@gaoxiaoyunwei2017
2020-01-03T06:57:08.000000Z
字数 6733
阅读 1428
HTTP性能极限调优
彭小阳
作者简介:陶辉,杭州智链达数据有限公司CTO,《深入理解 Nginx:模块开发与架构解析》作者。
1、编码效率优化
希望能给大家交付的就是这样一种体系的观点,我先说一下HTTP引进的方向,如果你在做API的话,你跟你的合作伙伴协作方式消耗是最低的。

但从2009年谷歌搞了SPDY,谷歌走得最早,我相信在座各位有(英文)的朋友,为什么会有极客,极客的性能会高很多。ICB3明年应该差不多了,因为现在(英文)已经出了二十多个。整个演进方式向性能的方向发展,因为要考虑性价比。
我们从第一个角度来出发,(英文)承载的是(英文),不管我的(英文)是语言描述信息。这个东西我们先对(英文)去讲怎么样做编码的时候,肯定绕不开一个话题,叫做压缩。为什么可以压缩,因为有数据冗余。如果是ABAA肯定可以压缩,因为有三个A是一样的。有统计冗余可以压缩,分为有损压缩,无损压缩。
有损压缩像视频也有很多种,我们可以说是增量压缩。原先很大的一个视频,我压缩了一千倍,肉眼肯定还看不出来,这是增量压缩的一个效果。后面我们看很多东西,都是跟基础的理论是相关的。我重点提到一个(英文),我不知道大家有没有用过(英文),也是谷歌提出来的压缩算法,有一个模块叫(英文),你换到(英文),你就能享受到很强悍的性能。

我不是想跟大家说这个东西,我们怎么判断一个压缩算法,一般我们看两点,一个压缩率,一个压缩速度。下面X轴是压缩速度,我很关心,我是实时的压缩,我很关注压缩率和解压速的速度。下面绿色的是(英文),蓝色的就是(英文),这个(英文)在同等的压速率下是相等的。
这里有更详细的图,我们做(英文)你要配1-9,老师你到底配1还是9,根据这些东西来判断,你要看(英文)是1-10,这个是压速比,这个是压速速度,那个是减压速度。我想跟大家说的是我们做性能极限优化,你有很多压速算法,你的业务场景越单一,就越可能做跟大家不一样,收益比很高的东西。这其实是一个方向,并不一定是要换算法。
我再说(英文),(英文)是我们的性能杀手,HTTP协议是性能架构,我为了保证你的(英文)有很好的(英文),你随便扩容,也不影响我们的吞吐量。怎么去解决这个问题?我们的一个(英文)随便就两三K,我拉一个很小的资源,还会产生很小K的头部。
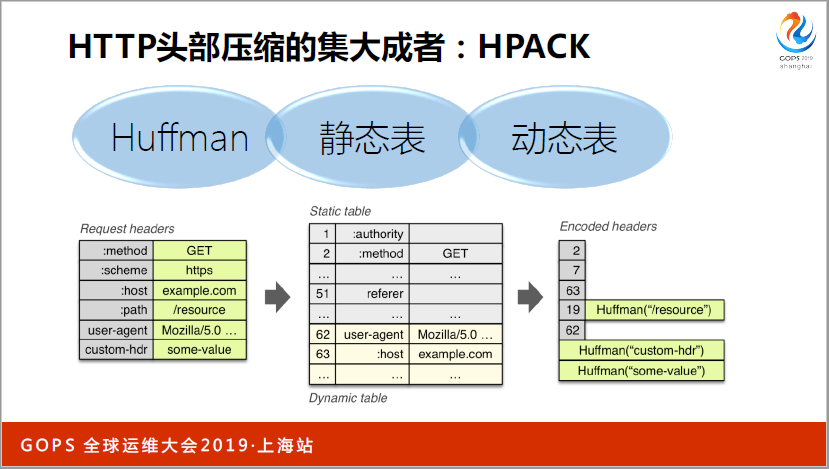
头部的话有一个叫(英文),(英文)是(英文),如果你把(英文)升到(英文),就用(英文),你配置配两行就可以了。原理在这里,今天你用的是(英文)。我今天想跟大家分享的是用(英文)怎么去优化。
第一个讲动态表,是(英文)里面最有效的方式,同一个连接下又去登陆,拉取个人信息,又传(英文),这个是很恶心的事情。第一次传的时候表示100,我下次不传了,只传100,动态表有多高的压速率呢,只有一倍的压速率,本身是2K,压完是1K了,效果是非常好的。
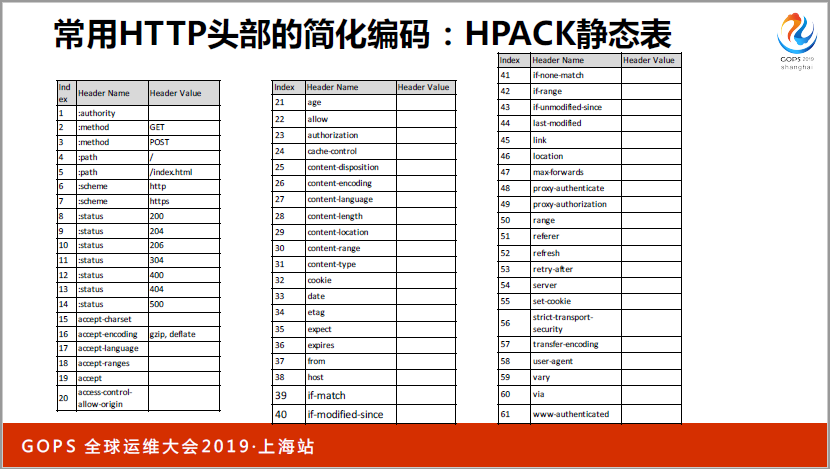
第二个叫静态表,从另外一个维度出发了,我把传输的东西硬编码到(英文)里面去了,一缩到31,就是(英文),有十几个字符。这个东西压速率很好,但是很多覆盖不到(英文),因为太少了,只有63个,63个以上就用动态表了。

第三个叫HUFFMAN编码。原理就不说了,静态HUFFMAN是(英文)专用的,今天我抓几个互联网上的,比如说抓近期两年以内的包,还要统计。A出现了一亿次,B出现了8000万次,A是00011,B是100011。
你完全可以在你自己的场景上去构建一个HUFFMAN,也许它的效果会非常好,如果你是特定场景下,你阐述的东西和我们通用的是不一样的,你完全可以做通用化的HUFFMAN。你标完01东西的编码就出来了。
我从另外一个维度说,这个维度是非常大。我们传的(英文)资源特性上面去,我们有非常多的优化方案。因为咱们主要是面向运维,如果面向前端的同学会发现很多的方法,把很多的图片切成大图,GS切成很多的小图。很多时候我一个30K的文件就有几百个字节,我压缩完还有一两K,这个时候怎么有更好的效果,有很多的维度。
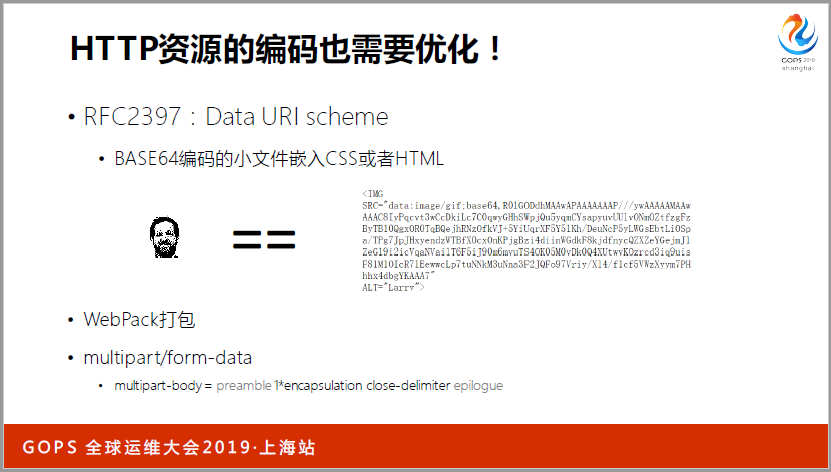
我只举三个不同的例子,第一个例子,(英文)定义出来的,我要单独传的话,成本是不划算的,如果大家写过(英文),有一个(英文)等于后面加个UL,你把这个东西传到(英文),一敲就能看到图片。这是一个角度,我们从资源本身的特性。
第二个WebPack打包,能不能压缩能不能合并。
第三个是从传输的角度,你既有传文件,也有原数据描述,一个表单提交,能不能合并到一个(英文)包里面去。
端到端有很多其他的优化路径,我都归结到端到端。
2、信道利用率优化

信道利用率我们先说第一个点,多路复用。大家现在知道我们在5G,1G的时候就是摩托罗拉,或者对讲机,要设频率。我们现在用的2G,TDMA、诺基亚搞的,一个时间上面我跑了很多辆车,就像我现在有很多的程序,但是只有一条网线,网卡前面加一个(英文),每一层都干这个事。其实你发出去的是比特流,原理是这个原理。我们看看多路复用,其实有很多维度,就不展开了。
第二个传输错误,我认为要及时恢复。因为我们在说传输错误的时候,一定不是指业务错误。只有网络错误重试是有用的,你怎么能快速发现错误,第二快速发现错误的时候,重试的时候会不会造成问题,我们会有很多东西熔断,我就不介绍了。
第三个我们的资源是有限的,只有一个带宽,但是同时有很多的用户,如果用户把我的带宽占满了,就有问题了。现在有一个网页,比如说门户网站有400多个对象,你去访问的时候,有些对象的优先级是很高的,有的是很低的可能就是一张图片,你看不到它没有什么大问题,体验不会有问题,就是资源合理分配。还有一个就是提高信息量的占比,有些用户老拉一些很小的资源,因为我们刚才说了,为了完成多路复用前面有很多的报头(音),实际传输的只有一二十字字节,利用率就很低。

我们一个一个来看,首先来看多路复用,我主要在谈传输层的应用层。你跑了两百个线程,200个用户同在服务,这是一个多路复用,从这样的维度来说。携程也是一样的(英文)和(英文)。重点想说的是http2stream。我希望源源不断的收和发,而不是说收到一个再发一个,这是我们做多路复用的原因。

为了做这个测试,我专门支持了(英文)1.1,性能是很差的,这是用(英文)浏览器,最多建六个连接,可以并发跑。(英文)只会用一个连接。第一个好处,间连接和关连接的成本少了。

第二个角度是从waterfall视角,如果大家做前端的,看一个请求等待哪里,消耗在哪里,会有好几个阶段。
我们再来看第二个错误恢复。一个(英文),上下可能就两三K,究竟多长时间收完是合适的,(英文)是60秒的,2K是不是合适,你可以根据你的场景来判断。比如说发送响应的时间,如果管连接,连接关你收不到404或者403,这个错误对你是有用的,时间应该控制到多长时间。还有间连接收发消息等等。

我们说说(英文),相信大部分服务器都把(英文)设1了。设1到底对我们提升在哪里,因为(英文)提升很快,隔几年又有新东西了。解决了RTO的问题,你升级一下(英文)的版本,就发现(英文)变掉了。RTO困难在哪里,设大设小都不行。
比如说设小了,(英文)已经发过来了,需要时间,但是设小了又重发一次,就性能很差。设大了也有问题,本来丢了,丢了以后因为你设得太大,所以就会导致隔了很长时间才会重发,整个吞吐量又上去了。有了(英文)解决了这个问题。有了(英文),有一个(英文)加进去了,会加入8个字节,就能解决RTO计算不准的问题,其实是要权衡的。
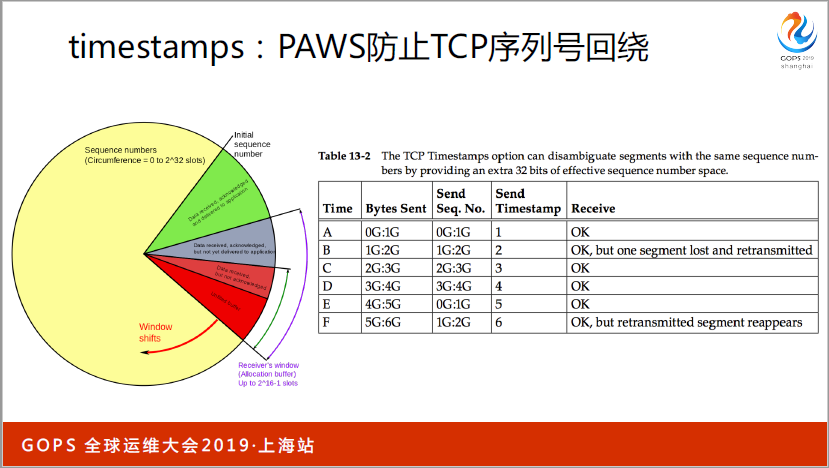
还有一个很重要的用途,特别是带宽很大,动不动就是1G以上,会出现序列号(音)回道的问题,比如说发一个6G的文件,发六个包,(英文)可以设(英文)缓存区,有些同学会调到很大,意味着飞行中的报文很大,你发六个报文,到第五个的时候,已经回到了。CTP的序列号是四十二点几,第二个报文如果丢到了,第一个和第二个你是分不出来的。这时候出现重叠了,也是靠(英文),对于一些高速的网络,很大带宽的情况下,(英文)上面一定要开。
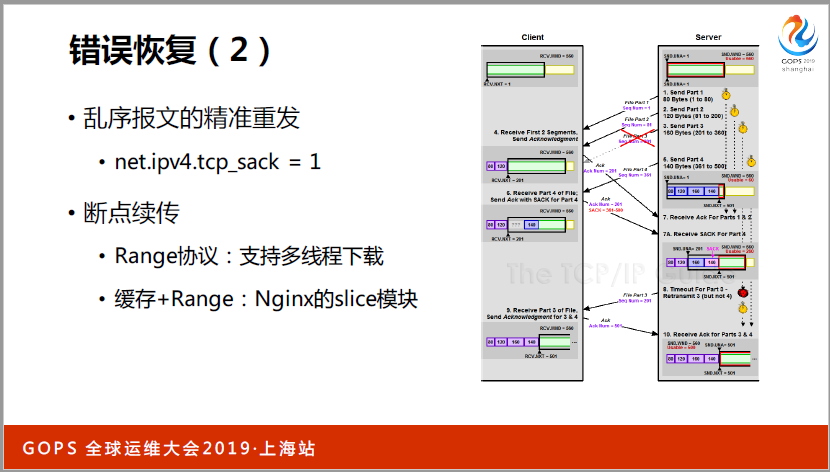
错误恢复,(英文)为什么要配这个呢?我们再看一个例子,比如说(英文)要向(英文)发五个报文,12345,第三个丢掉了,当(英文)搜到第四个的时候,会说第三个没收到,第四个会保存到自己的缓存区,不会丢掉的。第五个还会说第三个没收到,只有在你的发送缓存区可以源源不断的发。
这个时候,其实(英文)很简单,我只要跟你说我第三个没收到就行了,但是(英文)就很麻烦了,这时候只有两招判断。第一招,因为现在你告诉我第三个没收到,但是345都发了,我有两种办法,第一个叫悲观但积极,我觉得345都丢掉了,我不管4和5丢没丢掉,我把345全发一遍。第二种积极乐观。4和5肯定收到了,但是发3,都有问题。
到底会产生什么影响呢?3没收到的时候,又把(英文),20个字节的标准头部,这个时候大概要加好几个字节,跟你这个是有关联的,如果你收到4和5了,两个(英文)是要列上去了,转发给了(英文),只送3就可以了,这是本身的原理,究竟开不开,我认为是一定要开的。
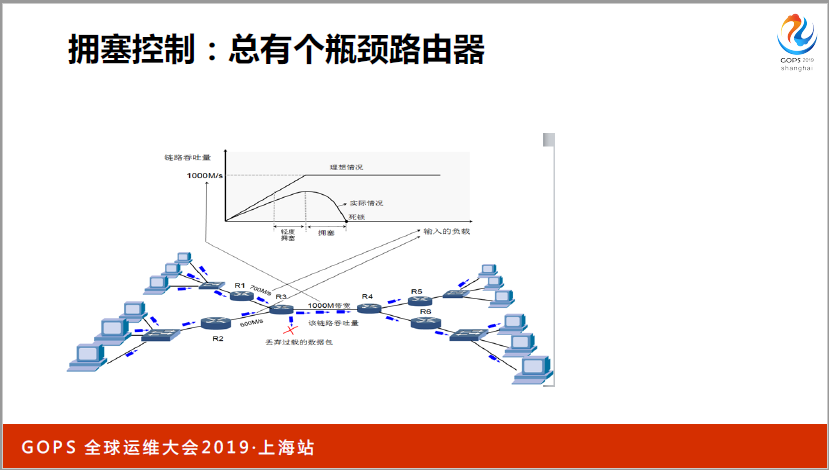
拥塞控制,有一些比较大的公司应该都做过拥塞控制的算法,我们看这张图,比如说R1只有700兆的流量,RI是600兆的流量,但是R3只有6000兆的流量。因为有了这个瓶颈路由器,我们在1982年的时候,就涉及到拥塞控制算法,因为我刚刚讲到只有你的缓存区配得够大,就一定会打满。很多服务器是共享的,如果你有一台拼命打满,两台都打满了,后面就没办法操作了。如果发现丢包,马上降一半,整个缓存降一半,这个是TCP能够支撑我们互联网世界的基础。这个东西其实是不好的,核心问题在这里。
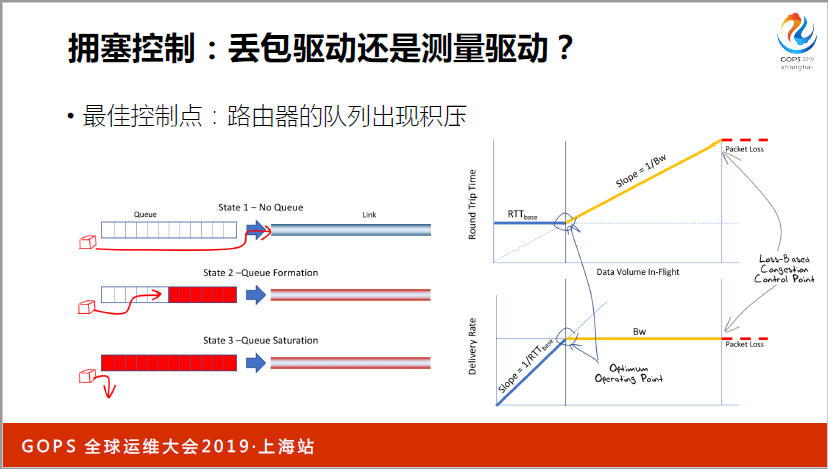
我们买一个路由器,越新的路由器内存越大,有一个功能会放队列,比如说R1和RI,突发流量很大不应该丢,我会放到我的队列中,队列越挤压,不会丢包,但是会导致我的RGP(音)增大,丢列一旦满了就丢包了,这张图看得很清楚,随着时间的进行,这是RTT,一开始RTT不变,因为我的进程还没有跑满。
一开始的时候,我可能卡到磁盘O上面去,RTT不变,我的吞吐量在上升,一旦到了这个点开始挤压了,中间的瓶颈路由器开始挤压了,RTT就开始上去了,因为要在这个队列等一会儿才能继续走,但是吞吐量不变,因为带宽宽度是一样的,所以吞吐量是不变的。
最后到了丢包的时候了,我们应该在这个点控制是比较好的。为什么要把丢包驱动改为测量驱动呢?我们早期的4.9内核,在这之前拥塞控制代码之前的(英文),2.6.19。这个BBR算法有多好呢?比如说这张图上面是吞吐量,就是我们的带宽。这个下面是丢包率,我们可以看到丢包率达到0.01%的时候,整个基于丢包的拥塞控制就没法用了,如果你现在的网络有这么糟糕,每一次发生丢包,操作系统拥塞控制算法根本起不来了,但是跑到BBR就没有问题。直到丢包率达到5%的时候,才会出现带宽的严重下降。
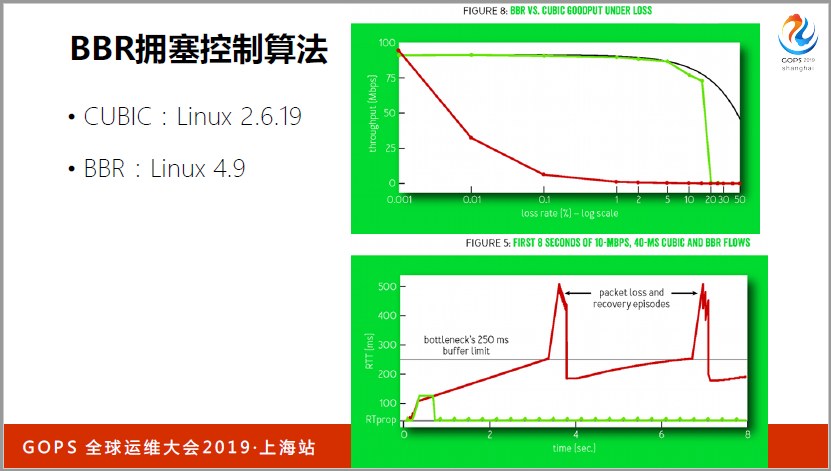
第二个是RTT的指标,把队列打满,一丢包,拥塞避免,后面加差不多了,又开始快速加,又加包,用户体验很差,总觉得你的网络很慢。

后面还有资源平衡分配,这是从另外一个角度,其实有一个盆在接水,就是应对突发流量。
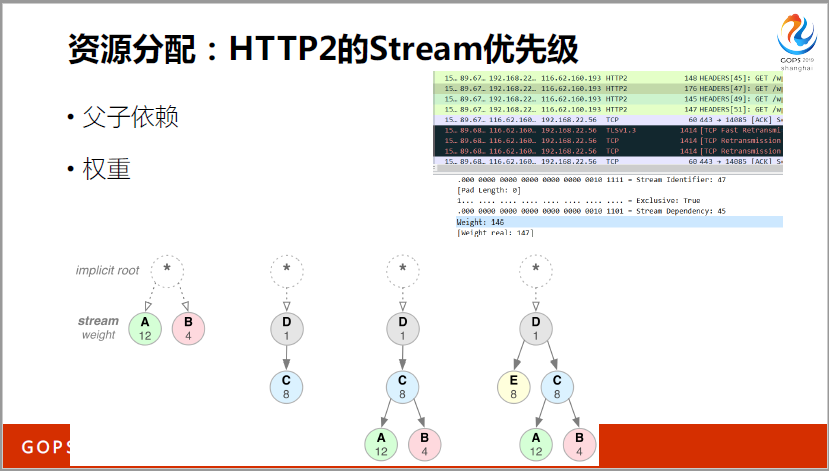
再说一个资源分配的问题,这还是我的网站,我专门抓了一个包给大家看,有一个(英文)146,是浏览器分配的,我们再回过头来说权重,HTTP2把不同的对象觉得比较重要的分到很高的优先级,很低的就分配到0-256之间。第一个是权重,比如说这是一个(英文),这是一个功能按纽的(英文),就可以分配(英文),这样网速就会传播得快一点。第二个有依赖关系,D没做完不能做C,如果(英文)文件没有下载完,你去切码图片给我我用不了。
因为工具统计了一下,像核心的CSI文件,对于这些GS文件试了183了,还有一些图片给我设了220,这些东西还是由浏览器决定的。比如说这是(英文),如果用(英文)也会有所不同。在(英文)拉了很多UL,它自己是知道的,因为(英文)已经表明了,是属于框架的位子,还是处于不怎么重要的位置,这是浏览器自己决定的。
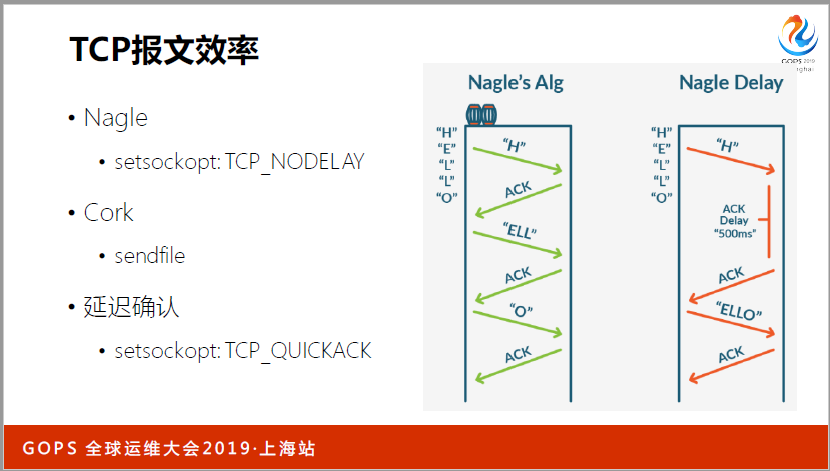
说到报文的效率还有几个点,都是很细的点,比如说像(英文),是我们(英文)算法,最多一个小报文,但是延迟确认是冲突的,开不开这个开关,我就不详细展开了,还有(英文)算法是(英文)上的,哪怕一个小报文都不能用。
3、传输路径优化
先说缓存,我们到处都是缓存,怎么样处理缓存?详细的就不再介绍了。
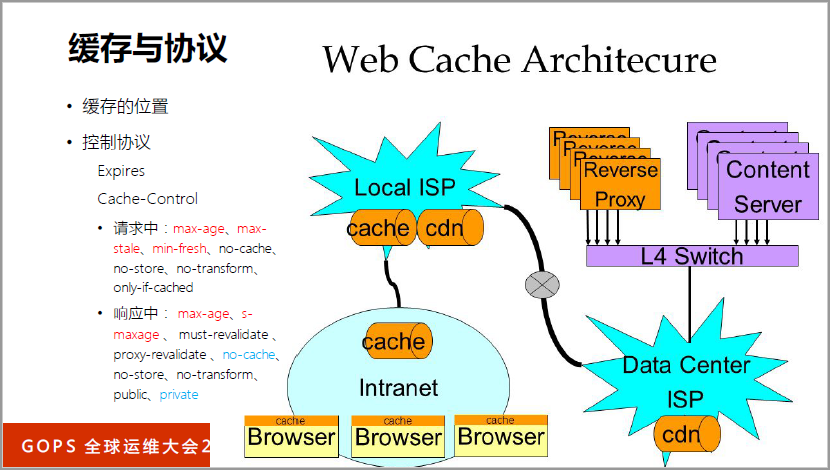
这里我主要想讲两个东西,因为我们的(英文)性能是很强的,上游服务性能是很弱的,不要把上游服务打爆了,有一些热点资源在更新,如果你没有设置回援请求合并的话,就把上游打爆了。比如说现在发了四个请求,第一个请求出去回援,回援以后把(英文)更新了,234就用(英文)就行了。
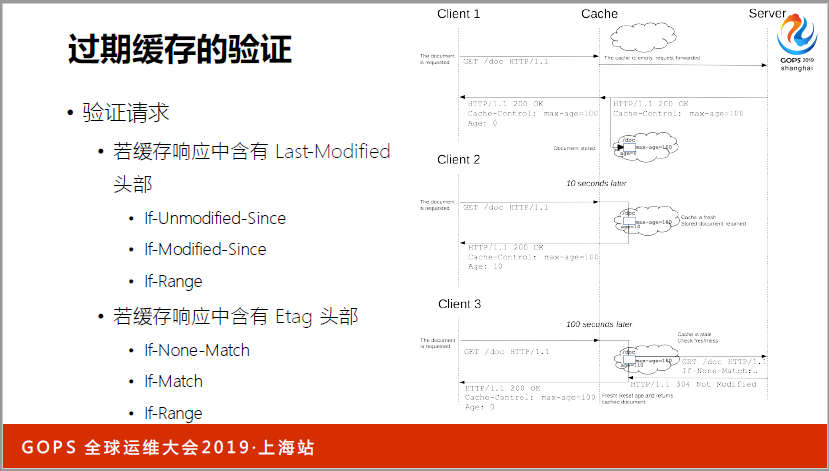
上游服务不光是怕它打爆可能就挂了,但是我希望给用户提供比较好的解决方案,用户还能看到以前的不是新的,但是效果还比较好,这个时候可能就要使用过期的缓存,有回援的也有过期的,要采用这样的方案。这些方案都有配置方法,都是(英文)的解决方案。
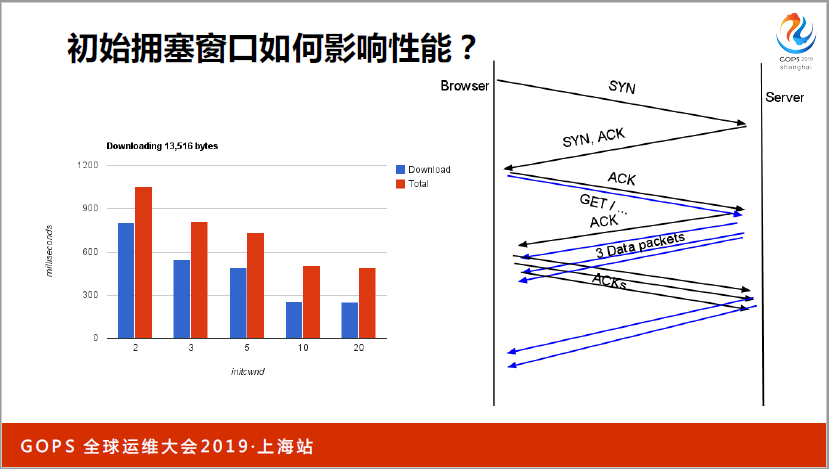
我重点讲一下初始拥塞窗口,我相信大家都改过了,早期是一个窗口,后来改到三个窗口了。三个应该就是四点几K,是不够大的,谷歌就说改到10个窗口,如果你用(英文)3.0的话,就是十个窗口。2.5.32的时候就是三个窗口。
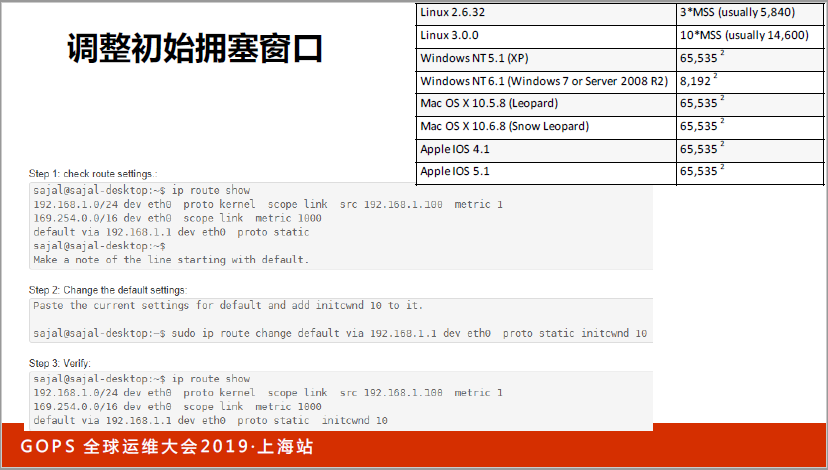
为什么要改呢?你改了以后,因为有一个慢启动,一趟来回才能翻一倍,为什么要改呢?我列出来一些主流的CDN厂商,这张图里面我们看2014和2017年的,2014年主流还是在十个窗口,窗口系统默认了,还是3.0的内核。
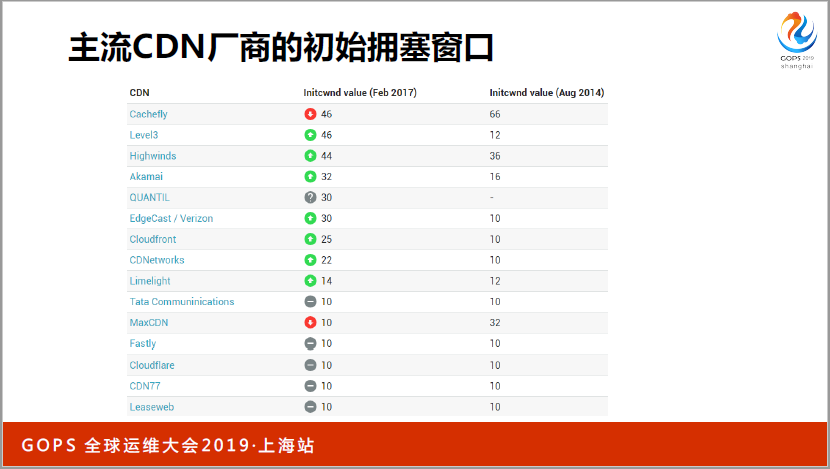
变化趋势来看,早期有两个厂商,已经改了60多个窗口,把30多个窗口到170到十个窗口。不是说一味地大就是好的,就会导致并发的流量起来的时候,慢启动还没发挥作用,就已经丢包了,如果并发量很大的时候,其实是不合适的。特别小的十个流量,追求极限速度的时候,就更不合适了。很多CDN厂商都是远远大于十个的,究竟调多大,需要大家评估你的核心价值还有成本。
关于传输路径还有很多的东西,比如说拉和推。
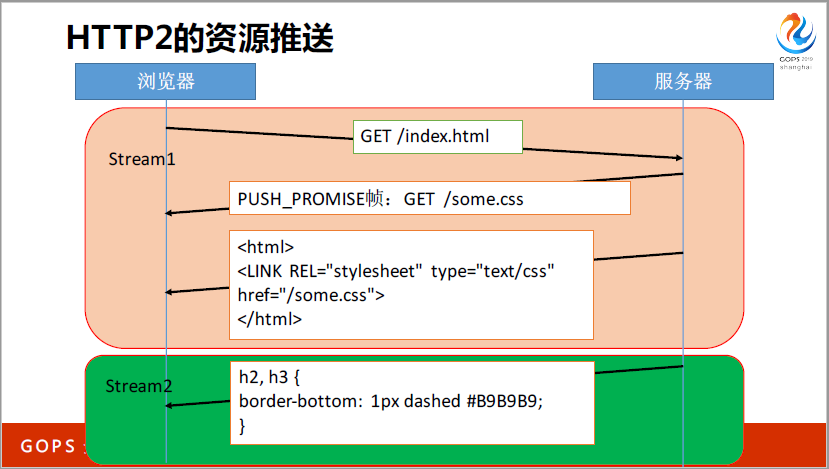
比如说这个是HTTP2的资源推送,是可以并发的,我拉的是(英文),但是服务器想推,我推一个(英文)文件,这个文件怎么推呢?不能直接在这里推,会有问题。在这里面都是串型的,如果想同时发,就要单独列一个双耗的,客户端主动发起的,双耗是服务器主动推的。
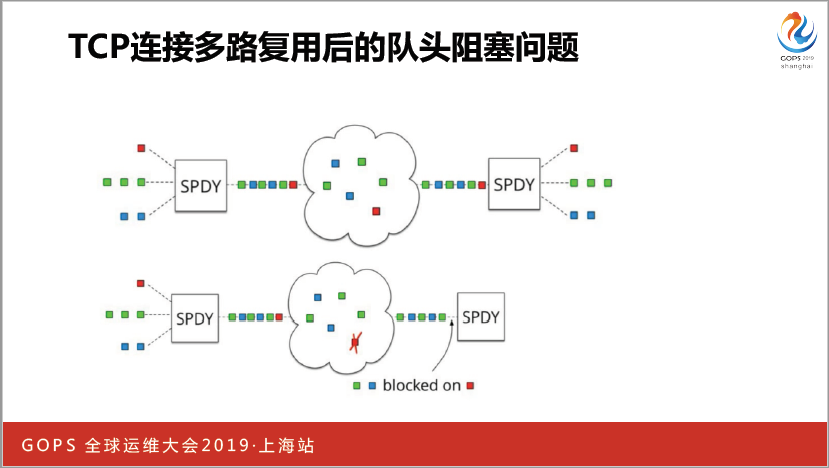
还有一个问题,还有对头阻塞,(英文)SPDY,这块东西其实是操作系统帮你实现的,因为CTP被传到操作系统里面去了,虽然发的时候是三个(英文),一个红的,一个绿的,一个蓝的。穿运化了,就是三个红的,但如果你这个红了丢了,对于操作系统就不行必须把系统的发给我,一来一回的问题就上去了。你基于一个CTP这样一个信道,是没有办法的,所有要抛开CTP。
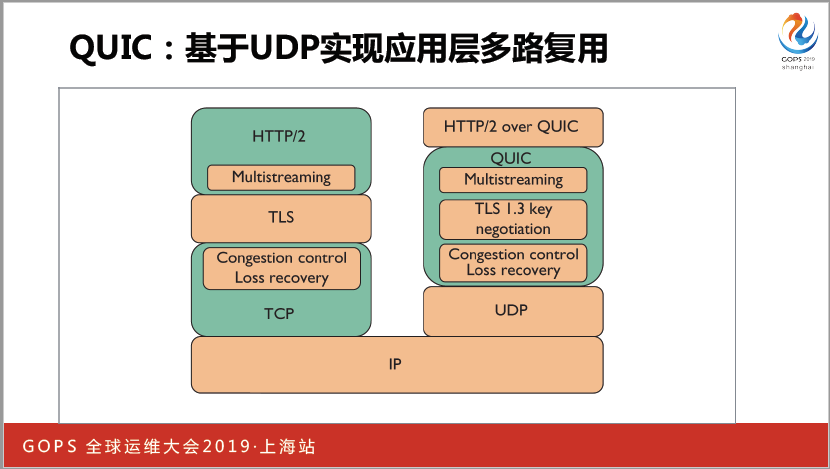
基于UDP协议,但是大家知道很糟糕,不保证可靠传输,也没有拥塞控制,你要把拥塞控制,多路复用全部用到里面。暴露了ICP接口,现在HTTP3就在做这个东西。
4、信息安全优化

我们再说信息安全,其实历史是这样的,从1695年SSL3.0,到2018年TLS1.3,我相信在座的各位你们自己的服务器都在用TLS1.2,你只要升级自己的服务器就行了。TLS1.2有什么问题呢?FREAK中间人攻击,大概1995年之前,美国要防止有些算法太多影响国防安全,只出口一些密钥很低的算法。
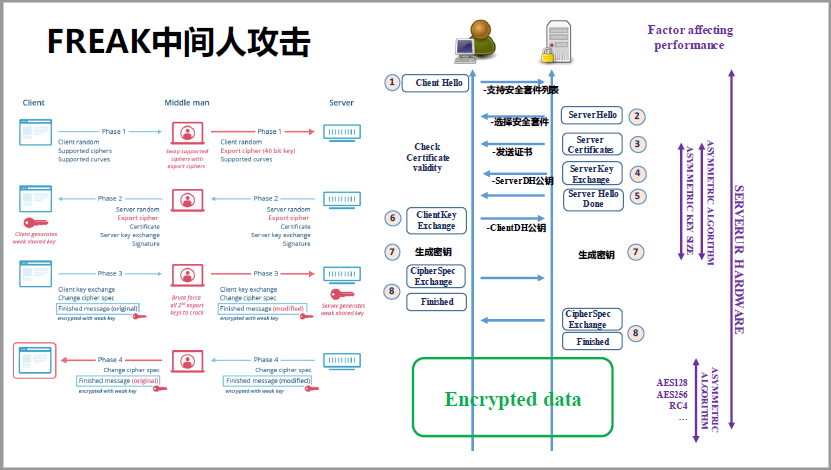
当时中国比较老的服务器都用的比较老的算法,到了2015年的时候,老的算法可以分分钟破了。我那个中间人(英文),一开始的那个改掉了,用一个很简单的算法,我们刚刚说出口的那个给到服务器,这套加密器就给破解掉了。当时是一个很大的漏洞,怎么样解决这个问题呢?

其实很简单,我们刚刚说的TLS1.3,我不支持以前比较老的了。如果你现在更新到(英文)1.1,而且就是一种,TLS1.3,而且你现在就几个。比如说I5515,一个是速度很快,密钥也很高了。

第二个问题,握手的优化。大家肯定做过(英文),因为握手的时间很慢,(英文)加密,要求你的(英文)生成一个(英文)两个要生成一个,所以很慢的。把这次握手的信息缓存到内存中了,下次的ID客户端发过来,你把那些东西读出来,复用就好了。如果有一个大集群的话,(英文)内存中有,另外一个地方没有,下次用到不同的(英文),还要再握一次手,(英文)把加密的东西放到客户端去了,都面临一个重放攻击。
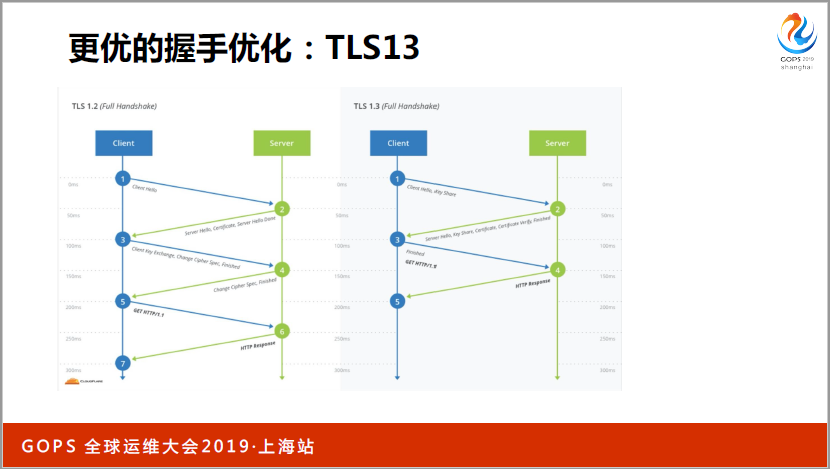
你要解决这个问题就是TLS1.3,和1.2的差别,我先跟你说我有哪些加密套件,原先告诉有哪些加密方法,沟通一次再去发。1.3因为是有限的,所以客户端先加密好直接给你,你选一个,只要把工钥用了,一下就解决了,两次变一次。
