@gaoxiaoyunwei2017
2019-04-29T08:06:40.000000Z
字数 5657
阅读 1467
技术驱动娱乐-直播平台运维保障实践
白凡
分享:张观石
编辑:白凡
我是张观石,来自虎牙直播,我在虎牙直播负责业务运维的工作。我们业务的技术怎么驱动平台的稳定性?主要的内容
首先,直播音视频传输的总体技术架构和挑战;
第二,稳定性保障能力概述设计与分析能力;
第三,全链路监控感知能力和直拨质量指标;
第五,可靠性工程思考。

1. 直播音视频传输的总体技术架构
直播的架构,主播用开播设备打开一个软件,软件要推流、转码、录制、截图等等,有P2P还要去做切片,然后再整个分发网络去分发,在观众端用手机打开来看。看了之后就是端上收流、解码、渲染、播放。但是,如果有很多很多主播开播,很多很多观众看直播确实不太一样,虎牙很早就做了混合云的架构。这是一个简单的架构图,我们有自己的传输网络,也用了多家CDN的网络传输,我们把多家CDN网络与我们的网络组合成更多的网络。一家主播推流会推多家网络里面,我们的观众可以到任何一个线路来看,观众是可以选择线路的,后台用几个调度。很多主播和观众的情况下,组合很多,从成本的调度、质量维度的调度,怎么做到调度的实时性是有挑战的。
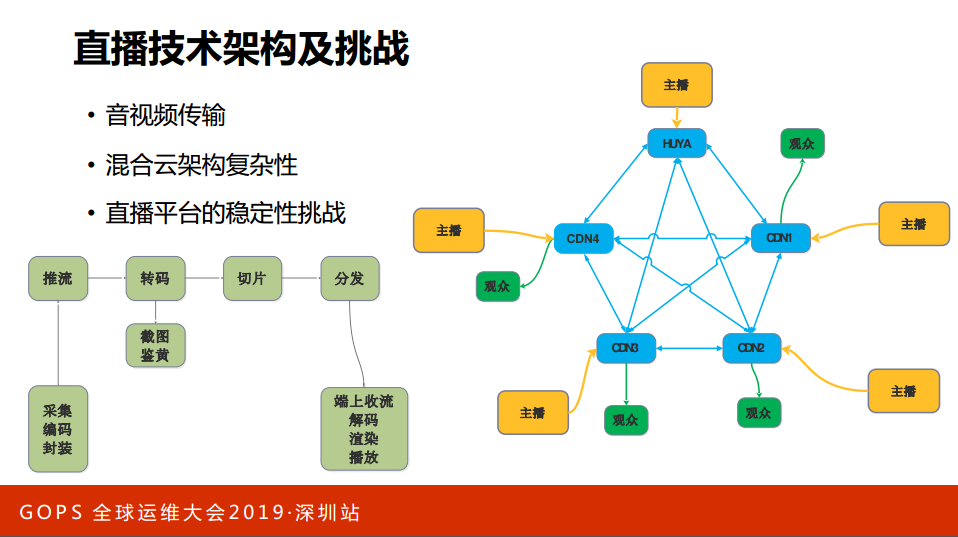
我们看一下单个主播直播的情况,一个主播会推到一个CDN在多云里面互传,在云里面有不同的分发商、不同的区域,在这里面的链路比较长,链路都是实时的,不管哪一个点出现问题,这个点是全局的,这个点可能是局部的观众。在实时量大的情况下,怎么能够保障它的质量其实也是有一定的工作量,当然卡顿有很多种卡顿的原因,有可能是网络延时,有可能是丢帧,看不了直播或者卡顿的情况有很多种。上面说的那些其实每家直播平台都是这样的,直播真正的技术挑战是在哪里?
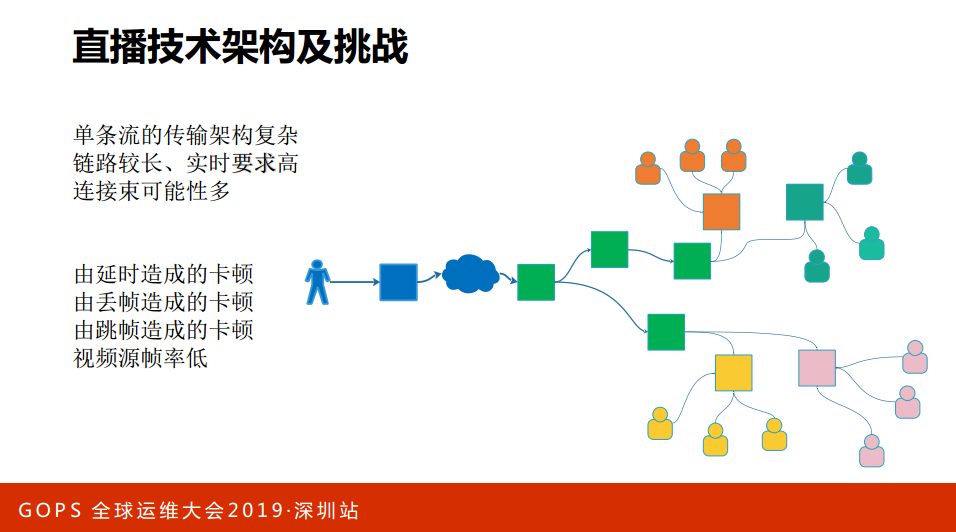
第一,与WEB有一些差别。WEB的服务都是打开浏览器来访问服务端,这是浏览器到服务端,浏览器是标准化的东西,很多时候可以重试,端到端,主播端是到后台再到端上,链路长很多,而且是实时的。所以与WEB有些差别。
第二,对网络的要求不太一样,网络是飘忽不定的,软件也很多,安卓软件很复杂,甚至有安卓TV的。所以对网络的要求非常高,上面用了一些技术栈,开播的方式有很多种,直推或者其他的,转码有档位,蓝光等等什么的。我们做平台怎么去掌握CDN的一些质量也很关键,观众端也有很多种类型。

直播界也有双十一--英雄联盟全球总决赛,去年是S8,今年是S9,去年中国得了冠军以后非常火爆。4个最高:最高荣誉、最高含金量、最高竞技水平、最高知名度的比赛,每次观看的人比较多,对带宽的要求也比较多。

5G时代来了,5G时代来了之后对我们整个运维、互联网应用和生态都会带来很大的一些变化。在4G时代,我们看直播还不错,但是5G来的时候可能会在整个的互联网,甚至不止叫互联网,甚至在很多的生活场景用得更多,不管是做直播或者娱乐的,什么AR、VR,今天这么多互联网的直播,将来在5G的时代直播的效果可能会更好,可能会做一种全新的直播。应用场景也很多,5G有一个很大的特点:高带宽、低延时,在一万平方公里里面有很多的连接进来。将来的连接终端或者整个的网络会更复杂,直播平台会更大,所以今天讲直播的保障,将来在5G时代也是一种探索,对我们也是一种机会。

2. 稳定性保障能力概述&设计与分析能力
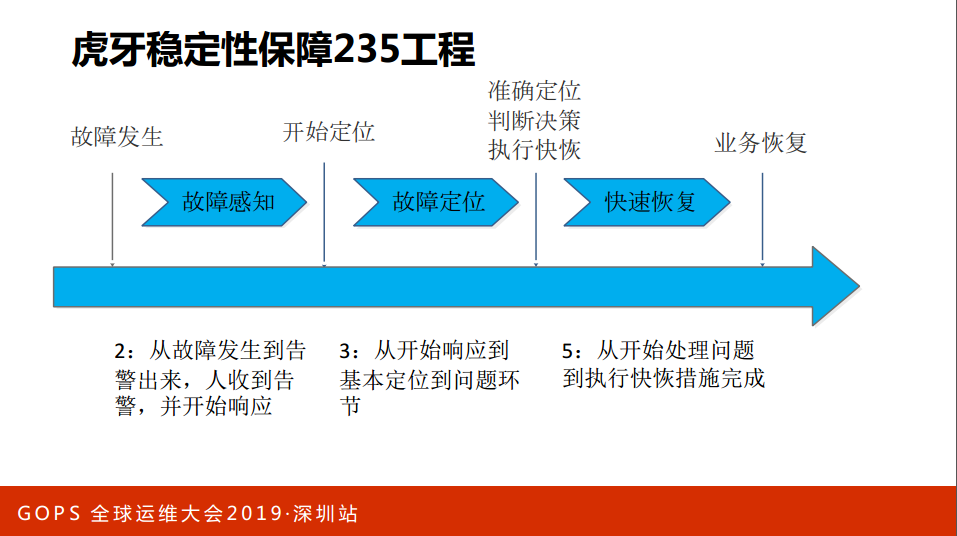
接下来讲一下稳定性思考的一个能力框架。我们今年重点要做一个稳定性保障的工作,我们提了一个“235工程”,“235工程”是什么?从故障发生到发现有两分钟,从故障到响应到定位3分钟,从定位到处理(执行快速的手段)5分钟,“2+3+3就是10分钟”,10分钟的要求是否高?其实挺高的,每个阶段发现问题到处理问题10分钟,但是距离要求特别高吗?不算特别高,10分钟的故障,如果经常出现这样的故障要10分钟处理,整个平台也是受不了。我们怎么样来保障稳定性呢?是不是像达摩克里斯之剑,剑掉下来整个人就挂了,我们头上是网线,保障光纤不死机就是稳定的,一定不稳定就死掉了。靠我们的努力,靠佛祖的保有去保障临时的稳定性。现在也有很多新的运维方法和新的理念出来,AIOps、DevOps等等。
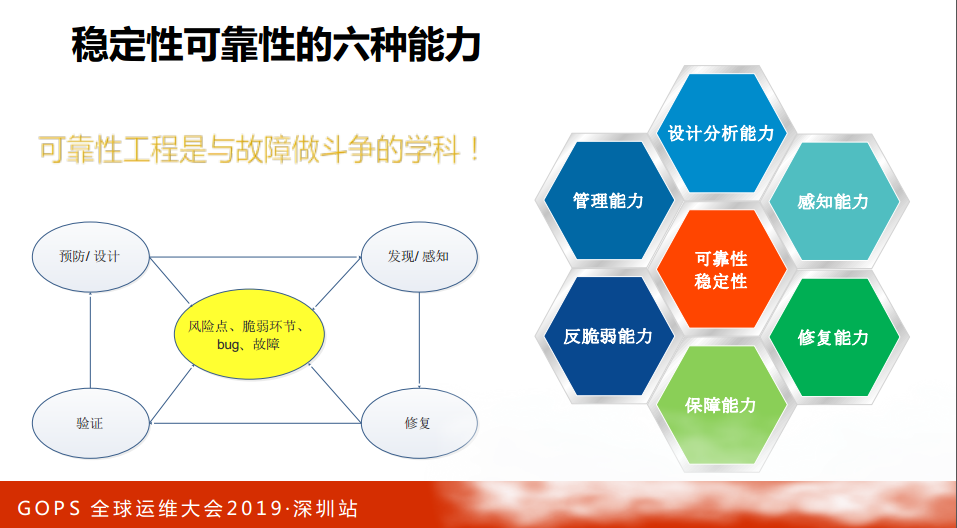
天龙八不里面有一个角色我很喜欢,鸠摩智,为什么呢?他很像技术的成长,各大门派都有,勤学苦练去学会各种功夫。学会了就能解决稳定性的问题吗?我们的稳定性就会好了吗?有可能学了很多走火入魔。但是鸠摩智最后的结果还是比较好的,他的结局是什么?进魔之后武功尽失,但是最后觉悟了开台演讲。可靠性和稳定性工程是与故障做斗争?怎么做斗争呢?我们要研究它故障规律,去预防它,纠正它,再解决这些故障,这是我们稳定性保障的本质。

我们看一下与故障做斗争的过程是怎么样的?
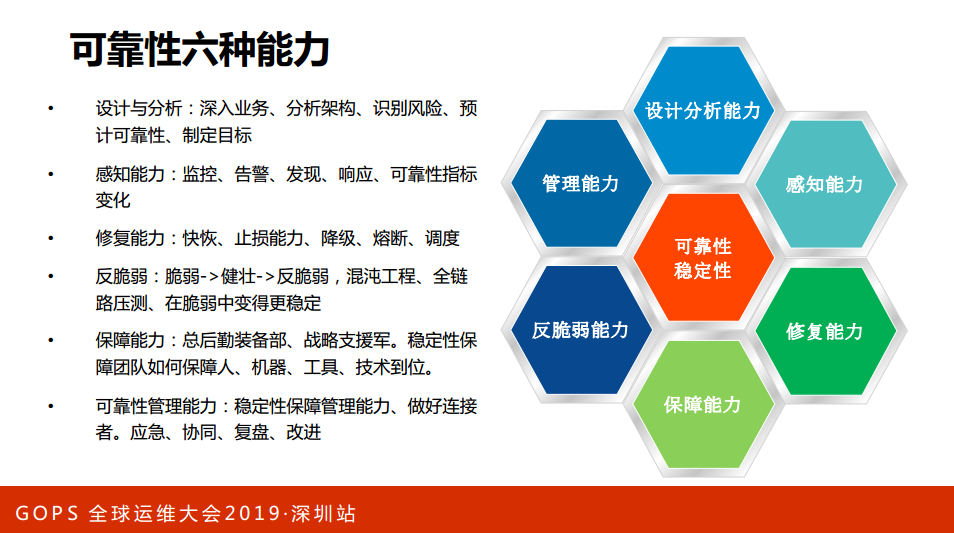
首先,从设计上去避免这些故障,做高可用的架构去预防这些故障,当故障有风险的时候去感知它,发现它,发现它之后要修复这些故障,修复故障有可能是临时的或者长期的,修复之后要做验证,验证就要重新做驱动设计、改进设计,形成一个闭环。这是整个与故障做斗争的过程。在这个过程里面需要哪些武功,提炼出六种能力:
第一,设计与分析能力。怎么去设计与分析我们的业务架构,业务架构包括研发的架构,这种架构有可能是业务研发来做的,我们运维也有架构,系统架构、基础设施架构、部署架构可能是我们运维同学来设计的。
第二,感知能力。我们分析架构去识别里面的风险点,甚至反向驱动改进我们的设计,在分析里面分析质量设计(成功失败的数据),分析过往的故障提出可靠性的目标(SLI或者SLO),这就是感知能力。
第三,修复能力。有了SLI、SLO之后怎么做监控、响应、警告等等,我们把这一块定位为感知能力。SLI、SLO去做监控、定位等等都是感知能力,修复能力,出现故障之后要修复,修复怎么去修,靠人跑到服务器里面或者跑到系统点一键去修?修有很多的学问,这个系统能不能修,怎么去修?比如说容量不够怎么去扩容,是否有隔离,是否有工具。
第四,保障能力。保障能力拿一个类比来说就是后勤装备部或者战略志愿军的一个保障。这个保障是有我们的资源交付是否是实时到位,资源和能力是否够,是否能实现实时响应或者快速响应,我们的技能和工具是否到位。
第五,反脆弱能力。我们的业务总是很脆弱,网络很脆弱,业务发展总是面临很多脆弱的环境。阿里是这样,刚开始及百亿、几千亿,出现故障或者问题之后是怎么修复,或者出现了问题改进设计或者提升,不只是扛住这个业务,不止是加强尖锐性,而是提供一些主动反脆弱的能力。
最后,管理能力。我们的业务涉及很多很多的服务器、架构、变更,包括故障,怎么把这些串联起来就是管理能力。
故障生命周期:发现故障、定位故障、解决故障。放大细分一点可以分为十几个阶段,不同的阶段可以做不同的事情。
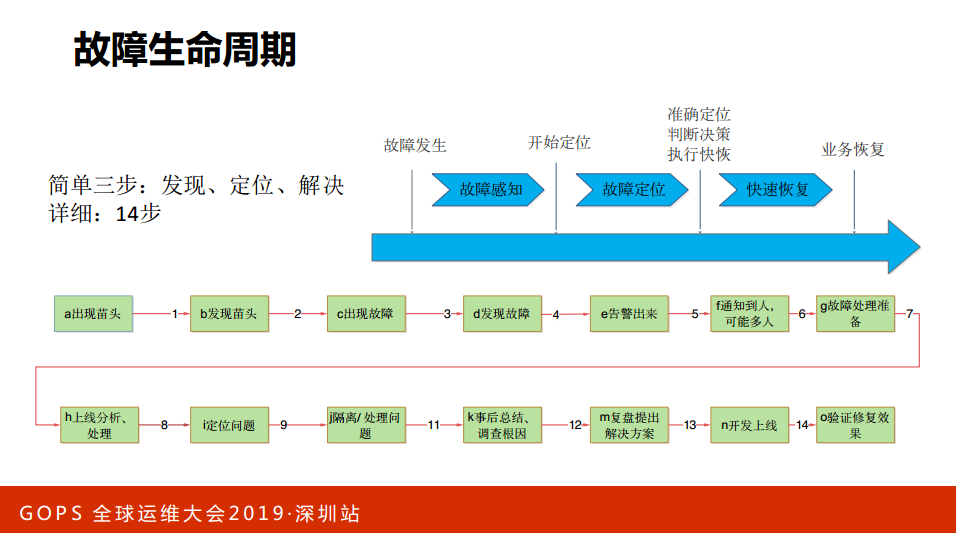
再讲一下六种能力里面的设计分析能力,我不知道大家做运维会不会参与到架构设计里面,或者对研发团队是否有一些影响的能力。在我们团队,我会要求大家首先要知道业务的架构、熟悉业务的架构(画出业务架构图),这个业务架构图就是我们的同学画的,对于业务架构比较熟悉了解之后才能熟悉里面的风险,才能够知道里面的问题,比如说做系统架构、部署保障的时候才能够有的放矢,才知道问题在哪里,甚至我们会肯定业务的架构。
做设计的时候有五个错,首先叫知错,大家是否有能力去知道它造成哪些问题,设计的时候要避免错误,要容错、查错、改错。有些架构是我们自己来设计的,右边是重磅流的一个高可用的保障,由我们来设计的。
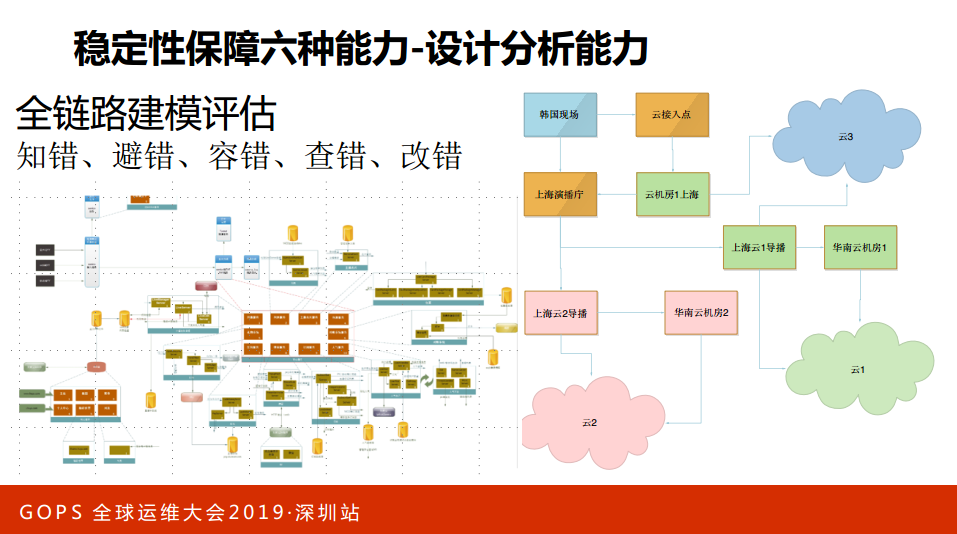
3. 全链路监控感知能力&直播质量指标
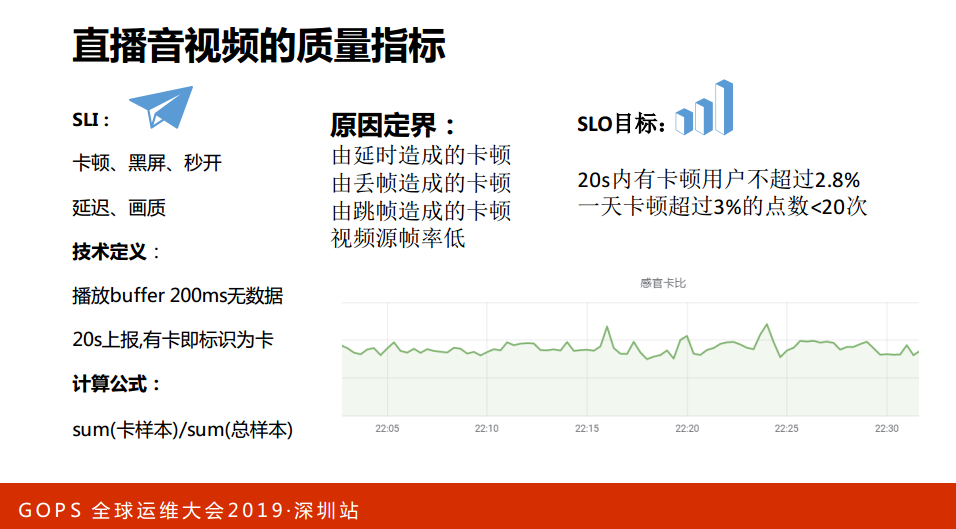
这是质量指标,刚才讲到识别、设计和分析能力首先要有质量指标,质量指标就是对SLI以和SLO,这些指标对于大家定量分析质量确实很重要,原因定界由眼时造成的卡顿、丢帧,我们一起分析过往的数据,目标是什么?定一个指标去确定目标,朝着指标去做六种能力:感知能力、修复能力等等。
有了这些质量以后,运维数据-维度+度量,有了卡顿、黑屏、秒开的数据,其实还会带很多的维度信息,比如说主播的、观众的,数据来源也有很多,我们自己的服务器断了,CDN的或者事件的各种各样的数据,我们会与端上做打通。端上在早期上报的数据比较少,后来我们一起来做这件事情,大家尽量把数据一报上来,我们来做同样的分析。
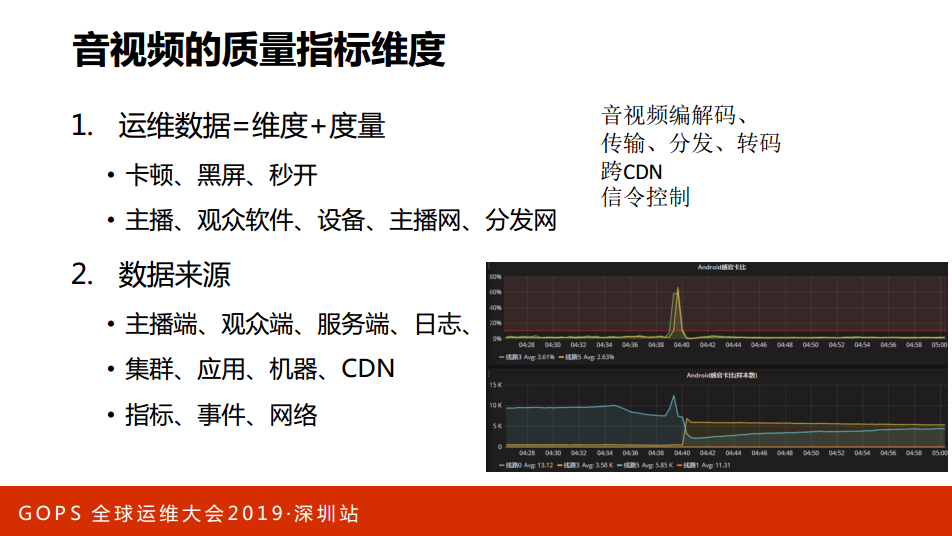
这就能感知到质量的变化,出问题也能快速知道。运维数据很多同学可能觉得运维一致那些东西,可能会把我们的磁盘填满这些问题,数据是非常重要的资产,对于业务来讲是非常重要的资产,能够把数据利用好,这是对运维在整个团队里面的定位会有很大不一样的地方。
这是我们上报的一个架构,有各种数据的上报报告,有端上的上报,有Agent的上报.
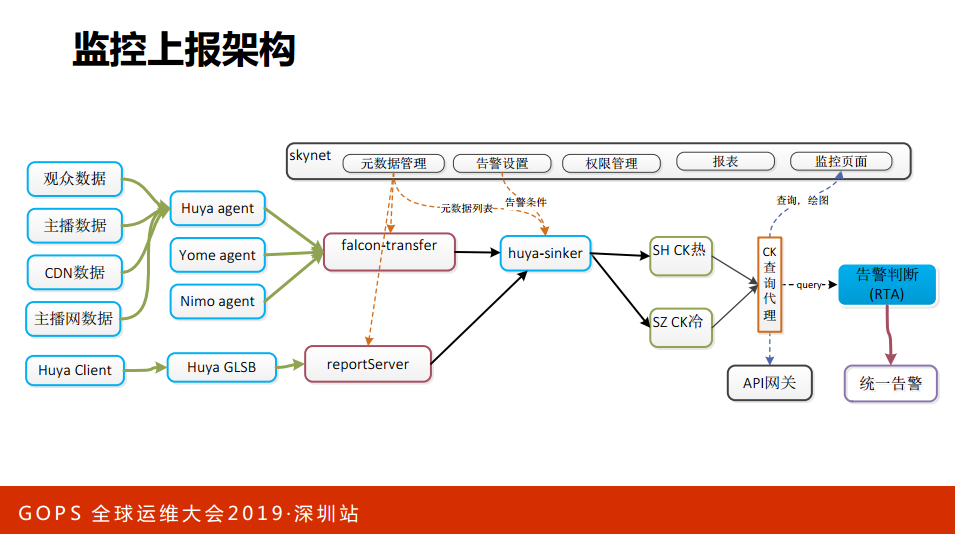
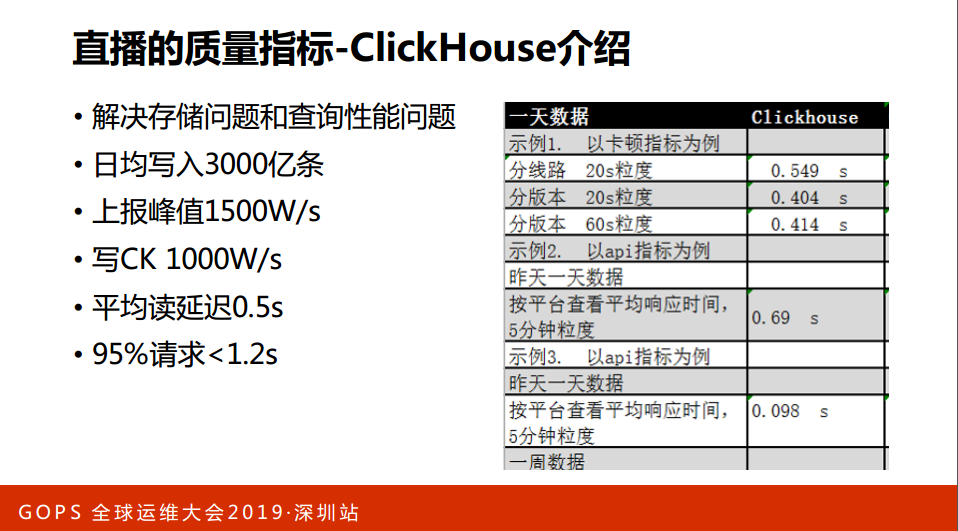
我们用了一个ClickHouse的存储,这是俄罗斯的。日均协同数据,都挺好的。
主要讲一下技术点的感知能力,感知能力不等于我们的监控告警,监控告警只是一环,我们的目标是从发生到感知有两分钟,这个从技术上来讲有一定的要求,20分钟来采集,触发告警要在1分钟执行一次,而且要准确地定位这个问题,而且要发给准确的人。

现在我们要求准确发到一线,发到Lock,而且要对告警做足够的收敛。我们要感知这个问题不是说告警就够了,而是要确定问题所在,监控覆盖必须要全,这就要求业务去做上报,主播端、观众端等等各种端都要做上报,要采集运维的数据,而且这么大的数据要进行实时地的计算,我们不能一条一条发出来,要做一些聚合和关联,聚合要比较准确才能告诉你业务出现问题,指标也要变成。这里面也会用到AIOPS的一些东西,因为要求阈值要合理,告警不能被淹没掉了,不能几百条没有人看,一线告警要升级到上级,一级领导要在更大范围去协同这件事情。
感知能力的一些方法,我们会用一些CK、Flink、Hive这些。
预警排障,通过业务运维去打开页面,要求所有的业务都做多预警排障,我们做了一幕排障,拉很多的数据进来。我们团队很多人用Hive来做分析,这是一线的分析,长期的分析,我们用CK或者Cercle来做分析,我们有很多灵活的页面。大家可以通过Cercle做多维度的分析,提供分析排障的东西。感知能力确实有很好的考核指标,一个故障出现了,有多少是通过告警首先响应的,这是我们的一个指标。有告警出来了被淹没了,不是我们先看到或者不是我们先响应,这个也不算偶发。这个要求也比较高,这是我们每人一天只收到5条告警,我们有很多环节的质量数据,一出问题就知道定位是某一个,一靠近主播源头可能更多就是他的原因。定位在此之后,我们要做修复和保障。

4. 全链路修复和保障能力
下面讲一下快速恢复的能力,故障出现之后,我们要求做到5分钟去修复,首先要对架构非常熟悉,要识别里面的风险,要开发出一些保障的工具。比如说我们对主播推流推得不行了,怎么办,那就是CDN的覆盖就是不行怎么办?我们怎么去定位,定位之后怎么去解决,解决就是有一办法换节点,换CDN的节点或者上行,或者私有的一些协议调度,这些调度要求线上与后台做互通或者决策的互通。
我们有一些效率可以做到智能线路的切换,对接到上行的问题或者链路的问题可以自动切换到其他的链路,我们还有其他的一些标准,比如说介入机房可以做到快速上下线。快速修复做好记录,很多人是这样的,出现故障要登陆服务器去处理,叫人肉处理,或者一些链路平台一键出路,这就需要做脚本,下一步做5G的平台,核心的服务要建立一些平台,在平台上丰富我们的工具,越来越多的场景提供快速恢复的能力。

要做到故障修复从手工到智能就是数据的智能,数据其实是运维很重要的资产,大家用得好可以帮助我们做很多的事情。比如说右边这个图看得清楚,正常情况下的业务流程,两个跑的数据没有问题就正常去跑了,一旦红线出现问题或者异常的数据会触发我们一些控制的算法,然后会做一些操作的指令,这样去恢复我们的故障。

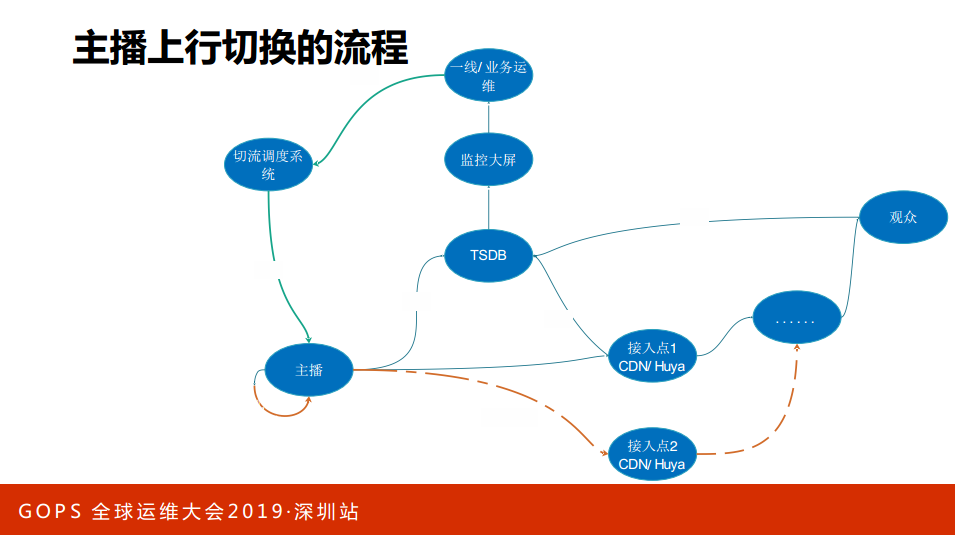
这是控制论的一个架构图,我们有些做的工具,有些无上行的推流会经常出现故障,有些一键切换的可能会切换十万次,如果十万次用人工是根本操作不了的。这是整个商业切换的一个简单的示意图,正常说它会介入CDN,同时数据会上报到TSDB、CK这些监控系统,监控能够看到监控大屏或者告警,一线的运维和感知,一旦有问题就做调度,主播可能就到新的地方。
5. 可靠性工程思考
再看一下可靠性保障的一些思考。稳定性、可靠性其实是一个工程工作,是一个系统工程,不光是靠我们运维来做的。前面加上设计可能要跟研发团队打交道,做分析应该与监控的、大数据,做商报要跟大数据的,做保障要跟运维团队,我们自己做开发团队,做一线的开发团队或者管理团队互相协同才能把事情做好。运维运营是一个连接者的角色,把很多团队联结在一起大家整合起来形成一个闭环,这其实是一把手工程,老板很重视稳定性工作才能够真正做好,要不然协调不动的。

在管理里面有一个故障管理,比如说一个故障出来之后,我们是怎么去记录和复盘的,复盘能力也很考验团队的协同能力。整改或者后期的验证整个的过程,前面讲了四点,这几点也是整改的重要环节,通过整改或者验证之后才能说这个故障是真正完结了。我们要求已经发现的故障必须要整改,要进行核验证,在里面要发现我们的性能脆弱点,从而去发现我们的问题。
再讲一下可靠性六种能力:
第一,设计与分析:深入业务、分析架构;
第二,感知能力。监控、告警。
第三,修复能力。快恢、止损能力。
第四,反翠错能力。脆弱大余健壮大余反脆弱。
第五,保障能力。总后勤装备部、战略支援军、稳定性保障团队如何保障人、机器、工具、技术到位。
第六,跨靠性管理能力。确定性保障管理能力,做好连接者,应急、协同、复盘、改进。
这是我们的“235工程”,故障发生到开始定位要2分钟,定位到响应3分钟,快速处理到快恢要5分钟,这个挑战挺大的。我们只能在部分的服务里面做好,但是不要紧,我们只需要在更多的场景做覆盖,业务组织会趋向于稳定的。
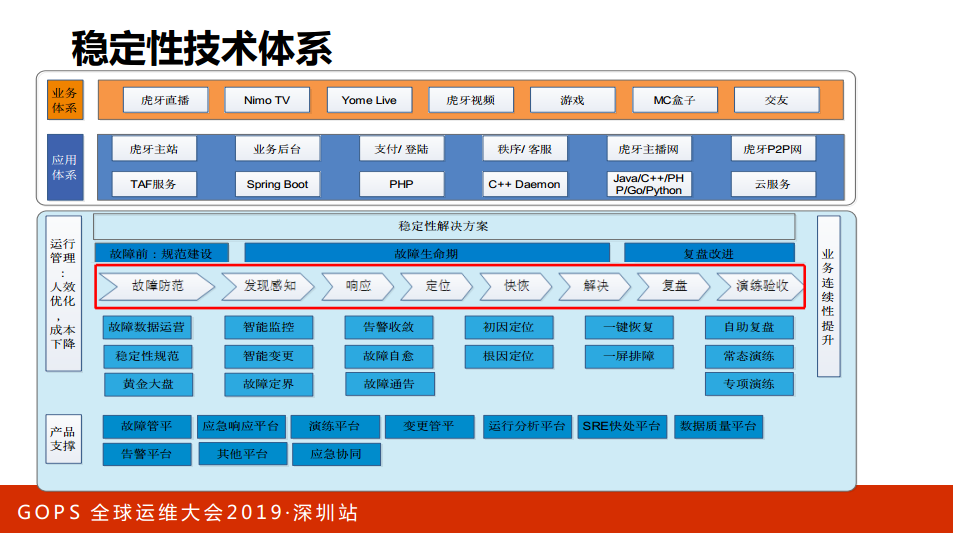
我们画了一个架构图,上面是我们的业务,中间是我们稳定性保障的一些打法:故障预防、防范、感知、响应、定位、恢复的过程。下面会定位一些不同的阶段做一些事情,事情防范要做哪些事情,响应要做智能监控等等。不同的阶段做不同的事情实现我们“235目标”。