@gaoxiaoyunwei2017
2017-10-27T08:57:03.000000Z
字数 3685
阅读 2280
智能化精准预测磁盘故障 --- 董唯元·先智数据
北哥
作者简介
董唯元
分享的主题是使用人工智能的机器学习的引擎来实现智能化精准预测磁盘故障。下面将按照三个方面进行讲解:
- 被动式故障应对的局限和隐患
- 故障预测的原理、方法和工具
- 主动式故障应对的价值和意义
一. 被动式故障应对的局限和隐患

磁盘故障大家都会遇到,我做了18年的数据存储工程师,经常接到电话说数据丢了、要丢了或者是已经丢了,反正就是磁盘不对了。
存储这个东西不像网络,断了还可以稍微等一下,跟用户说您明天再来取这个钱。2003年我在交通银行大连分行负责存储,大连分行下辖周边多个地方的交易,对私业务的磁盘阵列,其中有一个磁盘坏了,一共146G的硬盘,修复重建完耗到第二天九点半。故障持续时间都快达到上报总行的应急线了。类似的经历大家可能经历过。
磁盘阵列、分布式存储都有Rebuilding Priority选项,这是个极其糟糕不负责任的选项。我自己是做存储产品研发的,这个问题我也解决不了。
这个问题就是当一个磁盘坏了的时候要重建,你要用多少资源去重建?是为了尽快重建好,把所有的资源用来重建而不关心前端应用请求,还是为了保障前端应用请求,用很小的资源慢慢修复这个磁盘。
你选那个?恐怕做运维的哪个都不想选,我要的是以最快的速度把硬盘修好,一个2TP的盘,CPU稍微差一点的话,可能要修好几天,第二次还有可能要坏的,因为review负载会加重的。相当于一个卡车轮胎爆了之后,不换轮胎,其它的轮胎压力就更大了随时可爆的。
如果一个硬盘坏了,去review,第二个硬盘可能又坏了,所以要尽快去修复它。另一方面,所有资源去修复,前端的应用性能如何保障呢。这个选项在所有的存储设备都能见得到,似乎给你一个解决问题的办法,实际上是推卸责任的。
存储从磁盘阵列到后来的容错技术,一直都没有解决这个问题,就是如何同时兼顾可靠性和性能。

唯一的解决办法就是能预知,提前洞察你的故障,才能真正回避掉这个问题。
我们觉得副本是很可靠的事,谷歌就是三副本,人家就扛住那么多的数据。实际上副本也是有局限的,这个以前在数据量小,规模小看不出来,规模大就显现出来了。
我这里是把可靠性的模型简化到最简单,我们假设每一个磁盘的健康概率是一样的以小p表示,一共有n块磁盘,那整个系统的健康概率以大P表示是怎样呢?你的坏的盘数不能超过K,K是副本数,坏的函数不能超过K,所有的东西一累加,这其实是二项式展开的前K项,数学式我就不说了。
简单的逻辑告诉我们,n越大,一个系统里面磁盘数越多,就要取第一项达不到五个九的可靠性的,前面两项,意味着两副本,当磁盘数再多,两项也不够九个九了,你要取前三项,三副本。
到底n多大的时候需要两副本,多大的时候需要三副本?小p是容易得到的,你如果有90个磁盘的时候,两副本已经付诸了50%容量的代价了,居然还达不到五个九的可靠性。如果你的磁盘数大于512的话,三副本,你还是达不到五个九的可靠性,这个数在以前可能不觉得。
我做存储的时候,一个TB一整柜子,那时候没有太大的规模的存储,但是现在不一样了。现在一个系统里面有几百个磁盘不算很大,这么大规模的存储系统里面,我们简单的用这个公式套一下,你的两副本不够,三副本不够,是很吓人的概念。
因此要用纯副本帮助你解决可靠性的问题,瓶颈是非常非常明显的,代价就是你的投资回报率,每存一个TB,到底有多少分冗余,这个就意味着投资回报率急剧下降,所以副本这种方式在这种海量的规模下已经不行了。我说的这个和存储系统里面有很多随着我们的规模的发展,技术的发展是不得不解决的问题,这是为什么我们说做人工智能的预测,它是到了比较迫切的阶段。
二. 故障预测的原理、方法和工具
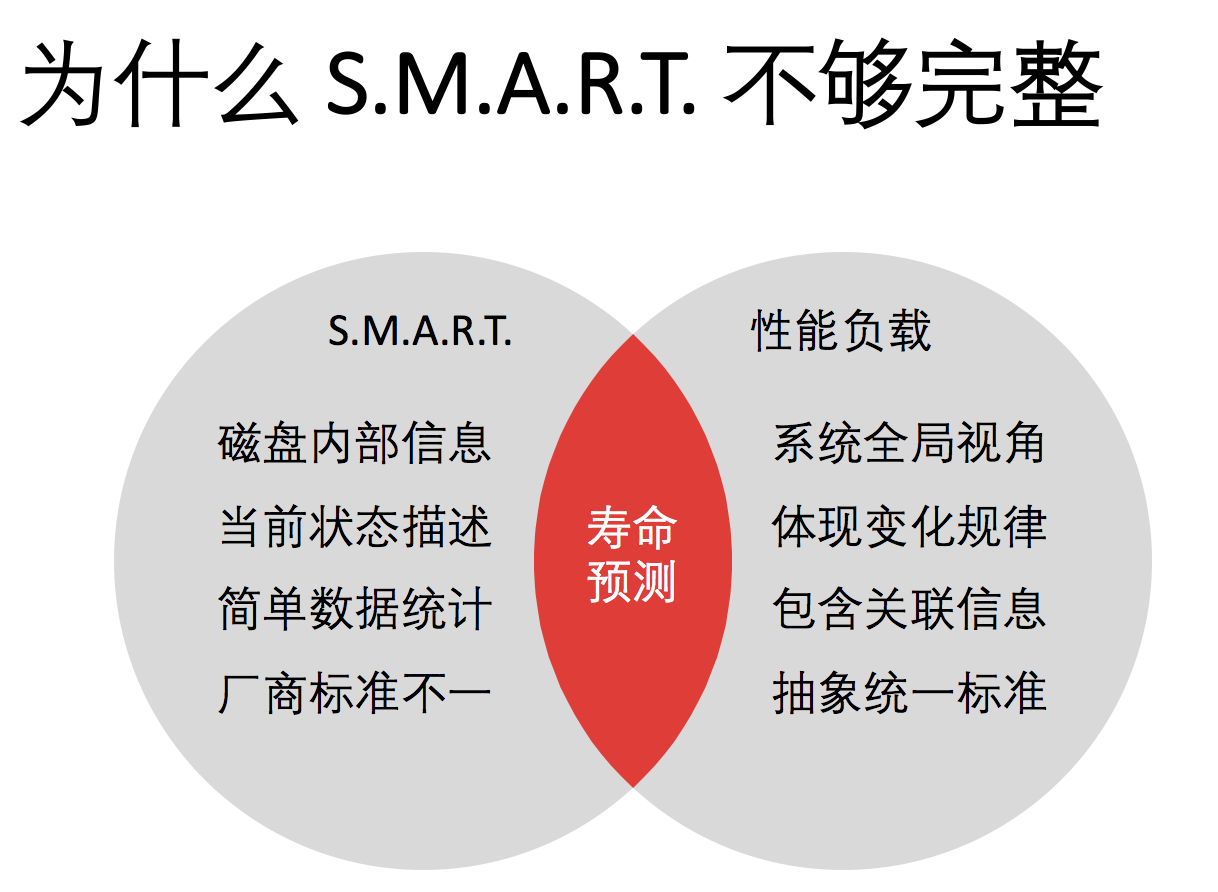
SMART的东西在所有的存储介质里面今天都有,但是为什么SMART还不够呢?就是因为我们今天问的问题不一样,SMART的数据结构很复杂,描述的出发点是描述磁盘主要的静态的状态,就是这个磁盘是否应该被更换。所以SMART当时设计的时候,目标就是这个。
但是今天的问题是这个磁盘还能活多久,这就不太一样了,多了个时间参量在里面,不是一个纯静态的描述。你告诉我这个盘是该换还是不该换?不是这个概念,而是这个盘在时间轴应该怎么走,纯SMART并不知道应用怎么变。如果这个应用刚巧写了一上午盘,过去半年不再写了,SMART是不知道这个事了。
如果我们想真的准确预测这个盘,在你这个系统里面什么时候坏,必须把应用的负载模式,变化模式带下来,所以就需要有两块内容,一块是SMART信息,一块是性能负载的信息而且是带时间的,综合在一起才能做预测,这是从大的基本框架上。
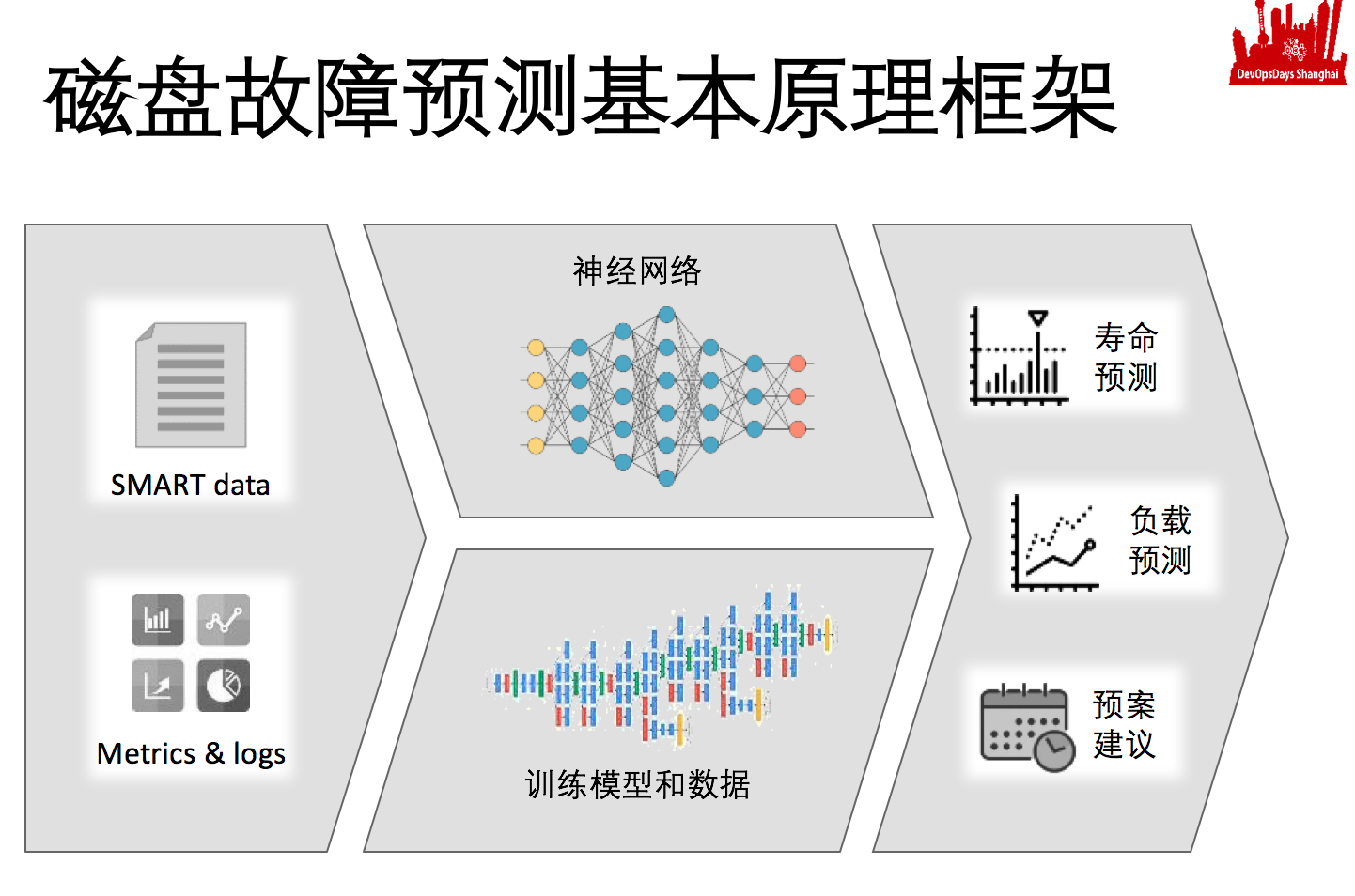
具体的做法,其实就是标准机器学习。现在机器学习都是用神经网络,工作原理是深度学习,大家关心到阿法狗应该知道的。
我们放到磁盘预测里面也是一样,有基本的输入神经元,输出神经元。输入神经元就是特性输入,输出就是归类输出。神经网络就是特性输入和归类输出。
磁盘也是,只不过我归类定义和特性定义需要我们中间摆多少层去建这个神经网络,建好这个神经网络之后,其实是个白痴,有脑子但是没有知识,这个盘多长时间坏,是不知道的。
你要把它训练成资深的专业的运维工程师的话,需要大量的训练模型和训练数据给它。把建好的神经网络的中间各个卷积神经网络,更多有聚合的意思,每一层神经元向下一层神经元传递的时候,有权重的定义和函数的定义,各种各样的按照刚才说的概率的传递。这种概率的传递动态的变化,其实就是让一开始什么都不知道的多维的形状慢慢变成专家系统的形状,最终有这个能力,相当于拿到smart的信息,它就像一个很专业的运维工程师一样,就可以给出来寿命预测,甚至给出你的负载的预测。根据你的寿命预测和负载预测,给你一些修复的建议。它看出来你有一个盘,一个礼拜后会坏,知道你的应用最近一个礼拜,三天都很忙,只有两天比较闲,而磁盘的修复需要两天时间,就建议你现在该修复这个磁盘了。
我知道我这会儿该修复这个磁盘,给一个权限就可以调修复指令,这本身不是个技术问题,更多的是一个安全策略问题。如果足够放心,耦合度要求没有那么高的话,是可以自动调用脚本进行修复的,这里面最核心的就是神经网络和训练。

神经网络建模是靠我们对这些磁盘信息的理解。这个模建起来是很容易的,但里面是有些小学问的。说到底还是基于对磁盘的了解,上图我列了两种情况,磁盘临死前的那一瞬间,它到底发生了什么,从指令响应的曲线来看,这两种基本上都是坍塌式的,前端应用无任何响应了,但是从后端具体的smart信息来看完全不一样。
故障1 smart是4、12、193、242,这几个数据出现大幅度的变化,是与机械性方面有关的。如果非常懂smart的话,看到这个第一反应就是磁盘非正常断电,硬盘受到了一些电冲击损伤。
故障2 smart是197和198地方出问题了,这个是坏道突然卡死。
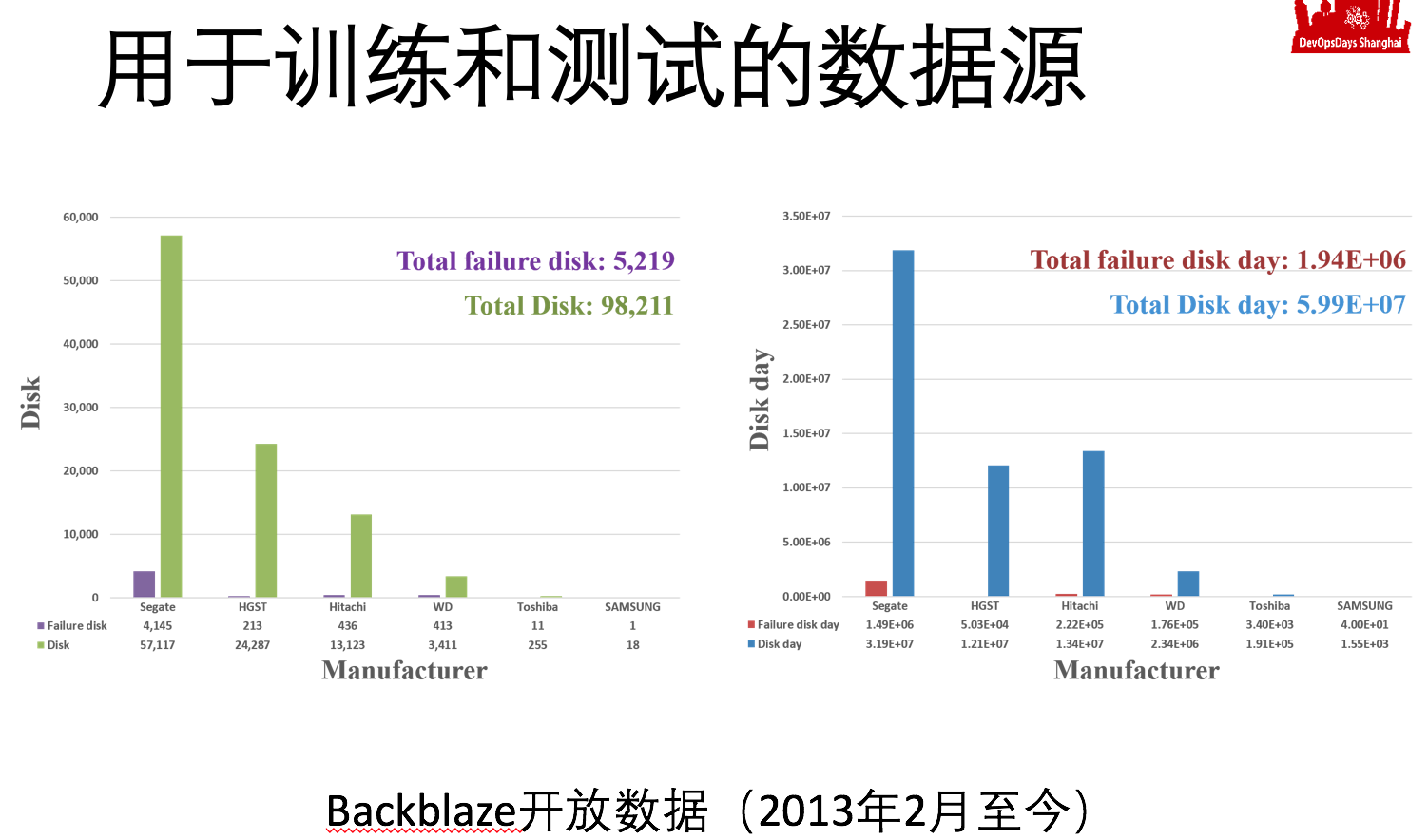
建模后就需要大量的数据源才能得出具有普遍性的结论。数据源需要具有多样性、实际性、真实性。磁盘数据源可以通过backblaze公司网站上下载,这家公司从2013年开始就把它的磁盘每天smart信息开放出来,磁盘总数接近10万,故障硬盘接近6千。因此拿到的样本数实际上是很大的量,大概是6000万的磁盘天,我们把一个样本叫磁盘天,一个磁盘一天的表现,就是6千万个磁盘天,来作为一个训练数据源,当然你得留一部分做做检验。
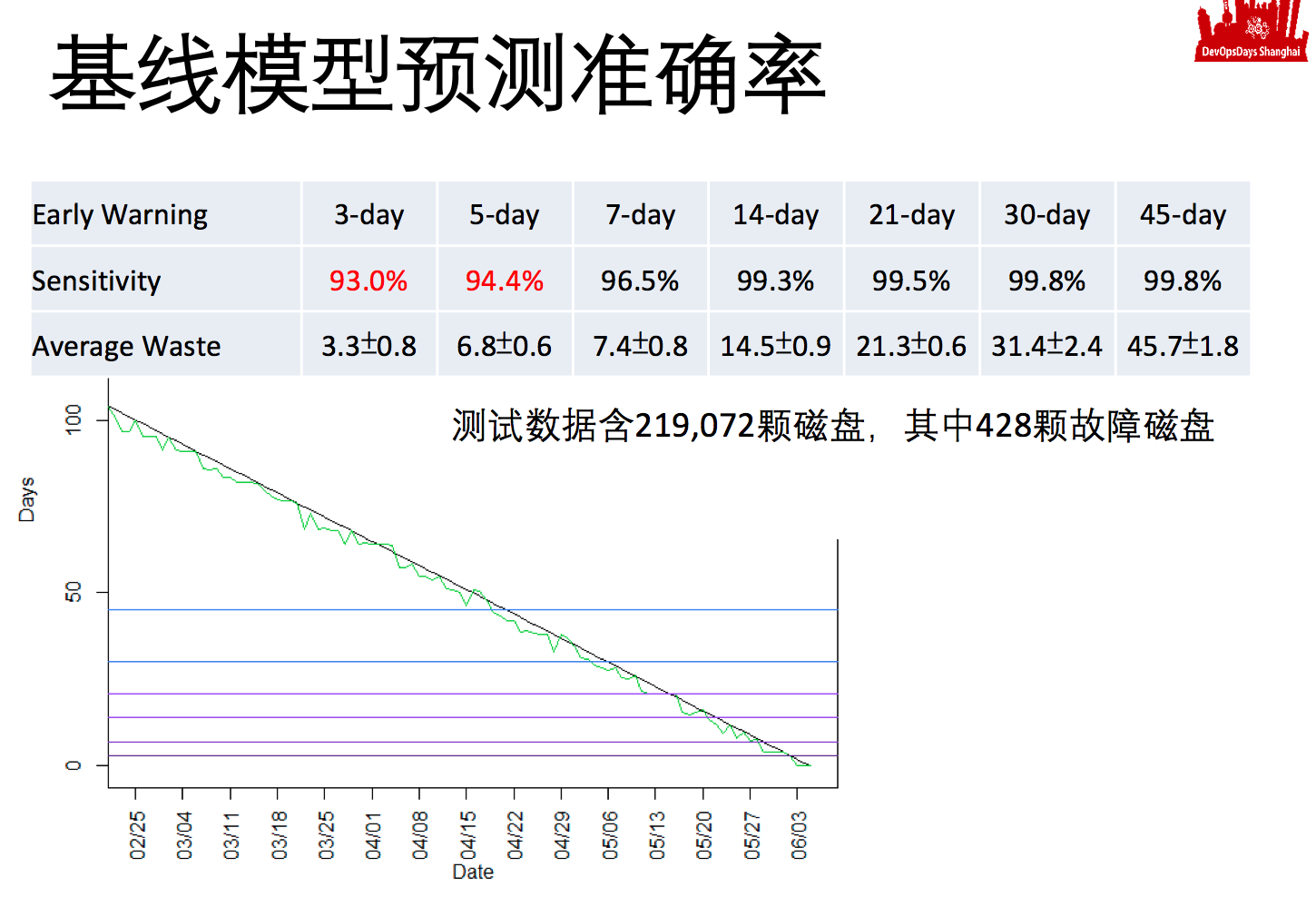
这是我们训练出来的引擎达到的基础效果,你会发现七天以上,我们每七天换一格或者每十四天换一格,预测这个磁盘活多少格的时候,准确率非常高,都是96%以上甚至99%。当然格越大,跟实际故障的点落到我格里的概率就会越大。
但是我现在的基准,就是以开放数据去训练出来的AI,基准的准确率在格子小到三天的时候,就稍微差一点了只有93%,这就是说你纯用smart的信息,而且数据源应用负载可能还不一样,纯用我的基准模型只能做周级别的预测,天级别的预测甚至小时级别的预测还需要负载可以达到95%以上。
我这个AI训练跟本地性能应用相关的不够多,所以训练出来的系统不够聪明,但是随着我的样本数的增加,准确率会提升的越来越多的。
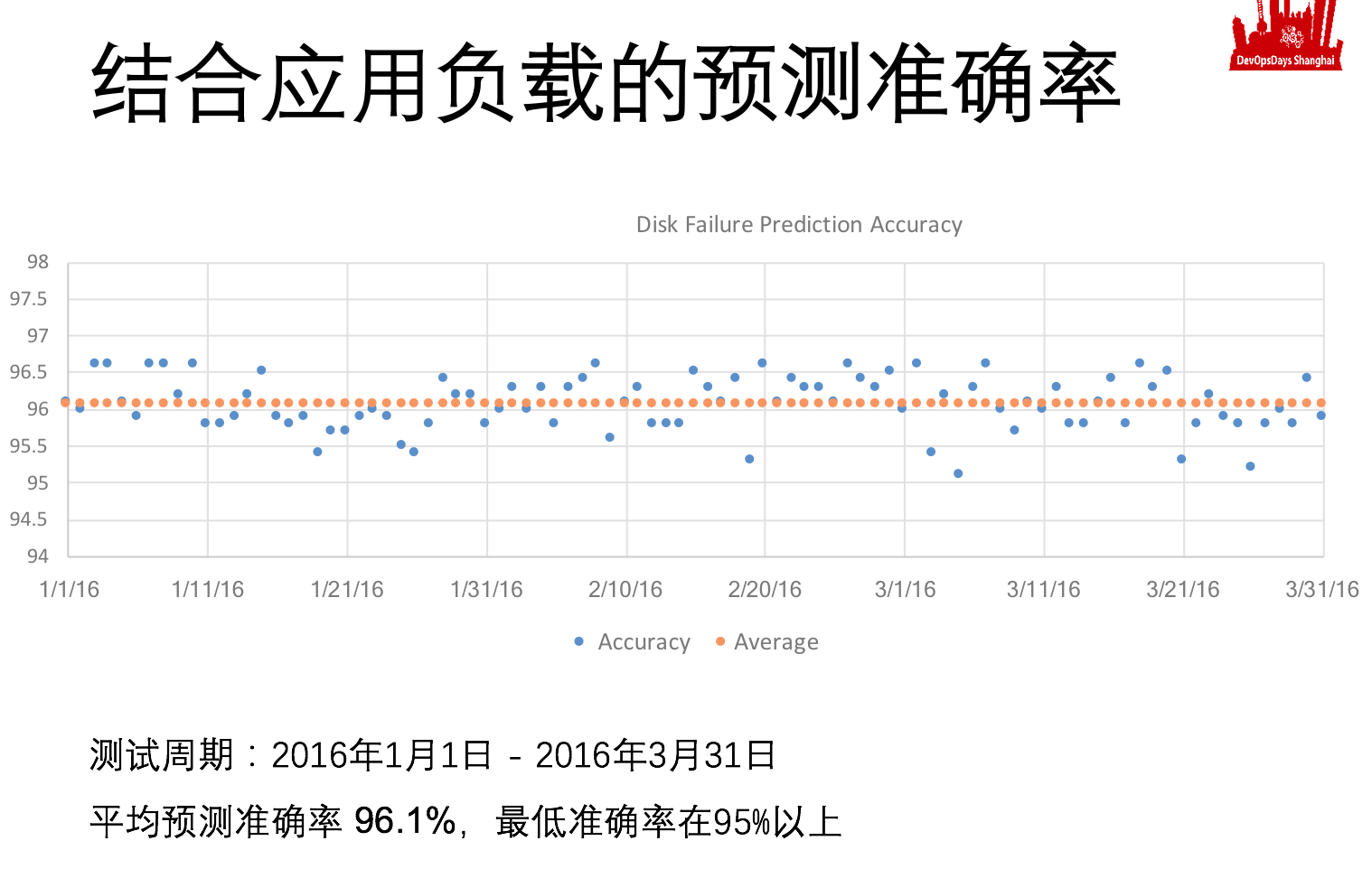
上图是结合应用负载进行的预测,准确率达到了95%以上。

这是用到的一些工具。
- Telegraf 采集CPU利用率,内存利用率
- Smartmontools 不同厂家的smart的信息不一样,不同版本的格式可能也不一样,这个可能需要进一步处理下
- DiskProphet 这是我们提供的云端服务,大家感兴趣的话可以免费注册个帐户体验下,当然我们有商用版,可以更准确的分析,包括生产级的部署和分析。
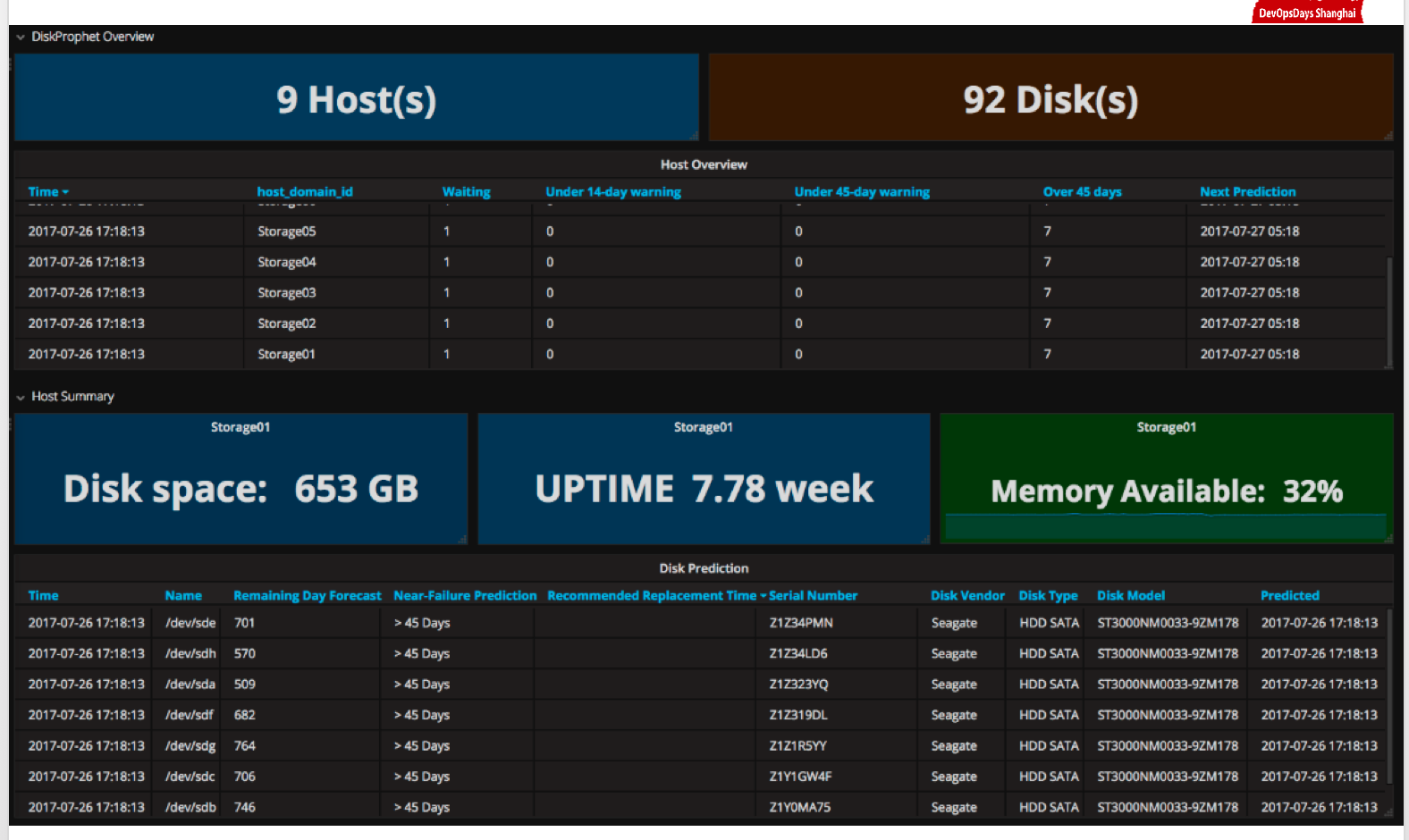
上图是根据我们的DiskProphet分析出来的信息情况。
三. 主动式故障应对的价值和意义
串行化修复 VS. 并行化预防:
- 感知能力提升
- 技术手段开放
- 简化操作流程
- 解耦依赖关系
被动式故障修复 vs. 主动式故障预防:
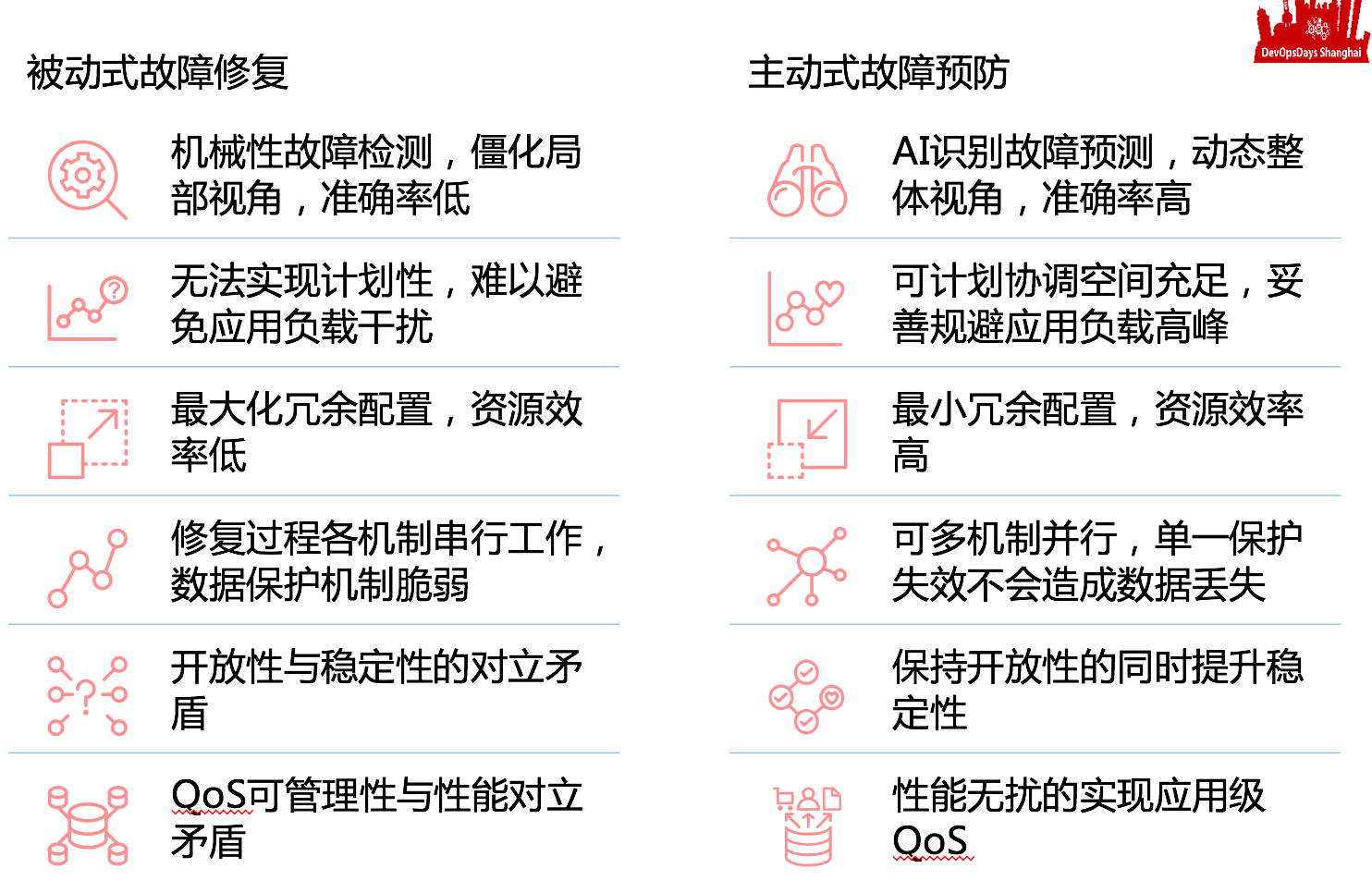
这方面我就不多言说了,主要是把核心的技术介绍一下,总之尽可能在最短时间内止损。
