@Pigmon
2019-04-30T12:14:52.000000Z
字数 1504
阅读 2401
End to End Learning for Self-Driving Cars
学位论文
参考文献写法
Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, et al. End to End Learning for Self-Driving Cars[J]. 2016.
摘要
端到端:
输入:一个前视摄像头的图像
输出:转向命令
1. 介绍
DARPA
Defense Advanced Research Projects Agency 貌似是美国国防高级研究计划局
DAVE
DARPA Autonomous Vehicle
2. DAVE-2
转弯半径
用 代替 来描述转角,因为直线行驶时转弯半径为无穷远,用就是0了。左负右正。
训练数据:
带时间戳的主摄像头图像,驾驶员输入的转角()
以及为了让网络从错误中恢复,增加了额外的图像:车辆跟车道线的偏移量,以及相对于道路方向的航向角偏移
额外增加的图像是从左右2个摄像机采集的。左右2个摄像头的图像相对于主摄像头的偏移和旋转,通过模拟主摄像头的视角变换得到。但没有3D场景信息,所以无法得到精确的视角变换。
因此设定图像中,地平线以下的都是地面,地平线以上的物体都是无穷远,这样只适合平地场景。因此会给地面上附着的物体(如车辆建筑等)带来的扭曲,但并不影响网络训练。
变换后图像的转弯label标记为1,这样可以让车辆在2秒内转到想要的方向。
训练过程:

预测过程:

3. 数据采集
数据在各种天气和光照情况下采集,以及各种道路类型。
地点主要在新泽西。
测试车辆为林肯MKZ,偶尔用2013版福特Focus。
线控:drive-by-wire
采集了时长共72小时的数据。
4. 网络结构
误差计算方法:网络输出的转向和训练数据转向的均方差。

5. 数据选取
采集数据的时候加些额外标注,如道路类型,天气,驾驶行为(车道保持,变线,转弯等)
开始只选择车道保持的数据训练,可以训练CNN的车道保持能力。
每秒选10帧图像。
为了消除直线驾驶偏差,提高了有车道线的帧的比例。
做了数据增强。
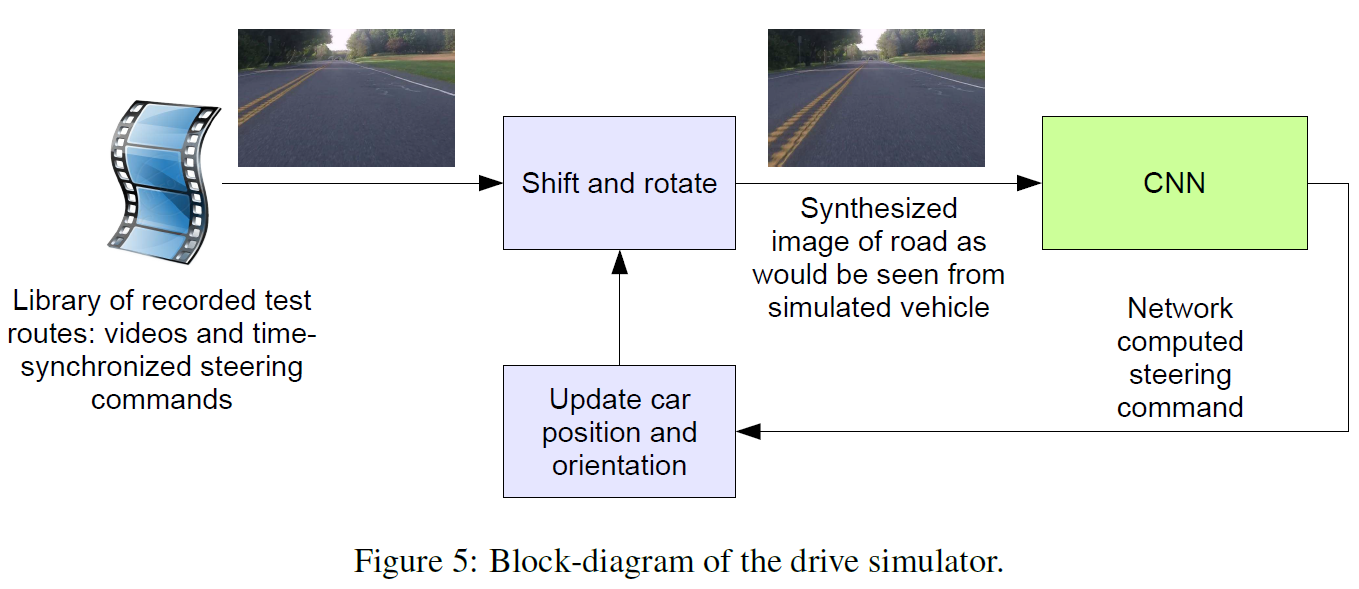
6. 模拟器(软件)
看起来是一个可以用视频采集的关键帧来模拟驾驶过程的软件。即,会根据上一个计算出来的转向命令,来对下一帧图像进行处理,达到持续驾驶的效果。很匪夷所思。
这个似乎可以用3D仿真场景替代。
对人来驾驶过程中采集的关键帧和输入转向命令做时间同步。
由于人类驾驶时也不是一直严格的做到车道保持,他们手动计算出了每帧中的车道中心(是在车道保持时的车辆中心线?),当做(ground truth)。
流程:
取一帧图片,根据Ground Truth进行调整(裁剪,旋转?)
输入CNN
CNN根据这一帧图像输出一个转向命令
更新虚拟车辆位姿
模拟器根据新的车辆位姿,修改下一帧,输入给CNN
重复
模拟器记录偏心距离(车辆和车道线距离),距离大于一定阈值,触发虚拟干预————根据当前帧的原始图像对应的车辆位姿,更新虚拟车辆位姿。
7. 模型评估
7.1 模拟器内评估
自治时间百分比:除干预时间以外(即自动保持车道——自治的时间)占总时间的比例。
虚拟车辆偏离车道线到一定阈值触发干预,干预结果是虚拟车辆返回车道保持航线,每次时间大约要6秒。

左边填补的绿色是因为模拟器会对图片进行扭曲操作以适应虚拟车辆当前位姿;
中间高亮的部分是裁剪出来作为CNN输入的部分。
7.2 实际路面驾驶评估
同样是统计自治时间百分比,不过这次干预是人为干预。
7.3 CNN中间过程可视化
主要就是说明CNN自动学会了检测道路边缘,但对于没有道路的地方也自动的不会检测到有用的特征。
8. 总结
主要是道路边缘不需要人工标注,CNN可自动学习。
需要提高鲁棒性。
改进网络步骤可视化过程。
