@agpwhy
2022-01-24T06:43:13.000000Z
字数 2071
阅读 1134
王胖的生信笔记第35期:中介效应分析
开始前先讲个事,之前看到很多教程,看着文笔很怪,不像是自己写的。

有些甚至要收费

就找了些关键词找一找。一看,是国外大学一些课程的公开资料。。。这钱也太好赚了。

这次就讲一个看自 https://zhuanlan.zhihu.com/p/341517271 的教程。不过这个教程是把原始教程讲清楚的(https://towardsdatascience.com/doing-and-reporting-your-first-mediation-analysis-in-r-2fe423b92171)。还是比较好的。
什么是中介效应(Mediation)?
简单来说,中介效应就是一种间接,非直接的效应。
比如天气热,大家去海滩的人多了,去海滩的人多了,就穿泳装的人多了。这时候就可以看去海滩的人对于天气对于人们穿泳装的作用有多少中介效应。就是说是因为天气热,就有些人直接就想穿泳衣了,还是因为通过影响去海滩的人树,使得大家想穿泳衣。
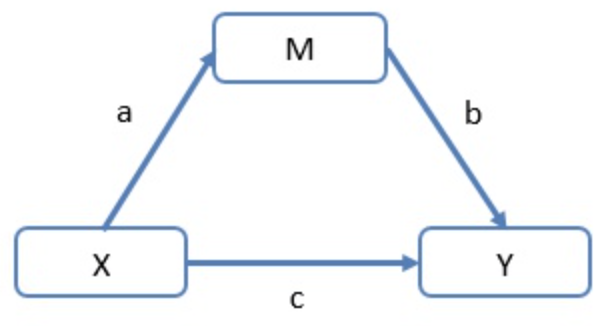
这张图上,X是天气温度(自变量),M是去海滩的人(Meidator,中介变量),Y是穿泳衣的人数(因变量)。M就是中介变量(Mediator),中介者需要是endogenous的,也就是必须和X相关。不能是处理措施或者是实验设计的条件。通过对中介者效应的分析,可以看出来有多少是X直接Y的,有多少是X通过M来影响Y的。
示范案例
R里自带一个iris(鸢尾花)的数据集。这里我们可以学习生成一个数据集,来模拟这个数据集相关的Mediator和最终变量。
这里的自变量是叶片长度,中介变量是对蜜蜂的吸引力,因变量是被蜜蜂授粉的几率。
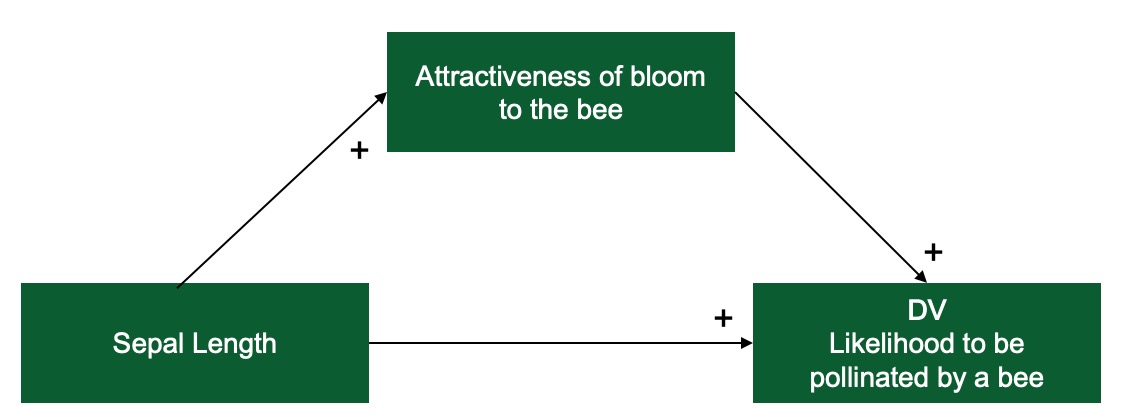
由于中介变量和因变量是没有的,我们需要生成剩下两组数据。同时通过定量生成,可以知道中介效应实质上是多少。
df=iris #读取鸢尾花数据set.seed(12334) #后面会通过随机来生成中介变量(鸢尾花对蜜蜂的吸引力以及鸢尾花被蜜蜂授粉的几率)df$random1=runif(nrow(df),min=min(df$Sepal.Length),max=max(df$Sepal.Length))df$mediator=df$Sepal.Length*0.35+df$random1*0.65 #这里我们可以知道35%的中介变量的值和自变量相关,65%是随机噪音df$random2=runif(nrow(df),min=min(df$mediator),max=max(df$mediator))df$dv=df$mediator*0.35+df$random2*0.65#这里我们可以知道35%的因变量的值和中介变量相关,65%是随机噪音。这里的35%就是中介效应
那么通过上面可以看到,大约35%乘35%,也就是12.25%的因变量和自变量相关,也就是自变量对因变量的总效应。
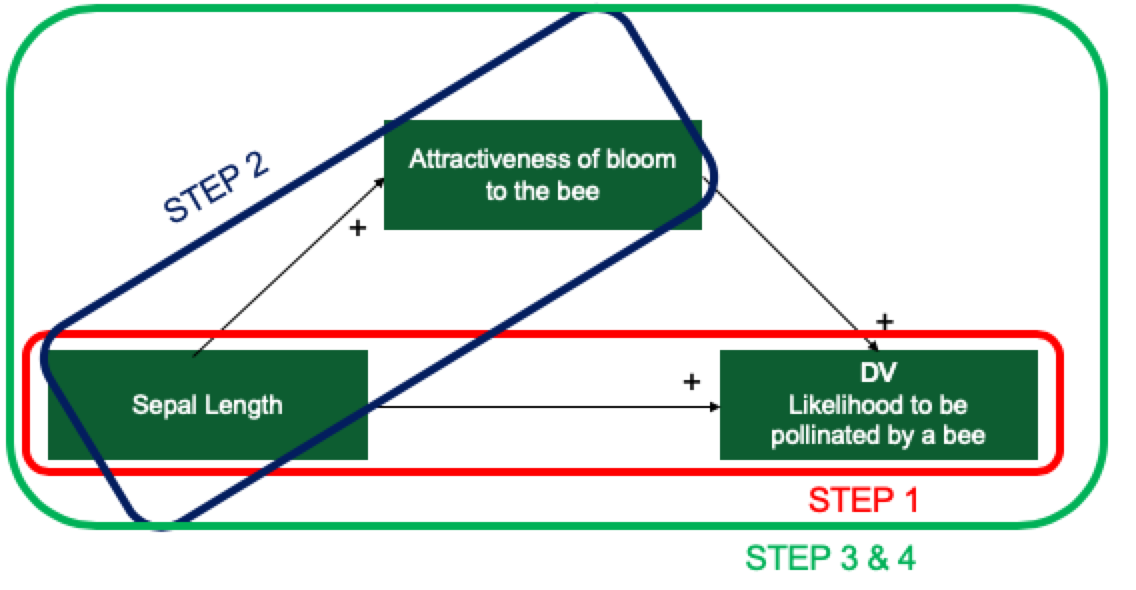
一步步看
- 第一步,检验自变量对因变量的总效应
- 第二步,检验自变量对中介变量的效应
- 第三步,同时检验中介变量以及自变量对因变量的效应(检验一个的时候控制另一个)
- 第四步,比较直接效应和间接效应
图示如下:
第一步:
关于自变量对因变量的总效应这一步有两派思想:要么认为只有总效应显著,才有中介效应;要么认为总效应不显著也可以有中介效应。
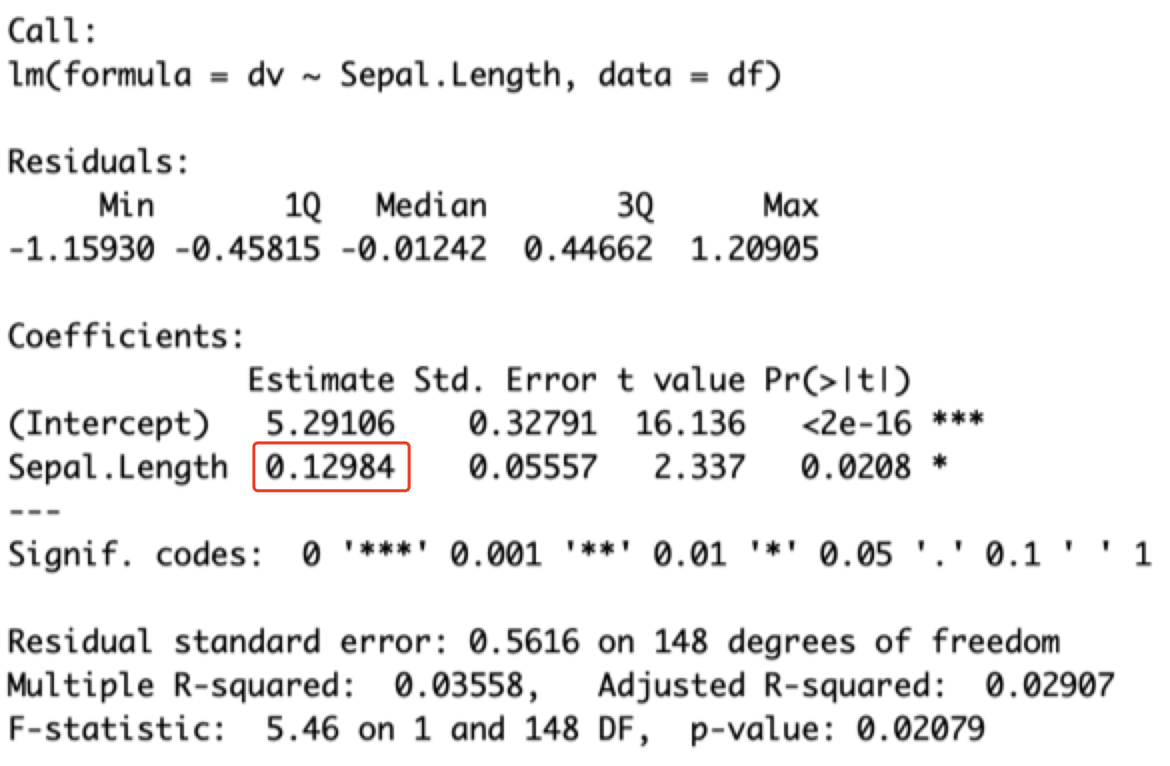
fit.totaleffect=lm(dv~Sepal.Length,df)summary(fit.totaleffect)
此时可见是0.12984(和12.5%差不了太多)。且p值小于0.05。
第二步:
如果要说明中介效应存在,第二步是一定要算出来小于0.05的。
fit.mediator=lm(mediator~Sepal.Length,df)summary(fit.mediator)
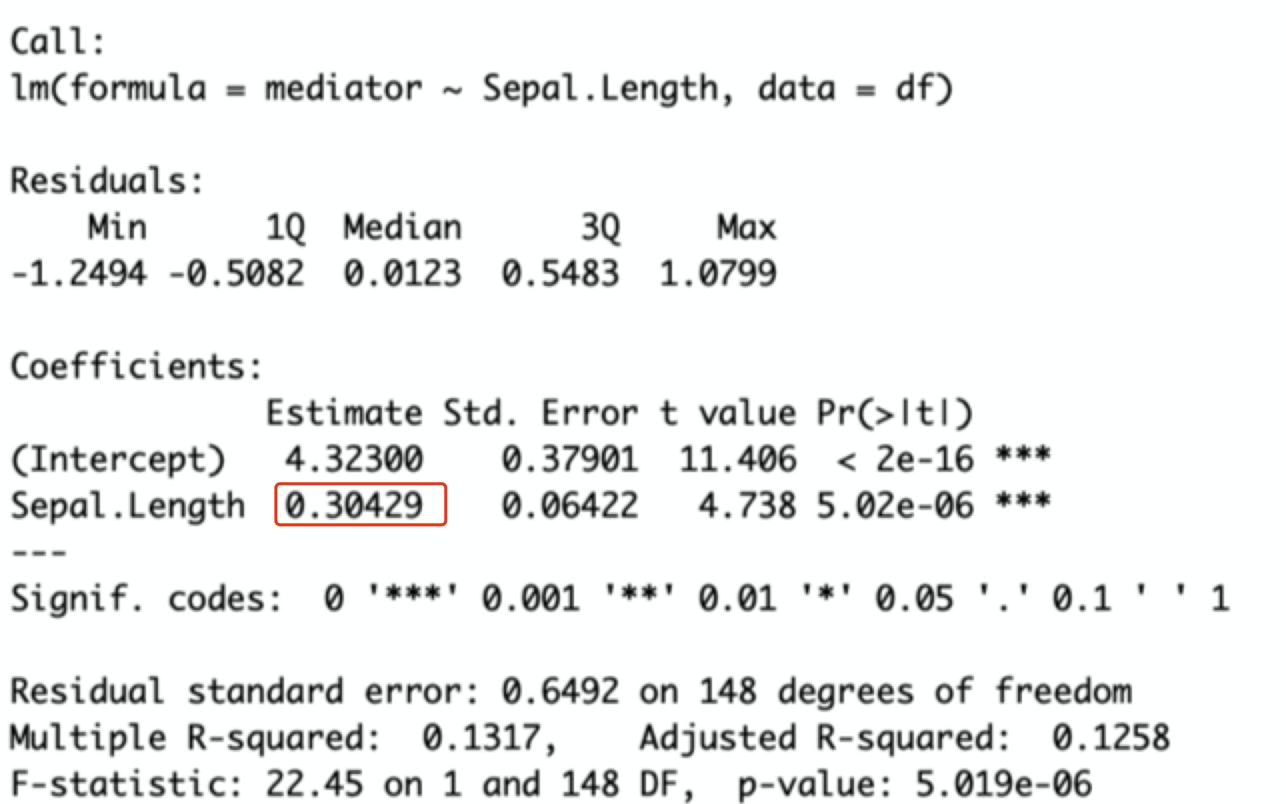
此时可见是0.30429(和35%差不了太多)。且p值小于0.05(甚至是*)。
第三步:
fit.dv=lm(dv~Sepal.Length+mediator,df)summary(fit.dv)
需要中介变量对因变量的影响比起自变量来说更多。
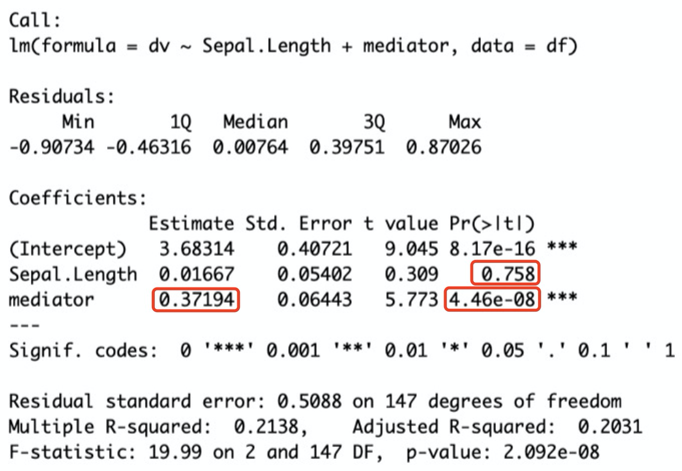
这样来看,中介效应是0.37194(接近35%),p值小多了(中介显著,自变量不显著这里可以认为是完全中介,即自变量对因变量的作用完全的是中介变量造成的;如果中介显著,自变量显著是部分中介)。
第四步:
library(mediation)results = mediate(fit.mediator, fit.dv, treat='Sepal.Length', mediator='mediator', boot=T)summary(results)

这里结果解读如下:
- ACME :自变量对因变量的间接作用,这里实质上是35%乘35%,算出来是0.30429乘以0.37194。
- ADE :是自变量对因变量的直接效应。这里实质上是第三步里那个不显著的那个值。
- Total Effect :总效应,即ACME+ADE。
- Prop. Mediated 中介效应的占比,是用间接效应除以总效应得到的,即ACME/(ACME+ADE)。
不过问题来了,秩和水平的如何进行这样的分析呢?
