@gaoxiaoyunwei2017
2019-04-16T13:57:02.000000Z
字数 5419
阅读 2201
云计算运维管理最佳实践 --- 菅骁翔
北哥
讲师简介
菅骁翔
- 资深技术专家
随着云计算技术普及,基于云服务的应用和云原生应用的规模化,运维管理成为一个新的技术难题。我之前是做虚拟化和软件数字中心定义的工作,加入阿里巴巴后从事基础设施软件管理系统的研发工作。本文将分享云上应用自动化运维管理最佳实践。这是我最近几年的工作想法,希望跟大家探讨在其他领域可以应用的点。
本文内容是分成四部分:
- 云计算时代的运维理念
- 上云阶段的运维管理
- 容器化阶段的运维管理
- 无服务器阶段的运维管理

1. 云计算时代的运维理念

- 首先是DevOps,很热的词,我对DevOps的解读是研发运维的模式,是工作的模式,涉及到开发和运维。开发和运维是两类不同的人,DevOps是让两类人变成一类人。
- 第二个词是SRE,谷歌专门推出了书说SRE。大家是怎么做的?就是把原来的运维部门改了名字叫SRE,并没有什么变化。我对它的解读是运维实践的方式,确确实实会带来很多的改变,跟DevOps是有紧密相关的。
- 第三个词是Cloud Native,这个词是最新的词,我对它的解读是技术架构。
DevOps分解
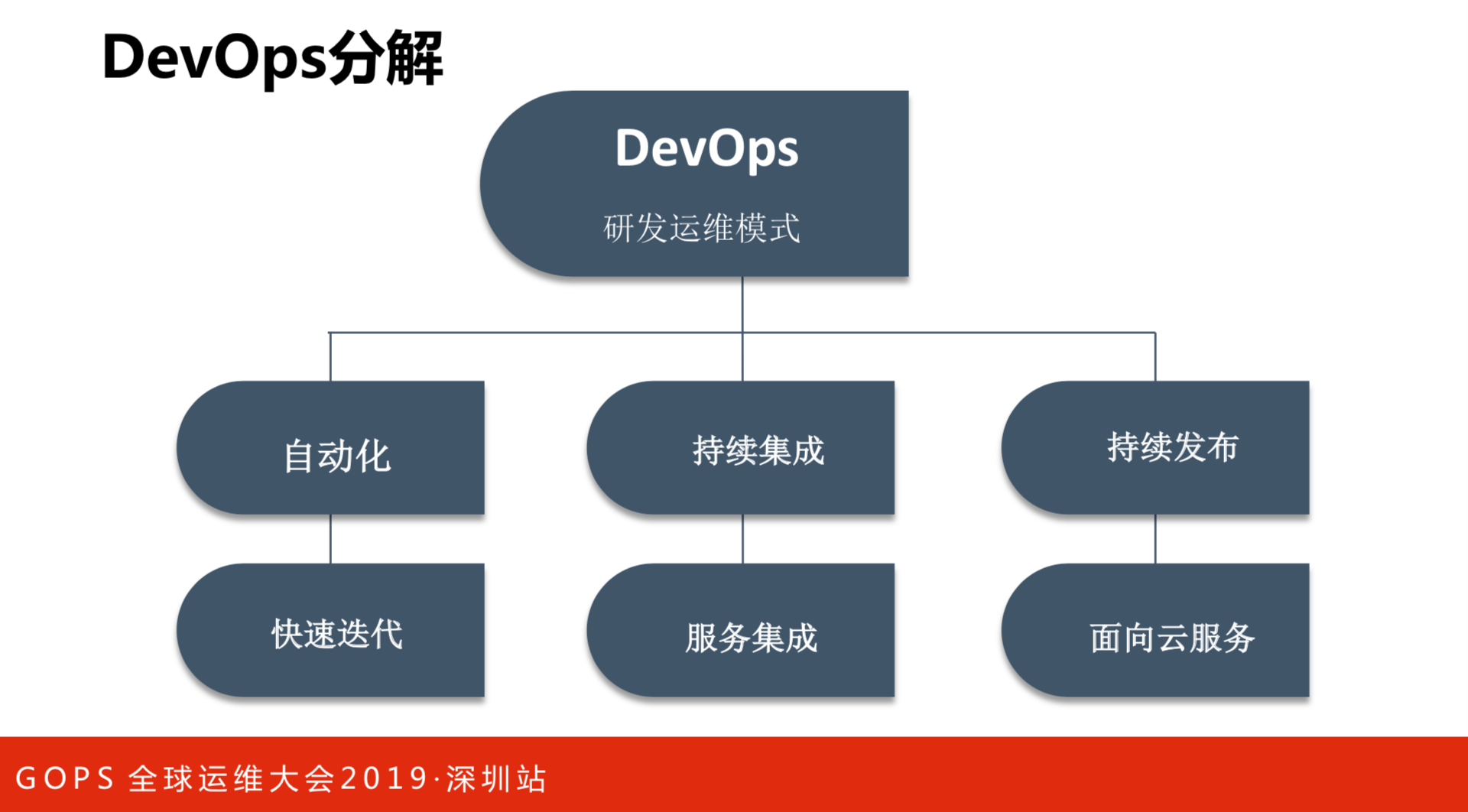
DevOps作为研发模式来说,有三个比较重要的事件组成:
- 一是自动化。整个环节都要做自动化,目的是为了快速的迭代。当把开发和运维结合起来,就是为了让过程变得足够的敏捷。
- 二是持续集成。持续继承和持续发布是DevOps里面非常重要的东西。持续集成过程当中要把所有的服务集中起来,阿里巴巴内部的系统,随着时间的演进,很多系统的纠葛会非常多。新办法上线的时候要跟老版本集成测试,还能不排斥。
- 三是持续发布。需要不同的环境解决,不可能全部铺满。我们部门用的时候,是把云的资源作为基础的测试环境用的。我是基础设施团队,管理的是物理机,测试环境要模拟那么大的规模就比较麻烦,因此就用了内部云服务,去模拟超大规模的环境。
在DevOps过程当中,实质上是归结到快速迭代、服务集成和面向云服务。
SRE分解
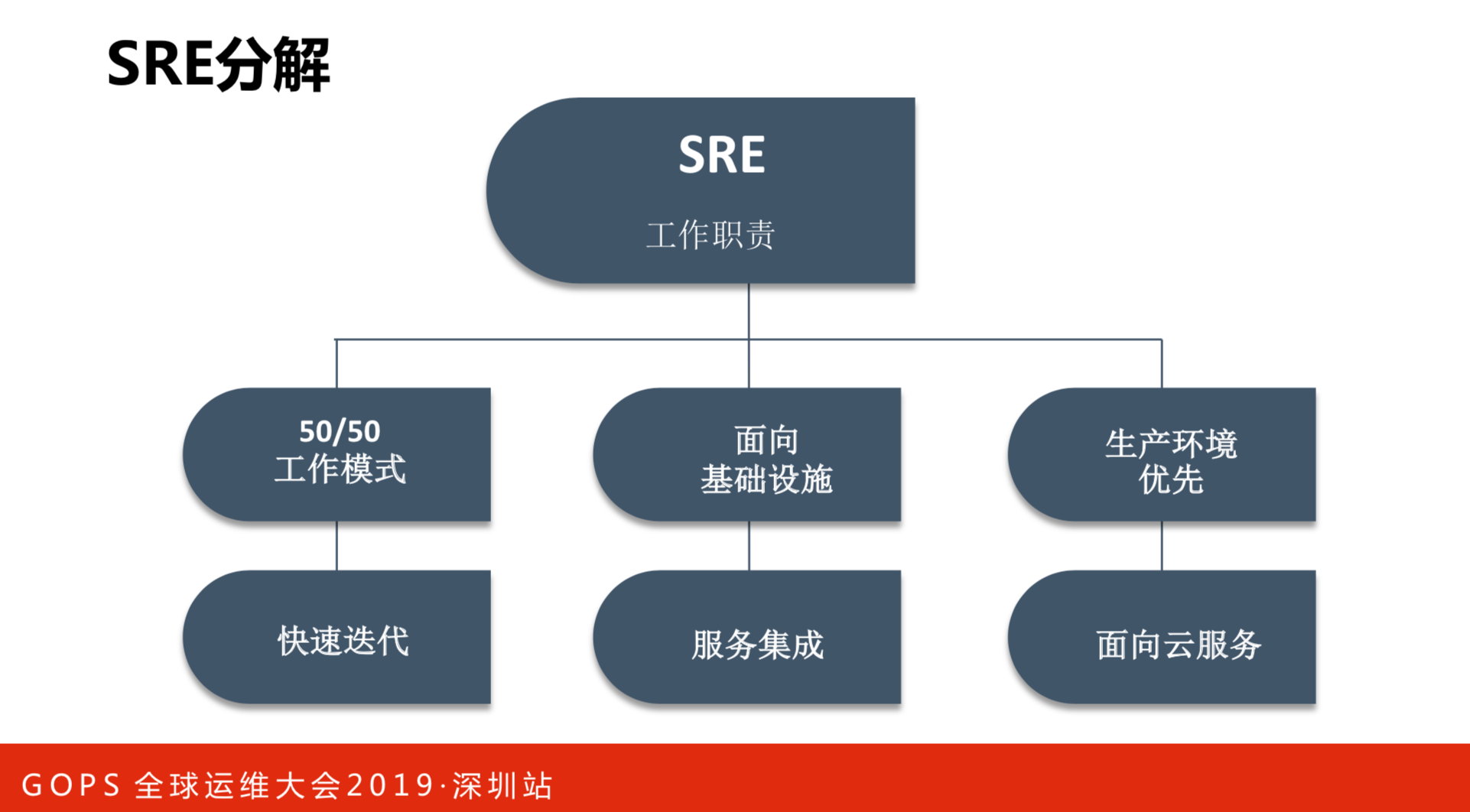
- 工作模式。这跟运维不一样,运维是要做变更、容量规划和环境检查等系统性工作师做的工作,而SRE50%工作是要做研发。从我们的经验上来看,这是一个非常重要的原则。DevOps最后落实到实践,在我的团队里面,研发都是要做线上运维的。当然,开发的时间不会低于50%的工作比例。这也是快速的迭代,如果出现问题就马上修复,有新版本也能马上上线。
- 面向基础设施。分为两个方面:SWE是软件研发,SRE是面向基础设施。基础设施不仅仅是服务器,更多的是中间件、软负载等基础服务,最后都把它形成基础设施,越做越厚。要做那么多开发工作,就是因为基础设施的服务集成工作越来越多,更多是软件的工作,而不是传统环境下做文件传输这种简单工作。
- 生产环境优先。作为SRE来说一定是生产环境优先的,要面向云服务,所有的服务就是对外的云服务。做的任何操作都有可能会对服务有所影响,这就要在系统层面设计上让整个过程更加安全。我们是做了很多的工作,人只是发起一个指令,所有的执行是由程序来完成的。
Cloud Native分解
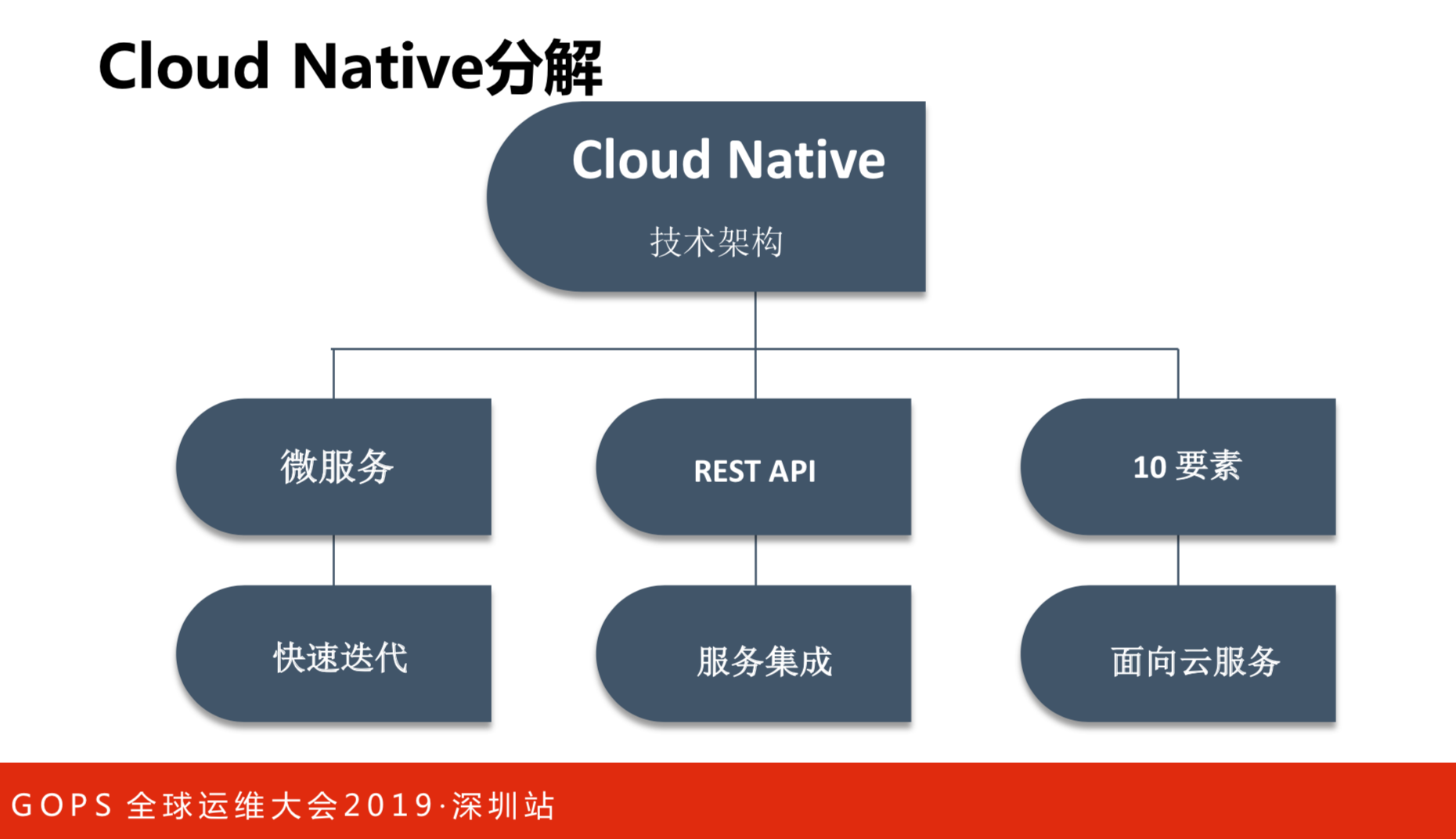
Cloud Native的目的是为了快速的迭代,终极的目标是让大家的研发效率越来越快。服务的交互,推荐大家用REST方式。REST的目的还是服务,要考虑服务之间的集成。
Cloud Native是什么呢?比较官方公认的是谷歌总结的“十要素”结构。要把这些技术架构落实下来,更多是云服务的技术能力,让用户用微服务的方式做最关键的事情,而不是重复的基础设施和基础软件的开发,这是我对CloudNative基础架构的解读。
总结下来,我认为在云时代里,将快速迭代,通过服务集成和使用云服务的基础设施,把我们提供的服务能力变成服务形态并把集中起来,统一对外提供最终业务的结果和业务形态。
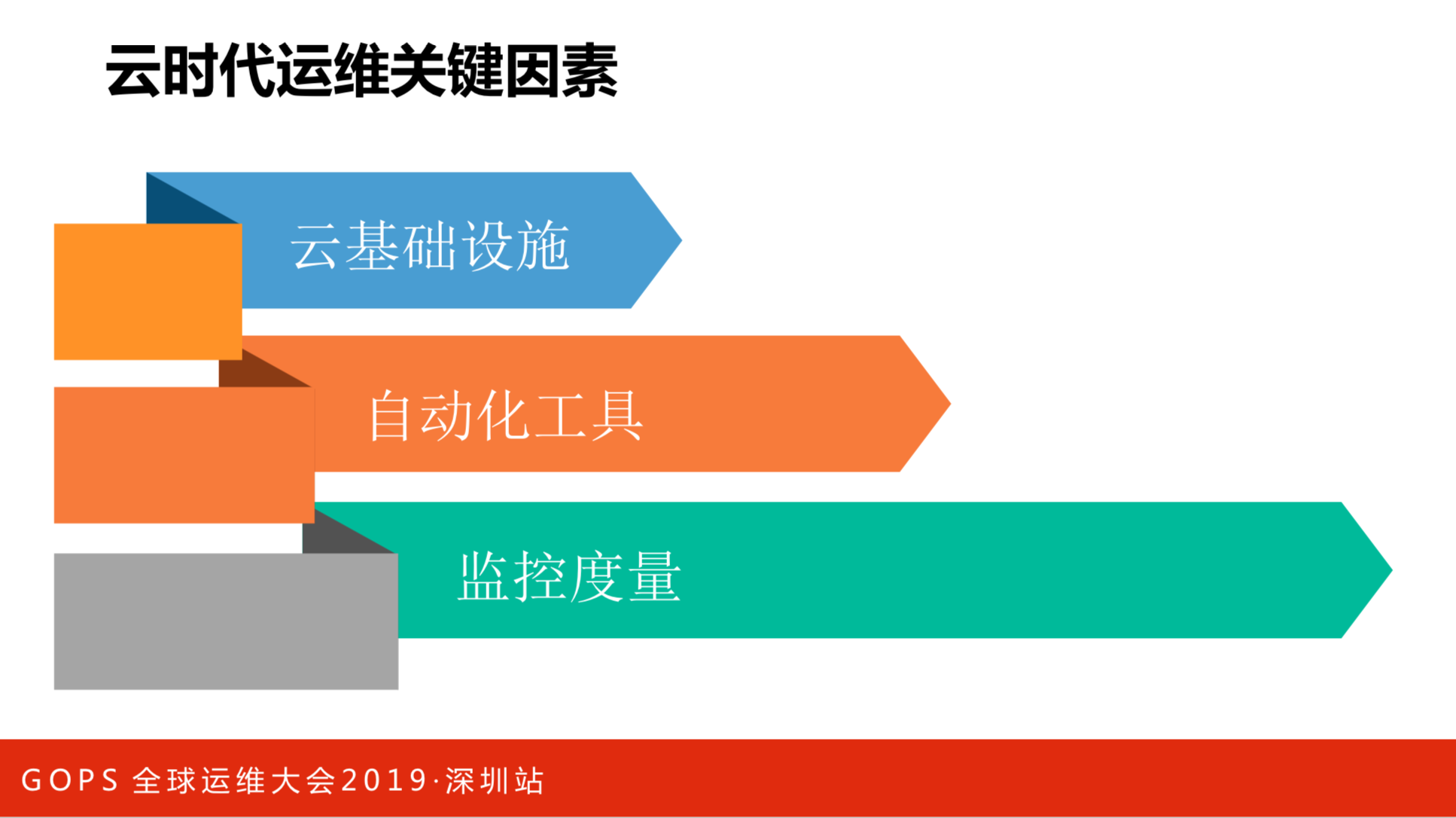
云时代运维关键因素
云时代运维的关键因素分三部分:
- 云的基础设施。亚马逊做云的时候是为了解决在研发项目里面,60-80%的时间不是在研发,而是在准备研发前期的基础资源的问题。基于这个思路就慢慢提供云服务,至于后期不断的推出云产品,都是围绕着这个思路在做的。就相当于我们在上层应用里面,中间件和业务的技术组建都会纳入到基础设施里面。
- 自动化。所有的服务要组装起来的时候,大家都会考虑自动化,特别是当服务越来越多的时候,靠人管理是来不及了,必须通过自动化的方式来进行管理。
- 监控和度量。最开始的时候,大家觉得监控看服务状态是很自然的事情。但是,当服务规模,特别是用微服务、云的时候,需要管理的东西会越来越多。如果反馈不及时,导致自动化做完了,可能得到完全不对的结果。
这三点不是孤立的,需要联起来看。我们要考虑把所有的基础服务纳入进来,还有把所有的监控和度量的结果注入到自动化的过程当中,而我们的监控和度量是围绕着基础设施和自动化来做的。
2. 上云阶段的运维管理
云基础设施服务
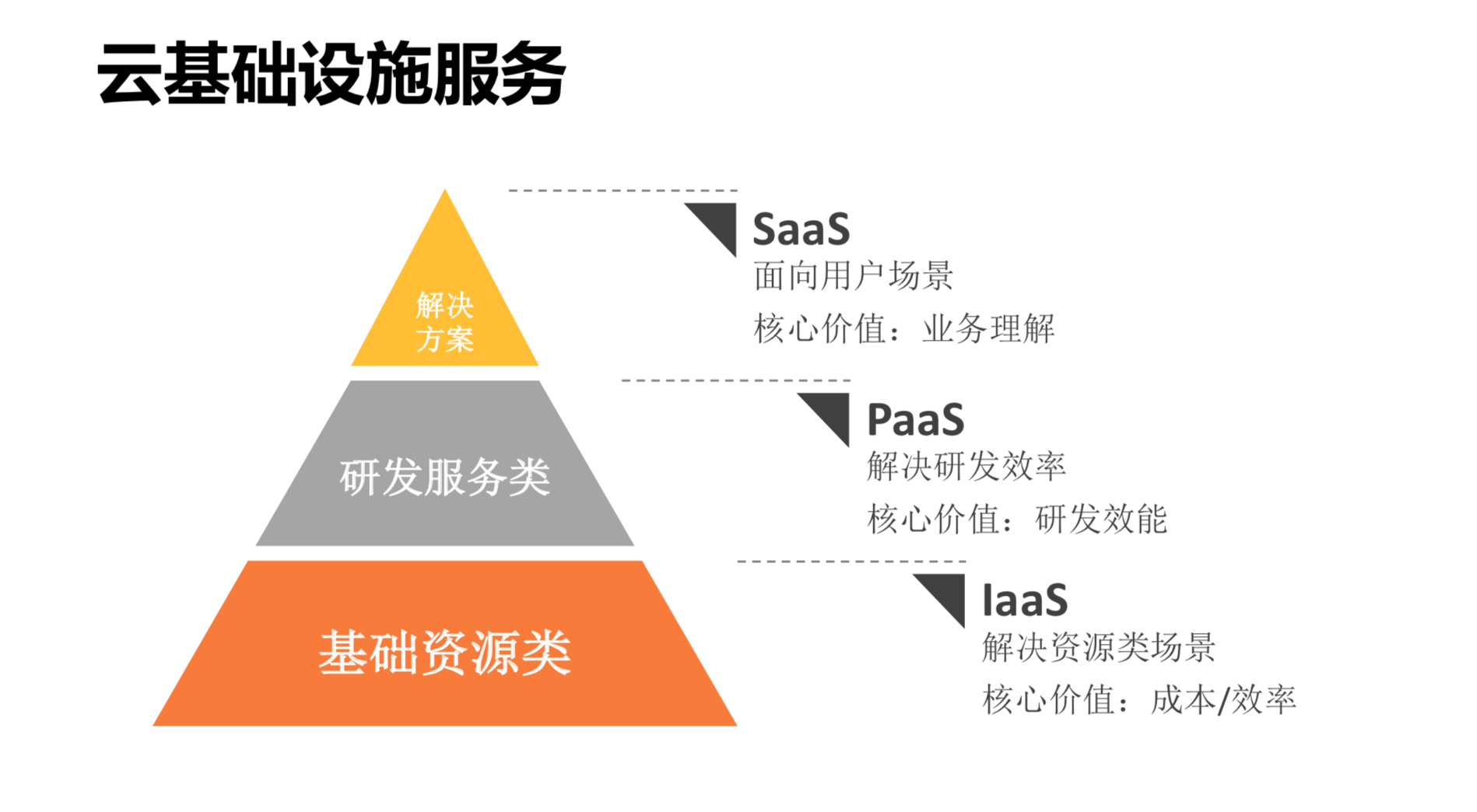
对于云设施,最开始通用的东西是基础资源。大家刚开始接触云的时候,解决的都是资源类的问题,核心价值就是成本和效率。
如果一个云的成本和效率赶不上自建的话,就没有意义了。在这里最主要是规模化解决成本和效率的问题,就是超大规模的集群,我们的服务都是自动化的,这样可以保证整体的成本和效率是远远高于用一个小规模的自建系统。
解决完资源场景之后,就要考虑研发效率如何提高,这也是后来开始尝试容器的技术,还有把硬层的东西用到容器化上面。
最上面是SaaS类,这个是行业解决方案。每个行业里面,细分场景会有很多的不同,并不是互联网技术就能解决银行的问题。每个行业的业务理解是不一样的,因此方案是不一样的,需要一些定制化的内容。基于这样的思考,我们的策略是在IaaS层通过规模化解决。
自动化工具

- Infrastructure as Code
系统规模变大了之后,你靠人是不太容易的。我们自己在实践的时候,有几百台服务器,想自动化管理,这个很好解决。当规模超过几千台之后,就会遇到一些问题,比如说做一些操作的时候,你想的和你的结果并不一样。我们一开始尝试用自动化的编排做,但是遇到失败的时候就解决不了。我们就通过描述性的语言,人期望是怎么样的,由系统把所有的操作做完,人只关注这个有没有做完。还有一个是不可变,它是很反直觉,很多人设计基础设施的时候,是考虑把一个系统先做一个操作,后面又做了一个操作,比如先把系统装好,一层层把系统交付出来。这个是很容易自动化的,但是它是可变的,特别是随着时间的推移。比如我有几百台的环境,第一次交互的时候是一个样子,过了一个月,上面已经做了很多次的变更,过了半年之后,再想知道这些环境的每台机器是不是我想的,就变得非常困难。这时怎么办呢?大家的做法是每次操作的时候要做一个编程,后面就越写越复杂,最后就没有办法维护了。我们使用简单粗暴的方式,就是每次交互之后不可变了,想变的时候就整个抹掉,从头再来,这样来保证环境一定是跟我想的一样。当然,我们是在物理化运作,大家可以用虚拟化和容器技术来做,考虑设计环境的时候,特别是规模大的时候不要设置可变的模式,因为后面运维的灾难是没有办法考虑的。
- 规模化和可扩展
规模化是对系统的评定和面临多大规模的问题。我们经常会发现,在面对同样一个应用,部署在100台、1000台极器、1万台机器和10万台机器是不一样的。还要可扩展,特别是上云的,可以用开源,这样就有第三方的服务能力集成进来。这需要有研发的团队来维护这些扩展能力。
规模化管理设计思路

这是规模化设计关键点,也是我们在过去阿里云最开始到现在系统设计考虑的问题,就是强制性和弱一致性的处理。
大部分的服务模块在设计的时候,大家都愿意用强制性进行处理,因为编程比较简单。以运维来操作,大家的想法是我有1万台机器做操作,能顺利就成功了,不顺利就再优化。不好的地方就是运维成本太高了,有的机器行为不一样。我们最初是通过“黑名单”来解决这个问题,发现不一样的,就删除它。在5000-1万台的时候是可以的,当超过1万台之后,就不好用了。就算不用处理那些失败的机器,加黑这个操作的成本也很高,第一次尝试的时候,有2台机器不一样,之后又有2台,可能得重试几十次才会达到自己想要的结果,这个成本就又太高了。
后面我们考虑用另外一种方式,首先,有些东西不一样,没有关系,但是应用系统设计对其他的依赖性没有那么高。这种方式的坏处是,一旦有关键数据发生不一致的时候,处理成本会很高。在运维领域,运维和应用不一样,超大规模的应用没有什么,做运维的场景规模会远远比一般的应用要大。那我们怎么办呢?就是强一致性和弱一致性在一块,用了折中方案。百万级的服务器是弱一致性的,能持续从控制节点获取信息,让它在希望的状态逼近,通过这种方式来解决状态一致性的问题。这是我们最终的方案,行业内也都是这么实现的,把控制信息写到ETCD,只是大家在选择具体的协议处理上有所不同。
监控体系设计
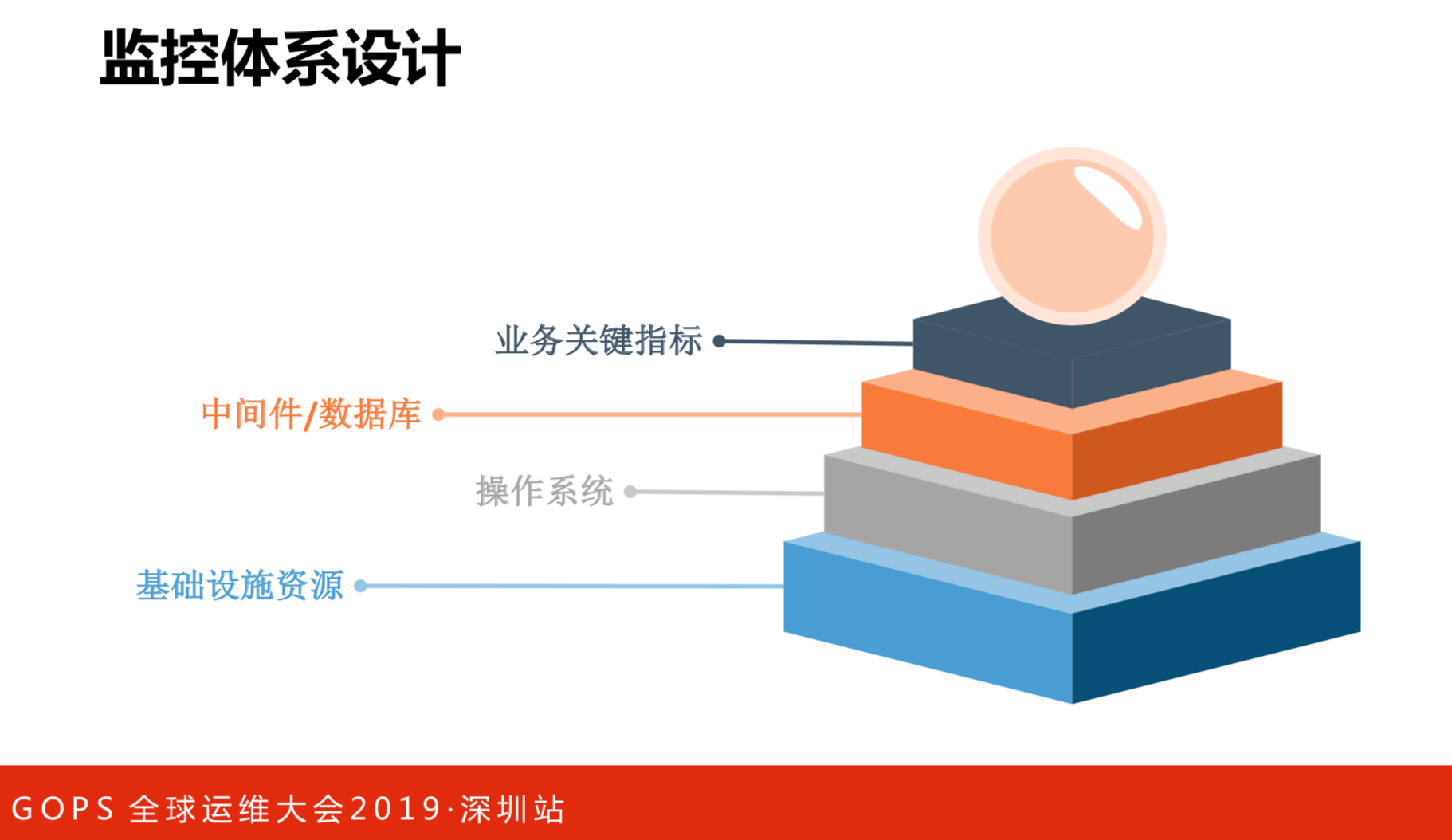
当讨论监控的时候,总会发现有很多的意见和建议,就是监控应该怎么做。我们的经验是监控要分层做,最开始是垂直做的,每个业务线自己做,所有的东西从头到尾都要做。现在是每层有自己的专业性,包括什么是健康,什么是不健康。每一层都有专门的团队做专门的系统,但是我们把数据共享,每一层都做得很专业。最上面的业务观测者是拿下面每一层的业务度量它的健康度。这里没有好的想法,只能告诉大家做的时候,每一层定义基础设施健康度考虑,比如说机器的健康是怎么样的、操作系统的健康是怎么样的。它没有行业通用的方式,在公司内部不同团队承诺SRA,把所有的放在一起,对系统健康和出问题的时候快速定位,通过这种方式来解决。
监控方法USE

U.S.E是行业比较好的监控方法。U.S.E就是资源使用率、饱和度和错误事件的记录率。它是对所有资源类型的,一定要围绕着这三个方向去做监控。
监控方法RED

R.E.D跟U.S.E是不一样的,R.E.D是面向服务的。我们把所有的服务分层了,关注的是基础设施和PaaS两层,这是描述我们在服务层关注什么样的信息。这个方式对各家公司都是适用的。
3. 容器化阶段的运维管理
容器化时代的变化

在容器时代,主要应用了两个技术Docker和Kubernetes。
Docker是非常好的打包方式,但是怎么运维?一旦容器挂了,里面的日志和信息怎么拿出来?交付是很简单,官方提供了很好的方式,监控也有很好的方式。很多人讲不同的运维方式,还是监控和交付的问题。
Kubernetes是很好的管理模式,我们尝试过用别的技术交互整个环境,后来发现还是Kubernetes比较好用。但是,没有人告诉你应该怎么运维,如果节点坏了怎么办?
问题诊断

Docker怎么运维?
有两种方式:改变应用研发模式和改变宿主机管理模式。官方建议改变应用研发模式,你的应用应该按照一定的原则,把所有出问题的点打到日志,通过日志收起来解决这个问题,你的信用评价都是可以通过监控收集的。我们把宿主机的方式改变了,通过主机的程序直接切到容器里面,对于运维操作的人来说,体验跟原来是一样的。但是,这是需要在主机上注入一个自己的管理程序。Kubernetes怎么运维?
有两种方式:Sidecar模式和CRD扩展。我们最开始是通过Sidecar模式,就是定义了几种容器,比如日志收集、容器登陆,挂在特殊的容器在上面,还写了一个程序来控制。这也是有问题的,就是这种方式怎么保证注入东西的质量,还有控制的环境影响周期的时候,控制程序的质量非常的重要,稍微写得不好,线上的就挂了。后面就改用CRD扩展的方式。它和Sidecar很像,唯一的区别是用Sidecar扩展的方式做的。只一个团队在做这件事情,其他同学通过加一个自己的资源类型,将运维的容器注入到里面去。
监控与日志

监控与日志,按目前现状来说,容器化是最好的,后来发现扩展性和数据存储是有问题的,我们自己有内部服务来解决。在不同的云服务上有别的服务来解决时间序列的存储,还有多集群的管理和指标,我们都是通过协议来做的。日志是需要统一的收集、存储和搜索,阿里云有一个服务,就直接用云服务去做。
4. 无服务器阶段的运维管理
无服务器技术带来的变化

无服务器是现在尝试的,没有真正的线上用。目前是比较好的一个方向。
- 什么是无服务器?
就是没有人使用,则没有除数据存储外的开销。另外一点是可以隐藏掉一些基础的产品。云的服务越来越多,就可以抽象出来更多的基础能力,开发的能力是不需要知道的。 - 无服务器的特性
不需要维护计算资源,还有事件的驱动,当没有请求的时候,是不用维护原来的计算资源的摊销。基于使用计费以及自动扩容都是在服务端解决的。
无服务器阶段的运维工作

在无服务器的基础领域,运维工作非常少,最主要的工作是设计最佳系统架构,基于云服务组装,这个架构该怎么设置。另外是监控系统的可用性,无服务器平时没有请求的时候是没有资源消耗的。还有可用性怎么监控?以及性能调优和成本的优化,无服务器请求的时候,是没有那么多的资源在那儿的。这些都是运维最需要做的事情。
云计算运维模式演进
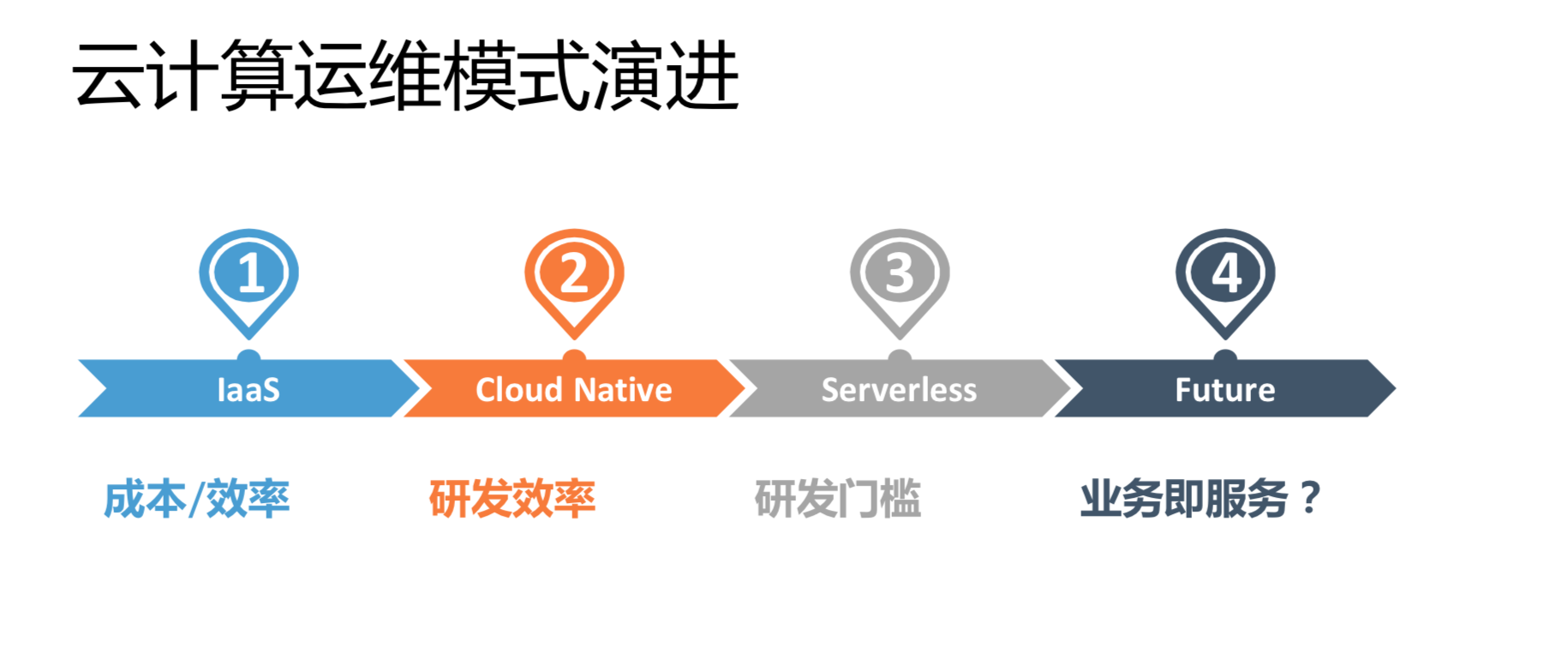
总结一下,我们认为云计算时代的运维模式的演进,最开始大家用云的时候是为了解决资源问题,就是成本和效率的IaaS问题。随着技术的发展,PaaS是要解决研发效率的问题。Serverless应用能降低研发门槛,业务变得很快,让它完全变成用业务语言描述的东西,就能极大的降低运维门槛。再往后是什么样的呢?我们现在还没有看到特别明确的趋势,可能任何服务都会变成业务化的模式。
