@gaoxiaoyunwei2017
2017-12-14T06:21:58.000000Z
字数 3052
阅读 1682
基于StackStorm的携程运维自动化平台 --- 胡俊雅·携程
北哥
讲师简介
胡俊雅
给大家分享的主题是基于StackStorm的携程运维自动化平台。
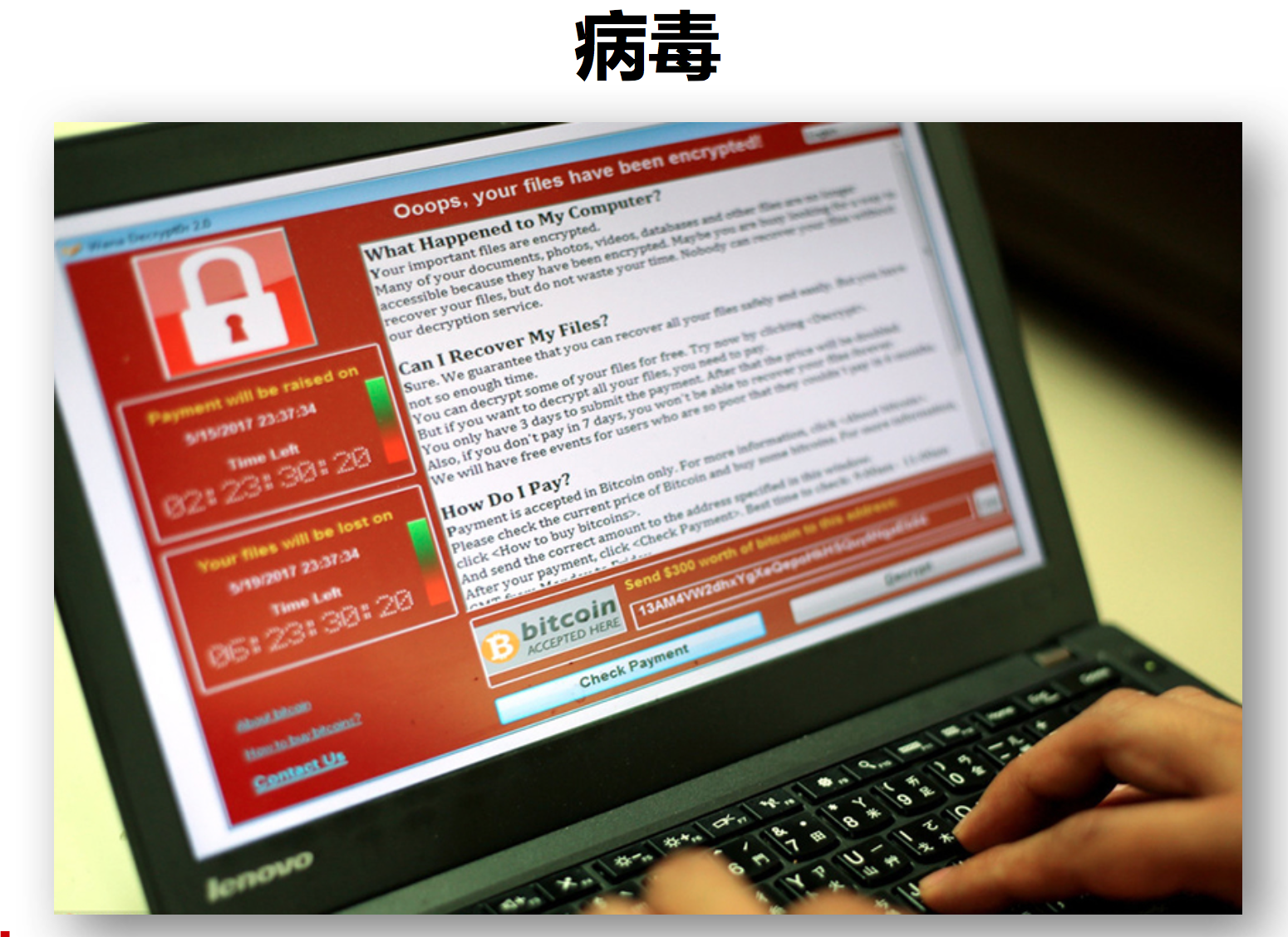
今年5月份,病毒爆发席卷全球,影响了政府、学校、医疗机构和各大企业,给世界造成了巨大的影响。如果有眼光的人,遇到这个事情考虑购买比特币。作为运维工程师来说,怎么跟病毒进行战斗,防止影响自己公司的业务系统呢?相信很多在坐的同行,都参与了预防病毒的战斗中。有做了很多措施,比如关闭端口,防止病毒的传播,或者建立域名防止病毒的运行。当然,这些只是一个方案,根本性基础病毒,还是需要进行补丁更新。

如果只有几台、几十台服务器,补丁更新很简单,点几下安装就可以搞定,当你有成千上万台服务器的时候靠人工是不可能的,如果一下子发一条命令下去到所有服务器也不合适,造成巨大的影响。

要给上万台服务器打补丁具体怎么操作呢?
我们先看一下,一台服务器上怎么操作打补丁。
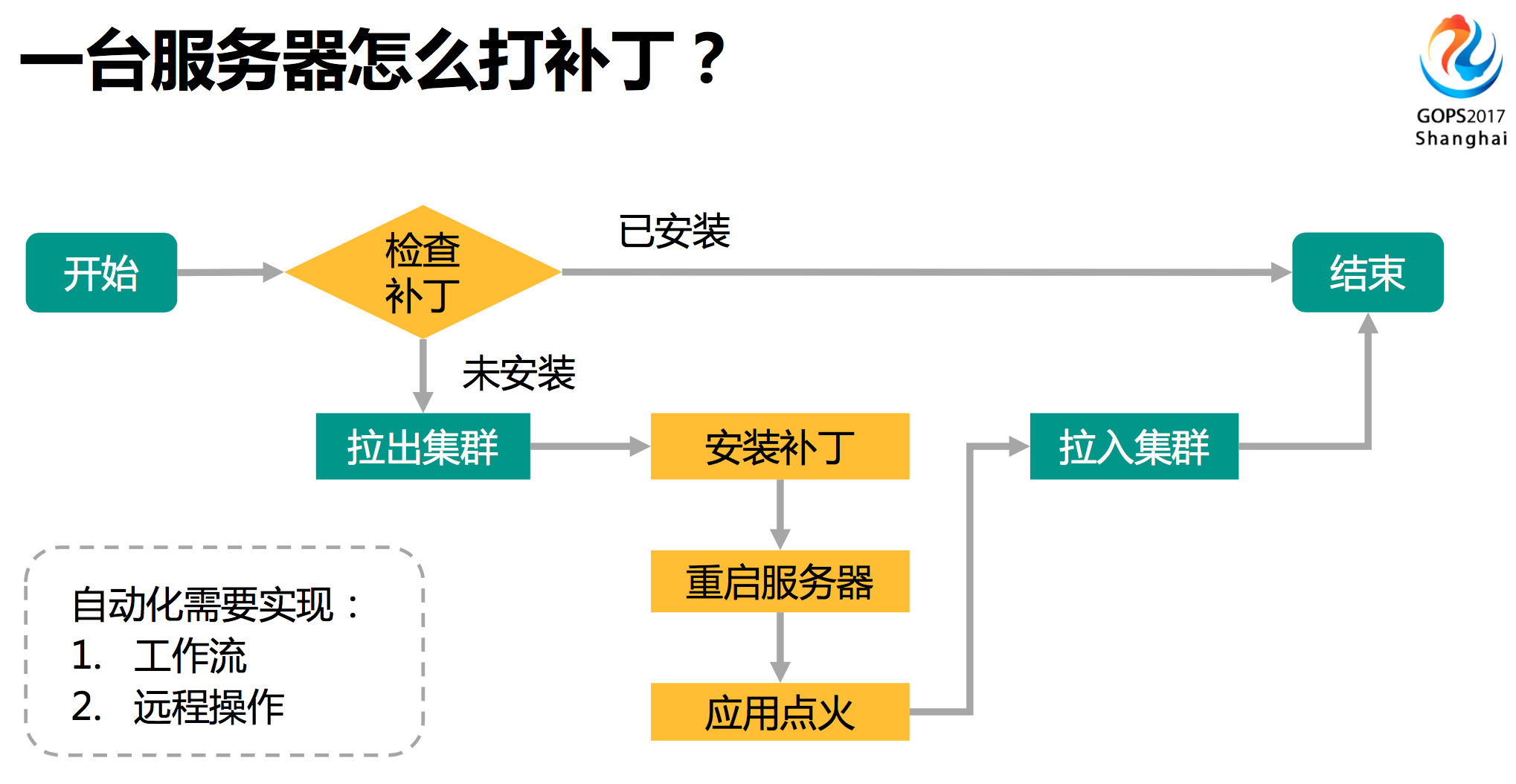
上图是个比较简单的操作流程。判断这个服务器有没有安装,已经安装就结束,如果没有安装要脱离生产,这时候把服务器拉出集群,再进行一些操作,比如安装补丁,重启服务器让补丁生效。我们有些应用有缓存,让应用恢复正常的状态后再拉入集群。这其中还有一些复杂的问题,比如拉出集群以后,剩下的服务器可能扛不住,以及一些可用性的问题等等。
使用一台服务器打补丁要实现自动化可以从两个方面入手:
- 一个是上面的工作流运转
- 另一方面远程操作,不可能登陆服务器去操作,要有一套远程的机制。
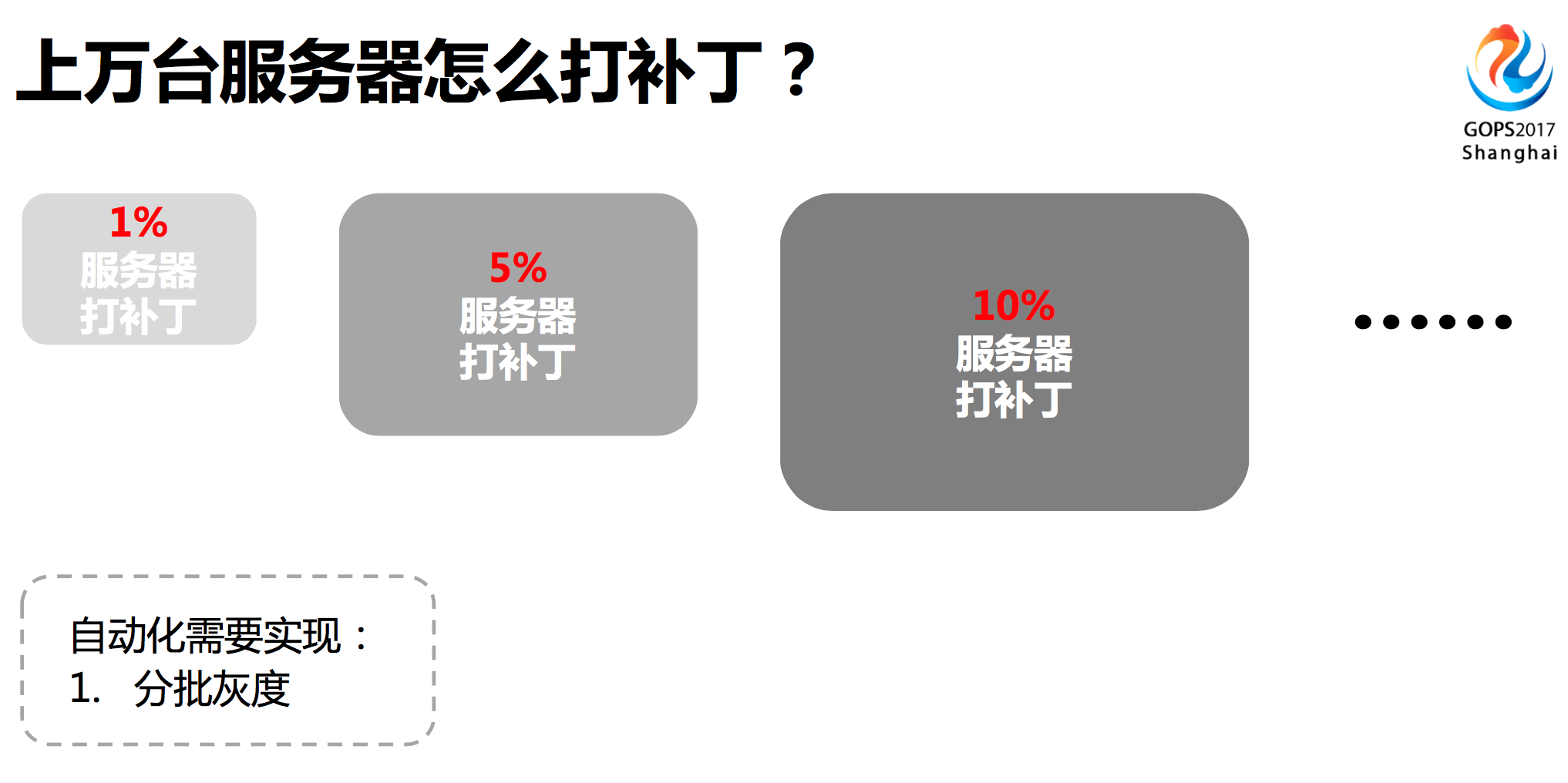
从一台扩展到成千上万台服务器的时候,就需要着重考虑灰度,我们知道一下子把命令下发给所有的服务器,可能会造成业务中断。无论对你开发的工具多么的自信,在生产大批量服务器下还是要做到谨慎再谨慎,灰度可以达到谨慎很好的方法。所以,对上万台服务器操作自动化的时候,要注重分批灰度。

鉴于打补丁的需求,我们需要这样一套自动化运维平台,主要体现在三个方面:
- 一个是利用远程控制
- 第二个是操作的流程自动化
- 最后我们自己开发的内部系统JOBS进行分批灰度的处理
下面将从这三个方面介绍一套运维自动化平台的具体内容。
1. 远程控制
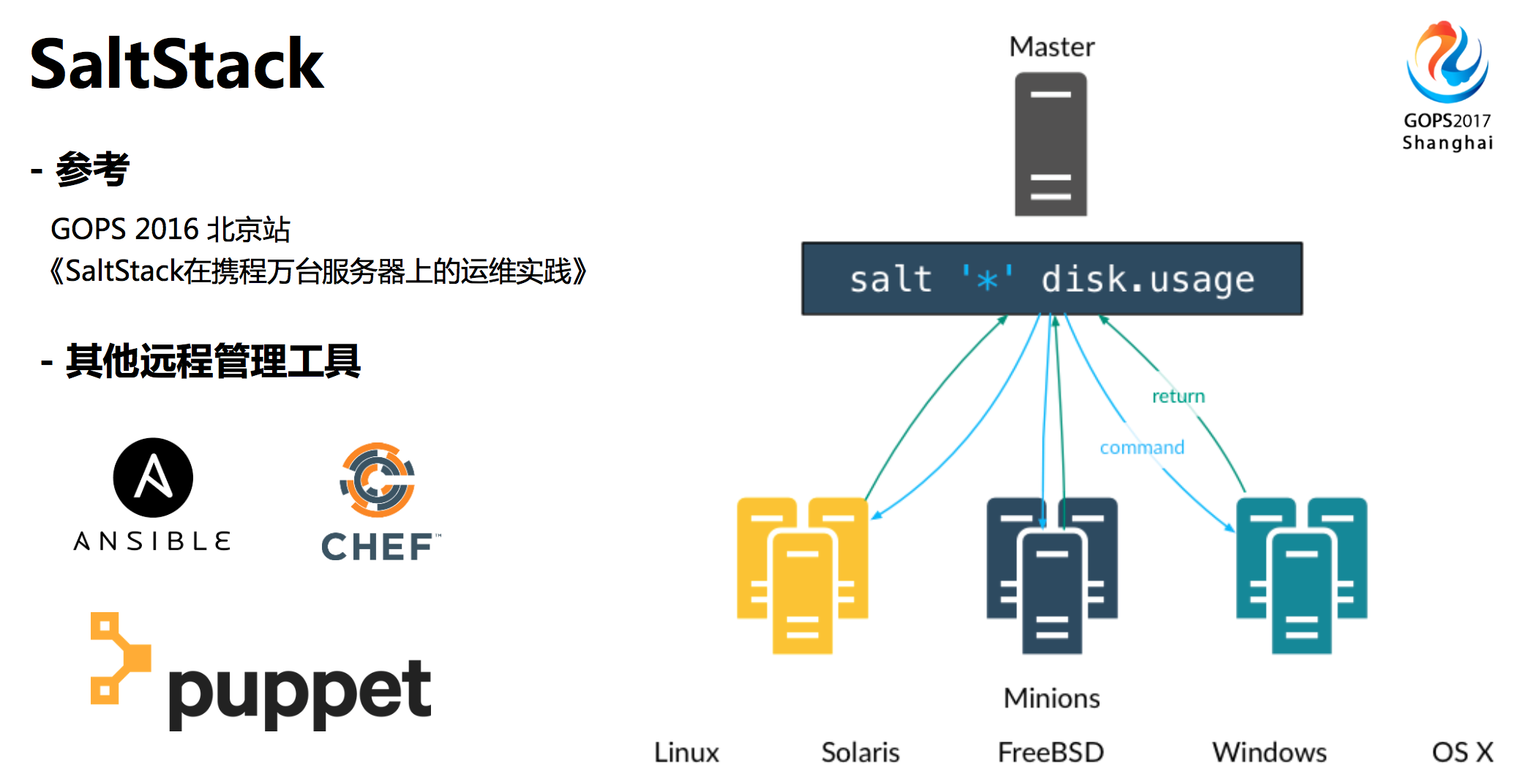
远程控制这方面我们是使用的SaltStack,关于这个内容,我去年在北京已经分享过了,大家可以进行参考,在此就不具体赘述了。
2. 操作流程
从运维的发展过程来看,传统运维相对来说主要是手工操作。一台服务器进行基础配置,按照操作文档,一步一步做下来,人每天重复做这样的事情,很累又低效还容易出错。同时还有一些脚本开发来实现重复的任务,中间有很多相同的功能,另外没有日志。生产故障其实很多时候是由于人为导致的,没有运维操作日志,就很难发现定位到谁操作了什么,不能很快发现做了啥事导致了这个故障发生。
随着时间发展,我们进入了DevOps时代。这个时代有一个很明显的特征,就是开源工具的使用特别多,同时会自己开发很多工具,给我们带来了很多的福利,让我们的运维工作量相对来说减少了很多,大大的提高运维自动化的进程。

有这么多的工具可以使用,也会存在一些问题。比如下面这些问题:
- 做一个复杂变更要操作很多工具
- 不同脚本或工具的代码里,相同操作重复造轮子
- 对别人开发的脚本或工具,不清楚具体操作逻辑
- 没有统一的运维操作日志
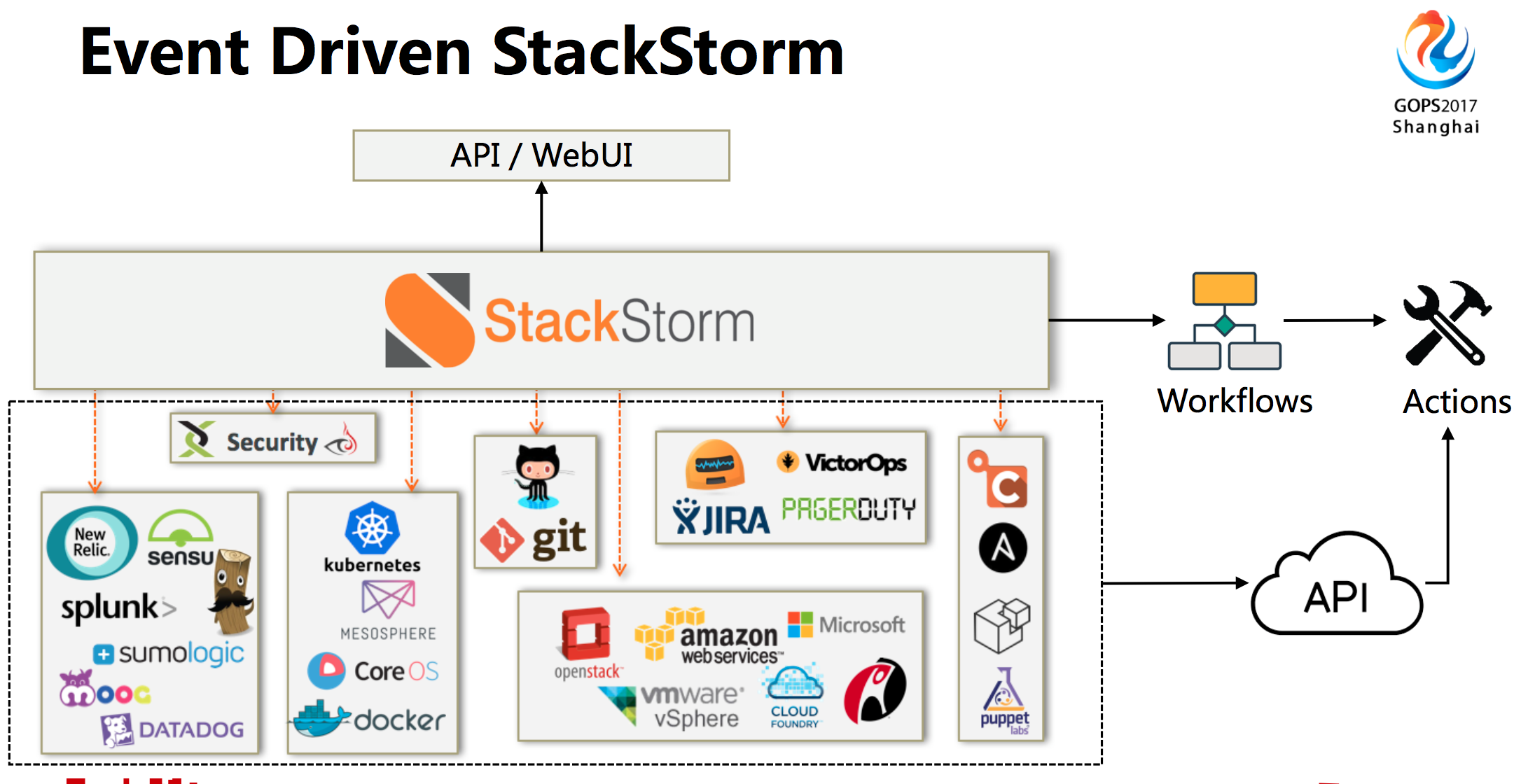
针对上面的那些问题,我们考虑使用基于事件驱动的开源的运维的平台StackStorm。你有各种各样的工具,也会提供API其实就是操作,把这些操作实现之后放在StackStorm里,这些操作有拉入拉出或者改一些配置,用比较简单的方式组合成自己的工具流。你的任何操作都有统一的日志。
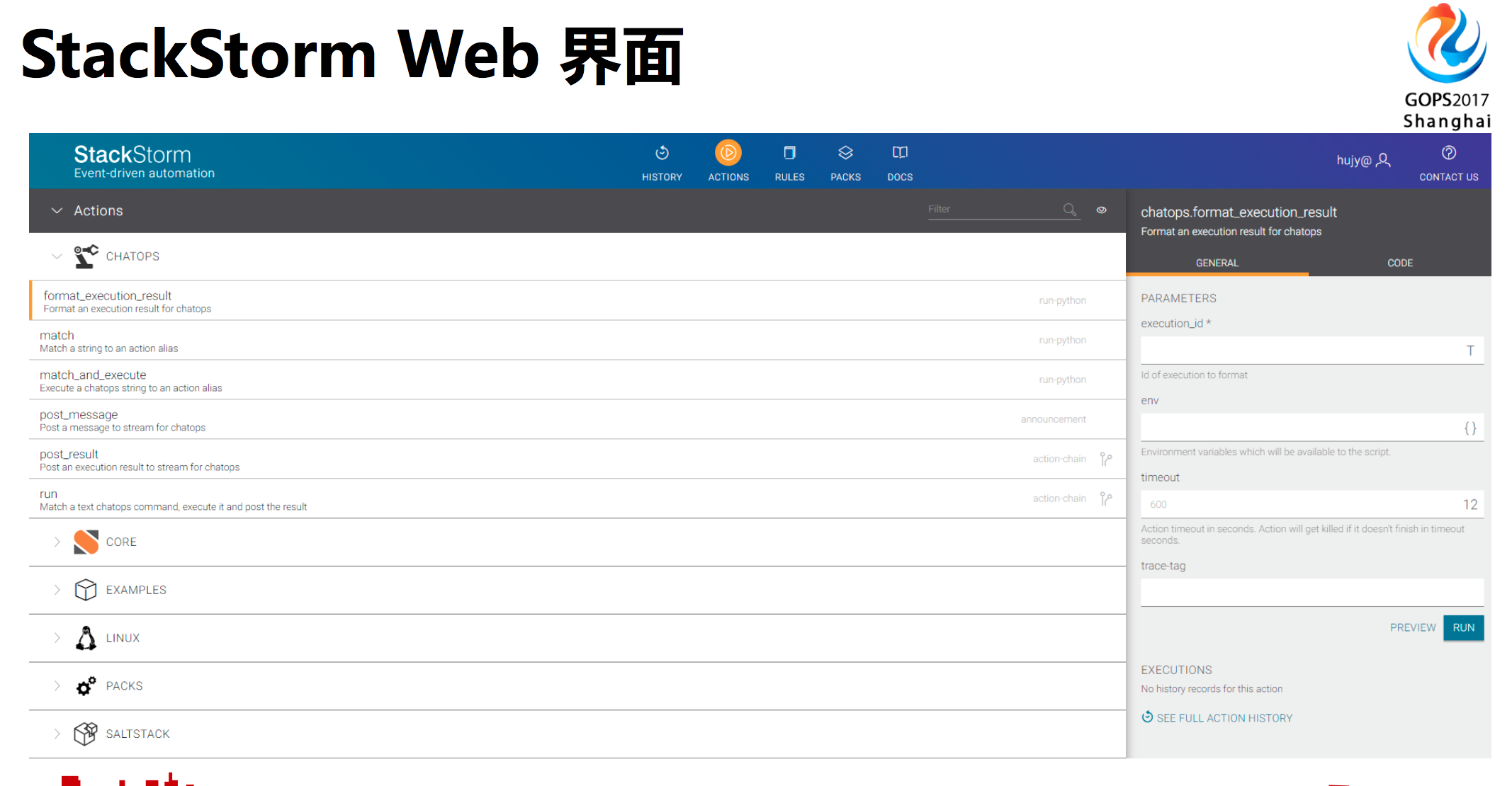
这个是StackStorm Web界面,也提供了API,就是说各种工具的操作基本上都放在这里面,在操作的时候填入参数进行运行。

使用StackStorm具体能做一些什么事情呢?

我们日常的运维变更,其实是一步一步操作的,每一步有很多共性,可以把运维操作拆细,实现原子操作。
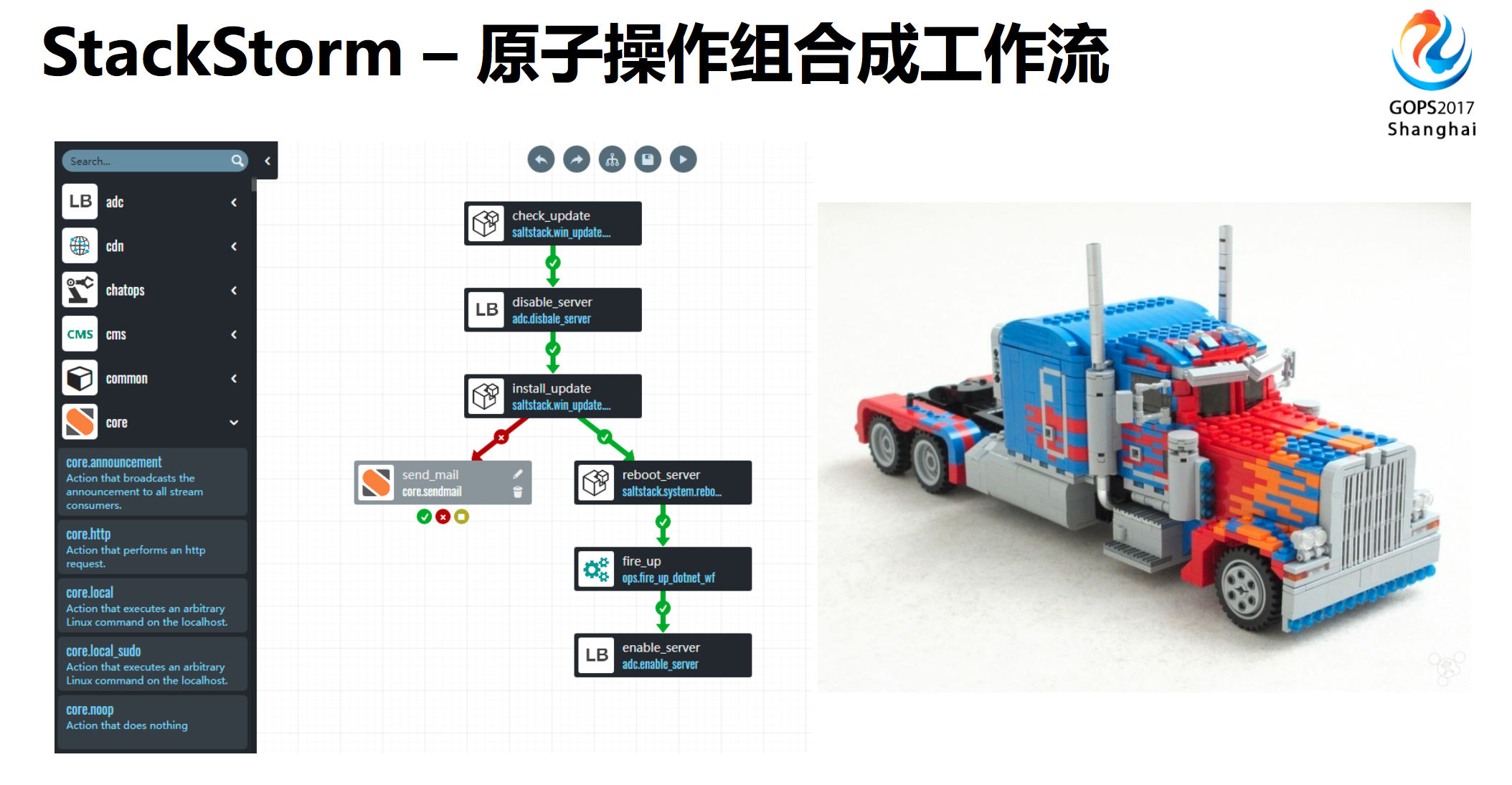
我们可以将上面拆解出来的原子操作,比如安装软件、安装补丁、重启服务等,像拼装积木那样组合成一个工作流,一块一块拼成一个模型。这样的话就提高了开发效率。这些都是都可以在StackStorm上面实现原子操作工作流的方式。
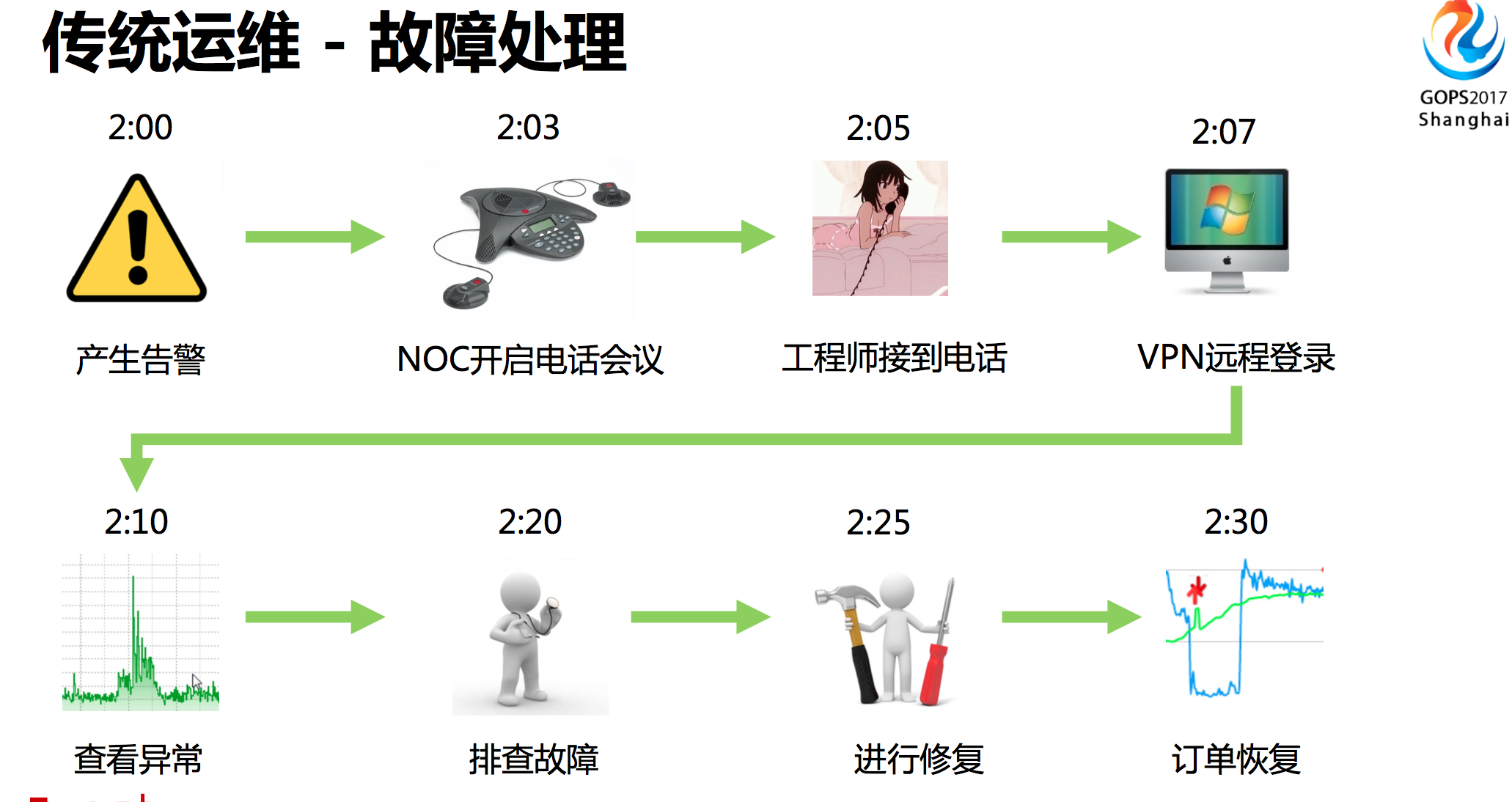
传统运维对故障处理的方式,比如说凌晨2点钟发现告警,然后给工程师打电话,工程师接到电话迷迷胡胡的起来问出现了什么问题,要陈述一边,匆匆忙忙爬起来打开电脑VPN登陆到内网查看监控指标除,利用自己的经验进行排查,找到问题所在,进行修复操作,之后才完全恢复过来。这样的过程虽说很高效,但是花费的时间很长,中间还需要有太多的人来做的事。

传统运维故障处理存在以下问题:
- 修复时间长
- 半夜处理故障,操作容易出错,而且影响第二天上班
- 随着业务增长,报警增多,无法及时处理
- 导致网站可用性下降
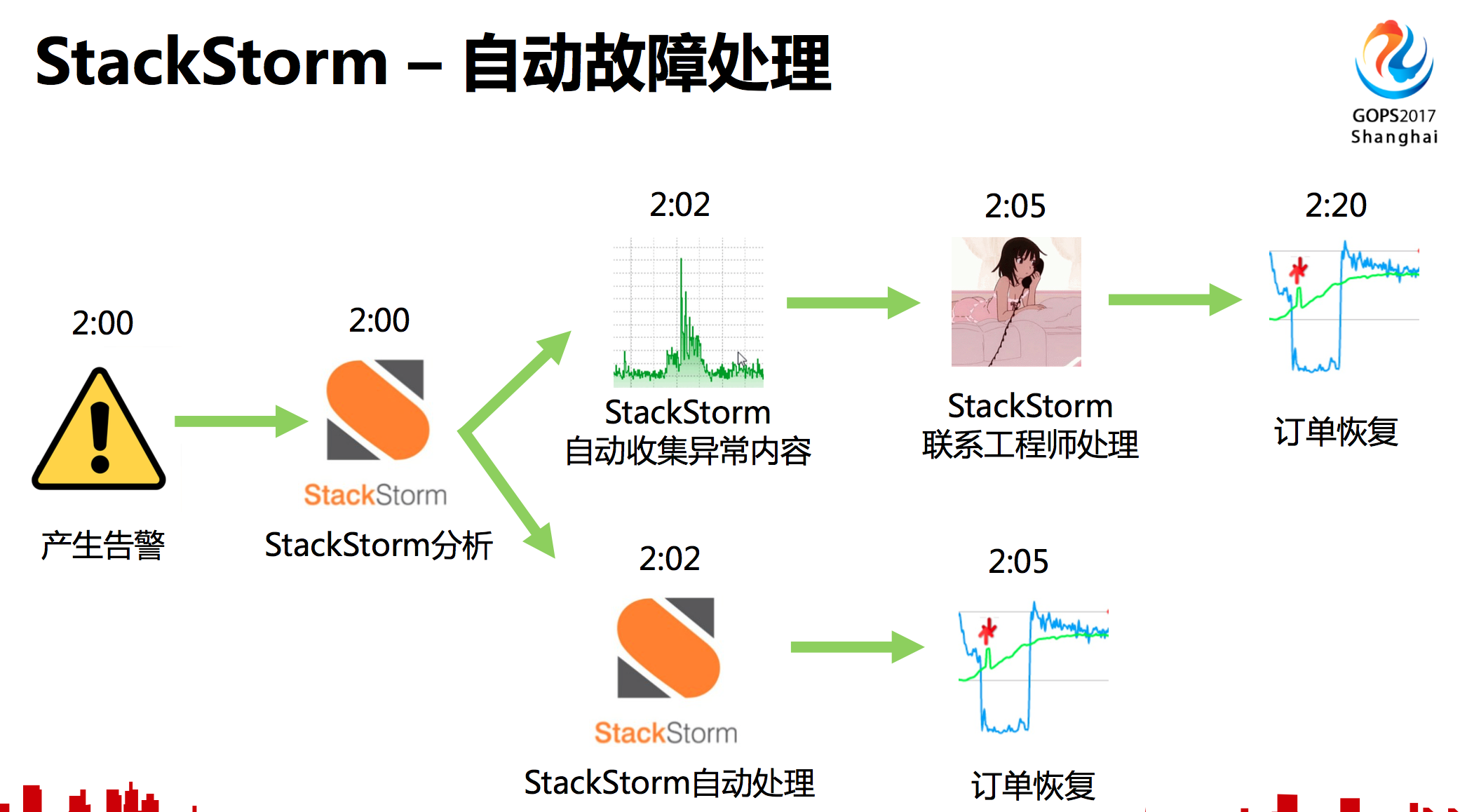
再看一下StackStorm的故障处理,StackStorm有接受机制,进行一些初步的分析,可以基于专家经验的分析,也可以基于机器学习的方式分析,分析完成之后,判断这个报警能否自己处理,如果可以就执行自动故障处理,订单恢复。如果自己没法处理,会收集一些故障的异常内容,以及一些当前我分析的结果,发给相关的工程师进一步操作处理,工程师也可以直接让StackStorm做一些操作,然后故障排除订单恢复了。这样能节省很多时间,对于一些常规的频繁发生的故障完全可以交给StackStorm自动处理掉。
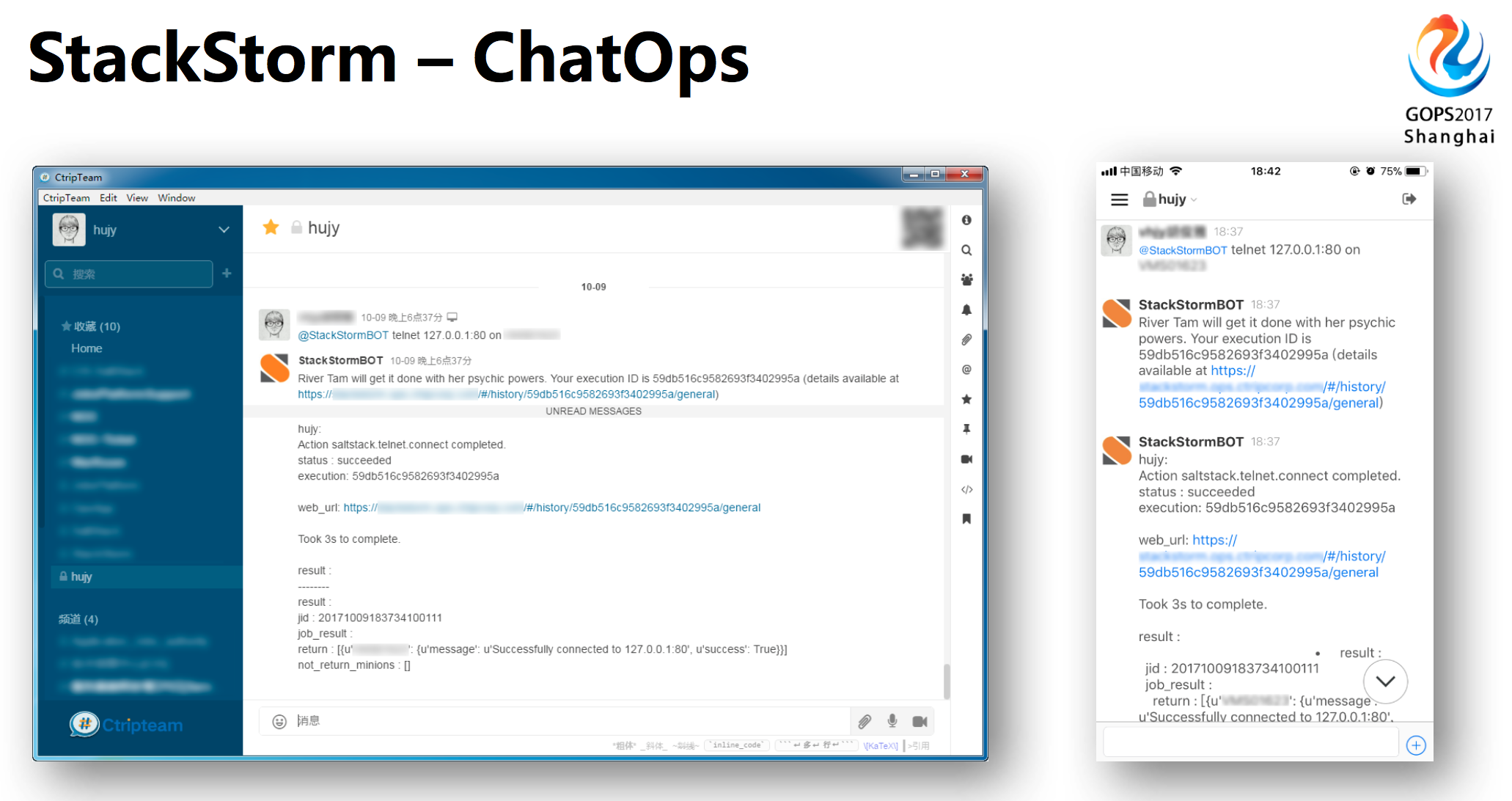
StackStorm与ChatOps组合一起,用户可以执行操作和工作流程,加快应用交付。
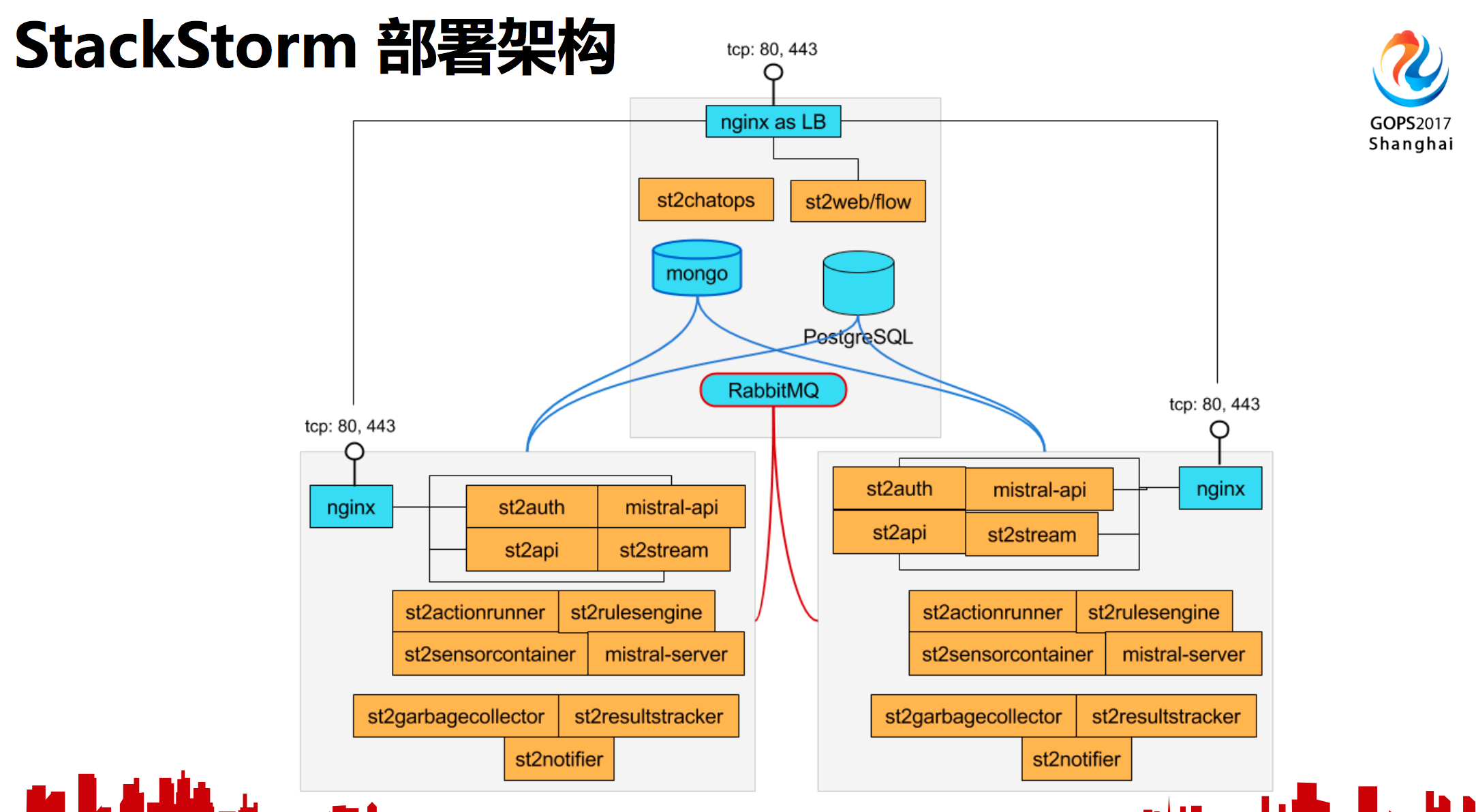
了解了StackStorm的一些具体功能之后,我们来看一下内部结构。黄色是StackStorm主要组件,规则引擎、工作流解析的服务等等。因为是事件驱动的消息队列,提供了一个个模块。
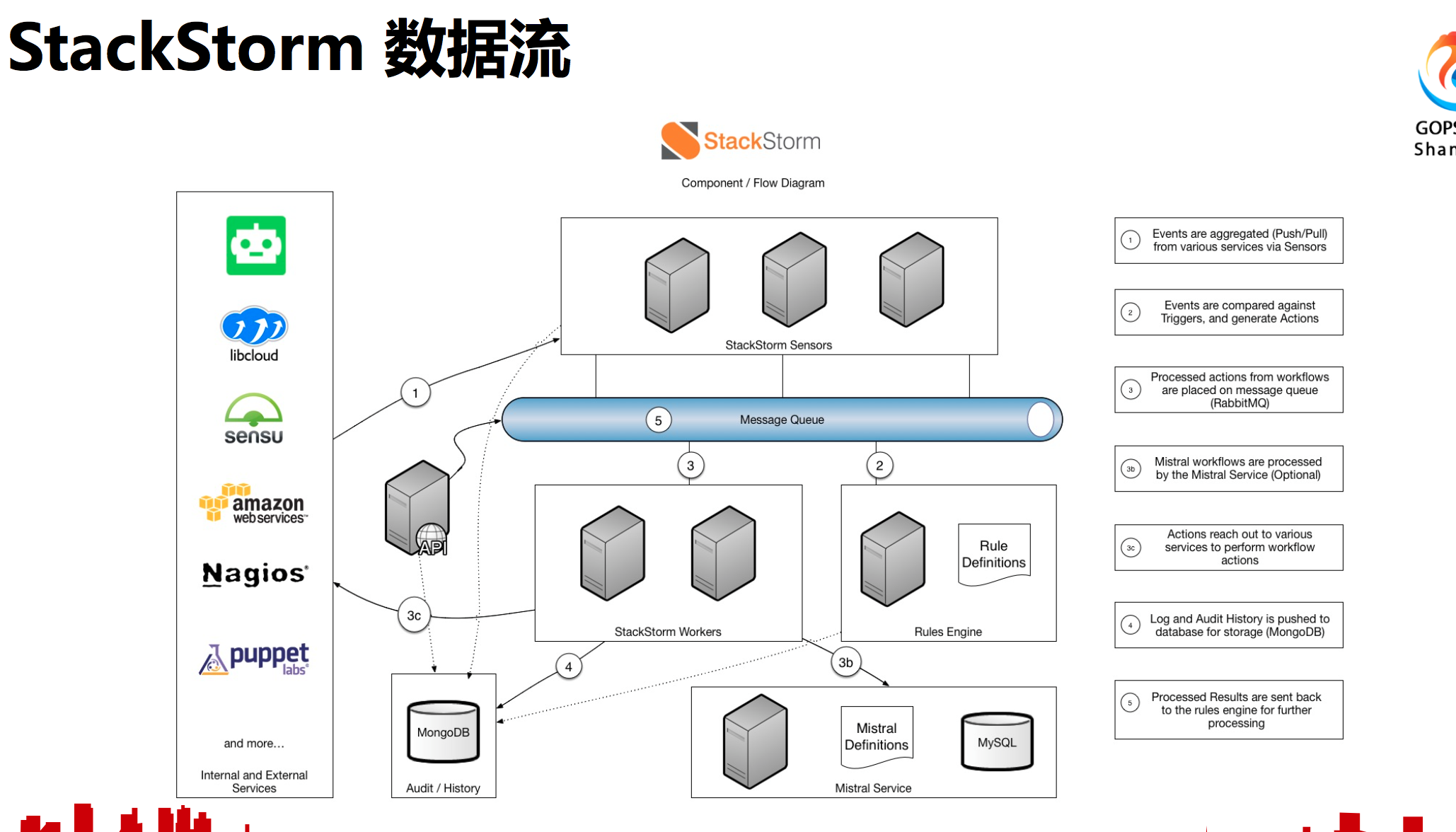
再看一下具体的数据流。上面说到了把具体的原子操作组成成工作流,这个就是在sensors里面完成的。具体报警过来做什么操作,在规则引擎做的,每个执行在worker里面做的。另外也可以指定一个定时的拉取。

StackStorm有下面三大好处:
- 提高了自动化开发效率
- 操作逻辑可视化
- 运维任何操作都有明细的记录
3. 分批灰度

做一个上万的操作,不希望人工把它分成一批一批,然后一批执行完再执行下一批,全部运行完成之后,统计到底有多少台服务失败。针对这样的情况,我们开发了一个能够进行自动分批以及灰度运行的任务JOBS。
我们希望达到的目标就是在一个新建业务的页面确定好我服务器的范围,指定不同的分批策略,然后设定好它的运营时间,最后设定它要运行的内容任务,点一下创建,这个任务就完成了,尽量减少人工操作。然后插件操作化,就是结合StackStorm,实际的运行逻辑在StackStorm里面,把相应的参数发给StackStorm,StackStorm运行完之后,就会得到统计结果了。
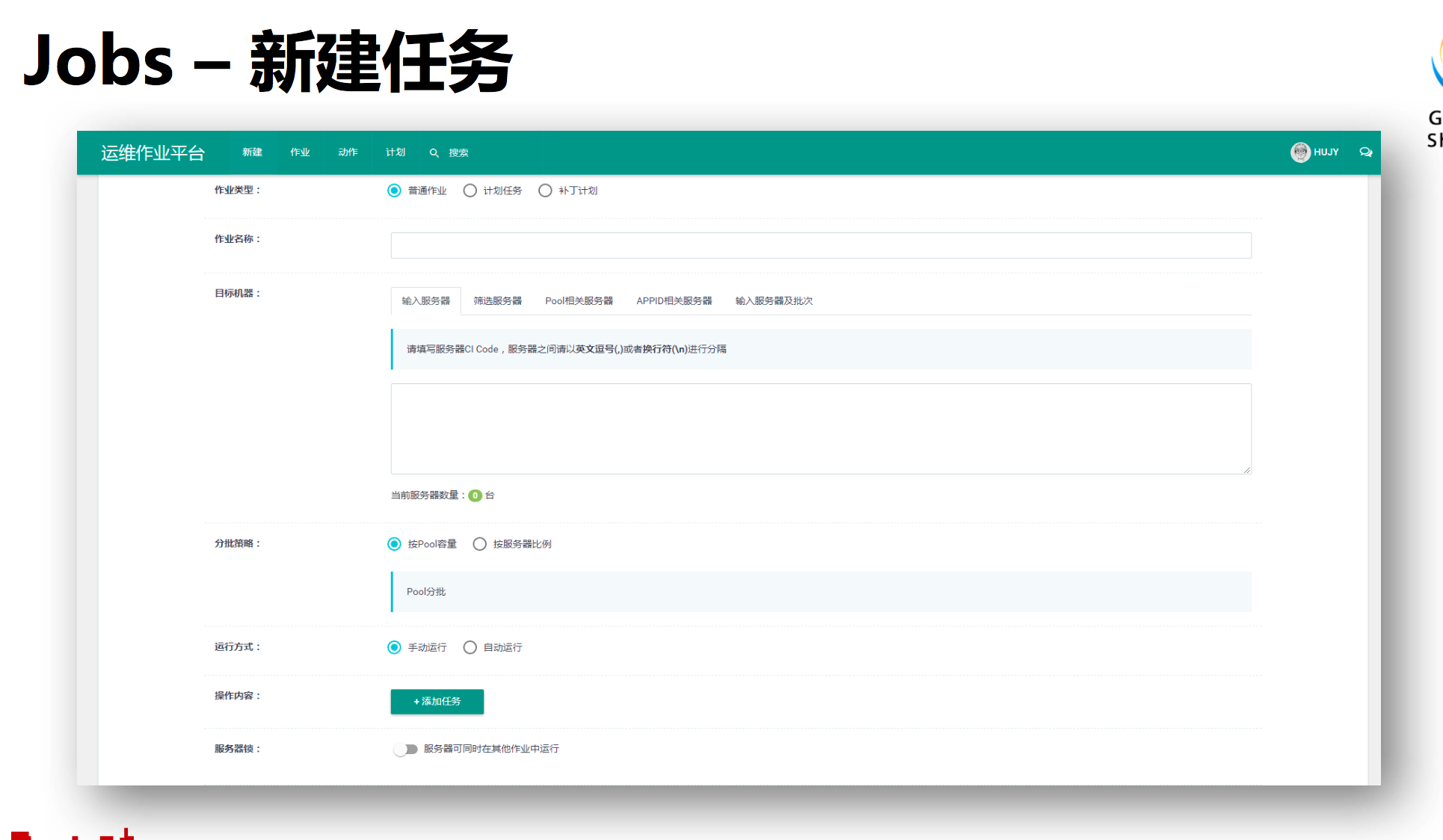
上图就是JOBS系统的新建任务界面,有分批策略、筛选服务器等等。
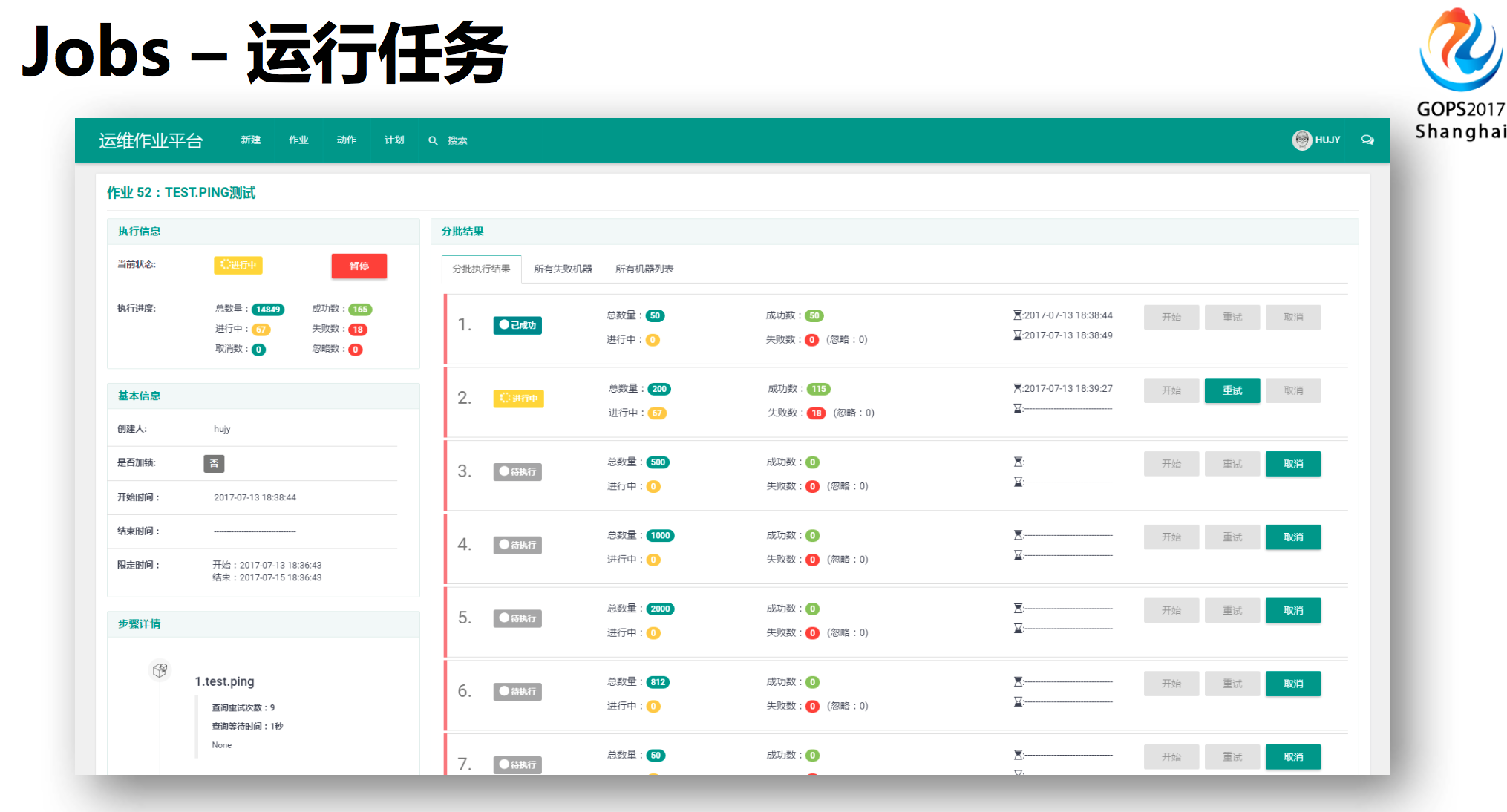
这个是JOBS运行任务的情况。右边是一个具体的分批的情况,左边是详细任务的信息,每批在什么情况下运行之类的,分批为了保障生产不会更多影响用户,有些某批任务失败率很高的时候就可以处理掉。
4. 总结
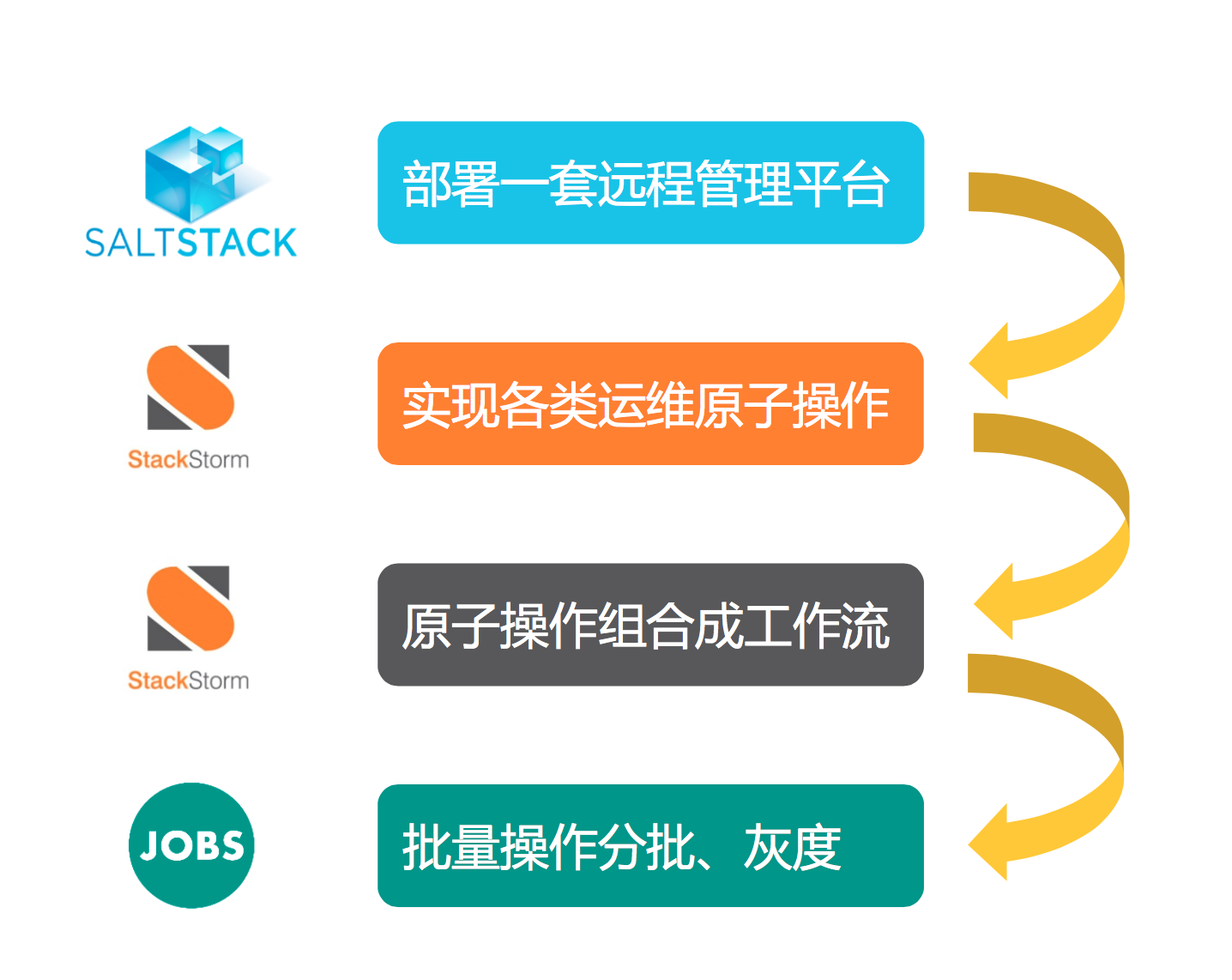
如果想搭建一套运维自动化的平台,可以利用一些开源的工具如saltstack,根据自己的实际应用场景的需求,结合StackStorm将各类运维操作原子化,把复杂的变更需求组合成一个个工作流。对于服务器数量庞大的情况,可以自己开发一套分批的系统。以上大家可以参考下。
