时候,在私有云与公有云上落地一个平台,迁移到容器,容器平台有不同与Openstack的特点,实力规模非常多。单个集群1个到1万个很是很长的,有创建和的过程。
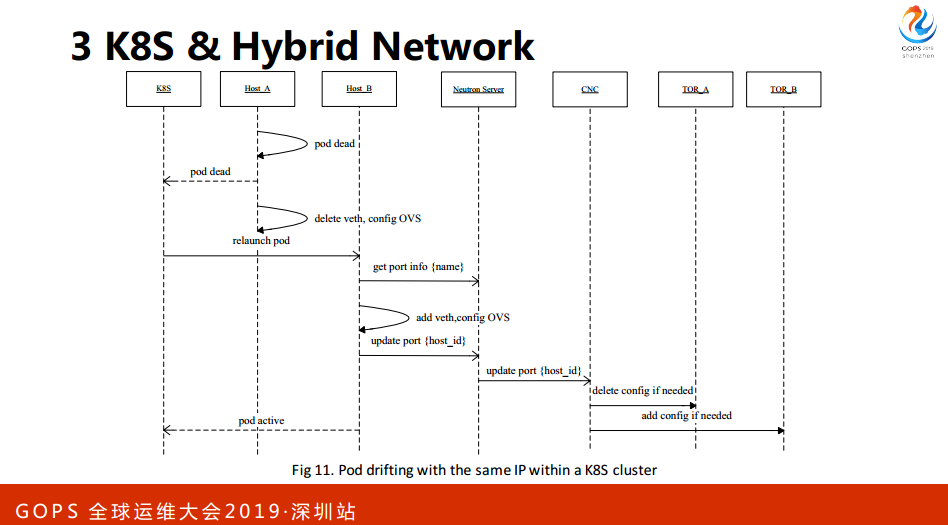
最后就是容器平台基本上都是假设挂掉是一个正常发生的情况,所以会考虑自动处理的错误,比如说挂掉之后重新拉起来或者换一个速率重新拉起来。如果我们要快速落地一个平台,我们必须要保证与很多外围系统的兼容。这边提出一个新问题,用户要求IP随着容器漂移,IP要漂过去。如果大家做容器的话,会比较清楚K8S里面是做不了这个的。
因为在虚拟机时代,虚拟机迁移的时候,IP跟着迁,所以有大量不受我们控制的外围系统会假设IP是生命周期内不可变的一个资源。如果我们突然把IP可变这件事情放在方案里面去就会破坏原有应用系统,容器落下来的时间会很长,因此我们会满足这个需求。如果我们开发一个Agent去创建网络的速度比较快。

最后定下来的方案,在私有云上对原来的SDN方案进行拓展,统一纳入我们的SDN的平台,最先是赋用原有的基础设施,比如说Agent、CNC、OVS都不变,我们开发一个Plugin把K8S的网络给打通。

性能优化,批量的优化和关键路径的优化。我们的Opnestack是从2013年做的,中间升级过一次,后面就不涉及到社区升级了,因此有一些新的特性要扩展回来。比如说原来OVS、Agent重启会清空,重新加上去会造成一段时间断网,新的版本就引入了一个OVS的技术,在整个过程保证实力的网络不会断。

K8S做的事情比较常规,配置IP、etc。最后是我们对于原有基础设施进行升级,比如说OVS的版本有点老,在这几年使用过程中遇到很大的性能瓶颈,后面查到的时候看到最新的LTS已经把这些问题解决了,我们升级到了最新的版本。
这个实例启动以后网络是怎么通的,与刚才很类似,换成K8S。
总结一下方案:保持拥有基础设施不变的,比较快把容器平台提升到网络当中,同时保持虚拟机、应用物理机和容器的网络。目前的部署规模,在四个可用区实现部署,现在可用区比较小,大概是500台物理节点。这些节点有虚拟机的宿主机,还有容器的宿主机,每个Host上面会有超过500个实例,部署的密度还比较高,部署到一定密度会发现K8S。最大的一个可用机超过2万个实例,大部分都是容器的。
刚才是私有云网络架构的演进,这张图是我们希望达到的架构,Underlay和Overlay。
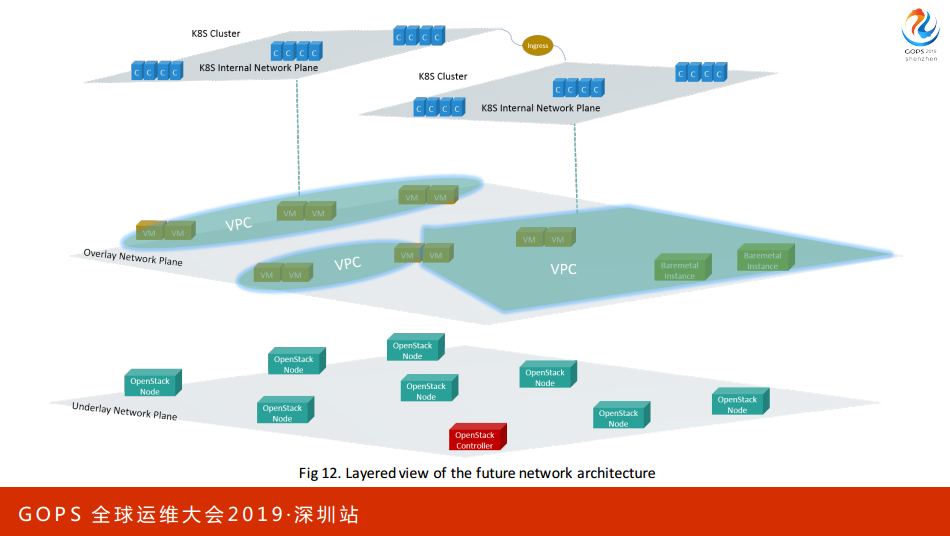
到2018年之后,携程开始推进国际化,对于我们来说需要在海外有交付资源的能力,自建数据中心肯定是来不及的,因为它的设计和周期很长,我们在海外买一些公有云的平台,然后结合打造成一个混合云的平台。
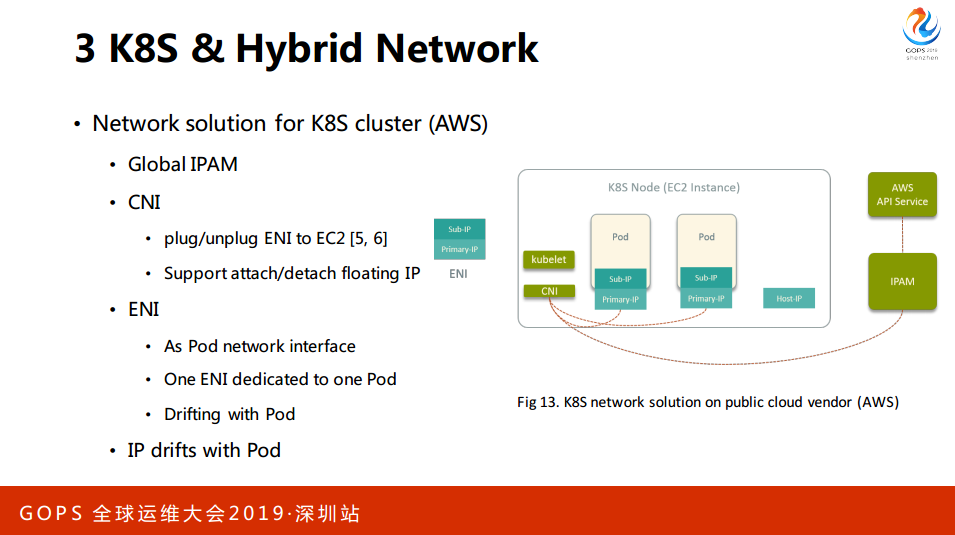
我们首先会在公有运上面购买一些虚拟机或者应用物理机,对于搭建或者维护的K8S集群,通过我们的API统一封装不同厂商的差距,给我们的用户提供一致的API。

涉及到不同厂商上面的一些网络方案,我这里以亚马逊上的K8S网络方案为例,介绍一下网络方案的实现。首先在AWS取一些实例作为K8S的计算节点,开发一个自己的CNI的插件,动态向一些地区插拔。弹性网卡插拔,ENI会给POD来做网卡来使用,在这个VNC有一个管理网络资源的服务,它会跟亚马逊的API交互创造删除或者管理这些资源。CNI插件是支持像实例去Floating IP,IP也是随着实例漂移的。
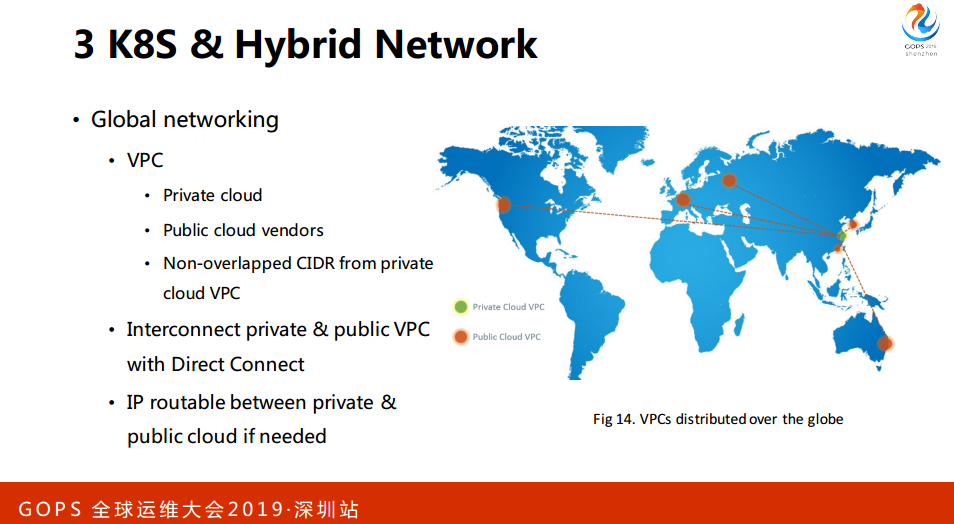
首先,我们在上海与南通会有自己私有云的VPC,在首尔、莫斯科、法兰克福、香港、墨尔本会有公有云,通过专线的方式去打通,目前VPC的网段都是经过设计不会重合的,如果有需要可以直接路由。以上就是我们今天在私有云和公有云上面的网络架构。
4. Cloud Native Solutions
接下来在Cloud Native的新挑战,不管是公有云或者私有云,我们的IP业务都是全局。现在的IP是随着容器在整个网络漂的,假如说整个网络有问题,故障范围是整张网络,而不是一台或者几台的宿主机,我们容器的部署密度会比较高,随着网络的扩大,有可能会出发BUG网络里面的瓶颈。

我们有4-7层的主机防火墙的需求。针对于这些问题,我们调研了其他的方案,如果做容器可能对于Calico比较熟悉,我介绍一下另外一个,它使用的内核是4.8以上,核心是叫伯克利eBPF这样的东西,这是一个虚拟机,可以动态向它注入一些自解码,在内核实现一些高级特性,比如说系统调用的跟踪,或者吸引一些字段,或者是路由。
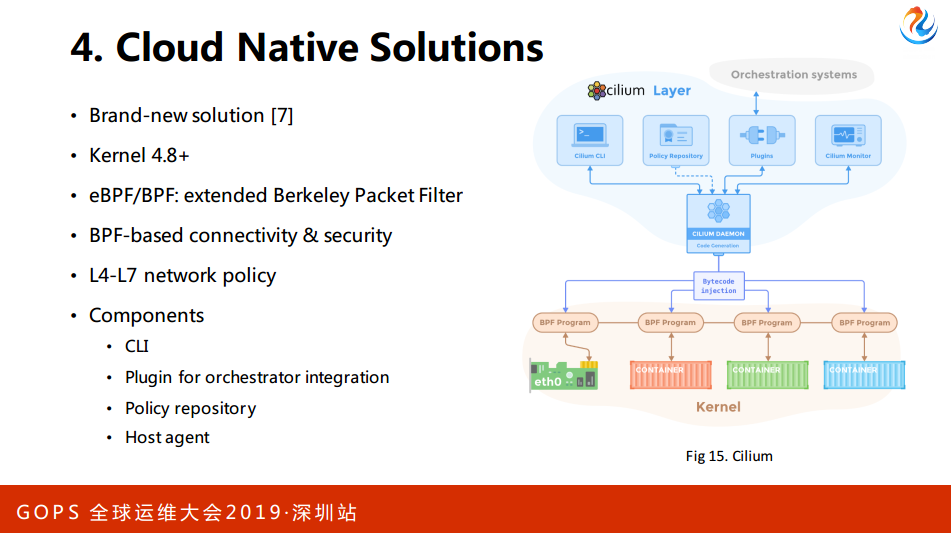
它有下面几个组件:CLI、Plugin、Pyhton等等。任何一个网络方案其实往大的方向来讲,一是解决宿主机内部的网络,二是跨宿主机内部,在宿主机内部管CIDR,在网关去创建,每个容器创建会在CIDR创建一个IP,配置到一个文件到到宿主机内部的一个网络,中间没有任何的OVS这样的调节设备,从传统的观点来看很奇怪,不知道包是怎么过去的。
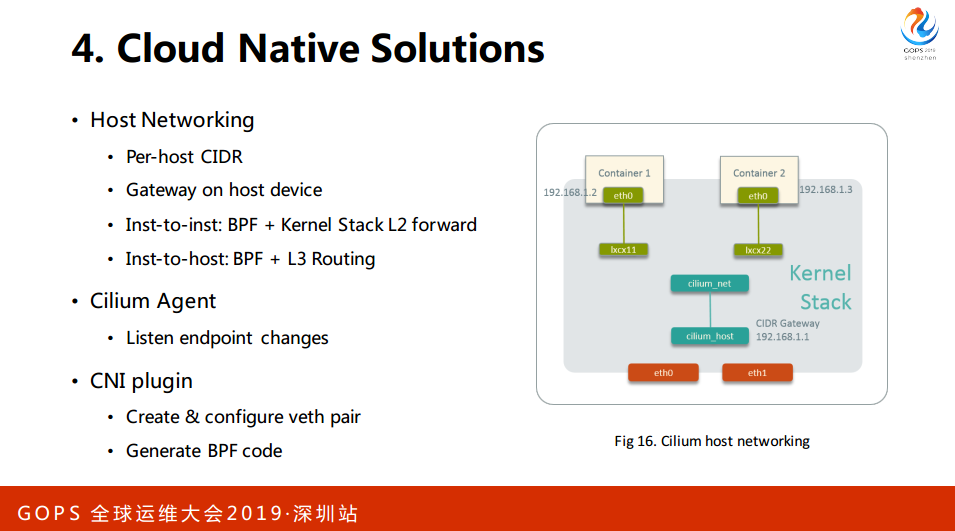
比如说两个实例之间,可能1与2之间,中间会有BPI的规则拦截这个包,他知道你会去,他会转到这里来然后再上去。对于容器与宿主机之间是怎么BPF,连接一个路段再加一个三层的路由。

跨宿主机的话有两种比较常规的方案:
第一,在宿主机内部做常规的软件。做封装与解封装,这样性能比较差;
第二,BGP,直接通过BGP通告出去,私有云起一个Agent,与宿主机网络一起做;
第三,在公有云提供一些BPI,这个还没有试过,只是看到亚马逊有这样的API。

最后总结一下这样的方案,比较新,它是K8S-Native L4-L7的案例。

最后建议大家,如果做开发还是要去试一下这个方案,非常惊喜的一个东西。其中有很多细节,因为时间没有展开,没有大家有兴趣可以看一下后面的方法连接。
