@gaoxiaoyunwei2017
2019-05-14T08:06:22.000000Z
字数 8042
阅读 1152
DevOps中高效测试基础架构的最佳实践
彭小阳
作者介绍:

茹炳晟 Dell EMC。ebay中国研发中心测试基础架构(QE-Infrastructure)技术主管,历任惠普(HP)软件中国研发中心资深测试架构师,阿尔卡特朗讯(Alcatel-Lucent)高级测试主管,思科(Cisco)中国研发中心资深测试工程师等职位,具有超过12年的软件测试经验和3年开发经验,具有丰富的测试框架设计与自动化测试经验。
概述:
今天我主要讲五个内容,我做内容规划的时候其实内容偏多,我们有些地方可以讲的快一点,有些地方可以讲的仔细一点。
第一部分,DevOps中高效测试基础架构设计概览。
第二部分,测试执行服务和测试执行环境服务的设计。涉及Jenkins和容器,帮助我们非常短的时间内进行成千上万的测试用例,按需来准备方式。
第三部分,做DevOps的过程当中发起测试。其实有时候测试是不稳定的,有些测试的不稳定很多是来自于测试数据。你的测试可以重试,但有些是由于数据造成的问题,怎么建立一套数据的体系帮助测试跑得流畅和顺利?会介绍eBay的最佳实践。
第四部分,测试结果自动化分析服务的设计与应用。流水线到某个阶段发起测试类型,可能会全回归,全回归的过程中,有可能测试用例的数量达到几千,产品制约的全回归可能是上万的。在这种情况下哪怕有1%的失败率,这个大家觉得低吗?其实很低。但如果基数是一万,失败的绝对数量还是很大的。
这么大的绝对数量用传统人工方式对失败用例做分析,你会发现DevOps流水线跑得再快,CI/CD跑得再快,测试会成为过程中的瓶颈。我们怎样通过构建自动化的测试结果分析,运用一些AI的理念快速做分配,去做失败用例的分发?这就成了我们讨论的重点。
第五部分,全局测试配置服务的创新设计。这个能解决很多有趣的事情。
一、DevOps中高效测试基础架构设计概览
首先讲一下什么是测试基础架构?我们可以从一个非常简单的方式去理解一下,当我们的CI/CD的Job要跑测试的时候,可以通过测试执行环境测试执行用例,测试执行环境本身需要人维护,测试用例代码需要管理,测试代码版本也需要人管理,代码版本需要与开发管理有一比一的应对关系。
也就是说如果你的开发代码版本号是1.0,那你的测试用例代码版本号必须是与之一一对应的,只有这样你才能找到对应的测试用例版本,才能做测试执行,否则很难找到实际可用的测试用例。
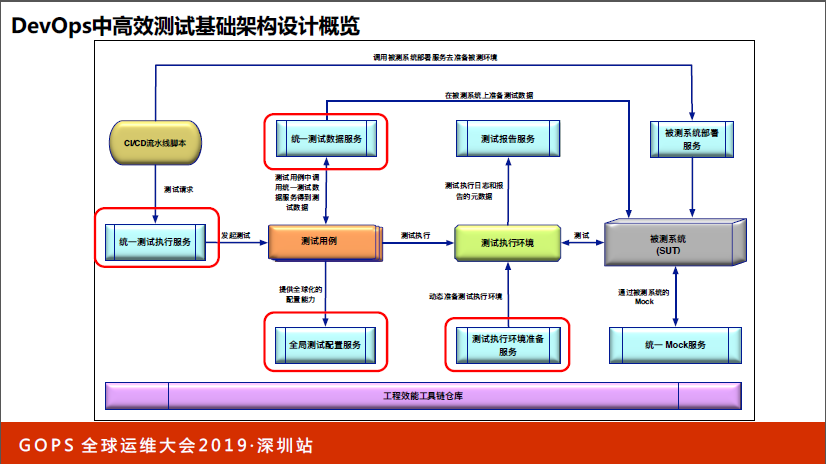
看一下整体架构。这个架构看上去有点复杂,但简单解释一下非常容易理解。
CI/CD的脚本都在这里,CI/CD不同阶段会执行不同测试,在早期或者在传统的CI/CD的脚本里,对于测试的发起在Jenkins的脚本里,所以测试脚本是强绑定的。其实这是两件事情,一个是CI的事情,一个是测试的事情,但由于他们之间的接口,所以会有绑定关系。
在这种情况下,我们提出了统一测试的服务概念,这个service可以发起各种类型的测试,但接口统一,在这种情况下CI脚本里可以直接调用统一的API的service达到解耦。
这个执行服务怎么调用?由这个服务统一发起。测试用例会统一测试服务,准备整个测试服务执行过程中所需要的所有测试数据,这个测试数据会在被测系统上创建,或者搜索我们需要的数据,而测试用例本身不需要对测试用例的数据做明确的指导,他只需要知道要什么数据,我们后面会讲这个服务是怎么构建的。
全局测试配置服务先卖个关子。之后我们通过测试用例在测试执行环境上对被测系统发起测试,比较直观来讲,可能是不同操作系统有不同的浏览器,还有被测网站,我们会在不同的浏览器和手机终端上,对被测网页进行测试。
这里有一个测试执行环境的概念,早年比较容易理解,本地机器装了浏览器。但在互联网背景下,测试执行环境变得异常复杂,主要体现在几方面。第一方面,要兼容不同浏览器还要兼容不同手机终端上不同的浏览器。以前比如100个case,一个一个跑,没问题,有时间。
但在互联网模式下,迭代周期可能是以天为单位的,你希望在很短的时间内把测试用例跑完,一定要采用并发,我们会让很多的case并发去跑,意味着如果有100个case想最短的时间跑完,意味着要100个机器同时跑,这样时间最短,100个case里面最长的执行时间就是整体的执行时间。
这时候希望整个测试环境和机器数量可以根据测试用例的多少,以及需要完成的时间来动态计算或准备,这个服务叫测试执行环境准备服务。
还有一些测试报告服务,可以提供统一报告。还有一些微服务测试的Mock服务,这些不是今天的重点。
二、测试执行服务和测试执行黄精服务的设计
整个过程我们会讲一下测试执行和测试执行环境服务的设计。讲这个之前我们先想一下,测试执行环境有哪些诉求,或者说有哪些问题?
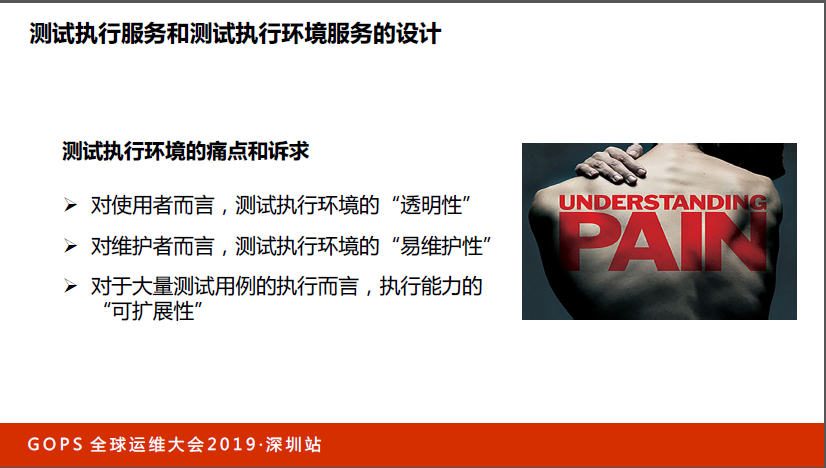
如果你是开发,或者是DevOpsCI上的工作人员,当你发起测试的时候,最理想的情况是要跑一个测试,而不是跑不同的操作系统和浏览器自己搭建环境,希望拿到的执行环境是按需拿到的,只需要说我要什么,不关心我怎么得到,这就是所谓的测试执行环境的透明性,所有的测试环境要准备好,这个是透明的,你要他就给你,至于他是怎么准备的?你不用管。
对维护者来讲问题就来了,要啥给你啥,意味着后台要维护大量不同操作系统中的不同浏览器,甚至是不同的手机终端,这里面有大量的维护工作,怎么在两边做平衡?这是测试执行环境的痛点。
最关键的一点,对大量的测试用例执行而言的执行能力可扩展性。刚才讲过,为了要在有限时间内,在CI过程中跑完很多case,会用并发来跑,但这个机器数量到底是放多少台机器?如果放固定的,比如eBay的早期的时候,测试执行机里面放了800台机器,空闲的时候全部是闲在那里的,但是到了发布的高峰阶段,这800台机器明显不够用,每台机器都在排队,希望机器可以随着测试用例数量的变化来动态扩容或者缩容,我们会用Docker技术来做,这是主要的诉求。
我们也不是一开始就做得很好,一开始是用很简单的环境,然后一点一点做成相对比较完美的方案,接下来我会通过这个过程,讲解一下整个过程是怎么发生变化的,以及在这个过程中我们遇到了什么问题,用什么方案进行的解决。

最早期的版本,相信大家都非常熟悉,Test case 放在代码仓库里管理,然后会有一个Jenkins的Job,Jenkins会把仓库里面的Test case给push下来,在一台或一批固定的机器上打开相应的浏览器,对被测系统进行发起测试,这是最原始的方案。我相信很多公司都在按这个方式用,随着这个方式越用越多,我们会发现有一个地方出了问题。
在Jenkins里面的Job数量越来越多,而且这些Jenkins的Job命名和规范,某某项目、某某版本、某某类型的测试会越来越多和越来越复杂,这种情况下包括执行完Jenkins的Job,也就是发起这轮后的测试报告管理,都是依赖于Jenkins做的,这时候我们觉得这个东西不够灵活,也不够方便。
为此,我们在Jenkins前面放了一个东西,叫测试执行系统。这是什么系统?说白了这个很简单,就是在Jenkins的基础上放了UI,这个UI是一个壳,对测试用例的Jenkins Job进行界面化管理或者说版本化管理。在这里面我们可以统一基于项目、时间和不同类型的测试分类,对这些Jenkins的Job进行管理。同时,我们会对Jenkins执行完成后的Test report进行统一化管理,这是我们做的第一件事情。
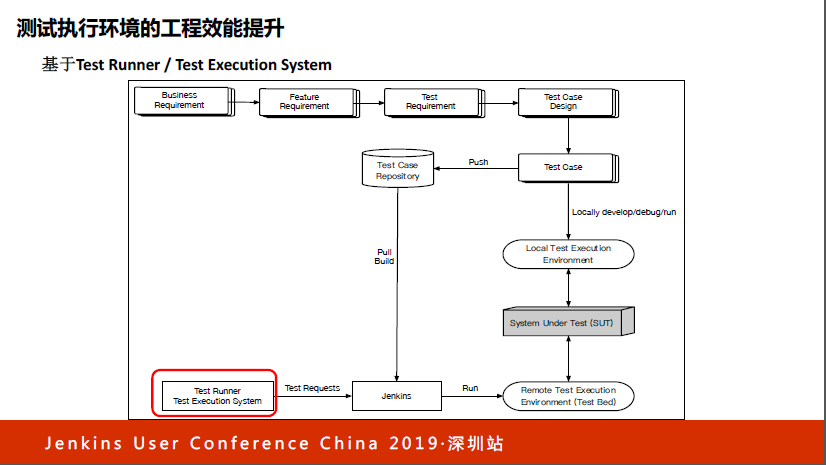
同时,这个系统除了有UI界面外,我们把这个系统暴露出了一个requests的service,可以统一发起测试,不直接跟Jenkins打交道。
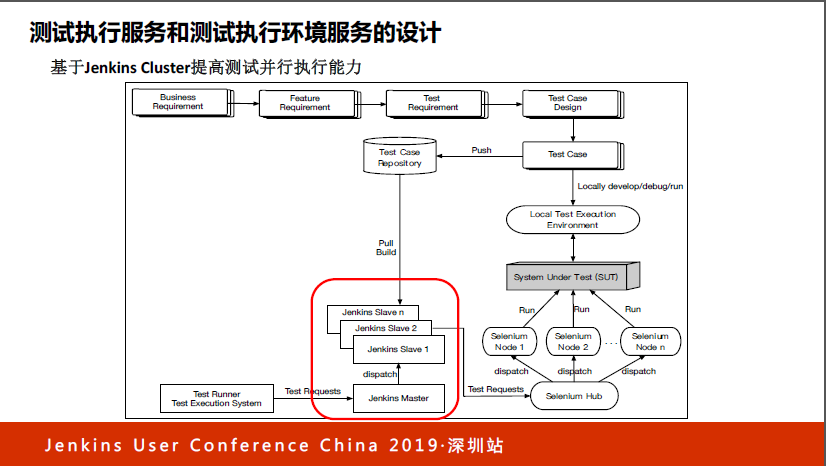
到了这个阶段之后我们发现,测试被管理起来了,但问题还有。问题来自于哪里?大家有没有注意到,这里其实是测试执行机,通常是固定放在那里的,这里面放的是不同操作系统装了不同浏览器组合的机器。
当Jenkins要跑测试的时候,这个测试假定跑在windows的IE上面,这时候就需要到这个库里找到这台机器的IP地址,然后把这个IP地址作为Jenkins Job的参数,然后Jenkins Job才能找到这台机器做测试。这样一来,你是不是觉得这个东西非常不方便?还要维护一张列表,还要维护机器的列表,还要维护机器列表相应的IP地址人工去做。
有什么好的方法来解决?我们引入了Selenium Grid。大家不要把Selenium Grid想象得很复杂,如果有时间我们可以在当场机器配置这个环境,不超过五分钟就可以把这个环境搭建起来。它是类似于树状结构的,有根接点我们称为Hub,下面的节点我们称为Node,节点可以挂不同浏览器和操作系统的组合。

当我们需要跑不同浏览器或者不同手机测试的时候,把请求发给Hub,由Hub统一分发。发给Hub的时候告诉他要哪个操作系统的浏览器,然后到下面的节点去寻找,如果有就执行。
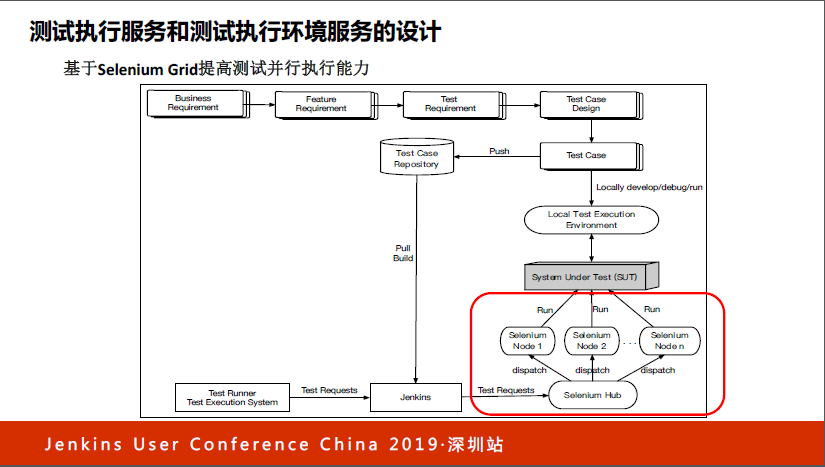
于是我们就把架构变成了这样,把固定的机器变成了Selenium Grid,这时候Jenkins还需要知道每个具体执行机的IP地址吗?不需要,它只需要知道Hub的地址,所有后面的分发全部由Hub完成,这是我们第一次做的比较大的更新。有了这个环境之后,我们觉得测试用例越跑越顺了,但这时候我们会发现有什么问题?
由于Hub的容量可以扩展,一个Hub下面可以放的Node数量很多,可以挂几百个Node,在生产环境和测试发布环境中发现了一个很严重的问题,Jenkins成为了瓶颈。
我们会发现,这下面有一两百个Node,没有执行满,但Jenkins在排队,因为Jenkins只有单节点,不能及时把测试分发下去,相当于这个Jenkins节点变成了整个系统的瓶颈点,那我们怎么解决?最简单的方式就是把Jenkins做成class,于是就有了Slave的格式,把排队的问题解决了。
之后又引来了一个新的问题,到底应该在这个环境里放几个Node?就像我说的,如果你放的Node数量比较少,那就省钱了,但是在高峰的时候不够用。但如果放的很多,浪费钱浪费电。我们有什么好的方法解决这个问题?现在大家可以想到,我们完全可以用容器做这个事情,不需要用虚拟机挂Node。
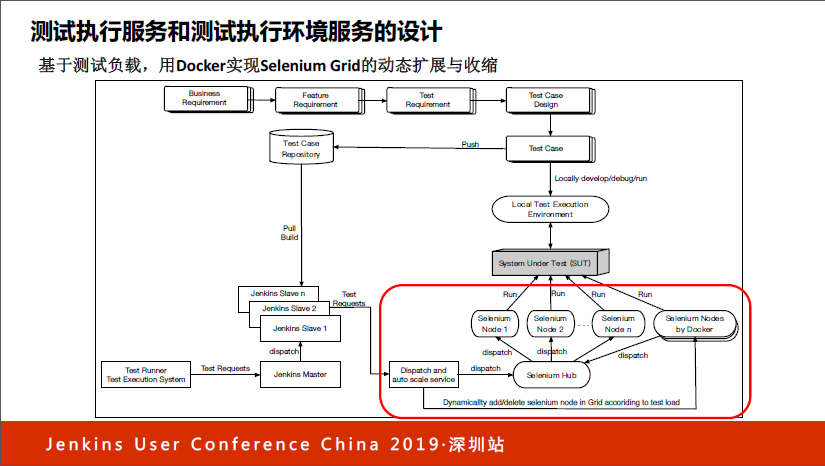
一旦用了容器挂Node,下面的节点就变成了Docker容器,同时引入了容量自动伸缩的模块,这个模块会根据Jenkins这边送过来的测试用例的排队数量以及需要在多少时间内完成,然后动态计算一个值,以此快速来做集群。
Jenkins来的时候,明确知道需要哪个操作系统和浏览器,所以在准备这个集群的Node的时候针对性很强,没有任何的浪费。这个事情是我们好多年前做的,当时我们做这个的时候,Selenium Grid的这套系统还没有Docker版本,后来我们还发现了很多bug,跟Selenium Grid和Docker团队做了沟通,他们意识到这是很好的方向。
所以从一年多前开始,Selenium Grid官方提供了这种方式,都是现成的,你可以直接拿下来用,如果我们现场搭的话,几分钟就搭起来。
这样一来,我们就可以做到在一分钟以内甚至是秒级,可以从平时的300个Node或者是800个Node,一分钟时间扩展成五千到六千个Node,三个小时跑完eBay的6万多个case,跑完后环境会自动回收,这样我们就省了很多钱,测试执行环境的执行能力明显上去了。
这里有一个不好的东西,我们可以作为坏的案例快速讲一下。既然Selenium Grid要做,大家觉得Docker有必要做吗?其实没必要。因为这里的Node数量都是上千的,而Jenkins这块的Node数量基本固定在三十个或者五十个,永远够用。五十个够用还有必要做额外的服务扩缩容吗?有点得不偿失。
所以当时我们做架构设计的时候,把它作为自动扩缩容,认为这是浪费的,所以只对Selenium Grid的做了扩容。
这是我们手机实验室内部的照片,会把各种各样的手机挂在Selenium Grid上面,为什么要选这些机器?我们内部用了Top30原则,调研了市面上前百分之三十的安卓大版本号、前百分之三十的安卓型号、前百分之三十的分辨率,交出来的就是这样的机器列表。在座有三星的人吗?没有我就讲了。
我们这个机房搭起来之后,三星的机器真的会爆炸,炸的不止一个。
因为这个机器理论上是不需要插线的,我们通过wifi执行,但因为要充电,所以常年线插在那,好几台三星发烫裂开了,而且不止针对于那个版本,这是我们实际看到的现象。
这是刚才讲的测试执行service,从界面来看,可以在这上面选择要跑什么测试,以及跑在哪些设备上,通过点击就可以跑。跑的时候可以选择测试环境、国家。红框里的内容很关键,这个选择的是测试用例的版本号。这个怎么选择?我们这个系统会动态侦测被测环境上的开发部署包是什么版本,自动找寻跟它一比一的测试用例版本。
为什么这么做?假定现在的环境是1.1,找到的测试用例版本好是1.1去做测试,测试不过有可能需要回滚,把1.1可能回滚成1.0,理论上应该用1.0的case做测试,而不是用1.1的,所以我们微服务架构下的测试用例版本一定要做版本化管理。
三、测试数据服务的最佳实践
刚才讲的是测试执行服务以及测试执行环境服务,接下来讲一下测试数据服务。
说白了,这个就是为你的CI过程中所执行的测试准备相应的测试数据。比如要做一个操作,在这之前希望把测试数据准备好。可能今天测试的同学不多,做测试的同学对测试数据一直是深恶痛绝的,对运维同学来讲就像版本分支和CMDB一样的概念,天天听到,天天是绕不过去的坎,天天被它坑。

这里面的数据有很多的复杂性,时间原因不一条一条展开讲了。我们最终做了一个非常棒的解决方案,把它变成了一个服务,只要你告诉我需要什么数据,我就帮你生成。怎么生成的?你什么都不用管。但这个东西也不是一蹴而就做出来的,我们也经过了很长时间的发展,我会讲一下这个发展历程,可能对大家开阔思路还是很有帮助的。
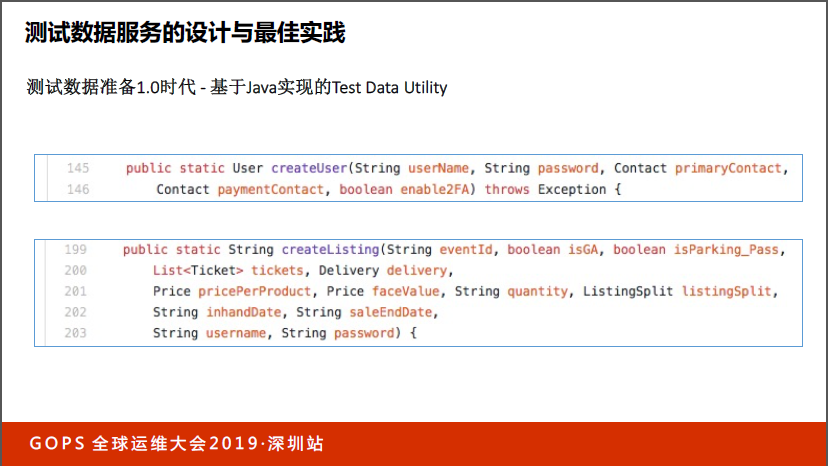
我们一开始的时候做了1.0版本,你不是要测试数据吗?比如要一个用户数据,我会把创建user所需要的API或数据操作封装成参数,并作为数据工具的函数参数。当你需要创建user的时候,可以直接调用函数就能拿到user。当时我设计的时候,我自认为肯定受欢迎,因为原来的数据是乱七八糟各搞各的,有些用脚本,有些自己复制,我觉得做完这个一定会受欢迎。但实际情况很悲惨,做完这个之后他们一点都不喜欢,你们知道为什么吗?
很多时候测试要一个user,其实绝大多数场景是能用就行了,不关注user的具体属性。更多的场景或者有一些场景只关心一个属性,要一个美国的用户,或者要一个绑定了支付宝的用户,我只关心这一个数据,其他以外的不关心。
如果封装成这种函数,你需要知道数据的每个属性,那就很不方便了,而且更坑爹的是什么?他还是一个复杂类型,调用之前要构建复杂类型,所以这个东西肯定不好用。
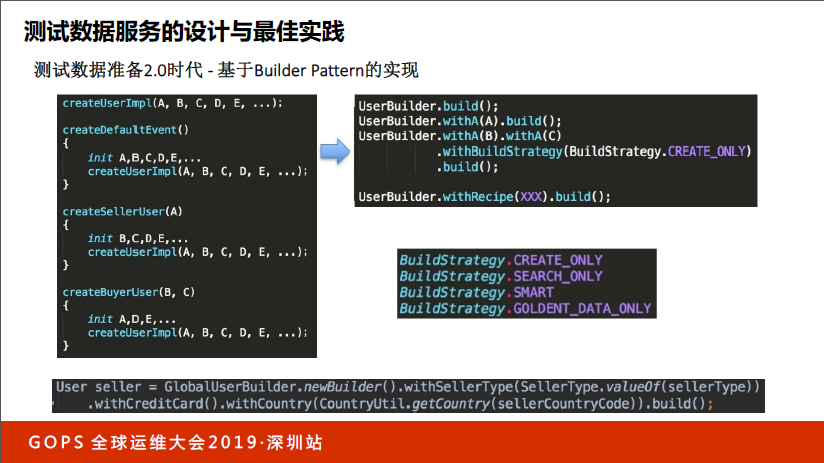
为了解决这个问题,我们做了2.0。这个我们做出来大家就很受欢迎了,我们会把最顶部这部分五个参数的组合作为底层函数实现,把其中ABCDE五个参数默认初始化,然后调用底层函数。如果你只关心一个参数,就把这一个参数暴露出来。除了暴露出来以外的余下参数,帮你做默认初始化,这样一来用的人就爽了,只需要用一行。如果要改一个参数,那就调这个,用的人爽了。
这个就像讲测试执行环境是一个道理,用的人爽了,维护工具的人很苦。如果有五个参数、六个参数、十五个参数怎么办?单个可以暴露,两两可以组合,三个也可以组合,那就无休止了。
我们在此基础上做了改良,这个样子还是很好玩的。当我需要一个user,我们引入了Builder,当需要指定一个参与,with某参数值就可以了。如果需要两个参数修改,就是with两个参数加上build。同时为了扩张应用范围,还引用了BuildStrategy。如果是Search_Only,可以默认帮你找。smart是为了让互联网的速度变慢,因为Search的速度慢。是不是任何时候就可以产生任意要的复杂数据?这就是2.0时代。
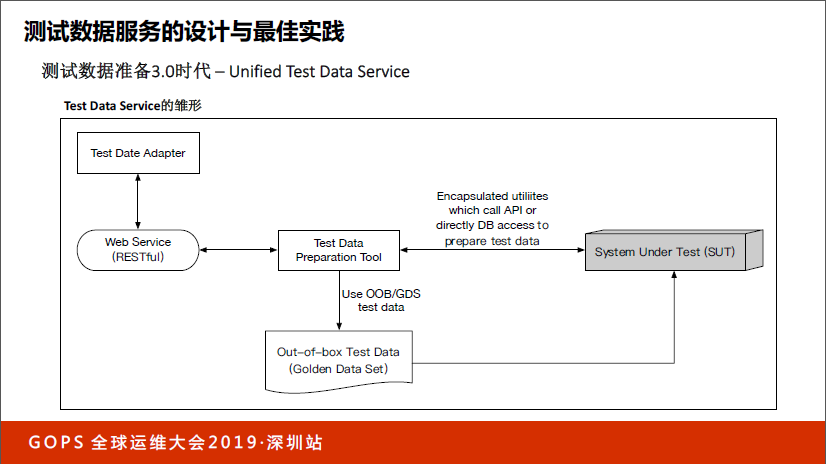
看一下3.0时代,不管你是Java写的还是Python写的,只要能创造出刚才的请求,就可以成功,所以Test Data Core Service就是它的雏形版本。有了Test Data Core Service之后,成功创建了一次测试数据,是不是有可能在下面还需要同样的测试数据,这个假定是合理的。
如果大家同意这个假定会发现,当你通过Test Data Core Service生成了一条数据并且成功创建了,我们就会在后台做Jenkins Job,自动帮你创建100个同样的数据。当你下次需要同样的数据,我们就不是实时创建了,是事先创建好的,会让整个测试执行的速度变得更快,这时候可能需要引用额外的数据库做管理。额外创建了100个数据的原数据需要在数据库里,不然怎么知道数据库是你创建的?所以我们引入了DB来做。
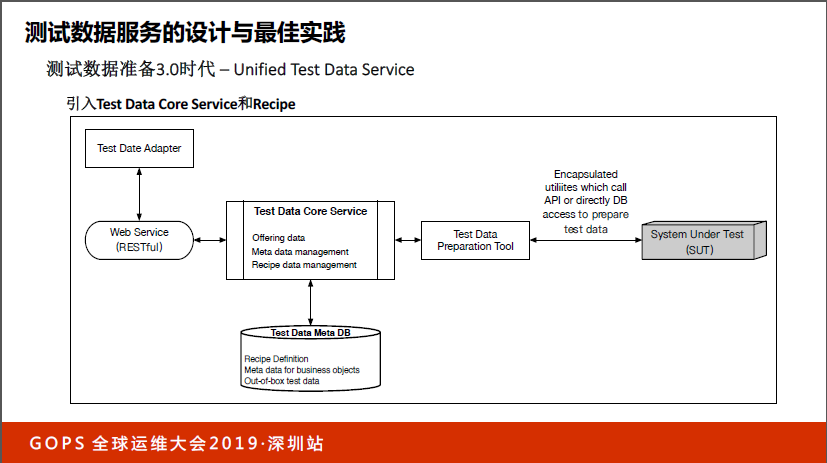
这样一来,就有了Test Data Core Service解决测试过程的问题,可以很方便拿到想要的测试数据。
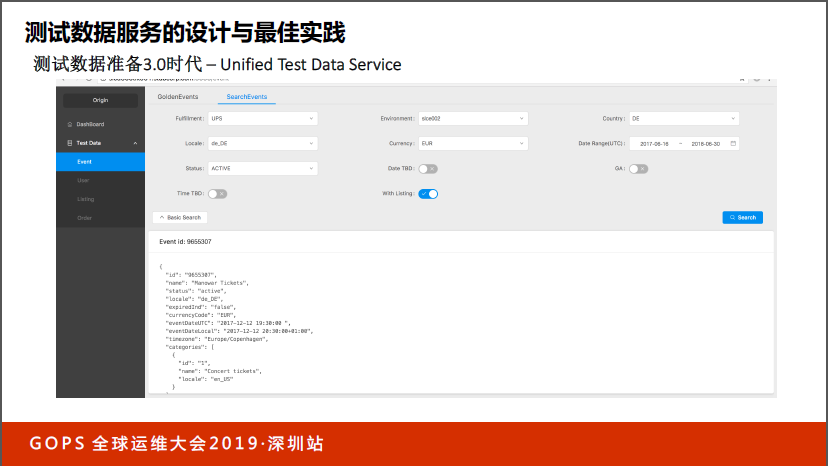
这是Test Data Core Service的UI显示。
四、测试结果自动化分析服务的设计与应用
看一下测试结果分析,这部分比较有意思。eBay的测试用例有6万多个,百分之一的失败就是几百个用例。我们第一步分析的目的是什么?仅仅把这个bug分配给正确的team,靠人做好像效率很差,我们能不能让机器来做?于是我们就引入了一个东西,会把Test report里面的东西引入,把这个模块对应的开发进行处理。
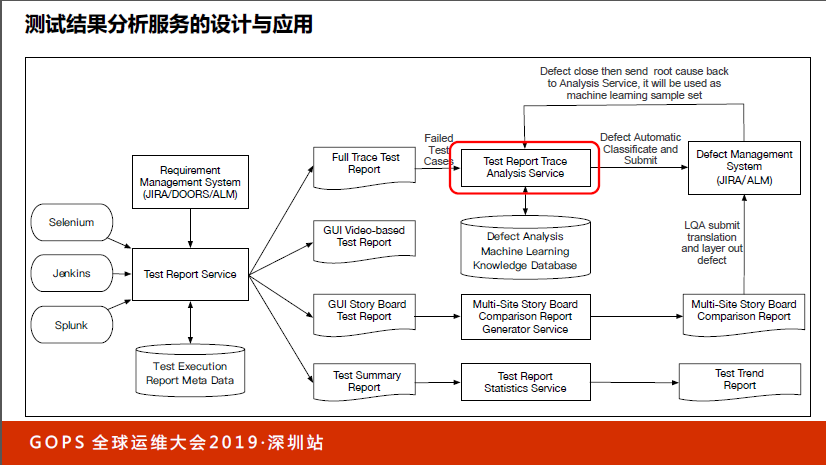
如果没办法判断这个bug分配给哪个team,我们会引入KNN算法,这是人工智能的分类算法,找到对应最合适的team来做测试用例的分发。这个过程就相当于在三种豆子里面分豆子。比如这颗画圈的豆子,到底是黄色橙色还是绿色?会先计算距离,然后拉一个框看这些距离哪个最近,看哪个多,它属于最多的这一类的可能性就最高,以这种方式进行分类。
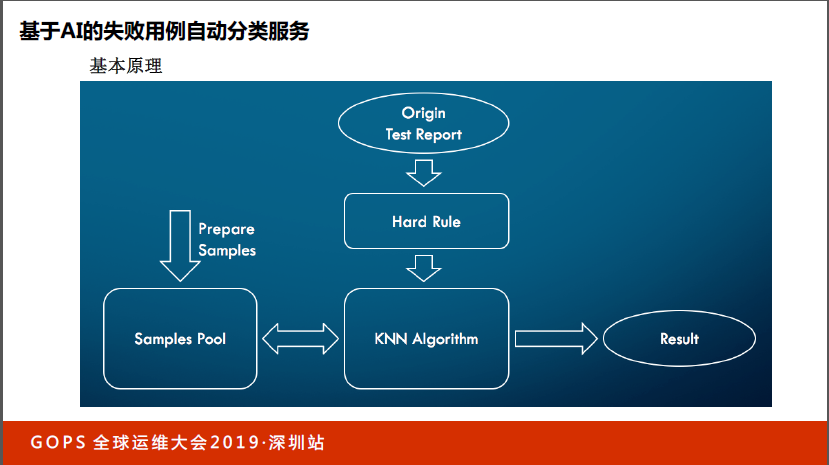
做分类的时候有特征值选取的问题,通常会用这些值来做。
五、全局测试配置服务的创新设计
最后一个,这个不仅测试可以用,CI也可以用,而且是CI可以用的很好的工具和思想方法。
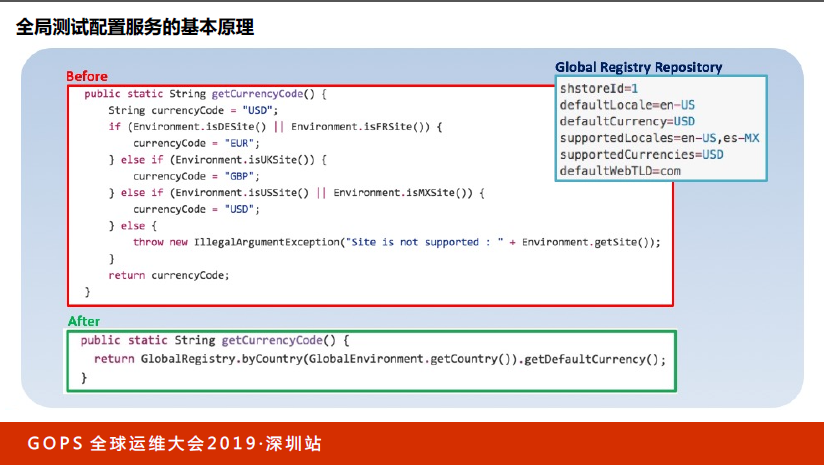
我们看一下这段代码。这段代码的目的是根据不同的国家拿到不同的货币符号,默认先把货币符号设成美元,如果环境是德国或者法国,把货币符号设成欧元。如果环境是英国,把它设成GBP,如果环境是美国或莫斯科,设成USD。如果有新的国家或新的分支,加一个if else。
但如果是多国家,每个国家有轻微差异,在测试用例的代码里,或者在CI Job的分支里,会有大量的if else,不同逻辑执行不一样,这种情况下代码维护工作量很大。假定今天增加了日本,是不是要把所有的测试代码包括运维代码里面有这个分支的if else都加上?
我们把这么大的代码变成了底下的这一行,而且可以做永久性拓展。通过globeregistry直接获得得到的国家。这个其实一点都不难,我们额外引入了配置文件,每个国家有一个配置文件。你去看byCountry,直接从国家的配置文件拿到,这时候整个代码里没有if else,这样一来可以把整个测试以及CI Job中由于国家差异和地域造成差异性的if else全部去掉,一行代码就可以解决这个问题。
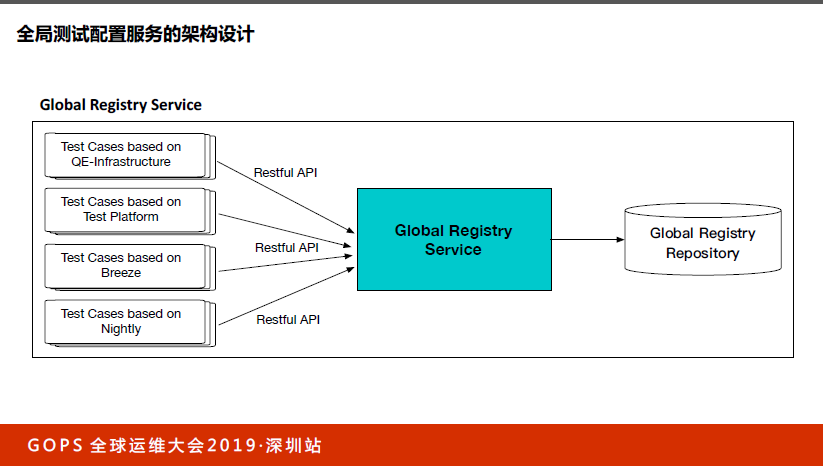
类似于Jenkins2.0的概念,流水线用代码写,有if else分支可以写,现在只需要这一行,再基于一个不同国家的配置文件,就可以解决所有问题。更好的是,这个配置文件可以放在GitLab里面做配置化管理,也就是做了一次解耦,把全局配置根据国家放到外面做了独立封装,这是Java实现的,我们怎么让它变成所有的语言都能用?我们可以把这个服务变成Global Registry Service。
