@gaoxiaoyunwei2017
2018-04-20T07:56:20.000000Z
字数 6786
阅读 1441
万台服务器一人挑的实战技巧
luna
作者: 张黎明
作者介绍:张黎明,SNG组建运维团队负责人,有八年的运维经验。参与了国内社交平台QQ、Qzone从发展到壮大的过程,也参与了SNG系统标准化、大规模组件的推广,自动化项目在海量服务运维方面有一定的心得,所以今天给大家分享一下具体实战。

首先,来说一下我们的组件运维团队的职责范畴。我们负责整个SNG业务的接入和逻辑层的运营维护。我们SNG组件团队负责了1.8万的域名,3000个业务模块,4万台设备,单人运维设备超过2万台。自然而然,我们面临五大挑战。
第一个挑战,我们都知道,中国幅员辽阔,横跨八个时区,有30多个省级单位,上万个域名如何保证就近接入?我们机房是上海、天津、深圳三地分布。考大家一个题,江西离上海近还是离深圳近?其实是部分离上海近,部分离深圳近,江西北面离上海近,江西南面离深圳近。
我们在招运维的时候,还要求运维上通天文、下通地理才能干好,这显然不靠谱。我们中国有三大运营商,电信、联通、移动,还有很多小的运营商。中国有一个段子,世界上最远的距离不是你在天涯海角,而是你在电信、我在联通,相信大家做运维这个体验特别深刻,所以我们要尽量避免跨运营商。
第二个挑战,自从苹果颁布https证书之后,这就是一个标准了,我们https是有有效期的,要不断续期,不断管理和维护,这上万个域名怎么保证证书高效,由运维完全搞定这个问题,这是面临的第二个挑战。
第三个挑战,一个人运维服务器超过万台的时候,你会发现每天名下有几台设备是一个常态。像前面讲的,你不能躺下了马上就起来,这是一个人做的工作,我们如何保证这个是无损的,而且还是做宕机自愈。
第四个挑战,互联网中有一句话上线容易、维护难,互联网服务的运营维护成本时间周期比研发周期长,一个产品的研发周期,开发出来就几个月,但是运营维护的时间往往是十年甚至超过十年,很容易进入长尾死而不僵的状态,所以对运维也有挑战。
第五个挑战,大规模的高扩容。比如说在春节、元旦这些节假日发感想,社交网络还会火上浇油一把,在节假日的时候搞一些活动,比如说QQ红包每年都搞,节假日就变成我们运维的苦难日,因为涉及到大量设备上线、模块扩容,服务高压下的稳定性,这是我们面对的第五个挑战,如何应对大规模的高扩容。

本文从3方面进行阐述如何应对挑战

1. 海量服务的基础架构
从海量服务的基础架构阐述,在我们运维过程中坚持的一些原则和我们支撑大型活动事件的技巧,来分别阐述这个过程中我们如何应对上述的挑战。
首先看一下腾讯SNG的基础架构。用户一个请求过来之后,任何一个访问首先是一个DNS查询,我们腾讯的DNS查询到TGW和STGW的网关。这个TGW与业界开源的产品是类似的东西。请求经过网关的负载均衡,到外部的服务器,从Web层到逻辑层,这种内网就是负载均衡。我们访问链路有几个访问基本点:第一,做到名字服务实现没有调不走的流量,这对运维是非常重要的。第二,容错做到没有不能宕机的设备,也就是没有不能死掉的设备。我们在网上看到一些段子,运维请法师来作法请求不要宕机,其实求佛不如求己。第三,统一框架提升研发运维效率,保证服务的基本质量,对于运维这有很大的意义,后续我会重点阐述。
牛顿说,如果我看得比别人更远,是因为站在巨人的肩膀上。如果我们能够运维万台服务器,是因为我们站在巨人的肩膀上,踮起脚尖,做了一米八的眺望。
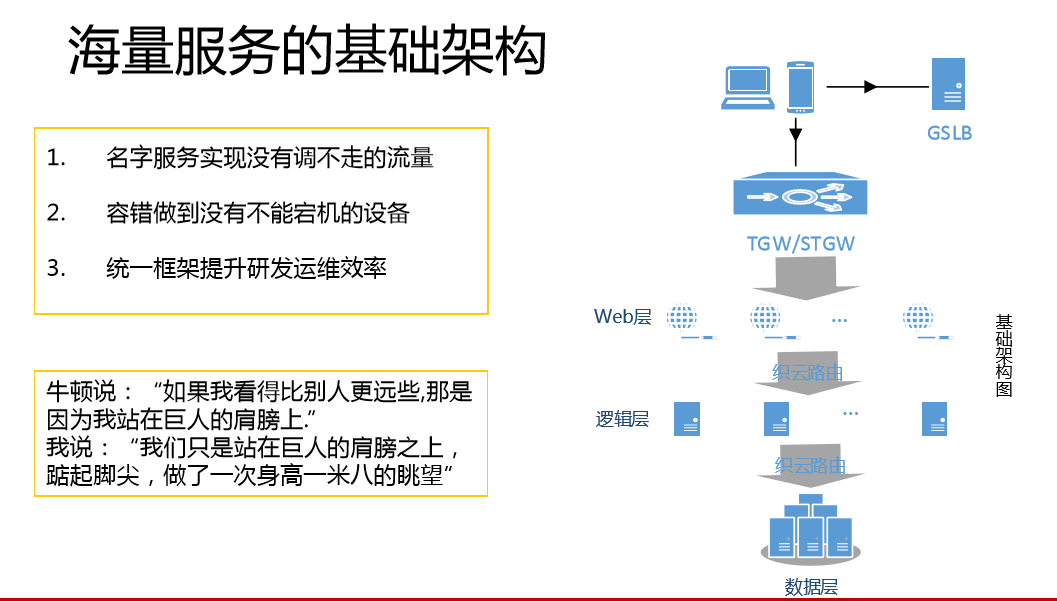
我们巨人的肩膀,一个是GSLB,是腾讯自研的DNS服务,通过识别LocalDNS出口IP国家+省份+ISP属性,然后给对应请求返回相应的IP,实现就近接入。北京、上海、天津每个地域有三大运营商+中小运营商,然后再加上香港,所有海外的通过香港接入的方式,根据运营商来进行调度,这样一个是避免了跨运营商,二是做到运营商网络出口故障快速切换,依赖的就是GSLB的两点。GSLB有一个强大的基础数据库,它有全面而精准的IP地址库,国家和运营商的信息准确率做到100%,省份的信息准确率做到98%,我们拥有各IDC机房对各地用户覆盖质量的实时数据。我们到亚洲网络中心和中国网络中心查这些数据,也会经过路由数据通过算法,然后抽样报告这个数据。
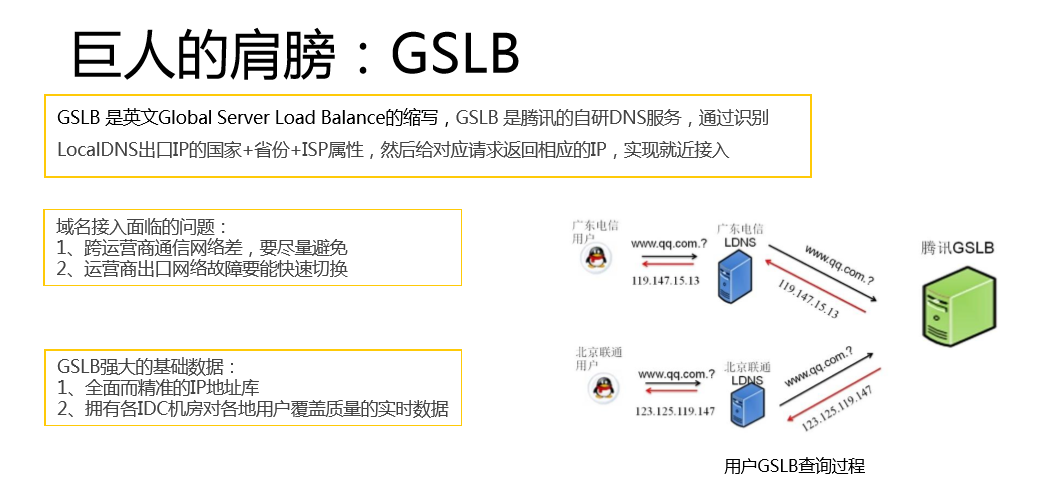
第二个巨人的肩膀是TGW,也就是腾讯的网关系统。2012年我们腾讯也用了外网接入模式,但是我们腾讯的业务发展太迅猛了,特别是游戏很快面临一个问题,外网资源耗尽。这种背景下,我们的研发部推出了TGW这个系统。它的最大特点是能够收敛外网IP,只需要一个外网IP,所有的进出都是通过TGW。所有RS数据的进出都是通过负载均衡,对后端真实的服务器是没有外网需求的。LD本身的VIP怎么做到呢?通过路由一致性,一般是4台为一个集群,共享这个VIP,任何一个LD挂掉之后都不会对这个VIP产生影响。
另外,我们还做了多通接入,每个机房有三大运营商的出口和KAP(音)的接口,我们部署的服务器对运营商机房没有要求,电信的机房一样有三网+KAP的出口。以前用外网的时候,电信的容量必须靠电信机房的服务器,所以对机房服务器的限制就非常多。
除了外网IP收敛之外,我们也支持4/7层,特别是在7层,可以做到几百域名同时,这些外设机房承载能力也比较高,抗压能力也非常强。
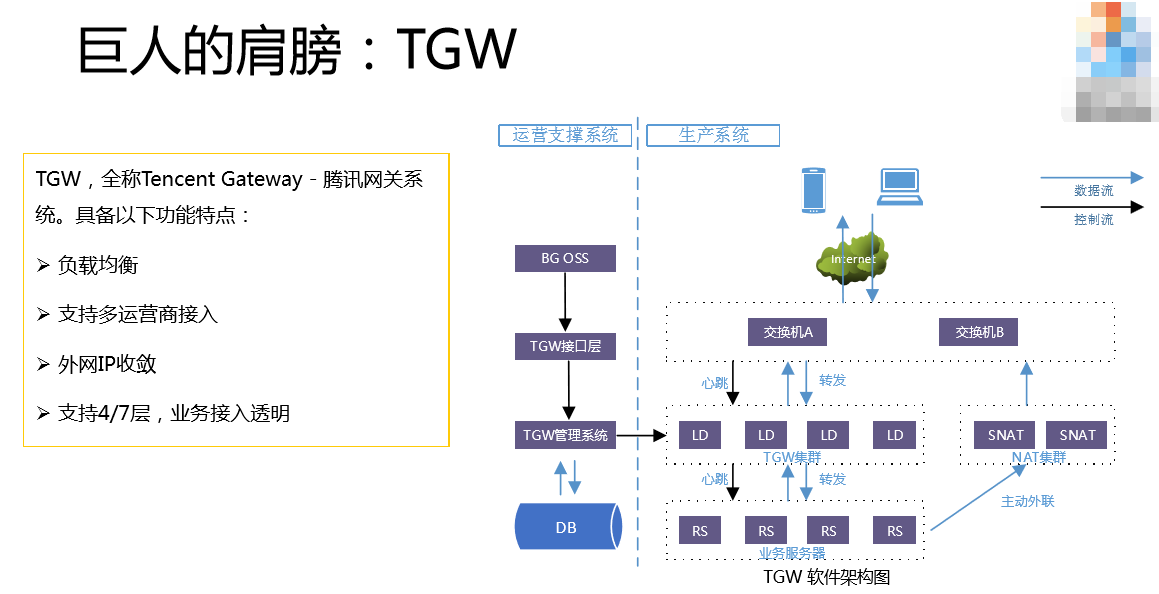
第三个巨人的肩膀是STGW。你可以认为跟TGW是差不多的,它只是在TGW基础上支持了https,自从苹果颁布了https之后,我们就增加这个接入,因为你说你的网站不支持https就不好跟人家打交道。我们面临的情况是域名特别多,以前没有https之前,开发或者运维自己有一套自己的模板,自己把证书加到这上面来,证书没有统一管理,所以出现很多证书的故障。我们痛定思痛之后,对全网的域名全部推动上STGW,所有证书统一上STGW平台,管控全部由我们来做。证书从外围一个一个的去拿的可靠性就比较低,如果是STGW托管,我直接从服务器上读取,这是不可能失误的。
第四个巨人的肩膀是织云路由。刚才也做了详细分享,它的定位是内网的名字服务系统。它是我们的用户寻求经过TGW之后,到内网是接入层到逻辑层,逻辑层到存储层的寻址系统。有一些是用F5的代理,我们为什么不用呢?是差钱吗?我们根本不差钱。讲一下我们为什么不用,我们的路由是强嵌入式的,对用户主调是有要求的,这里有两个函数,接口非常简单,首先通过GetRoute获取ip端口,拿到端口之后去访问,然后你访问我访问成功还是失败。通过对API上报的数据进行统计之后,做一个负载均衡的决策。
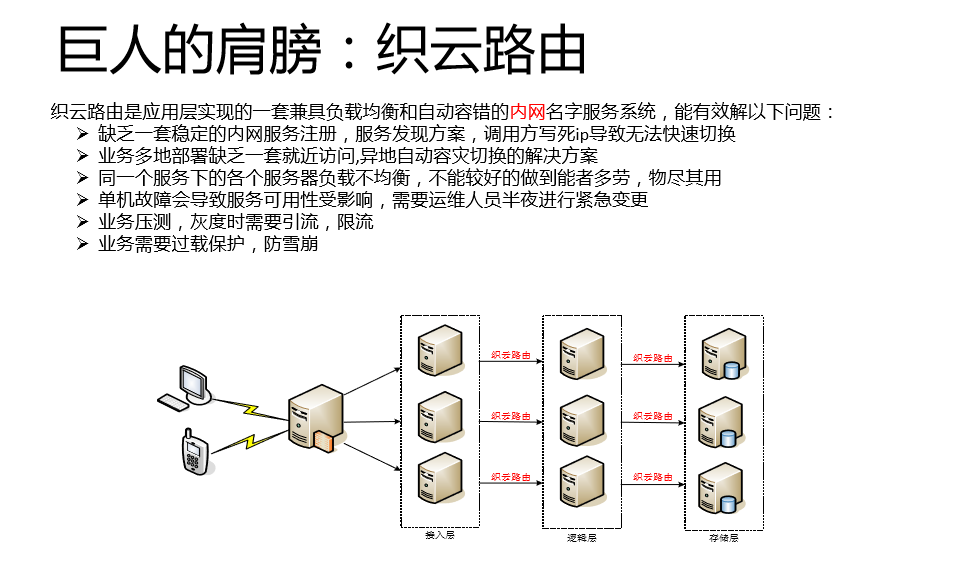
我们的织云路由跟业界大家熟知的东西到底有什么区别?我来详细介绍一下。刚才说了,我们不差钱,为什么要用织云路由呢?因为我们对服务的精细化治理有要求,所以它本身是一套服务精细化治理的解决方案。
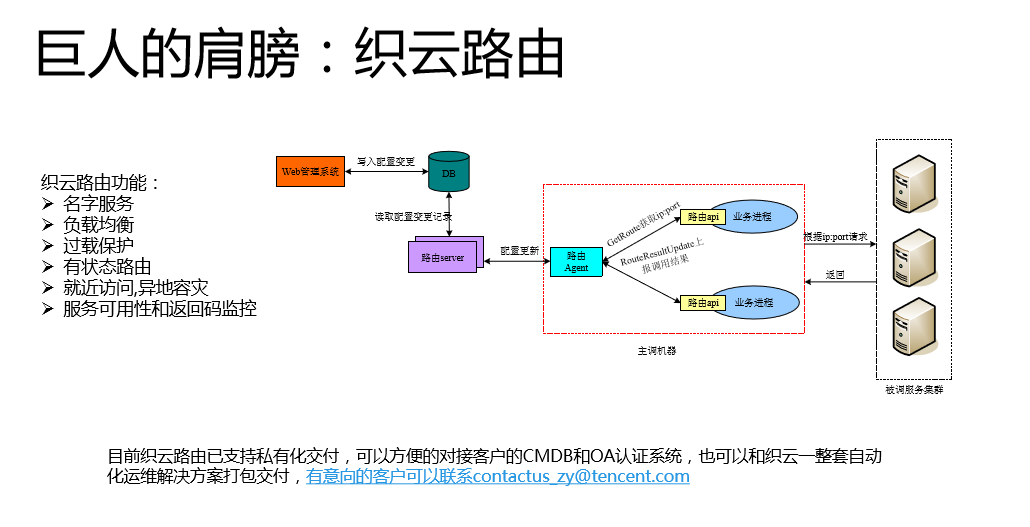
它唯一的劣势是在使用门槛方面需要业务调用API代码,但是这业带来好处,相对F5和LVS这种透明的方式,我们的好处,一是我们实现了后台服务质量的精细化管理,我们后台服务考核的标准,通过这个给后台打分,我们运维推动后台的服务质量。二是负载均衡根据业务上报的成功率设置了过载保护的能力,后台能力不行的时候会把多余的请求拒绝掉,只给能够成功的请求。与其把请求全部发送给后端,把你压死,不如在前端获取端口的时候就告诉你过载了、不要请求了,我们把请求放在它能够承受的次数来发给他。三是容错能力,F5和LVS的容错只能探测到端口的数据有没有错,而我们有容错场景。如果拿不到这些数据,我们对服务的排查和前端的问题追踪是一个很大的门槛。

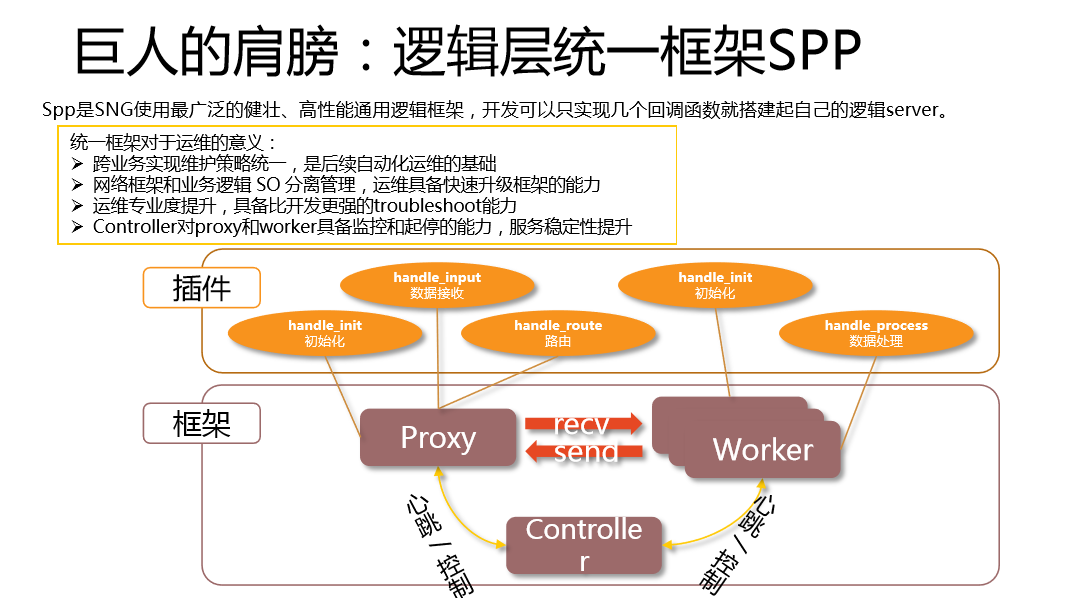
第五个巨人的肩膀,逻辑层统一框架SPP。后台的框架对运维的意义重大,我们的后台框架由Proxy、Worker和Controller三部分组成。开发可以有高大上的开发程序,这个Controller对Worker和Proxy有监控能力,如果发现Worker和Proxy有问题会进行控制,还可以通过配置Worker的进程数来监控。
统一框架对运维的意义:
- 一是我们可以跨业务实现维护策略的统一。
- 二是网络框架和业务逻辑SO分离管理,运维具备快速升级框架的能力。说一下我们的优势,有很多统一框架是集成的,有很多框架是和业务程序包打在一起、编译进去的,我们框架推出一个新的优化,想全网快速普及的时候,你唯一要做的是让所有业务系统重编这个SO,重编框架才能够得到普及。而我们的框架和SO分离的管理方式,框架是由运维统一部署的,SO是由业务部署的。我们有一个好的特性或者紧急的BUG要升级的时候,我们快速升级框架,不需要重新编译就可以做到这一点。
- 三是运维专业度提升。大家知道,铁打的业务,流水的兵,人员流动是非常快的,我们统一框架之后可以做到运维在问题定位方面具备更强的能力,专业度的提升非常大,框架数据包的流转流程非常清楚,你就比开发更懂他写的这个程序,当然除了业务逻辑除外,大部分方面你比开发更专业。
- 四是Controller对proxy和worker具备监控和起停的能力。后台经常出现扩掉的情况,使用不善就会扩掉,Controller使你的服务即使挂要也能够恢复。
2. 运维实践中总结的几个原则
说完了巨人的肩膀,接下来说一下踮起脚尖一米八的眺望。如何让运维变得更加高效?
第一个原则是“名字服务原则”
前面说了,名字服务非常关键,我们要保证系统任何一个寻址都有名字服务。我们每年有上万台设备,没有IP是不能动的,所有IP都是可以变的。而且我们一天有几万的发布,这是非常常见的。我们近10万台设备,设备宕机成为一个常态,名字服务是自动化运维的基础之一。

我们从三方面来做:
- 一是联合QA建立质量考核体系。我们把访问关系梳理好,和名字服务的访问关系来对比,发现哪些没有使用名字服务,从名字服务的覆盖率和QA推动所有研发必须用。这是中策,毕竟推进过程中还不是那么好。
- 二是后台框架支持RPC,你的框架支持RPC之后,对它是封装路由寻址调用,让他在不知不觉中已经使用了你的服务,你的服务提供方就可以具备流量快速切换的能力。
- 三是某种场景可能不适合使用无状态织云路由服务,所以我们在内网支持了DNS协议。有的业务可能不具备程序的修改能力,我们支持服务协议就是降低接入门槛,这样来普及我们的名字服务,做大我们名字服务在内网的普及。

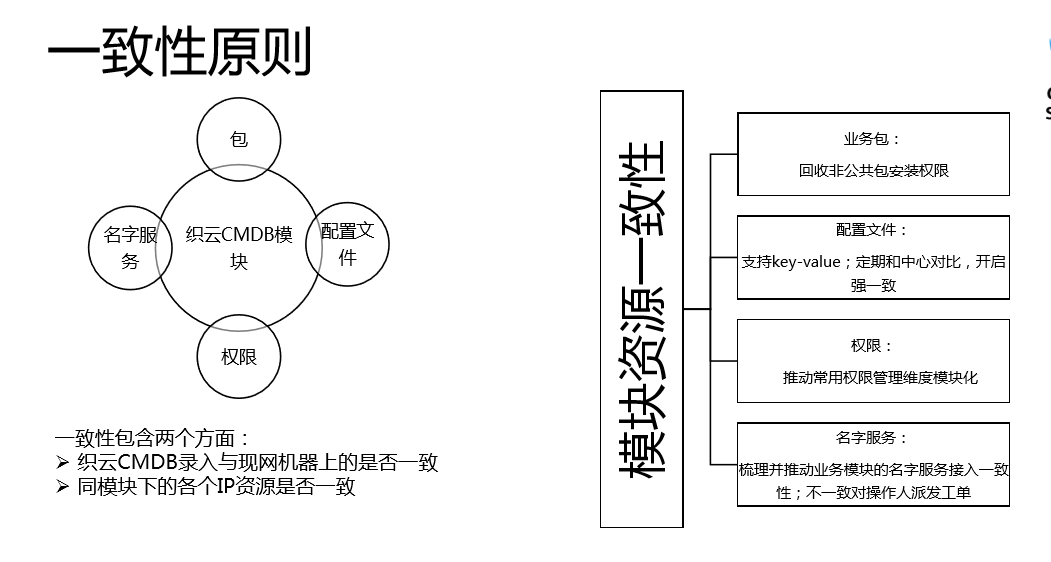
第二个原则是“一致性原则”。
大家做过运维,都知道我们的服务是按照模块。我们的织云CMDB模块有包、名字服务、配置文件、权限。你要看系统接入和现网使用的是不是一样的,所以我们运营的时候也遇到问题,我们对装包的程序进行了收拢,装包的时候在我们总监团队进行控制,必须我们这边审核和抓后续的升级,我们为了实现模块下所有设备包的一致性的管理,不能有的机器装了、有的机器没有装,这会对现网带来运营风险。
配置文件方面,你通过配置发送到现网,有人篡改了,和现网使用的配置不一致,只要你动这个配置就会出现问题,所以我们正在启动一个改造,开启强一致功能,把配置文件和中心目录进行一致,发现不一致就强制修改回来。我们在想,为什么要以配置文件的方式,而不能以Key-value呢?使用Key-value,你不需要在本地文件进行读取。比如说有一些是热重启的,有一些不支持,难免就会有影响,Key-value的模式天然的就是不需要你重启的,所以这种方案也有很多实现。我们后续主推Key-value的方式,让生效时间和生效影响都变得最优。
权限方面,最开始我们按照IP去管理,后来发现IP上下的冗余,短板很大,所以我们就跟模块绑定,不是跟IP绑定,跟IP绑定会发现运维的问题很大,按照模块管理,只要在这个模块下就有这个权限,这个管理比IP管理要优一些的。
某种程度上,我们织云的管理维度,你这个模块绑定了哪些名字,这个模块的IP是不是接入这些服务,如果有的没有接、有的接了,对于你缩容的时候会产生风险,会有把某一个维度踢空的风险,所以我们定期进行比对,一旦发现有问题就发信息让它去处理。
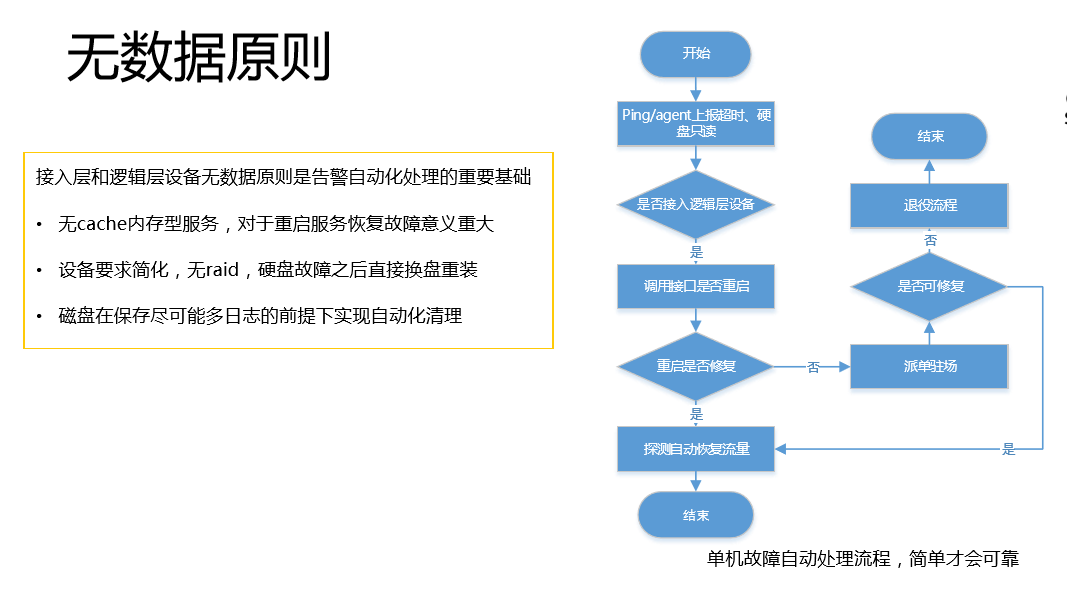
第三个原则是无数据原则。
这个原则是很重要的,对于我们接入和逻辑层,对于一个人维护2万台设备是非常关键的基础。我们要求所有的数据的接入层和逻辑层设备无数据。比如说上报超时这种假死状态的告警,服务恢复是非常关键的,因为它无数据,所以整个过程变得很简单,我要考虑的点比较少,自动的宕机故障处理就变得简单,而且可靠。你有告警,我们首先判断是不是组建接入层这个设备,是不是可以重启,如果可以重启就直接重启。刚刚说了,我们的织云路由是具备流量自动恢复的,会在你故障之后发现你的端口OK之后就把流量自动恢复过来,如果不能修复就看驻场能不能修复,如果驻场不能修复就退役了,如果驻场能够修复就可以继续服务,所以这种就是简单粗暴可靠的。第二个无数据的要求,你可以存储不能丢失的数据。这样就简单了,设备要求简化,无raid,硬盘故障之后直接换盘重装。第三个无数据的要求,磁盘在保存尽可能多日志的前提下实现自动化清理。我们一步一步的压缩下去,对我们来说骚扰就会变得非常少。
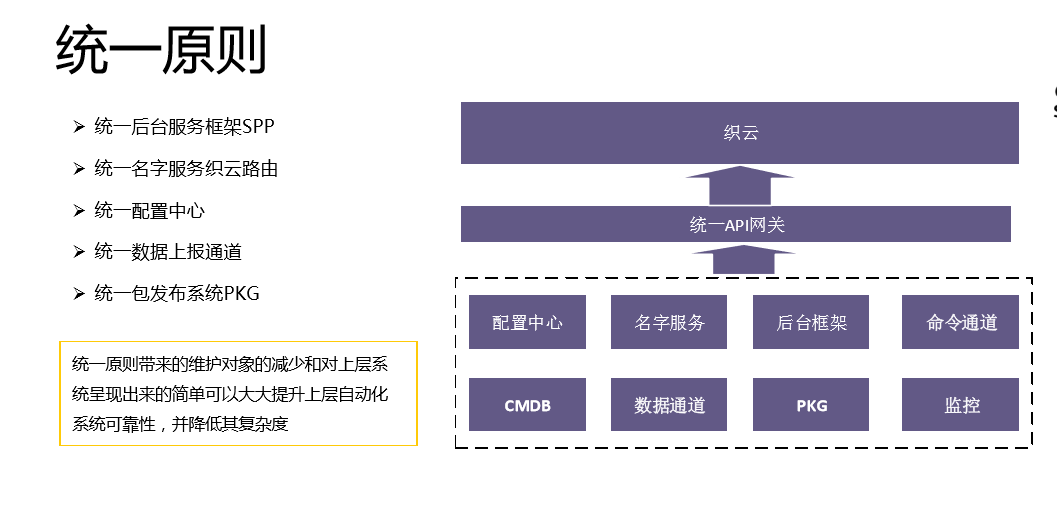
第四个原则是统一原则。
我们有统一后台框架、统一名字服务、统一配置中心、统一数据上报通道、统一包发布系统。这些自动化平台基础,统一是非常关键的,因为统一带来维护对象的介绍和对上层的简单,可以大大提升上层自动化系统的可靠性。我们有一句话,不要在沙盘上建高楼,底子没有打好,自动化程度很难提升上来。
3. 支撑大型活动事件的实践技巧
接下来说一下我们针对大型支撑活动事件的实战技巧。针对社交业务的活动、节假日活动做的事情,是比较个性化的,大家可以听一下,看看有没有什么启发。
我们大型活动的挑战:扩容设备量大、模块多、扩容状态跟进难,你扩容一两个模块还好,有很多模块的时候就容易失败。一个人要扩容一个模块还好,要扩容几十、上百个模块,你发现流程状态跟进很难。留给扩容部署的时间也紧,刚刚过去的2018年春节和红包活动,组件运维团队扩容641次,涉及535个模块,15701台设备,扩容操作要求在设备交付后一周内完成。
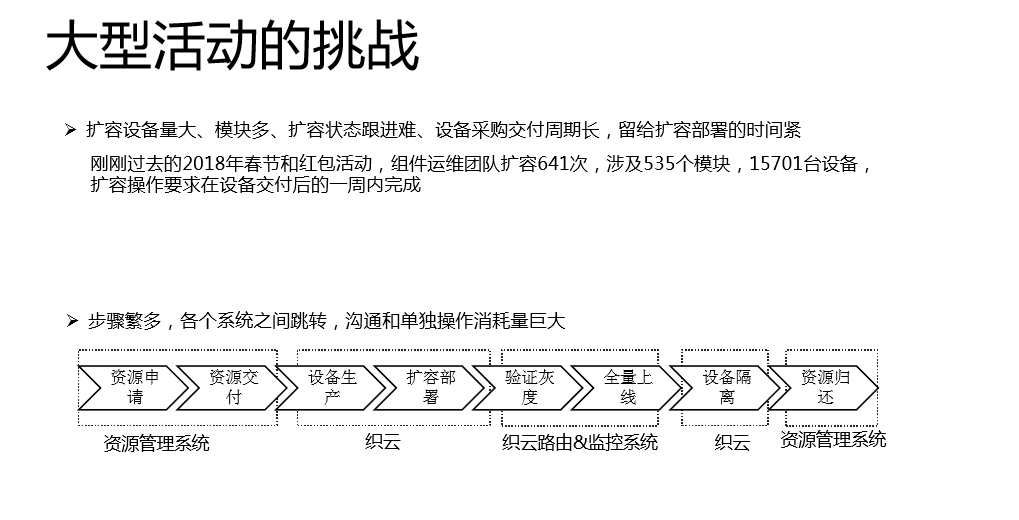
看一下春节扩容的大概流程。首先是资源申请,你要资源PK,然后要去买,要进行资源交付,之后要有虚拟化的过程,设备生产和扩容部署在织云,验证灰度和全量上线涉及到织云路由和监控系统,因为监控的时候涉及到质量,又涉及到织云路由和监控系统的关注。活动搞完了,要下线,要进行设备隔离,整个资源的退还部门要在资源管理系统去做。我们面临不同部门的沟通,单独操作的成本是很大的。打一个简单的比方,当你有15000台设备分配下来的时候,你要把它划到对应的模块,这个事情不用工具去做,人肉去操作都要搞两三天,而且还很容易出错。
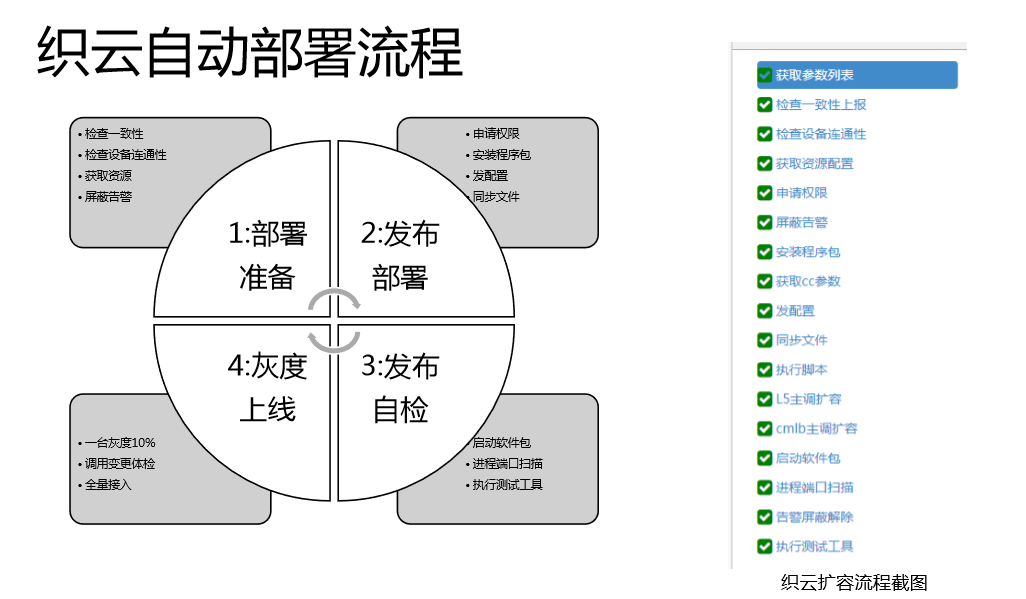
我们织云自动化部署流程:首先是部署准备,二是发布部署,三是发布自检,四是灰度上线。
- 首先是部署准备,检查一致性、检查设备连通性、获取资源、屏蔽警告。
- 二是发布部署申请权限、安装程序包、发配置、同步文件。
- 三是发布自检,启动软件包、进程端口扫描、治行测试工具。
- 四是灰度上线,一台灰度10%,调用变更体检,全量接入。
我们比较好的具备单个服务的自动化部署能力,但是对于我们应对几百个模块的同时扩容还不够。在这个基础上,我们做了批量部署的系统。各个系统接口化,你不管做什么,资源必须具备接口化的能力,对外提供https的接口,系统可以把这些串联起来。
批量部署系统:一是集中展示和管理,各个步骤封装成原子接口,在统一界面操作。二是对接各个系统,比如说哪个模块扩充多少,一开始资源申请的时候这是提供了的,我们根据提供的这些自动生产设备,把设备分配给相应的模块,批量在织云上发起扩容流程。三是规模效应,批量操作上百个业务模块。四是状态自动跟进,我们把关键节点的状态全部记录下来,在统一的页面上去展现,才知道这几百个模块到底是什么样的,完成了多少,有哪些正在进行中、哪些没有到位,把这些流程做了打通。
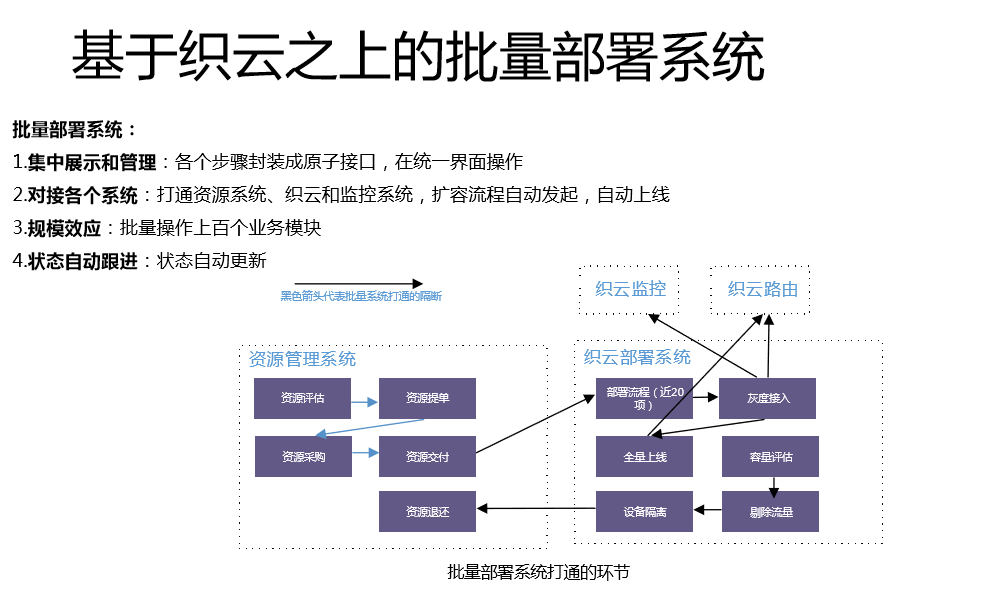
我们最终做到的效果就是能够在一周内把15701台设备600多次扩容全部搞定。春节期间的组件团队,单人最多的时候操纵过2万台设备。

4. QA环节
提问:你们可以识别小运营商的多出口来调度到运营商吗?
张黎明:我们所有中小运营商是通过统一的KAP(音)出口,我们做统一的VIP。提问:小运营商走专门的出口。
张黎明:对,电信、联通、移动不跨网的,中小运营商我们有一个加速平台,走了统一的一个VIP。提问:你们调度是根据机器密度还是根据业务?如果机器现在有问题了,你把机器的流量都切走,还是把理想的流量切到这里来?
张黎明:比如说福建电信原来走深圳电信的服务,当我们一旦发现深圳电信故障的时候,它会调度到上海电信,因为我们三地分部,所以会有一个自动切换到上海电信的过程。提问:根据业务来的吗?它只影响了一部分业务。
张黎明:出口故障是挂在这个下面的所有业务都会受影响,无一幸免的,这个VIP承载的运营服务,我们是多个运营的,都会产生问题。
