@gaoxiaoyunwei2017
2017-10-09T03:32:27.000000Z
字数 3840
阅读 1410
运维如何应对十倍、百倍的业务增长?——分解式计算与可扩展存储的理念和实战
于济萌

作者 | 谭芝兰
编辑 | 济萌
作者简介

谭芝兰
Facebook TechLead在硅谷从事运维工作10多年。2012年至2016年先后在Twitter大数据平台(Data Platform) SRE和工程效率组(Engineer Effectiveness)任职。2016年起就职于Facebook广告部门,负责大数据和计算平台可靠性及性能优化等相关工作。几年来带领过的项目包括在线迁移输送价值数十亿美元数据的实时线上系统;Apace Spark @100TB Scale;持续整合线上线下大数据计算平台开发;以及不间断自动愈合服务平台。
序言
在刚刚起步的小公司,中型的Twitter以及规模庞大的Facebook做运维有什么不同?在硅谷十几年做这一行都经历了一遍,回头看看,满满的都是故事。互联网时代的小公司里面做运维的人都是十项全能,在这样的环境中你的目标只有一个那就是支撑产品的运行,所有工具都可以用open source的平台,在云上搭出支架,最快实现产品的功能就是赢家。然后有一天你的用户规模开始以每月50%以上的速度增长,要支撑这样的发展,我们把有限的资源放在哪里?如果规模增长了十倍百倍呢,我们面对的又是怎样的挑战?
本文的六个部分:
- Facebook在可扩展中面临的挑战;
- 分解式的概念;
- 分解式的网络;
- 分解式的存储;
- 使用温数据存储(Warm Storage)的spark;
- 总结。
(一)Facebook在可扩展中面临的挑战
在几个星期以前,扎克伯格发布了Facebook月活人数的讲话:揭示了Facebook月活人数超过了20亿人。20亿的人每天所产生的数据相对于内部的机器与机器之间的数据传输,实际上只是冰山一角。在内部的数据尤其是在计算内部数据的时候,数据增长的速度几乎是几何增长。现在所有的现有技术都不能够支撑我们所要面临的更多的挑战。而且在这样巨大的一个基础之上,我们仍然还要要求十倍、百倍的增长,怎样来面对这样的挑战?
首先,网络作为一个基础时,我们想要解决一个问题。这个问题就是在计算和存储的时候,先要有一个基础,就是网络。大家都知道在网络里,我们有一个概念是Clusters switch。如果说大家对网络有一些概念,我们有一个集群,想要做一个网络,Clusters switch做3+1;那么,这样做出来的网络可以使得集群比较可靠。
即使,如果说有一个switch坏掉了,其他机器还可以继续工作。可是它的局限性在于:如果这个Clusters switch的尺寸不能够更加扩大,就会产生它的局限性。这个局限性在于顶多可以做一个1000台或者几千台机器的群,如果想要再跨群那就更加困难。
3+1集群取决于交换器的容量,维护起来特别困难。而且,如果一个交换机坏掉了,对一个集群可靠性的影响非常大。现在很多的应用已经超过了1个集群范围,比如一个Spark或者Hadoop的Clusters,其网络超过几千台、上万台的集群,所以经常要求跨群。
(二)分解式的概念
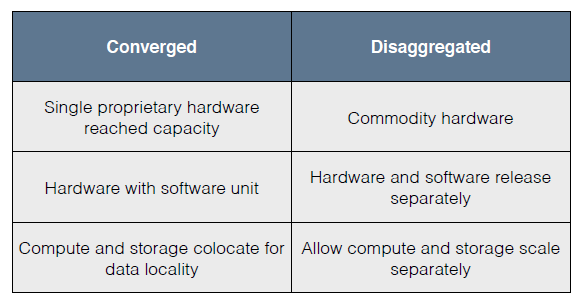
现在,有一个概念是分解式。一个定制的硬件往往是非常容易到达它的局限性。然而,以前的做法是硬件和软件一同开发;现在的趋势是硬件和软件分开来开发(这就是分解式的概念)。
在这种情况下,分解式的优点是:如果我们需要对硬件升级,软件只要放在上面就可以工作。其次,计算和存储之间可以分级。这就允许我们把计算和存储(存储指的是Storage)分开来扩展。
(三)分解式的网络
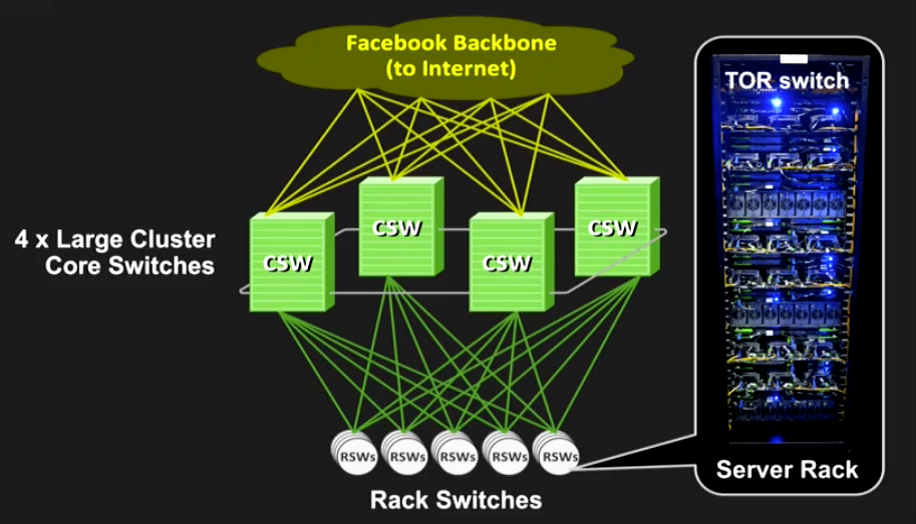
先讲一下网络数据,Facebook把它叫Fabric。它是Facebook数据中心核心网,有了这个基础可以让计算分离成为现实。上图是架构,左边大家都非常熟悉,在每一个柜式的架上,顶端有一个Switch,结构是3+1,4个Core switch来达到可靠性的要求。下面连接到Core switch,这样组成一个Clusters。
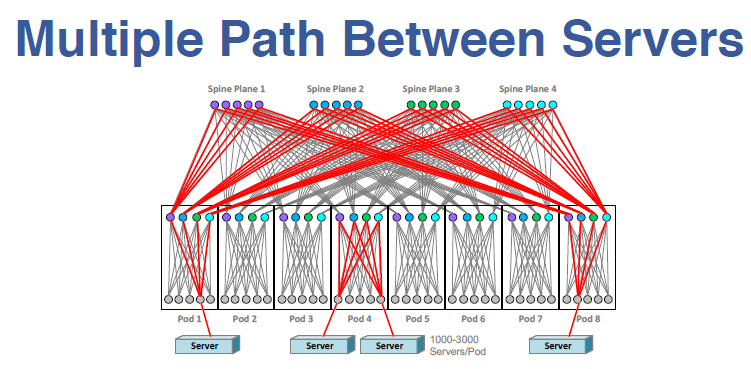
现在,新型的The Fabric架构是网状的架构。而传统的结构是金字塔型的,其顶端必然是一个瓶颈。在这样一个网状的网络里,它是在Rack switch、Fabric switch的上面和之间全部都是网状结构。我们所得到的结果从这一端的Server到另一端的Server,两者之间如果要传输数据,它有多条通道。在多条通道里,当任何一个节点坏掉或者多个节点坏掉,对于整个的传输没有任何的影响;而且可以做到在几十万台机器之间相互的传输,没有任何瓶颈。
那么他的优点在哪?就是说如果有一些switch坏掉,可以完全抗损坏。
上述途中所说的一个模块叫做一个Pod。所用的部件是通用部件,即:Fabric switch,所有的switch全部是通用的。它们的部署是通过一个Fabric来部署。如果需要扩建,我们只要直接加一个Pod就可以了。如果需要在Fabric内部增加,就是再增加一个上传的link。上述的网络基础就给我们的计算和存储带来了一个全新的,可以做更加完全不同架构的扩建。
(四)分解式的存储
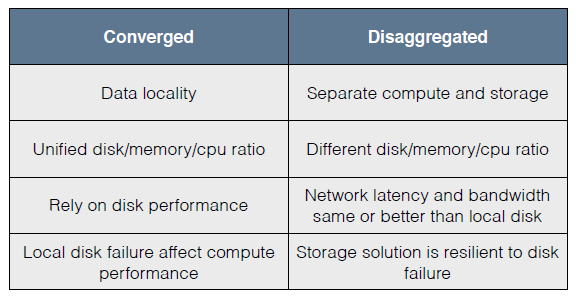
过去,在分解式计算与存储中,一个比较大的理念是Data locality。如果我的数据在一台机器上,我尽量用一个方法把我的计算单位放在数据单位同样一台机器上,。这样来增加它的performance。
现在,在分解式的计算中,我们就可以做到运算是一个集群,而存储是另外一个集群。
以前还有一个问题,在Hadoop的Clusters 里面,我们往往说40个cpu、120G的memory,这些都是固定的比例。如果想增加运算的容量或者存储的容量就非常困难。像刚才说的传统的方法对每一个硬盘的performance要求就非常高。
但是,在分解式的方法,网络的带宽和延迟都完全超过了Local disk;所以网络不再是一个瓶颈。有的朋友会看到某些时候自己的硬盘坏了,数据就要重新处理一遍。那么对于我们来说,就是要想办法提高硬盘的可靠性,来预测一下或者怎么样尽快的去处理去修复,可是这些方法都不能从根本上解决问题。
(五)使用温数据存储(Warm Storage)的spark
Facebook将内部的Storage叫做Warm switch(温交换)。先说为什么我们要用这个Warm Storage(温数据存储)。因为,它对于硬件的配置有一个比较灵活的配置;我们可以专门对Warm Storage进行一个配置。而且在传统硬盘应用的时候,在很多计算的情况之下,我们可能遇到一个最大的瓶颈(实际上是iops seconds)。在计算的时候,如果每一个io数据特别小的话,这个IOps就会成为一个问题。在p99情况下,如果经常是io的q很高,就需要几秒钟的等待时间。刚才说了这么多,所有的铺垫都是为现在解决Spark的问题。
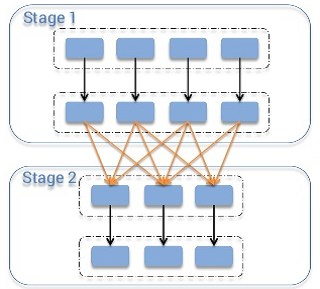
我们有一个很大的问题就是Spark的挑战。如果大家用过Spark,就会知道它有一个过程,即:Shuffle。这个过程是在Storage1和Storage2过程之间,1和2之间有一个Shuffle。这个Shuffle数据存储在当地机器的硬盘上,除去这个硬盘坏掉时,这个计算就必须回到Storage1。
它的挑战就是一个硬盘可以直接影响到Spark的稳定性。而且,在drop越大的时候(比如我们的drop经常是以年CPU时间计算的),其运算工作就会越大的;如果硬盘的损坏率是1%或者0.5%,这个运算工作就会非常大,基本上这个Spark就不能用了。
Spark的做法以前是和HDFS在一起的。HDFS跑的是数据的存储,Spark跑的是运算。这个想法很好,存储是用它的硬盘,运算是用它的CPU和memory。但是,实际上并非如此:在我们使用的过程当中发现Spark和HDFS之间相互竞争IO的资源,经常Spark的performance受到HDFS的影响。如果考虑机器的比例,比如:40个CPU和100个G的memory,每一个memory的mapper是非常小的。如果说运算输入的数据比memory size更大,就会有一个溢出。当溢出的时候,对于performance就有很大的影响。
所以最后我们就用了Spark with Warm Storage。因为网络的基础,我们可以做到分开。这样Spark完成变成设置Scale 的Clusters switch。而机器的配置是很多的memory、CPU,但是只有一个disk。它的性能超过了传统的方法。
现在我们已经将它用于生产环境。硬件的配置可以给它很多memory,要扩展计算容量也会变得非常容易。以前如果我们想要维护一个Spark的机器,还要等着HDFS排流。就是说,你想要把一台机器移出来,必须让它的数据移到另外一台机器上才可以将它下架。但是,通过Spark with Warm Storage,这种情况下我们就不需要再考虑它的排流,使其可靠性提高了4倍。
举一个非常实际的例子:用分解式的方法,对于计算的Scalability有决定性的作用,而且改变不仅仅是说对一个Feature做什么改变,而是对整个系统做非常根本的改变。在过去的几年当中,Facebook一直都是在用这个理念考虑问题。Facebook想要用的是通用的机器,硬盘和软件之间分开来开发,即:软件只考虑软件的问题,硬件考虑硬件的问题,而且软件和硬件之间可以分开来升级。
(六)总结
最后,如果这个分解式能真正帮我们解决Scalability的问题。但是并不是每一个应用都应该用到的,像有一些比较小的Scale,把它合在一起来解决问题也是比较好的。
