@agpwhy
2022-03-07T12:20:22.000000Z
字数 2234
阅读 362
王胖的生信笔记第39期-关于Wordle
最近大家可能都玩过汉兜(https://handle.antfu.me/,没玩过的赶紧试试,真的好玩)。这个游戏是从Wordle来的,不过原版猜测次数是六次,而且规则因为是英语稍有不同。设计这个游戏的公司已经估值超过十亿刀乐了。
今天就来简单试一下分析Wordle的一些数据,使用的是Rview上的教程。稍微改了一些地方。
https://rviews.rstudio.com/2022/02/21/wordle-data-analysis/
配置环境+获取数据
library(httr)library(dplyr)library(stringr)library(ggplot2)library(ggthemes)library(scales)library(tidyr)url = "https://www.nytimes.com/games/wordle/main.18637ca1.js"wordle_script_text = GET(url) %>%content(as = "text", encoding = "UTF-8")
这是nyt上面出Wordle题的函数。里面内容很多,我们需要的数据是五个字母的单词(为啥我觉得这里可以埋个五字不行的梗)。就需要使用stringr里面的函数进行拆分提取。
word_list = substr(wordle_script_text, # 里面第一个五个字母词语是cigar;最后一个是shavestr_locate(wordle_script_text, "cigar")[,"start"],str_locate(wordle_script_text, "shave")[,"end"]) %>%str_remove_all("\"") %>%str_split(",") %>%data.frame() %>%select(word = 1) %>%mutate(word = toupper(word)) # 去除\ 保证每个词语独立,同时转化为大写
反正一共两千多个词语。
统计字母频率
letter_list = word_list %>%as.character() %>%str_split("") %>%data.frame() %>%filter(row_number() != 1) %>%select(letter = 1) %>%filter(letter %in% LETTERS) %>%group_by(letter) %>%summarize(freq = n()) %>%arrange(desc(freq))
这里是把两千多个词语全部拆成字幕,统计字母频率.
filter(row_number() != 1)这一步是因为走到那里会有个多出来的c(为啥会有可以去思考一下),不是原来2309个词语里的。
统计出来的词频是这样的
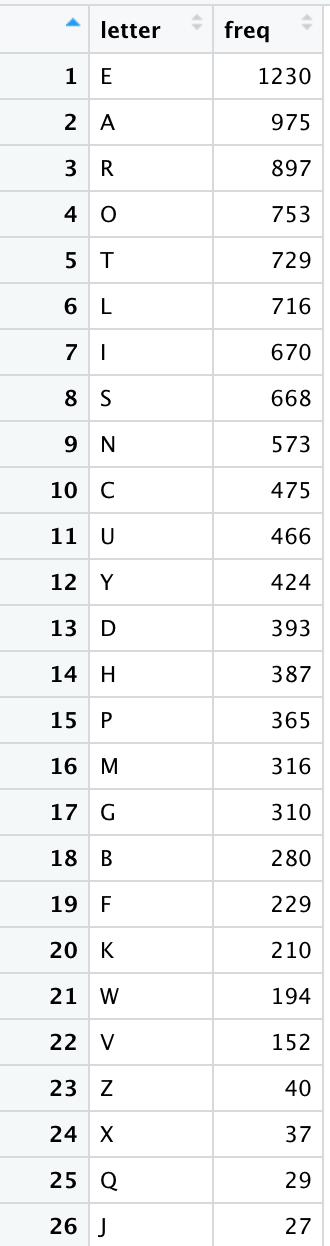
这和英语语料里的字母词频并不完全对应(取样问题)

(来源于https://en.wikipedia.org/wiki/Letter_frequency)
可视化一下
ggplot(letter_list, aes(x = reorder(letter, (-freq)),y = freq,fill = reorder(letter, (-freq)))) +geom_bar(stat = "identity") +scale_fill_manual(values = mycolors)+geom_text(aes(x = reorder(letter, (-freq)),y = freq,label = comma(freq, accuracy = 1),vjust = 1),size = 2) +scale_y_continuous(labels = comma,expand = c(0,0)) +theme_clean() +xlab("Letter") +ylab("Frequency") +labs(caption = "Modified by WangPang\nshengmingwangjat@qq.com") +ggtitle("Letter Frequency in Wordle's Official Word List")+theme(legend.position="none")
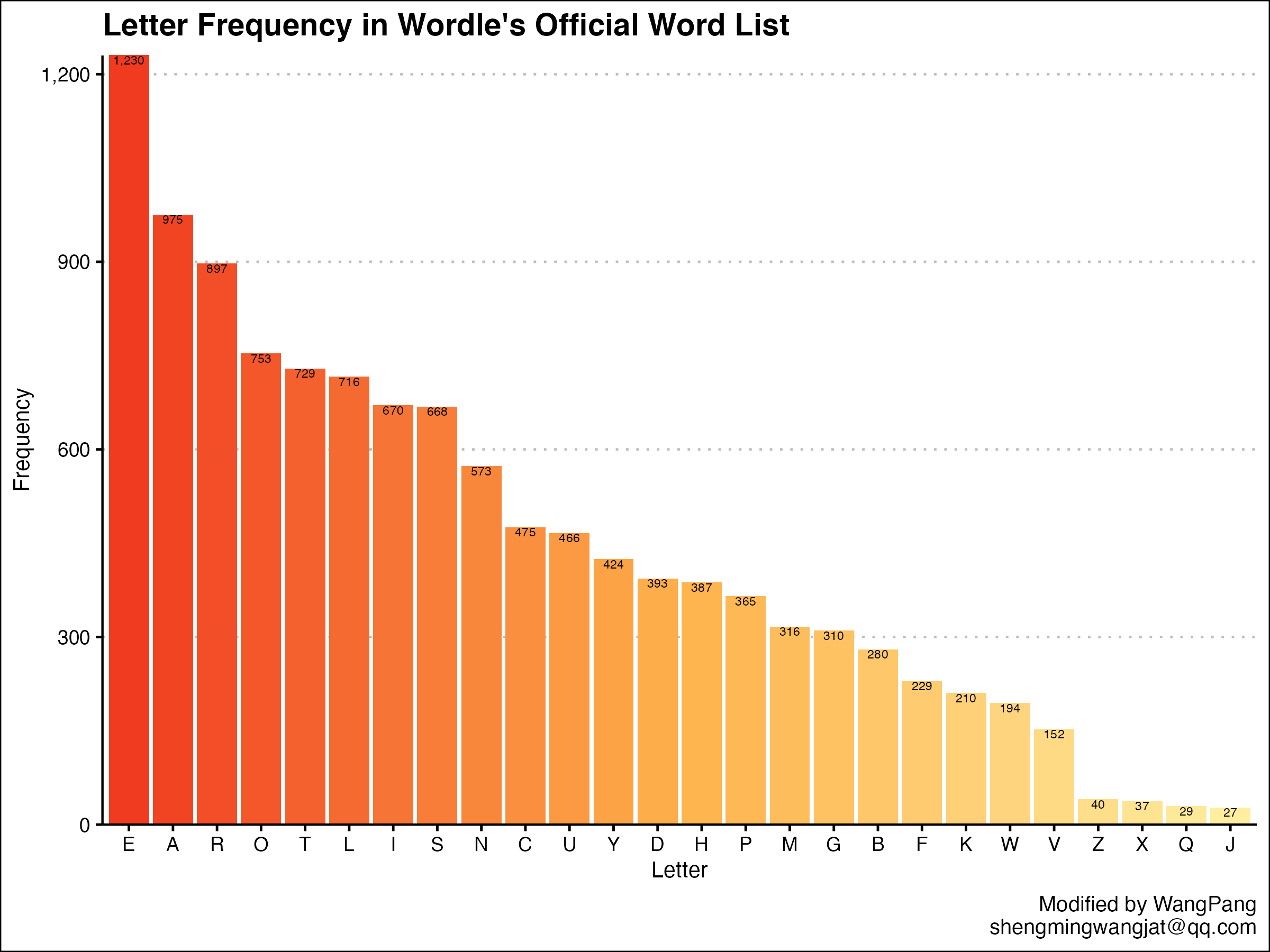
这里前面配色不会的可以发邮件or私信交流呀。
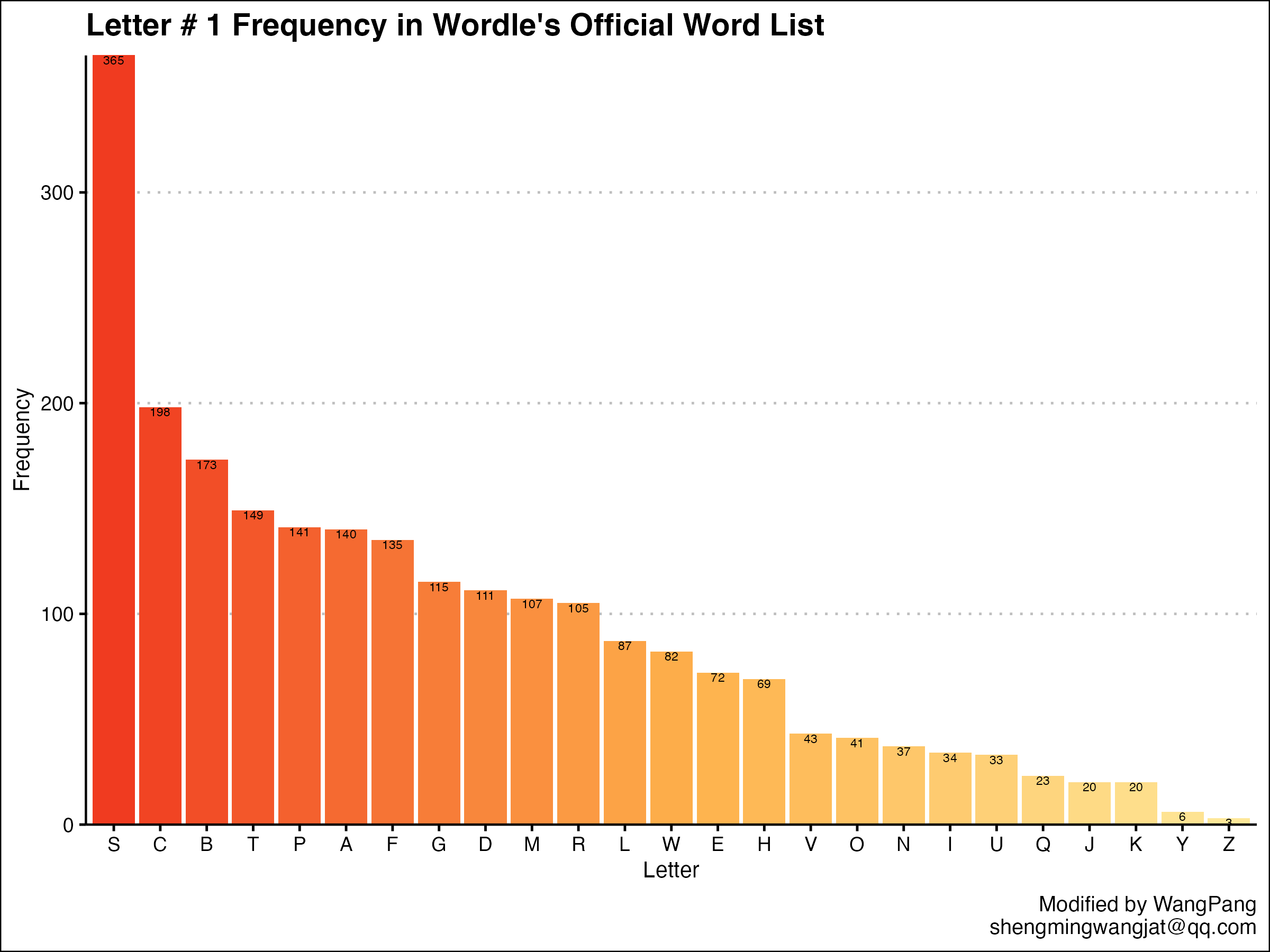
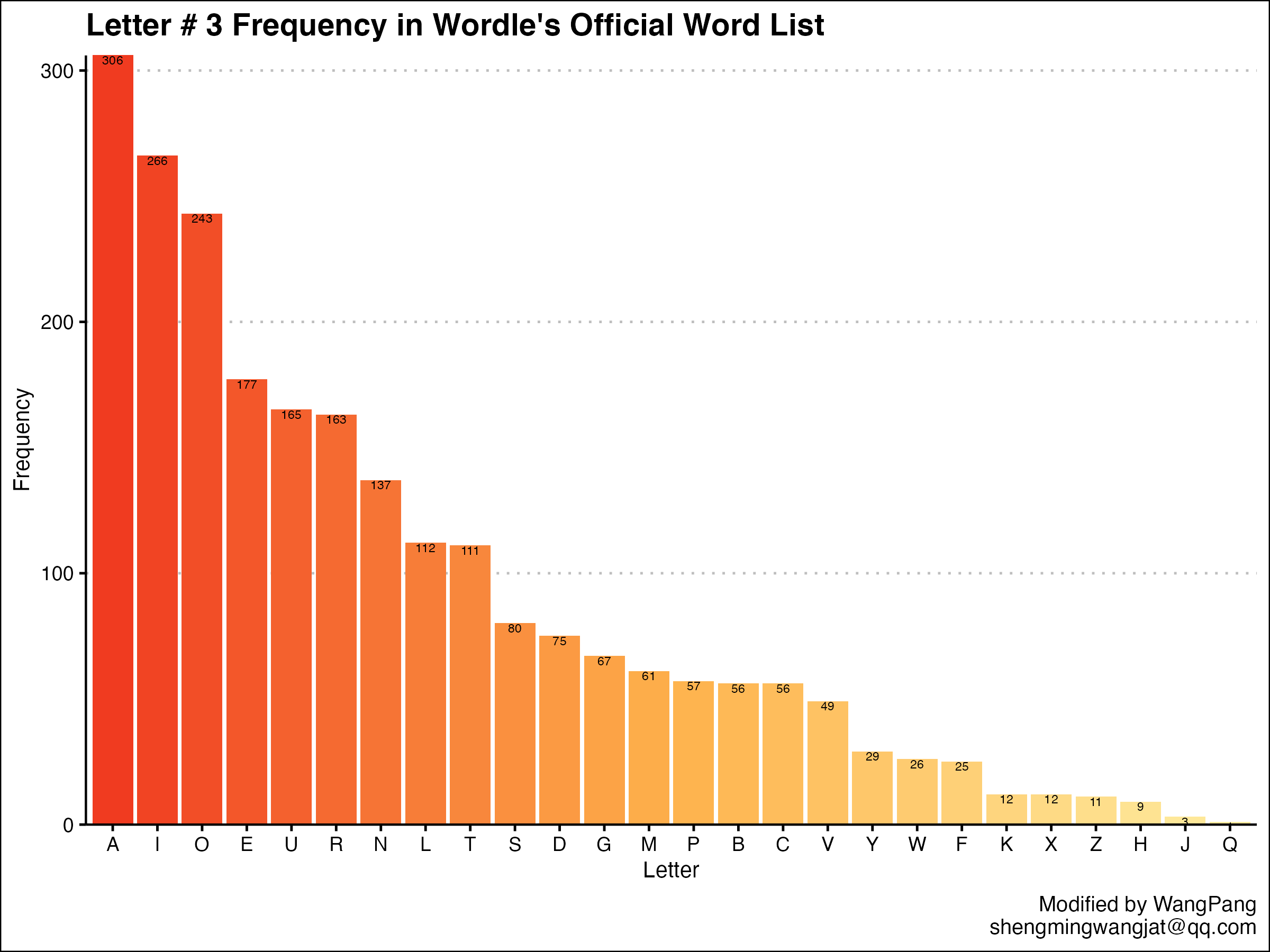
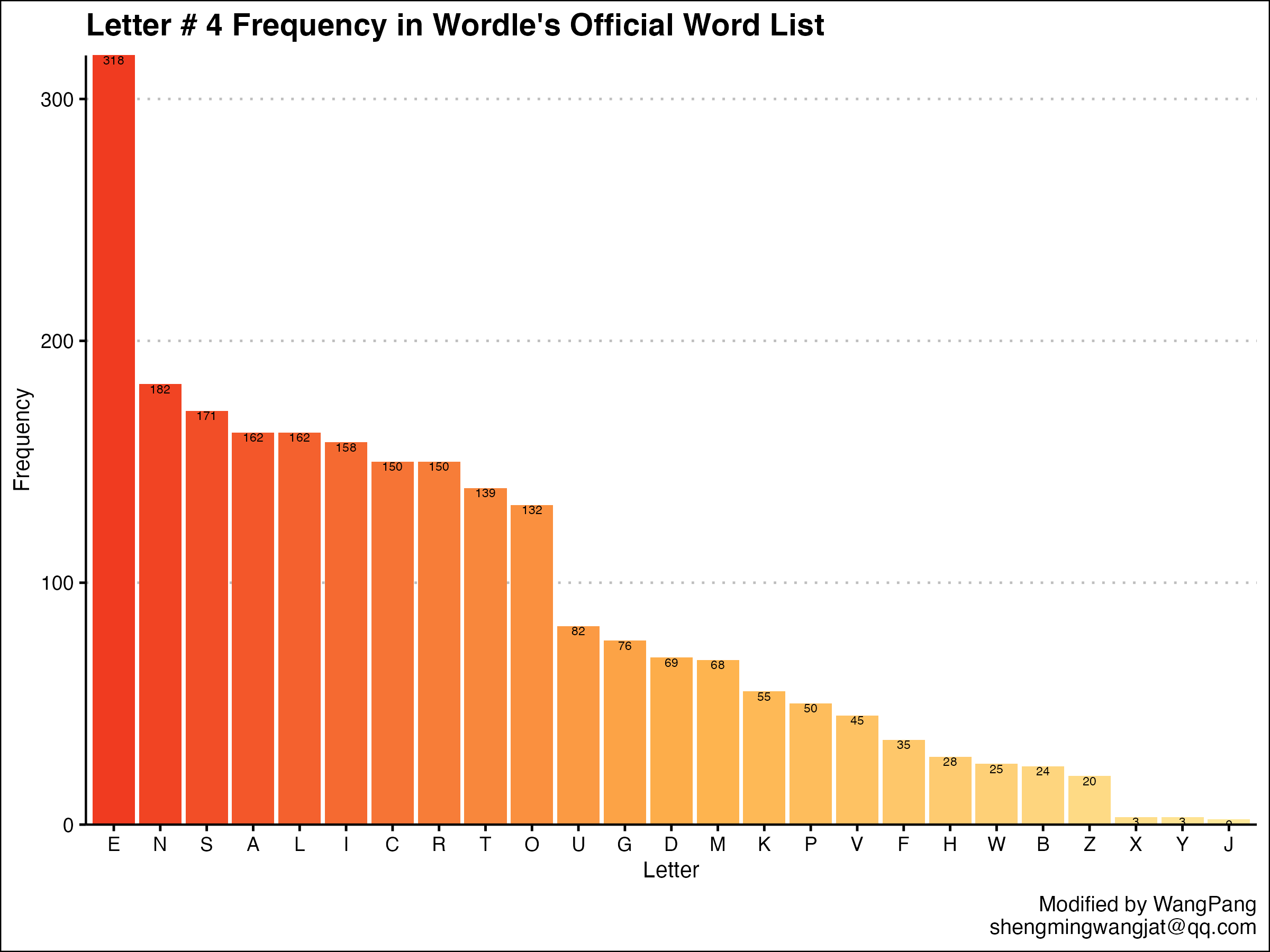
进一步统计各个位置的字母频率
ordered_letter_list = word_list %>%separate(word,sep = "",into = as.character(1:6)) %>%select(-1,"l_1" = 2,"l_2" = 3,"l_3" = 4,"l_4" = 5,"l_5" = 6)
可以思考一下为啥要在select那里去掉第一个。
build_df = function(df, col_name) {new_df = df %>%group_by(letter = eval(sym(col_name))) %>%summarize(freq = n()) %>%arrange(desc(freq))return(new_df)}
利用这个函数可以拆分各个位置字母的数据。
然后写个循环批量输出图
极简打分法
这一次先写到这?下次介绍一下极简的打分方法。
