@Pigmon
2017-01-11T08:42:17.000000Z
字数 5932
阅读 2301
OLAP Visualization: Models, Issues, and Techniques 笔记
文献阅读
介绍
多维数据的可视化问题越来越多的被各个行业重视。多维数据可视化中最困难的部分是获取数据的维度信息。人类处理多维数据存在很大的困难。处理高维数据在以下几个行业中需求越来越明显:(i)存储大量基因和蛋白质数据的生物学数据库。(ii)实时监控系统的数据库。(iii)用来做决策分析的高级商业智能系统。
传统数据库管理系统满足不了高维数据的需求原因如下:(i)DBMS实现的是OLTP范式,为事物处理进行优化,而故意忽略数据的维度信息。(ii)DBMS的运算符很贫乏,除了满足SQL标准以外其他什么功能都没有,所以用来进行可视化很困难。综上所述,通过DBMS来管理操作内嵌了大量维度信息的多维数据是不现实的。
另外,相关的文献也非常少,因为多年以来这个问题只和生命科学有关。之后,随着诸如生物信息学(Bio-Informatics)这类的学科的发展,这个问题成为了计算机科学中的基础问题之一。与此同时,许多涉及多维数据可视化问题的提案出现在文献中,其中包括新颖的应用领域,例如通过挑战性技术(如聚类和关联规则发现)生成的数据挖掘结果的可视化。
解决这个问题的一个可行方案是通过OLAP(Codd等人,1993; Chaudhuri&Dayal,1997; Gray等人,1997)进行展示(多维数据),关注于通过数据立方体展示多维数据集的方法,而产生了文献中提及的术语OLAP Visualization 和 Visual OLAP 这个研究领域,这两个词在文章的剩余部分中可互换使用。
背景
通常来说,给定一个数据集,的数据立方是一个元组,。
其中:
(i) 是的一个数据域,里面包含的(OLAP)数据单元是通过对中的元组进行SQL聚合(SUM, COUNT, AVG等操作)产生的。
(ii) 是关于定义的,的功能属性集合,也称为的维度;
(iii) 是与的维度相关的层次集合;
(iv) 是底层OLAP分析的感兴趣(的)属性集合,也称为的度量。
OLAP数据立方不仅可以很好的展示多维数据,而且还支持对数据集的一组操作符:
(i) 下钻(drill-down),通过增加度量的细节水平(并降低其抽象级别)在立方体的维度层次中下降;
(ii) 上卷(roll-up),这是下钻的反操作,用于将度量聚集到更低的细节级别(和更精细的抽象级别);
(iii) 旋转(pivot),旋转数据立方的坐标轴,也会包括数据的重聚合。
考虑到数据立方体存储在大容量存储器中,除了可视化功能,OLAP还提供了一组备选方案来表示多维数据集的相关问题:
(i) ROLAP (Relational OLAP,关系OLAP),支持将数据存储在传统的关系型数据库管理系统中。
(ii) MOLAP (Multidimensional OLAP,多维OLAP),配备有高效索引数据结构的多维数组;
(iii) HOLAP (Hybrid OLAP,混合OLAP),混合了上述两种方法,数据立方一部分存储在关系型数据库中,其他部分存储在基于数组的存储中(具体的选择取决于各种参数,例如数据立方的查询负载)
没有进一步的细节,值得注意的是,数据表示的效率对数据可视化和查询的有效性有很大的影响。
Visual OLAP的成果来自与BI技术的融合,以及在信息可视化和视觉分析领域的进展。传统的OLAP前端工具主要用于支持报告和分析例程,仅使用可视化来表达数据。在Visual OLAP的研究中正相反,可视化作为‘交互式查询驱动分析’的方法而扮演着关键角色。这种更全面的分析包括各种任务,例如:从多个角度检查数据,提取有用信息,验证假设,识别趋势,揭示模式,获得见解,以及从任意大和/或复杂的多维数据集中发现新知识。Visual OLAP 不仅支持传统的分析处理操作如下钻,上卷,切片,切块,旋转和排序,还支持更多的交互式数据操作方式,如缩放和平移,过滤,清洗(brushing)?,折叠。
OLAP 可视化:调查
大型数据可视化最初不是用在OLAP上,而是传统数据库。一堆人做过各种工作。VisDB的介绍。
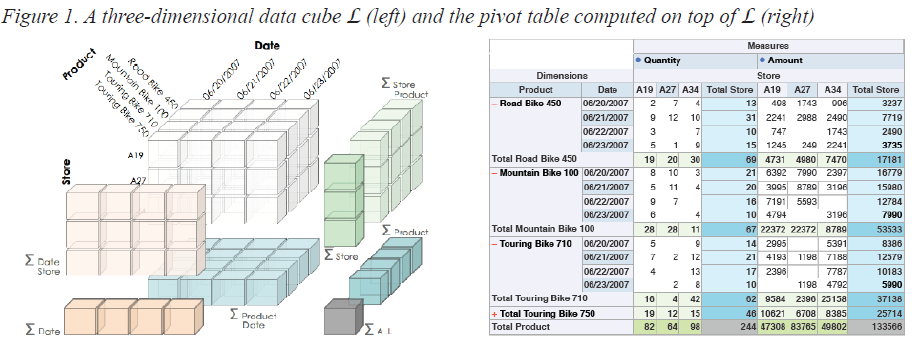
用于分析OLAP数据的传统接口是交叉表,它是通过指定感兴趣的一个或多个度量并且选择用作用于概括度量的垂直(和可选地水平)轴的维度而产生的多维电子表格。这种呈现技术的优势来自于其沿着各种维度汇总数据的能力,以及将以不同粒度级别计算的聚合安排到保持聚合本身之间的“部分”关系的单个视图中的能力。图1例示了将三维数据立方体(左侧)“展开”到交叉表(右侧)的形式,其中在两个表现形式中具有相同粒度的单元格标记为相同的颜色。然而,交叉表对于解决非常规的分析任务是无能为力的,例如识别模式,发现趋势,识别异常值等(Lee&Ong,1995; Eick,2000; Hanrahan等,2007)。尽管有这个弱点,交叉表仍然具有很大的优势,即通过利用人类视觉系统的模式识别现象来节省时间和减少分析推理中的错误(Hanrahan等人,2007)。
现有的OLAP可视化技术基本是交叉表配合众多的业务可视化图形(散点图,柱状图,饼图等等)的形式,或者用其他图表增强交叉表的可视化能力。介绍了Advizor和Polaris。
(Russom,2000)总结了业务可视化软件的趋势,从基本的数据可视化到高级形式,提出区分可视化技术的三个生命周期阶段,成熟,发展和新兴。然后就是Visual OLAP怎么好。
选择用于解决特定问题的可视化技术是非常困难的,因为各种视觉表示(也称为隐喻)可能不仅是任务相关的,而且依赖于域。 成功的Visual OLAP框架需要基于域,任务和可视化的综合分类。 连目前最最先进的OLAP工具也没有解决为特定任务确定适当的可视化技术的问题。 通常,用户必须通过尝试不同的布局手动地找到适当的解决方案。 为了可以支持大集合的多种可视化技术,并且实现从一种技术到另一种技术的动态切换,必须定义抽象层以便描述数据及其视觉呈现之间的关系。
根据这种方法,由Gebhardt等人提出的Tape模型 (1998)建议使用磁带和磁道的隐喻来表示和可视化多维数据域,增强了在磁带内定义层次结构的可能性。
Maniatis et al. (2003a; 2003b)提出了一种称为立方体表示模型(CPM)的抽象层解决方案,其区分两个层:(i)处理数据建模和检索的逻辑层,以及(ii)表示层, 用于表示数据的通用模型(通常在2D屏幕上)。 表示层的实体包括点,轴,多立方体,切片,tapes,交叉连接和内容函数。 作者展示了在表透镜的示例中,CPM结构如何映射到高级视觉布局,这是一种基于交叉表范式的技术,支持多个可缩放的焦点窗口。
在OLAP应用程序中可视化的常用方法依赖于一组模板,向导,窗口小部件和一系列可视化格式。 Hanrahan等人(2007)却认为,一组开放的需求不能通过有限的一组技术来解决,并为他们的可视化分析工具Tableau选择一种不同的方法。 这种创新性由VizQL表示,VizQL是一种声明性可视化查询语言。 VizQL通过允许用户组合各种视觉组件来创建自己的视觉呈现,提高表现力。 图2显示通过简单的VizQL语句创建的复杂视觉呈现的一小部分,不依赖于任何预定义的模板布局。
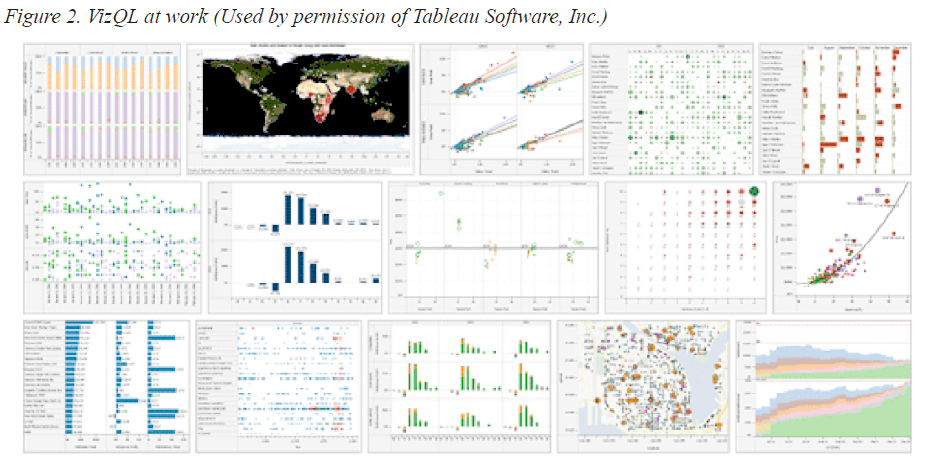
Tableau的设计者故意令其只支持受欢迎的和可靠的可视化集合,例如表,图表,map和时间序列。因此,Tableau方法被约束为生成均匀粒度和有限维度的视觉网格。其他研究人员建议,应该通过扩展基本的图表技术或通过采用还不普及的新晋的可视化技术来充分利用多维和层次属性的数据来扩展Visual OLAP(Tegarden,1999; Lee & Ong,1995; Techapichetvanich & Datta, 2005; Sifer, 2003)。 Tegarden(1999)提出了‘商业信息可视化’的一般要求,并概述了多变量数据的高级视觉隐喻,如Kiviat图和平行坐标,用于可视化高维度的数据集,以及3D技术,如3D散点图,3D线图,floors和walls,以及基于3D map 的条形图。
DIVE-ON(Data mining in an Immersed Visual Environment Over a Network)系统展示了由Ammoura等人提出的一个替代方案(2001)。 DIVE-ON的主要思想是提供一种沉浸式的视觉环境,用户可以通过“走动”或“飞行”这类操作来与分布式多维数据源进行交互。 因此,DIVE-ON巧妙地利用了人类与空间对象交互的自然能力,从而显著的增强了知识获取过程的体验。 在其核心层,DIVE-ON利用OLAP技术,以便有效地支持数据的多维度。 可以说DIVE-ON是OLAP可视化研究领域最独特的方向之一,其中一些特征与视觉娱乐系统颇为相似。
OLAP的可视化研究的另一个分支集中于开发能够在不同聚合级别呈现数据的多尺度可视化技术。 Stolte et al. (2003)描述了它们在Polaris系统框架内的多尺度可视化的实现。底层视觉抽象是支持多个缩放路径的缩放图,其中缩放操作可以与维度轴相关联或者由不同种类的交互触发。 Lee和Ong(1995)提出了一种多维可视化技术,采用并修改OLAP中的并行坐标法进行知识发现。这种技术的主要优点是它可扩展到几乎任何数量的维度。每个维度由垂直轴表示,并且聚集沿着每个轴以条形图的形式对齐。轴的另一侧可以用于以更高的细节水平生成条形图。从原始平行坐标技术采用的多边形线用于指示沿着各个维度计算的聚合之间的关系(如果两个聚合中的事实条目的基本集合重叠,则存在关系)。
Mansmann和Scholl(2007)专注于解决在改变细节等级的同时,丢失前续查询步骤中的聚合的问题,并且建议使用分层布局来获取同一显示内的多个分解的结果。作者介绍了一类多尺度视觉隐喻,称为增强分解树。 通过沿着指定维度分解聚合来创建视觉层次结构的级别,并且节点包含布置成嵌入式可视化(例如,条形图)的结果子聚集,用各种层次布局和嵌入式图表技术来处理不同的分析任务。
Sifer(2003)提出了一种基于维度层次的协同视图的OLAP的多尺度可视化技术。 使用空间填充嵌套树布局来呈现具有作为底层节点附加的合格事实条目的每个维度层次。 通过在每个维视图内缩放,隐式执行下钻和上卷。 过滤通过在任何维度层级上选择(或取消选择)感兴趣的值来实现,导致在所有维度视图(全局上下文协调)中突出显示合格事实条目或者从显示中消除不合格条目(仅结果协调)。
在(Techapichetvanich&Datta,2005)中提出了一种类似的交互式可视化技术,称为分层动态维度可视化(HDDV, Hierarchical Dynamic Dimensional Visualization)。维度层次结构显示为分层对齐的条形棒。条形棒被分割成矩形,每个矩形表示与维度的相应成员相关联的聚合度量值的一部分。颜色强度用于标记满足指定范围条件的记录的密度。与(Sifer,2003)中不同,维度级别条柱没有显式地彼此链接,允许沿多个维度拆分相同的聚合,从而保留反聚合任务的执行顺序。Choong et al. (2003) 等人提出的一种寻找多维聚集表示的技术。可能有助于提高任何可视化的分析质量。该技术解决了沿着维度轴对聚合进行排序的问题。 默认情况下,度量值的排序受维中的值的词典顺序影响。 为了使模式更加明显,用户必须手动重新排列排序。算法自动为表示中的度量的排序,以便最佳地显示可以在数据集中观察到的模式(例如,趋势和相似性)。
Cuzzocrea et al. (2006; 2007) 提出了一个有效支持多维数据立方体的OLAP可视化的创新框架。该框架在例如空间 - 时间数据的可视化以及科学和统计数据的可视化等多个实际应用中具有广泛的适用性。通过有效地处理目标数据立方体的OLAP层次结构,该框架的新颖性在于计算基于语义的分区,令OLAP数据单元语义相关,从而产生所谓的语义感知桶。 此后,通过基于高效四叉树的数据结构进一步压缩所得到的分割表示,用于可视化这些数据结构。 这种压缩表示最终产生一个新的多维直方图,称为层次驱动索引四叉树汇总(H-IQTS, Hierarchy-driven Indexed Quad-Tree Summary)。
在(Cuzzocrea等人,2006; Cuzzocrea等人,2007)中提出的方法的主要优势在于,通过令用户可以进入这些空间的子分区,使得高维空间的可视化和查询行为得到显著的改善(这些子分区是基于语义划分而不是其他的分区规则)。这个结论基于以下事实——用户在交互过程中通常会对特定的部分分区感兴趣,而不是对全部的分区感兴趣。从实用角度来说,Cuzzocrea et al. (2006; 2007) 展示了虽然H-IQTS的压缩效率与目前主流的基于直方图的数据立方压缩技术差别不大,但其可视化的效率要比其中一种要高几个数量级。
未来趋势
OLAP可视化研究仍处于初步阶段,在这一领域还有很多工作需要完成。 OLAP研究这一分支的成功的关键在于可视化OLAP在大量实际且领先的应用中有广泛的需求,例如多个流数据源的实时监测和其结果的可视化、高级知识发现工具,包括聚类,关联规则发现、频繁项目集挖掘和子图挖掘等领域。
未来OLAP可视化研究方向可以确定以下3个主题:(i)整合在数据仓库管理系统中,以达到在多维数据集上完成一体化的知识生成,处理和可视化工作。(ii)用于可视化集成的数据立方体/数据仓库方案的技术,目标是研究可视化从多个且不统一的数据源中获取的多维数据域的方法。(iii)多维数据库的可视化查询语言,旨在定义一个新的范式,可以让智能用户与多维数据交互。这也产生了新的挑战——设计一个强大的知识提取语言的理论基础。
总结
如何有效地可视化OLAP数据是需要创新模型和技术的,且充满吸引力的研究主题。目前,研究成果并不多,需要在这一领域开展大量工作。
基于这些考虑,本文提出了OLAP可视化模型,问题和技术的概述,同时也很谨慎的分析了当前各种研究的优势和缺陷,以及证实了这些研究在当前的实际应用。
