@zhongdao
2020-01-09T05:53:53.000000Z
字数 24233
阅读 3822
导出-电影数字拷贝卫星传输冗余恢复方案草稿1.0
未分类
1. 前言
1.1 电影行业的数字拷贝发行背景
我国电影数字化发展到今天,电影数字拷贝的发行由于数字电影内容的数据量巨大以及现有传输条件的制约等原因仍然采用胶仍然以硬盘邮寄方式为主, 这种发行严重制约着我国电影产业整体向数字化演变的进程。
电影数字拷贝发行的特点如下:
1. 传输数据量大, 一部片子通常在200G到400G。为了迎合观众对电影画质和音效的高质量要求,无论是拍摄还是后期制作都采用高分辨率和高码流图像画质,这就使得最后用于发行的DCP包也越来越大;同时为满足不同群体的观影观众,发行商还会将同一部影片的各种发行版同时发行,这就会将一个影片的DCP包变成两个甚至更多。
2. 完整性要求高。接收到的影片内容若是出现 任何一个比特的错误 , 影片都不能通过服务器端的完整性校验,也就无法将影片文件存入至服务器。
3. 一对多的传输,影片发行一般是由某个发行商发送至全国所有上映该片的影院 , 对于传输来说,就是一个发送端同时传送影片至上千个接收终端 ,截止2019年第三季度,我国纳入国家电影专资办统计范围的电影院数量已达10650家,电影银屏数量已达67060块。发送端无论是设备性能或发送带宽等方面压力都较大。按照传统方式需要寄送的硬盘越来越多。
1.2 可用网络的技术应用背景
我国共有三类可用于电影数字拷贝分发的传输网络 : 互联网 (基于 IP 方式) 、卫星与有线数字电视网。
常用的互联网传输 协议一般有 TCP 和 UDP 两种。
UDP 组播方式最主要的问题在于进行组播传输需要得到收发两端之间网络中所有路由器的支持 , 而现有的网络运营商都未提供此服务 , 因此 如果采用UDP组播需要搭建专网 , 搭建与维护费用都较贵。
基于TCP的发送,一个发送端需要同时与上千个影院接收端建立连接 , 并为每个连接传送一次电影数字拷贝,相当于一部影片被传输了上千次。如果传送至一个接收端所需的带宽为N,发送至上千个接收端则要求发送端的带宽为N的上千倍。TCP这种点对点面向连接的传输方式不仅加大了发送端的负担,也提高了对发送端网络的要求。此外,TCP的可靠传输机制也增加了收发之间整个传输链路的压力 ,容易造成网络拥塞。
有线电视网络单向、广播的特点使得此传输系统在完整性与安全性方面存在一些不足。有线电视网络单向传输的特点使得传输过程中一旦出现数据丢失的情况,丢失的数据将无法补回,接收端接收到的数据文件 也将不完整。在小数据量文件传输时 ,针对这一问题的解决办法一般是重复传 输数据文件 , 直至所有接收端接收完整为止。但对于大数据量的数字电影文件来说 , 由于单次传输的 时间就较长 (假设采用单个频道传送 , 按时长 90 分 钟的 2 K影片数据量约 120GB 计算 , 单次传送至少 需要 120GB ×8 ×1024/ (35Mbit/ s ×3600) = 8 小 时) , 再采用重复传送来解决数字电影传输丢包问题 的话 , 将导致每部影片的传送效率过低。
按照传统的传输方式,专业IP网络带宽较大,传输速率快.适合大数据量的电影数字拷贝传输,但网络费用高,且随着影院数量增多.网络成本急速增长;国家广播电视光缆干线网带宽大,速率高.但现有国干网仅连接了全国各省会与直辖市.由省会传送至各市、县的影院存在“最后一公里“的问题.而这“最后一公里”的光缆铺设与维护的成本都较高:有线电视网络在我国发展多年.技术成熟、覆盖范围广.但一个频道的传输带宽仅8MHz.传输速率低.传输电影数字拷贝的时间很长;卫星网络属于无线传输.带宽较大.传输速率能达90Mbps,覆盖全国,缺点是转发器租赁费用高.但随着影院和影片数量增多,网络成本将逐渐下降。因此.对于逐年增长的影院与影片来说.电影数字拷贝卫星传输具有一点发送、多点同时接收的特点,卫星网络是适于我国专业电影数字拷贝的传输方式之一。
1.3 中美两国的数字电影拷贝卫星传输方式
使用移动硬盘传输电影数字拷贝的成本也远远大于使用卫星传输电影数字拷贝的成本。电影数字拷贝卫星传输具有一点发送、多点同时接收,传输速率与信道费用不因接收点数量增加而改变的特点,符合我国电影产业快速发展的趋势,相对于IP网络更受电影行业的喜爱。
在中美两国,目前广泛使用的数字电影拷贝传输方式,基本都为卫星网络传输方式。随着数字化、网络化、信息化技术在电影产业中的应用,电影数字拷贝传输方式由最初的移动硬盘邮寄的方式向卫星传输与移动硬盘邮寄混合的方向转变。
1.3.1 中国的情况
由于卫星网络是单向广播网,并且电影数字拷贝的数据量较大,在卫星网络的实际信道中总是存在这样或那样的干扰,无失真的理想状态在实际应用中是达不到的,这样就很难保证电影数字拷贝在发行传输过程中仅靠一次传输就完整的将数据分发到各个终端接收机上,一旦传输过程中发生数据丢失或误码,这部分数据将无法找回。
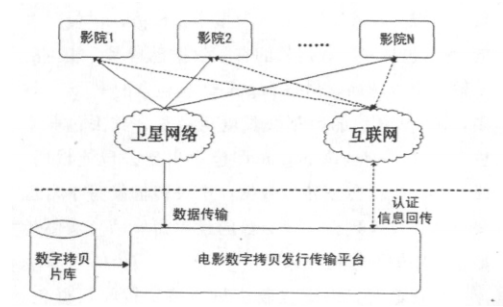
卫星传输结束后,如有数据包丢失或错误.接收机可将未接收成功的数据包序号由互联网发向传输平台.申请重新补发。接收补包.接收完整后自动解密校验。丢失的数据信息通过互联网回传至发送平台.由发送
平台集中统计所有接收机的数据丢失信息.统筹安排.为每轮补发选择适合的补发策略.以保证本轮绝大部分机器能完成接收。
采用90Mbps的速率进行电影数字拷贝的分发,总数据量在400GB左右,传输时间达12个小时。
对于丢失的数据,重复1到2次补发后基本都能接收完整。
正常情况下平台整体传输成功率会在95%以上。
1.3.2 美国的情况
针对卫星传输过程中的数据丢失或错误 ,该系统按情况采用前 向纠错码FEC、双向信道补包与硬盘寄送三种方式。如果数据丢失或错误较少,接收端可采用前向纠错FEC通过计算自行修复;如果数据丢失或错误较多,FEC不能修复所有丢失或错误的数据,则需要通过双向信道由发送端补发;如果数据丢失或错误太多以致于双向信道补发时间过长,将为该影院寄送硬盘。
1.4 目前中国电影行业电影数字拷贝卫星分发系统技术标准
电影数字拷贝目前的国内标准是:
《电影数字拷贝卫星分发系统技术要求和测量方法》(GD/J045-2013)
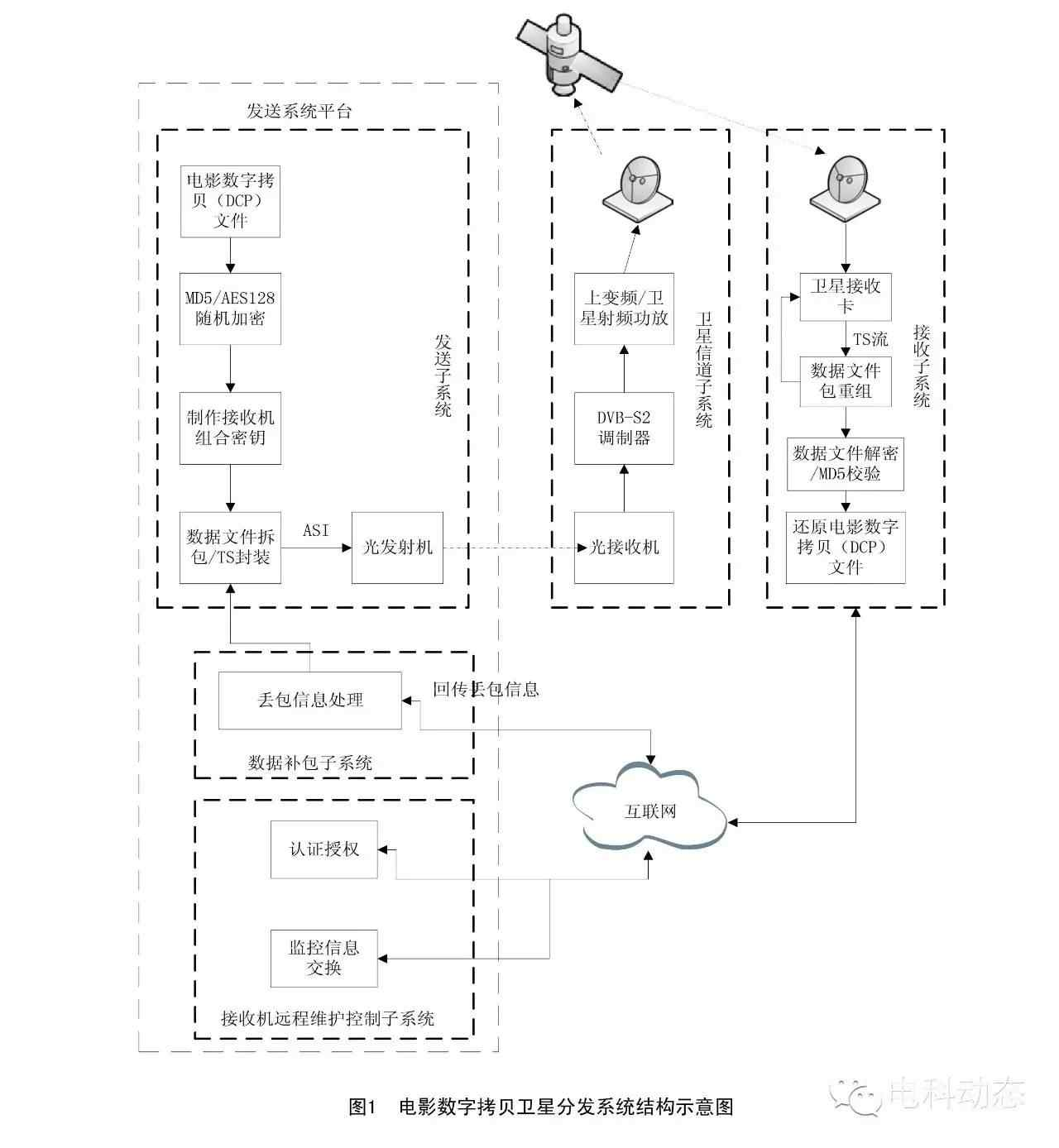
数据补包子系统与接收机远程维护控制子系统通过双向互联网信道与接收子系统通信,实现丢包信息回传、处理。
就文件传输而言,具体描述如下:
电影数字拷贝传输发行平台将组织好的一系列Segment包数据依次发送出去,通过卫星信号上行站将信号输送到卫星,全国各地的影院利用卫星接收天线接收信号,再通过线缆传输到影院接收终端。影院接收终端对于接收到的一系列Segment包进行分析,数据完整有效的Segment包进行拆包并拼组成电影数字拷贝文件,不完整或错误的Segment包,接收端只能抛弃掉,并进行记录,最后通过互联网将该接收终端本轮的接收情况汇报给中央传输发行平台。

当中央传输发行平台发送完一轮数据后,开始汇总和统计所有接收终端的数据接收情况,对于丢失的数据,按照第一轮发送的要求,重新提取组包再发送,直到所有终端接收完整。
卫星单向传输大文件时,有时因为各种原因,第一次传输时文件会出现错误,目前的规范设计的是等待之后的时间再次重传,无法一次传输完整和正确的文件。
1.5 本文提出的优化解决办法
1.5.1 说明
当前数字电影拷贝的分发,本质是巨型文件集合面向大规模接收端的一点对多点的卫星单向不可靠链路的低成本分发,是个对资源、时间和资金成本要求极优化的问题。
在目前的技术发展和资金时间成本考虑情况下,单独采用卫星、或者IP互联网都无法最优化地解决这个问题。
卫星的接收端小站基于成本考虑,都是无卫星回传信道的单向接收小站,通过便宜的IP互联网来解决双向通信,解决补包的问题。接收端众多的情况下如何补包是个关键问题。
为了解决这个问题,本文提出的方法就是生成可控冗余恢复度的文件卷,在卫星终端接收完成原始数据之后,如果文件有损坏,那么就通过互联网按需下载冗余包来恢复损坏的部分,降低了互联网的传输量,而通过P2p网络协议,降低了互联网发送端的带宽压力,解决了众多接收端卫星小站的巨型文件集合的修复和完整性问题。
需要说明的是,冗余文件可以通过2种方式传输:
对于冗余文件通过卫星传输信道发送的情况:
当卫星传输协议层短期内的数据段的丢失将使得超过卫星信道编码FEC纠错能力而造成数据有中断,采用应用层面文件级别的恢复卷后,将把短时间发送的数据包丢失的风险散开,这样某一个时间段内大的误码率也不会影响其系统整体的纠错能力。因为冗余恢复卷集在恢复能力范围内(x%)具有恢复任意处文件错误的能力,所以整个原始巨型文件集合数据的可靠性得到了保证。
对于冗余文件通过互联网按需下载时的情况:
如果卫星传输过程中数据丢失或错误较多,不能本身修复,则通过互联网由生成冗余恢复卷的发送端发送;接收端根据校验的错误的百分比或损坏块的个数,从PServer按需下载,这样避免了通过互联网传输巨量的大文件,按需仅传输需要的小文件,降低了成本和传输时间。而且因为冗余修复卷可以修复任意的错误,所以对不同位置发生错误的众多接收端也都支持。
1.5.2 总结
在数字电影拷贝的巨型文件情况下(超过200G)如何解决在如下条件下:
1. 卫星的单向不可靠链路。
2. 发送端带宽资源等成本较高,以及互联网的传输时间长。
3. 现有的卫星+互联网的传输方案占用卫星信道
4. 接收端数量众多,上限达到10000家。
实现了:
从一点到多点的,借助互联网,短时间传输到大量单向卫星接收端,不给互联网线路增加压力的效率较高的传输方案。
为此采用了如下技术:
1. 非传输信道层的纠错,基于Reed-Solomon的文件级别的冗余恢复机制。
2. 冗余修复文件根据文件名来区分恢复块的多少,每个文件包含的恢复块数量呈倍数递增,可以按照任意原始文件损坏的块数来确定下载的冗余修复文件名,从而在应用层按需下载按损坏或丢失的块的数量来修复。
3. 冗余创建端PServer和卫星接收修复端PClient为服务器/客户端(Server/Client)的架构,便于通讯和交换信息。
4. 冗余修复文件的分发通过非中心化的p2p网络。
5. 在p2p网络架构中,对于由于防火墙等原因无法对外提供服务的TMS接收端,采用多个中间节点做缓存,提供冗余文件的传输,形成兼容p2p协议的高效BFT传输网络。
解决了:
1. 文件级别冗余,解决了卫星信道的不可靠。超过传输层卫星信道编码FEC纠错能力而造成的数据中断,采用应用层面文件级别的恢复卷后,将把短时间发送的数据包丢失的风险散开,这样某一个时间分段内的大误码率也不会影响最终的整体纠错能力。
2. 按需下载冗余修复文件,减轻了发送端的互联网压力和成本
3. 与卫星发送端技术松耦合,兼容其传输系统,互不影响。
4. 通过基于p2p协议的BFT网络分发冗余修复文件,进一步降低了发送端成本,支持到大量的接收端。
1.5.3 架构
面对大规模的接收端,对于基于IP的互联网的一点对多点的传输瓶颈,即使是比原数字拷贝要小的冗余修复文件,则采用P2P的传输协议进行传输,
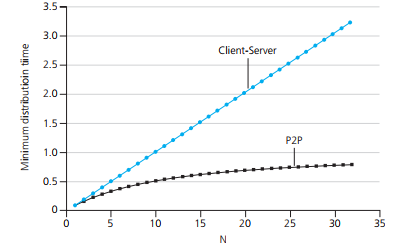
客户端-服务器体系下,分发时间随着对等方数量线性增加P2P体系下,分发时间随线性增长而趋向一个常数。
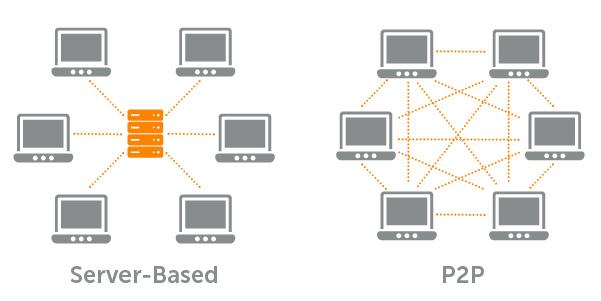
基于服务器和基于p2p的网络对比
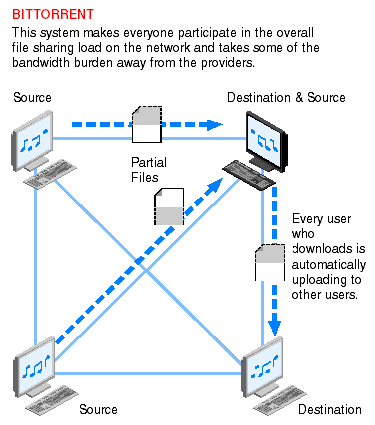
p2p网络采用的Bittorrent协议的分片传输机制

冗余传输恢复架构图
1.5.4 特点与效果
特点:
并行进行:卫星端接收文件,BFT接收修复包;
文件接收完进行错误修复,无需二次分发;
通过p2p的BFT网络高效按需下载少量修复包;
兼容卫星传输包格式;
效果:
卫星下载后无需二次卫星重发,经过修复,即可确保文件正确;
1.5.5 意义
其业务场景和意义如下:
- 电影行业的影片文件比较大,上百G大小,通常在200到400G之间。传输是个比较麻烦的问题,考虑到成本以及现有设备技术规范等原因,目前往往通过快递硬盘的方法分发到各个影院。如果通过互联网传输,则对影院的带宽要求较高,成本和时间也比较长。
- 目前通过卫星中心站向各家影院的单向传输,总体成本较低,接收时间稳定,支持的影院数量较多,缺点是传输一旦出现小部分错误(接收端会通过较窄的互联网带宽给予卫星中心站反馈),整个文件就不完整,需要重新制定重发的日程,给一小部分没有收到完整文件的影院进行分发,而且是整个文件重发,即占用了卫星中心站的带宽资源,又影响了影院的接收时间期限。
- 互联网中心化的传输要想支持分发到多家终端,例如ftp,http等传输方式,能够支持的接收端数量非常有限,时间成本和带宽成本非常高。目前互联网的传输模式要想支持大规模分发,即大文件分发到各个终端比较好的方式是采用p2p的(bittorrent)传输模式,每个接收终端同时也是发送的服务端,其传输时间与接收的终端数量呈非线性关系,可以支持非常多的终端数量, 但是目前的带宽成本平均下来与卫星相比,还是非常高,而且对整个网络的流量占用是非常高的,因为网络带宽的波动,单个文件对于接收端的传输的时间也呈波动状态,不稳定。
- Parity Volume Set Specification 是一个公开的冗余恢复规范,最初是用在usenet上的文件损坏问题,通过生成冗余文件来恢复原始数据,其原理采用Reed-Solomon编码,类似RAID的容错恢复的技术,其规范2.0 可以支持对PAR文件通常具有不同的大小,允许您选择适合您需要修复的损坏数据量的大小。 这样损坏的数据量和需要修复的par文件之间根据创建冗余时的参数而定,呈一个线性关系,也就是损坏少,需要恢复原始数据所需的冗余文件也少。已经有多个客户端支持其规范,其中Linux上的par2客户端名称叫做par2cmdline。
- 对于大文件传输而言,卫星单向传输支持接收端数量大,总体成本低,但是传输出错时,需要重传整个文件来恢复,占用传输通道。互联网传输通过p2p传输时也能支持大规模的接收端,不会出错,但是总体成本高,占用互联网的总带宽资源使用太高。 为了既利用卫星单向传输的低成本,又利用互联网的准确传输特性,需要有合适的方案来解决大文件传输到到大规模接收终端的成本,传输时间稳定性的问题。
- 一个比较优化的方法就是在卫星传输时,根据原始大文件数据生成冗余恢复包,每个卫星接收端在接收完第一轮的数据之后,下载冗余包判断损坏的量,然后再次下载所需数量的par文件,进行恢复。为了避免中心化传输支持并发规模和带宽资源的消耗问题,采用p2p的分发模式进行分发冗余文件,每个接收终端既是接受者也是发送者,有效支持了卫星传输的低成本,时间稳定性以及较低互联网带宽下的少量冗余恢复文件的传输问题。达成了低成本,大规模稳定接收的问题。
2. 简明原理
2.1 错误检测与纠正背景介绍
在信息理论和编码理论以及在计算机科学和电信中的应用中,错误检测和纠正或错误控制是使数字数据能够在不可靠的通信信道上可靠传输的技术。许多通信信道会受到信道噪声的影响,因此在从源到接收器的传输过程中可能会引入错误。错误检测技术可以检测到此类错误,而错误校正可以在许多情况下重建原始数据。
2.1.1 纠错Error Correction的三种类型.
- 自动重复请求(ARQ)
- 前向纠错(FEC)
前向纠错(FEC)是向消息中添加诸如纠错码(ECC)之类的冗余数据的过程,以便即使有许多错误(达到代码的能力)在传输过程中或存储时进行了介绍。由于接收方不必要求发送方重新发送数据,因此在前向纠错中不需要反向信道,因此它适合于诸如广播之类的单工通信。纠错码经常用于较低层的通信中,以及在CD等介质中的可靠存储,DVD,硬盘和RAM。
纠错码通常区分为convolutional codes 卷积码和 block codes块码:
卷积码是逐位处理的。它们特别适合在硬件中实现,并且Viterbi解码器可以实现最佳解码。
块码是在一个处理块逐块的基础。分组码的早期示例是重复码,汉明码和多维奇偶校验码。它们之后是许多有效的代码,由于它们的当前广泛使用,里德-所罗门代码最为著名。Turbo码和低密度奇偶校验码(LDPC)是相对较新的结构,可以提供几乎最佳的效率。
3. 混合方案
混合ARQ是ARQ和前向纠错的结合。
至于错误检测方案,则包含很多种:
错误检测通常是使用合适的哈希函数(或具体地说,校验和,循环冗余校验或其他算法)实现的。存在各种各样的不同哈希函数设计。然而,由于它们的简单性或它们对于检测某些类型的错误的适用性(例如,循环冗余校验在检测突发错误中的性能),它们中的一些被特别广泛地使用。
Minimum distance coding 最小距离编码
Repetition codes重复码
Parity bits奇偶校验位
Checksums校验和
Cyclic redundancy checks (CRCs)循环冗余校验
Cryptographic hash functions哈希函数
Error-correcting codes(ECC)纠错码。 任何错误纠正代码都可以用于错误检测。
2.1.2 部分应用场景
传送电视(包括新频道和高清电视)和IP数据的需求推动了对卫星转发器带宽的需求不断增长。应答器的可用性和带宽限制限制了这种增长,因为应答器的容量由所选的调制方案和前向纠错(FEC)速率决定。
现代硬盘驱动器使用CRC码检测和使用Reed-Solomon码来更正扇区读取中的细微错误,并从“已损坏”的扇区中恢复数据并将其存储在备用扇区中。RAID系统使用多种错误纠正技术来纠正硬盘驱动器完全故障时的错误。
错误检测与纠正往往都在传输层及以下实现,Parchive项目则是一个例外,在应用层和数据文件的层面来实现。
2. Reed-Solomon码介绍
Reed-Solomom编码器接受一块数字数据并添加额外的冗余位。传输或存储过程中会出现很多错误(噪音或干扰,cd上的划痕)。解码器处理每个块并且尝试去纠正错误,恢复原始数据。可以纠正的错误的数量和类型取决于Reed-Solomon代码的特性。
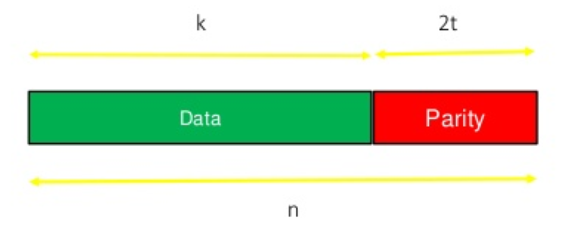
图显示了一个典型的Reed-Solomon码字(这被称为系统码,因为数据保持不变并且奇偶符号被附加):
例子:流行的Reed-Solomon码是RS(255,223),带有8位符号。每个码字包含255个码字字节,其中 223个字节是数据,32个字节是奇偶校验。对于这个代码:
n = 255,k = 223,s = 8
2t = 32,t = 16
解码器可以纠正码字中的任何16个符号错误:即码字中任何位置的多达16个字节的错误可以被自动纠正。
里德-所罗门码是分组码。这意味着将输入数据的固定块处理为输出数据的固定块。对于最常用的RS码(255,223)– 223 Reed-Solomon输入符号(每个8位长)被编码为255个输出符号。
大多数RS ECC方案都是系统的。这意味着输出代码字的某些部分包含原始格式的输入数据。
之所以选择八位的里德-所罗门符号大小,是因为使用当前技术很难实现较大符号大小的解码器。此设计选择将最长的代码字长度强制为255个符号。
标准的(255,223)Reed-Solomon代码能够纠正每个代码字中多达16个Reed-Solomon符号错误。由于每个符号实际上是八位,这意味着由于内部卷积解码器的存在,该代码最多可以纠正16个短错误突发。
Reed-Solomon codes have the longest history. The strip unit is a w-bit word, where w must be large enough that n ≤ 2w+1. So that words may be manipulated efficiently, w is typically constrained so that words fall on machine word boundaries: w ∈ {8, 16, 32, 64 }. However, as long as n ≤ 2w+1, the value of w may be chosen at the discretion of the user. Most implementations choose w=8, since their systems contain fewer than 256 disks, and w=8 performs the best. Reed-Solomon codes treat each word as a number between 0 and 2w-1, and operate on these numbers with Galois Field arithmetic (GF(2w)), which defines addition, multiplication and division on these words such that the system is closed and well-behaved .
里德-所罗门码的历史最长。条带单元是一个w位的字,其中w必须足够大以使 n ≤ 2 w +1。为了可以有效地操纵单词, 通常会对w进行约束,以使单词落在机器单词边界上:w∈{8,16,32,64}。但是,只要n≤2 w +1,用户就可以自行选择w的值。大多数实现选择w = 8,因为它们的系统包含少于256个磁盘,并且w = 8表现最好。里德-所罗门(Reed-Solomon)码将每个单词视为0到2 w -1之间的数字,并使用Galois字段算术(GF(2 w))对这些数字进行运算,该算法定义了这些单词的加法,乘法和除法,从而使系统成为封闭且行为良好。
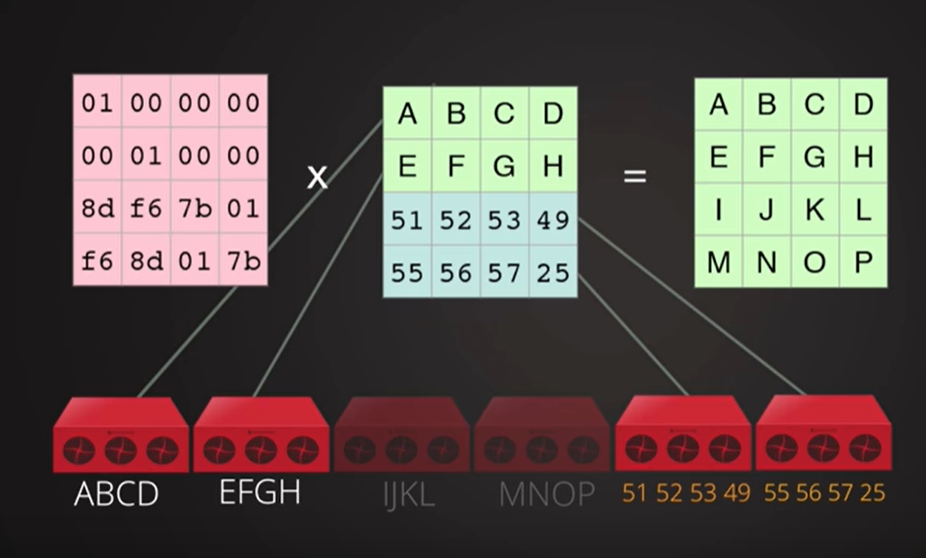
用里德-所罗门码进行编码的行为是简单的线性代数。生成矩阵是从构造范德蒙矩阵,该矩阵由乘以ķ数据字创建一个码字的组成ķ数据和米 编码字。图中描绘了该过程
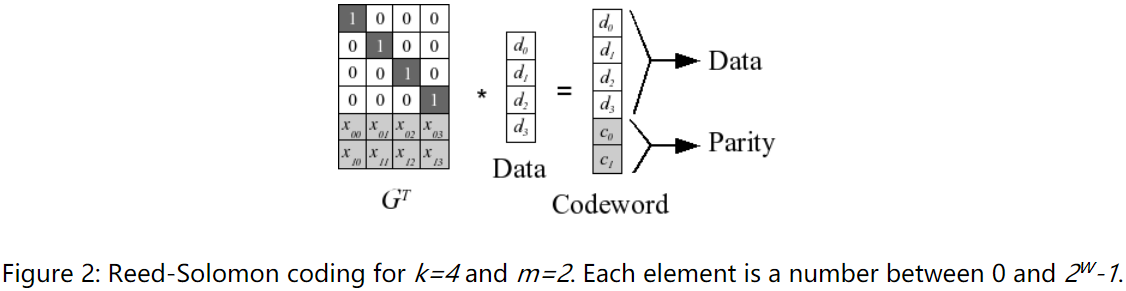
Figure 2: Reed-Solomon coding for k=4 and m=2. Each element is a number between 0 and 2^w-1
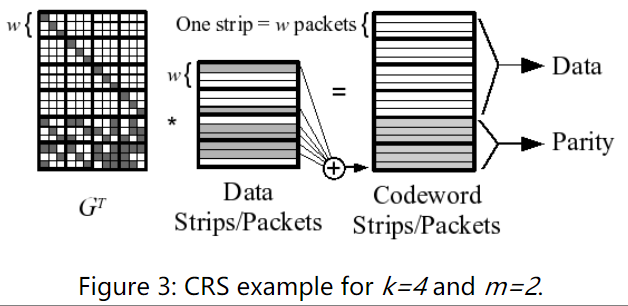
To make XORs efficient, the packet size must be a multiple of the machine's word size. The strip size is therefore equal to w times the packet size. Since w no longer relates to the machine word sizes, w is not constrained to [8,16,32,64]; instead, any value of w may be selected as long as n ≤ 2w.
Reed-Solomon Codes 部分应用场景
Reed-Solomon Codes是基于块的纠错码,在数字通信和存储中应用广泛。主要原理是在传输数据的同时,也传输一定量的校验信息,当传输出现少量错误时,可以用这些信息恢复出原信息。
在以下系统中有应用:
-存储设备 (including tape, Compact Disk, DVD, barcodes, etc)
-无线或移动通信 (including cellular telephones, microwave links, etc)
-卫星通信
-数字电视
高速调制解调器 such as ADSL, xDSL, etc.
传统上,Reed-Solomon Code 都用在传输层及以下,较少用在应用层和文件级别上。
2.3 Parchive Project
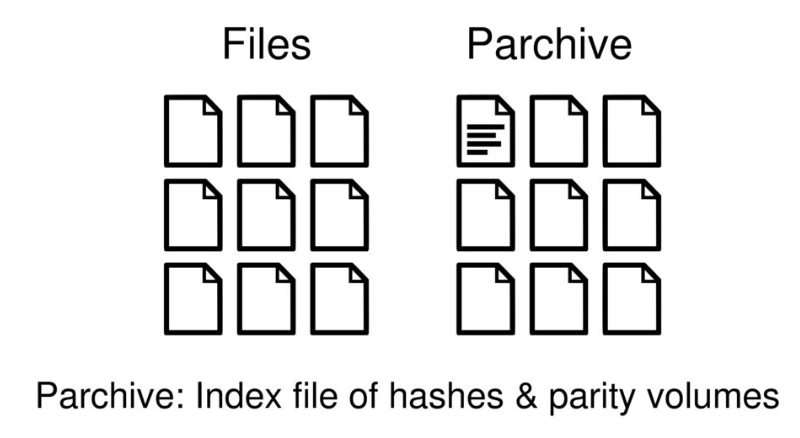
Parchive(综合的奇偶存档partiy archive,并采用奇偶卷集规范 )是个开源规范系统,产生用于par文件,可以修复或重新生成损坏或丢失的数据。
Parchive最初为解决Usenet的可靠的文件共享问题,现在通常用于保护任意的数据损坏。Parchive使用了用于错误检测和纠正的方法,具体采用的是Reed-Solomon编码纠错。
截至2014年,PAR1已过时,PAR2已经成熟,可以广泛使用。
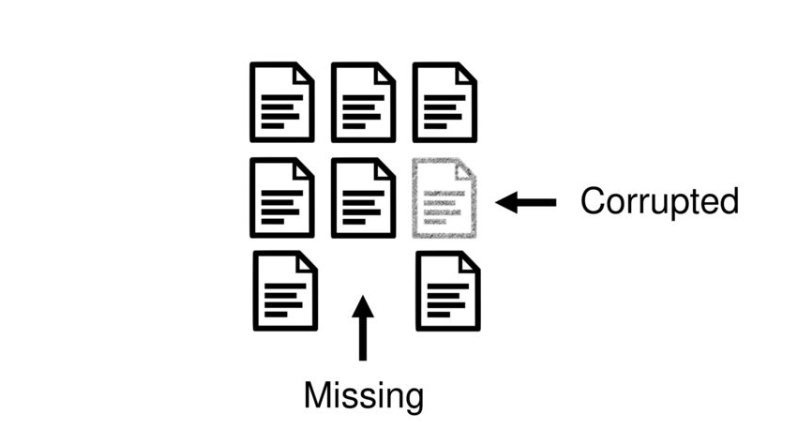

par2 verify Files
par2 repair Files

即使冗余恢复文件有丢失或损坏可以进行修复。
Parchive系统基于这样的思想,即只要有足够的冗余信息(parity),就可以修复损坏或丢失的数据。Parchive将一组数据文件(例如RAR文件)视为一个大型数据集合,将其分为固定大小的BLOCKS。当Parchive程序处理数据时,它会创建足够的parity数据来还原各个块。然后,此冗余恢复数据存储在PAR2文件中。
简单来说,使用了软件RAID技术来提供所需的文件冗余性和可靠性。
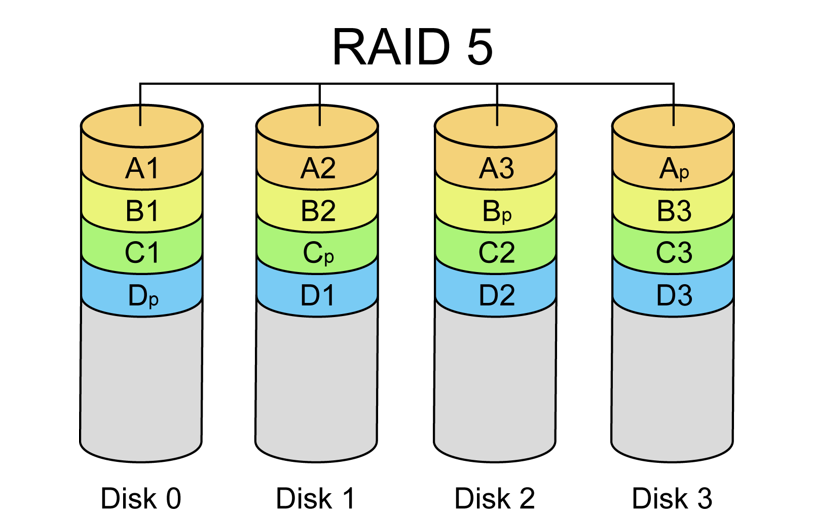
众所周知,在类似于RAID的系统中,Reed-Solomon码可用于为多个故障提供纠错。
该具体技术是基于“Reed-Solomon码”实施,基于“X”的奇偶校验数据块的存在,允许恢复任何“X”真实数据块。(数据块参照文件或比文件小得多的虚拟切片)。
冗余包是根据原始文件的数据生成的,其简明原理可以参考下图

将文件集合分成4部分;每部分的对应位相加得到奇偶(odd,even),然后作为parity的相应位填入parity文件的对应位。当有一部分丢失时,例如第3部分丢失,那么就可以通过剩余的所有部分,以及parity部分,反推出来丢失的位究竟是0还是1.这样就恢复了丢失的文件。
其中采用的运算在数学的逻辑运算符中称为异或
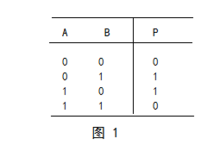
这个简明示例中,可以恢复1部分丢失的数据,然而面对更多的数据丢失时,这需要进一步的纠错技术。
更深入的具体技术实现可以参考Reed-solomon码的实现。
对于par2规范,对应到文件级别的冗余恢复文件生成,以及相关过程示意,见下图:
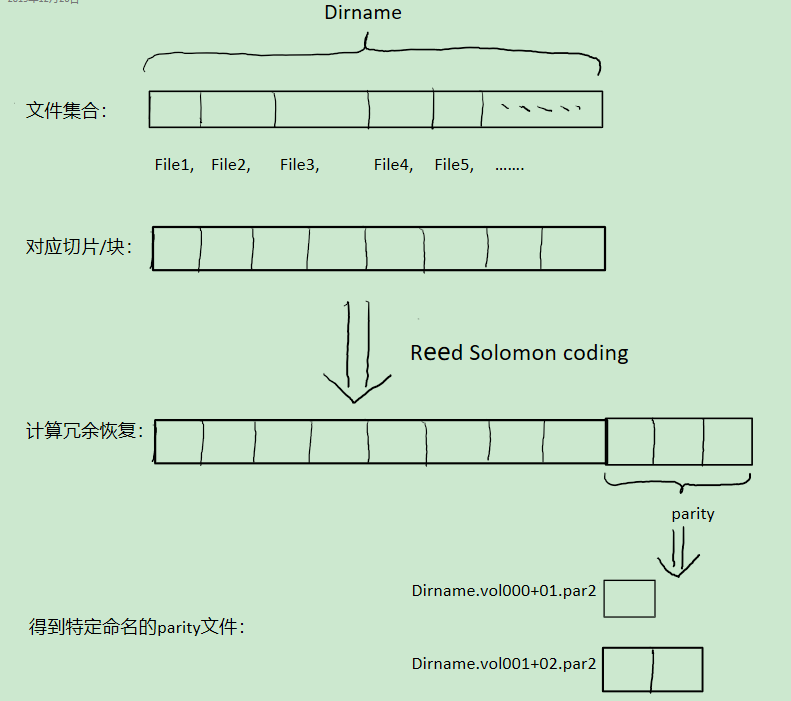
2.4 Reed-Solomon 与 文件数据重建过程示例
A Parity Volume Set(奇偶校验卷集,为便于理解简称为冗余恢复文件集)为给定数量的文件提供类似于奇偶校验记录的 RAID。 有了这个parity记录,包含数据文件数据的reed solomon 校验和, 就可以还原集合中丢失的文件。
因此,如果原始文件丢失或损坏,可以从剩余的数据文件和冗余恢复文件中重新构造该文件。这个集合的任何文件都可以用任何冗余恢复文件重建。
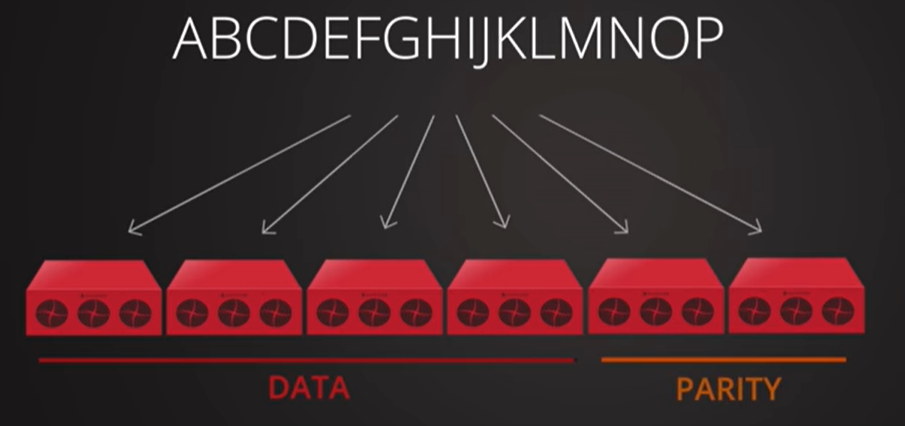
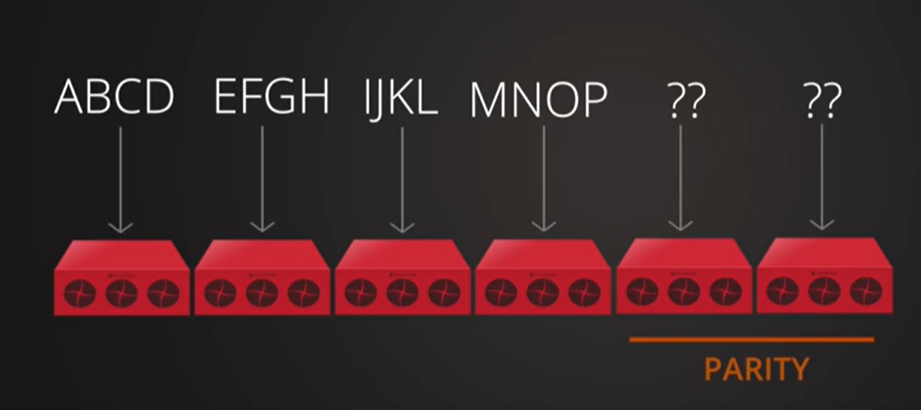
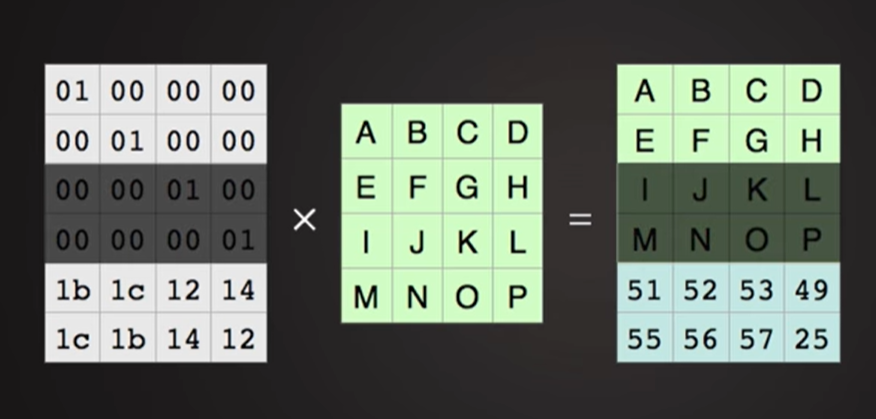
create
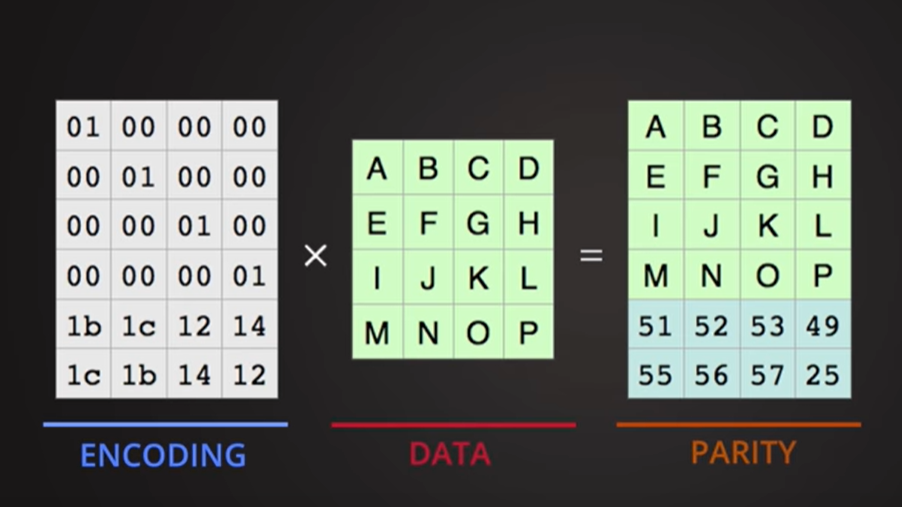
编码矩阵与数据矩阵相乘,得到parity行(比原来矩阵多的2行)
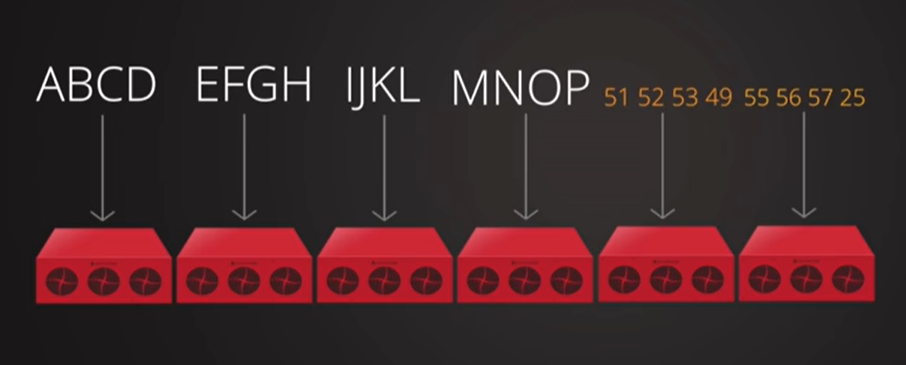
也就是对应的冗余文件
如何从损坏丢失的文件中得到原始数据?

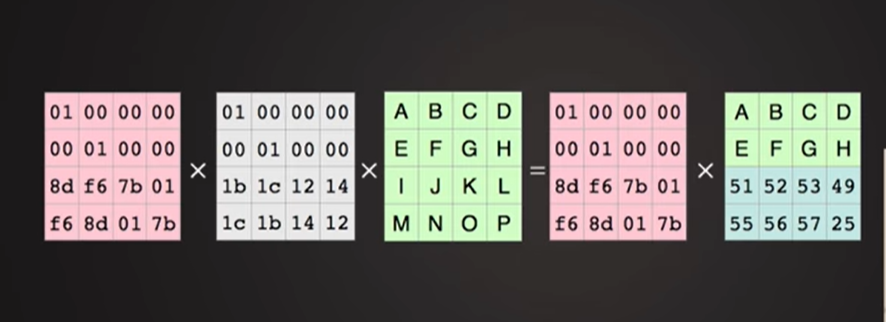
逆矩阵与编码矩阵相乘得单位矩阵,左边抵消。
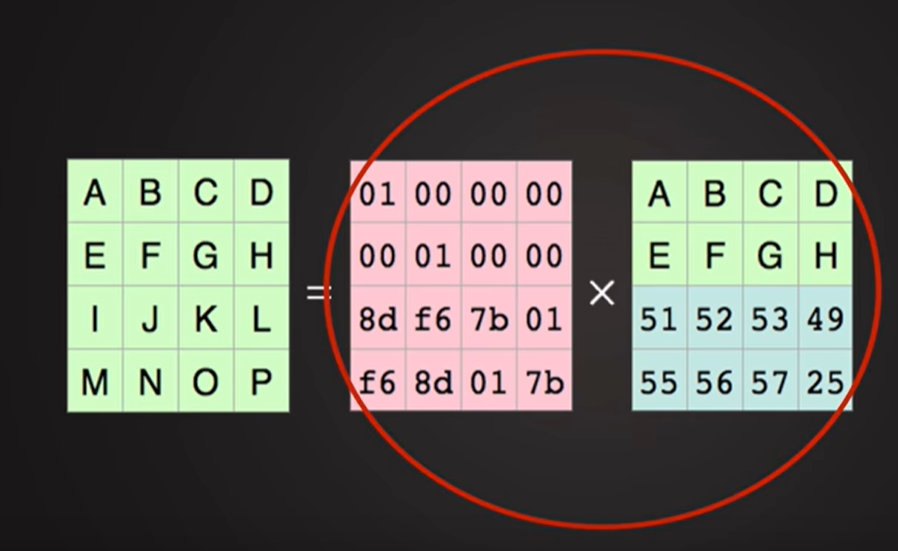
通过丢失后的数据和冗余数据组成的矩阵恢复原始完整数据的原理。
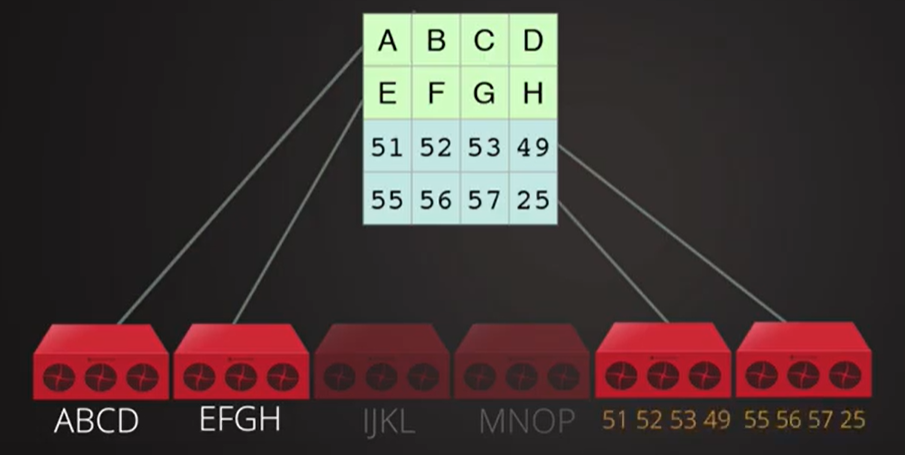
除去丢失数据外剩余数据文件块组成的矩阵
3. Parity文件恢复规范与说明
在应用层对文件实现冗余恢复数据生成,基本可以参考下图,将文件进行处理,然后分块。
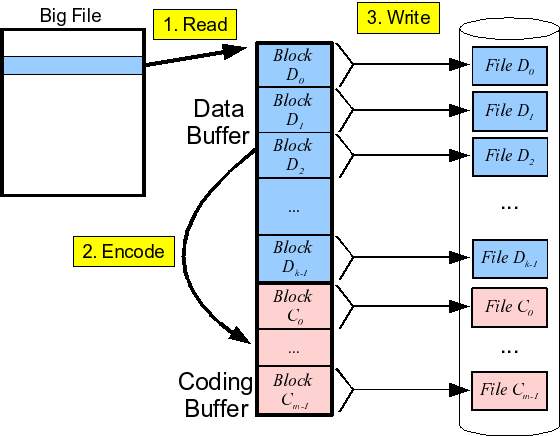
par1.0 和par 2.0 对文件分别有不同的处理策略,导致最终的应用功能和性能有较大区别。
简单说明如下:
若有n个数据和m个恢复数据(m<=n-1), 从这n+m个文件集合中,任意拿出小于等于m个文件扔掉,都可以完全恢复所有数据。
3.1 PAR 1.0 实现
校验和数据的组合:
您有n个文件,想要创建 m个奇偶校验数据。因此,您创建了一个数据字段 D1..Dm,其中D1是file1的第一个字节,D2是file2的第一个字节, D3是文件3 的第一个字节... Dn是文件n的第一个字节 。为该字段创建一个m个奇偶校验和C1..Cm的字段。C1存储为.p01的第一个奇偶校验字节,C2存储为.p02 的第一个奇偶校验字节,C3存储为.p03的第一个奇偶校验字节... Cm 存储为.pm的第一个奇偶校验字节。
然后处理所有文件的第二个字节,依此类推,直到到达最大输入文件的末尾。如果文件没有剩余字节,则使用0进行计算。因此,奇偶校验数据的大小将是存储在奇偶校验卷集中的最大文件的大小。
为了计算校验和,使用了Reed-Solomon算法。
http://web.eecs.utk.edu/~jplank/plank/papers/CS-96-332.html
James S. Plank,关于RAID系统中用于容错的Reed-Solomon编码指南,1996
对程序员的这种算法有很好的描述。
3.2 PAR 2.0 实现
Par 文件中的冗余数据是使用Reed-Solomon码计算的。 这些代码可以获取一组相同大小的数据块,并生成若干相同大小的恢复块。 然后,给定原始数据块的子集和一些恢复块,就可以重新生成原始数据块。 只要丢失的数据块数量不超过恢复块的数量,Reed-Solomon码可以执行此恢复。 在这个规范中,Reed-Solomon码的设计是基于
http://web.eecs.utk.edu/~jplank/plank/papers/SPE-9-97.html
James S. Plank,关于RAID系统中用于容错的Reed-Solomon编码指南,1997
技术报告中包含一个错误,因此设计被稍微改动以修复问题。 Par 2.0使用16位的 Reed-Solomon 代码,可以支持32768块。
相同大小的恢复Reed-Solomon码块来自恢复集中的输入文件片。 切片是每个文件的连续的相同大小的块。 如果一个文件没有填充完这个块,也就是说它结束于切片的中间部分,那么这个切片的其余部分将被当作是用零字节填充的。
PAR 2.0文件本身是由数据包组成的,数据包是独立的部分,带有自己的校验和。这种设计可防止损坏文件的一部分,使整个文件无法使用。
3.3 PAR 规范1.0与2.0 区别
PAR 1.0的局限性都归因于它在“整个”文件上运行。
PAR 2.0通过“虚拟”将您希望保护的文件拆分为许多较小的“切片”(或block块)数据来运行。
PAR 2.0然后以与PAR1.0处理整个文件相同的方式处理这些虚拟切片。生成的恢复数据块与这些切片的大小相同,为方便起见,其中许多将放在单个PAR文件中。
PAR2文件与常规PAR文件不同,因为可以修复损坏的部分(损坏的块)而不是整个文件。较新的格式将仅修复文件中的损坏块,而无需下载整个修复文件。Par2将节省带宽和下载时间,因为您不需要下载与损坏的文件大小相等的PAR文件。
3.3.1 PAR 1.0规范和PAR 2.0规范之间有什么区别?
PAR 1.0有许多限制:
损坏的文件无法修复,而必须完全重建。这意味着10MB文件中的单字节错误将需要使用一个完整的PAR文件来重建损坏的文件。
所有PAR文件的大小均相等,并且包含足够的恢复数据以重建最大的源文件。这意味着,如果您拥有各种大小的源文件,而最小的源文件已损坏,那么您仍然需要一个完整的PAR文件来重建它。在UseNet上使用PAR时,这可能意味着您必须下载10MB的PAR文件才能重建3MB的数据文件。
损坏的PAR文件在重建期间无用。PAR文件的单字节错误使它包含的所有恢复数据均无用。
与少量源文件一起使用时,效率非常低,并且您需要创建过多的PAR文件才能获得所需的保护级别。因此,文件通常会分成许多大小相等的文件,并从这些文件生成PAR文件。
它不能处理超过255个文件。
PAR 2.0完全消除或显著减少了这些限制:
损坏的文件可以修复。10MB文件中的单字节错误可能仅需要使用大小仅为100KB的PAR文件中的恢复数据。
数据文件的大小与PAR文件的大小之间没有关系。此外,PAR文件通常具有各种大小,使您可以根据需要修复的损坏数据量来选择所需的大小。
损坏的PAR文件仍将可用。PAR 2.0可以使用PAR文件的未损坏部分。
PAR文件可以从单个源文件生成,而无需拆分。
它最多可以处理32768个文件。
3.3.2 那么PAR 2.0如何完全消除所有这些限制?
PAR 1.0的局限性全部归因于它在“整个”文件上运行的事实。
PAR 2.0通过“虚拟”地将您想要保护的文件拆分为许多较小的“切片”(或块)数据来运行。然后,PAR 2.0以与PAR 1.0处理整个文件相同的方式处理这些虚拟片。所得的恢复数据块与这些片的大小相同,为方便起见,其中许多将放置在单个PAR文件中。
3.3.3 使用PAR 2.0程序与PAR 1.0程序有何不同?
一个PAR 2.0程序对于单个800MB文件或数百个大小不同的文件将同样有效。既无需拆分大文件,也无需存档大量小文件。这使得文件直接可用,而无需重新加入文件或先解压缩文件。这意味着可以将PAR文件放在SVCD上以保护视频。
对于PAR 1.0,在创建PAR文件时需要指定的唯一选项是希望创建多少恢复数据。
使用PAR 2.0,还必须指定文件将被虚拟划分为多少个切片。使用大量较小的片可以更准确地检测文件中的错误,并减少成功修复所需的数据量或恢复数据。
3.3.4 PAR 2.0 如何实现最小数量的恢复块下载?
PAR2系统的优点在于,一旦拥有所有数据文件,您只需下载一个小的验证文件即可测试所有数据文件。如果一切正常,那么您就完成了。如果不是,您将被告知需要多少个恢复块。这使您能够下载解决问题所需的最少数量的PAR2文件。
问题是,一旦知道需要多少恢复数据块,又如何知道需要下载多少个PAR2文件?答案是,您可以通过查看文件名来判断。
3.3.5 如何通过par2.0 实现按需下载
3.3.5.1 规则与方案设计
基于文件名中标识的块数量,1,2,4,8,16,32,64,128呈几何级数增长。
可以支持的冗余百分比也逐渐增加。
为了支持p2p的方便传输,简化服务器端的任务生成。按照生成的冗余文件,或者5%,10%,15%,20%,25%,30%的比例进行p2p种子的生成。
方案设计:
一种是每个文件都建立一个p2p的种子任务提供下载。
一种是按照阶梯的百分比,分别提供对应文件集合的下载。如5%,10%,15%的块数来。
还有一种是混合的方案。
3.3.5.2 实际数据展示
0 dirsend.par294 dirsend.vol000+001.par2187 dirsend.vol001+002.par2374 dirsend.vol003+004.par2747 dirsend.vol007+008.par21494 dirsend.vol015+016.par22987 dirsend.vol031+032.par25555 dirsend.vol063+064.par211094 dirsend.vol127+128.par23901 dirsend.vol255+045.par2
300G 文件生成15%的冗余,总共有26G,共计10个Par2文件,第一个是索引文件,其余则是恢复块文件。
3.3.5.3 实际混合方案
基于实际的考虑,每个文件都建立一个种子任务下载足矣。最后也可以提供一个所有文件的种子下载任务。接收端根据需要恢复块的多少自行下载种子并下载,判断依据是根据文件名中提示的恢复块的数量,其中种子文件名与冗余恢复文件的名称要保持一致。
对于超过15%的错误,对正常的卫星传输而言不太可能。可以考虑二期的时候,增加到50%的冗余恢复,并提供冗余恢复文件的下载。这时采用整体对外提供p2p的下载。
极低的概率下,如果出现了文件错误过多,甚至超过50%,在不考虑传输时长的情况下,也可以通过p2p进行原始文件的下载,p2p网络设计合理的话,2天左右也可完成分发。
最差和极端的的情况下,可以考虑通过硬盘快递。
3.3.5.4 发送端和接收端逻辑
A. 发送端
具有所有文件数据的发送端,生成冗余,百分比可以设定为例如15%到30%,也可分2次生成,以减少创建时间,分批对外提供p2p下载。根据块大小和数量等具体参数,从而得到par2文件。
B. 接收端
1.) 接收端得到损坏的原始文件后,下载相应目录名或文件名的索引par2文件或者至少含有1个恢复块的par2文件,首先通过索引文件或者任意一个par2文件,校验原始数据文件,得到需要恢复的块数量。
2.)向发送端发起请求,首先确定发送端提供的最大的块文件数量,下载相应数量的par2文件。例如坏了10个块,那么就下载至少16块的par2文件,或者是8+2的par2文件。
3.)如果所有种子的文件数都不满足错误块数,但是还没超过50%,那么则向服务端发起请求创建更多冗余块,然后等待下载。 超过50%的,那么通过p2p网络直接下载原始文件。
3.4 文件名说明
Filename.vol(A)+(B).PAR2
A是所有先前文件的块总数。
B是PAR2文件中的块数。
C是修复RAR存档所需的Block文件数
如果B大于C,则您有足够的PAR2文件来修复损坏的文件。
可以使用par2来修复文件的一部分(单个块)并替换整个丢失的档案。要使用PAR2文件修复损坏的块,请确保有足够的文件来修复。查找一个PAR2,其中的B指定数量大于所需的块数量。
PAR2文件还允许您重建文件存档的整个丢失部分。例如,如果存档中有10个部分,但您仅下载了10个RAR部分中的9个,那么下载足够的PAR2文件将使用户能够重建丢失的RAR。
Par2文件通常使用此命名/扩展系统:
filename.vol000 + 01.PAR2,
filename.vol001 + 02.PAR2,
filename.vol003 + 04.PAR2,
filename.vol007 + 06.PAR2等。
+ 01,+ 02 文件名中的等等表示它包含的块数,vol000,vol001,vol003等表示PAR2文件中第一个恢复块的编号。 如果下载的索引文件指出缺少4个块,则修复文件的最简单方法是下载filename.vol003 + 04.PAR2。 但是,由于冗余,filename.vol007 + 06.PAR2也是可以接受的。
还有一个索引文件filename.PAR2,它在功能上与PAR1中使用的小索引文件相同。这些索引包含文件哈希,可用于快速识别目标文件并验证其完整性。
文件名举例说明:
| File Name | Size | Starting Block | Number of Recovery Blocks | Which Recovery Blocks? |
|---|---|---|---|---|
| steal-this-film-2.sfv | 5 KB | (verification file) | ||
| steal-this-film-2.vol000+01.PAR2 | 420 KB | 0 | 1 | 0 → 1 |
| steal-this-film-2.vol001+02.PAR2 | 840 KB | 1 | 2 | 1 → 2 |
| steal-this-film-2.vol003+04.PAR2 | 1,634 KB | 3 | 4 | 3 → 6 |
| steal-this-film-2.vol007+08.PAR2 | 3,179 KB | 7 | 8 | 7 → 14 |
| steal-this-film-2.vol015+13.PAR2 | 5,054 KB | 15 | 13 | 15 → 27 |
| steal-this-film-2.vol028+24.PAR2 | 9,225 KB | 28 | 24 | 28 → 51 |
| steal-this-film-2.vol052+41.PAR2 | 15,645 KB | 52 | 41 | 52 → 92 |
| steal-this-film-2.vol093+41.PAR2 | 15,645 KB | 93 | 41 | 93 → 133 |
| steal-this-film-2.vol134+41.PAR2 | 15,645 KB | 134 | 41 | 134 → 175 |
当存在多次调用生成多余的恢复文件时,有可能文件名不是完全规律的,数字是2位或者3位的。
# 第一次创建5%的冗余,设置1000个块。# par2 c -b1000 -r5 8M.dat8M.dat.par28M.dat.vol01+02.par28M.dat.vol00+01.par28M.dat.vol03+04.par28M.dat.vol07+08.par28M.dat.vol15+16.par28M.dat.vol31+19.par2# 第二次基于block no.50,创建多余的修复文件# par2 c -b1000 -r10 -f50 8M.dat8M.dat.vol050+01.par28M.dat.vol051+02.par28M.dat.vol053+04.par28M.dat.vol065+16.par28M.dat.vol113+37.par28M.dat.vol057+08.par28M.dat.vol081+32.par2
3.5 Par2cmdline
是实现了par2.0规范的一个客户端,使用Reed Solomon算法创建奇偶校验卷的实用程序。有关使用的算法的详细信息,请参阅SourceForge上的Parchive网站和 github官网。
奇偶校验卷可用于验证一组文件是否未损坏,或用于重建损坏的文件(前提是您有足够数量的奇偶校验卷来匹配丢失或损坏的文件)。
3.6 创建与恢复时间
| 类型 | 命令 | 冗余 | 文件大小 | 时间(minutes) | 文件名 | 备注 | |
|---|---|---|---|---|---|---|---|
| 创建 | create -r15 -R | 15% | 197G | 360m/6小时 | AO-MEN-FENG-YUN-3-3D | 每个100M, 106052420 bytes, 2000个block生成300个block冗余 | |
| 检验 | v | 15% | 197G | 36m/81m | AO-MEN-FENG-YUN-3-3D | 18个文件损坏 | |
| 恢复 | r -p vol001+002.par2 | 6%,300个中的18个block用于修复 | 197G | 203m/3.3小时 | AO-MEN-FENG-YUN-3-3D | 修改了代码-p只删除备份文件; 只保留了18个block. |
每个block约100M
创建冗余时, 50M,100M的Block, 以及 cache 不同时创建时间的记录比较。
| 命令(创建冗余) | 文件大小及参数说明 | 总时间 |
|---|---|---|
| par2 c -r10 -R AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV.par2 AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV | 197G 2000 block (100~M) | 240m 4个小时 |
| time par2 c -s52428800 -r10 -R 52428800-AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV.par2 AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV | 197G, 4038-Block(50M) | 346m, 5.8小时 |
| time par2 c -s52428800 -r10 -m300 -R 52428800-m300-AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV.par2 AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV | 197G, cache300m, 50M block | 375m 6.2小时 |
| par2 c -s52428800 -r10 -m900 -R 52428800-m900-AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV.par2 AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV | 197G, cache 900M, 50M block | 296m, 5小时 |
| time par2 c -s26214400 -r10 -m8000 -R 26214400-m8000-AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV.par2 AO-MEN-FENG-YUN-3-3D_FTR_S_CMN-QMS_115M_51_2K_20160125_HXFILM_OV | 197G, cache 8000M, 4711 block (25M) | 418m, 7小时 |
| time par2 c -t30 -T4 -r10 -R Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV.par2 Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV | 115G 2000-block | 206m 3.3小时 |
| time par2 c -s52428800 -r10 -R 52428800-Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV.par2 Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV | 115G 2358-Block(50M) | 300m, 5小时 |
| time par2 c -s52428800 -r10 -m300 -R 52428800-Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV.par2 Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV | 115G,cache300M, block 50M, | 163m 2.7小时 |
| time par2 c -s52428800 -r10 -m1000 -R 52428800-Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV.par2 Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV | 115G,cache1000M, block (50M) | 140m, 2.3小时 |
| time par2 c -s26214400 -r10 -m10000 -R 26214400-m10000-Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV.par2 Albb3_FTR-1-3D_F-178_20_2K_20190115_IOP-3D_OV | 115G, cache 10000M, 4711 block ( 25M) | 220m, 3.6小时 |
| 4par2 c -s104857600 -r10 -m800 -R 100Mblock-800m-big400gdir.par2 big400gdir; | 442G, 800M cache, 4571 block(100M) | 698m, 11.6小时 |
块的大小与创建冗余的效率需要平衡tradeoff, 块大速度快,块小则需要下载的冗余文件小。
目前来看,在固定 block大小的创建过程中,如果日常传输文件在200G左右,那么block设置为50M-80M是个比较合理的数字, 构建10%的冗余(400个block),能保证在4-6小时内完成创建(有2个par2进程同时进行的情况下,内存占用500M左右)。
传输时,如果卫星接收下来只有10几个block损坏,那么也只需要传输500-800M的大小。(具体损坏情况需要收集和测试)
时间消耗主要花在create阶段,可以采用高性能的计算机,以及采用并行的算法来一定程度上解决。
至于恢复时间的最短化需要什么样的参数则需要进一步调整,同时也与硬盘读写和cpu的性能有关系,需要准备服务器进行测试。
3.7 修复错误数
par2 create test.mpg.par2 test.mpg
800Mb的 test.mpg 将创建8个par2文件,近100个块。(1,2,4,8,16,32,37)
第一个 test.mpg.par2 有39kb, 其他文件则为从443 KB 到15 MB 不等。
这些 PAR2文件可以从原始 test.mpg 文件中恢复多达100个错误,总共40MB的丢失或损坏的数据。
par2 create -s307200 test.mpg.par2 test.mpg
当用300kb作为块大小时,将创建9个par2文件。
可以恢复134个错误,共计40MB的丢失或损坏的数据。
以上2个例子都是5%的恢复数据。
par2 create -s307200 -r10 test.mpg.par2 test.mpg
创建10% 恢复数据而不是默认的5% ,并且使用300 KB 的块大小.
所用时间更长。
会创建9个 PAR2文件,但是它们能够纠正多达269个, 总共80 MB 的错误。
这说明,错误的个数与块的个数有关,每个错误的大小则与生成的冗余的百分比有关。
推论:
a. 如果是数量很少的,突发性的大面积的错误类型,那么可以将块的大小设置大一些,这样只需极少的块就可以覆盖到错误。
b. 如果是均匀的错误类型,每次错误大小比较小,但是总数量相对较多,那么可以将块的大小设置得小一些,这样不必下载多余的恢复块。
c. 如果是a,b的混合类型的错误,而且不是那么极端化,那么块大小设置中等适中,则成本和方案复杂性也都相对较适中。
4 整体架构与流程说明
4.1 涉及到的主要模块及关系
4.2 BFT传输架构图
BFT指p2p的peer客户端程序,支持大文件传输,采用Bittorrent协议。
Tracker指用于p2p网络的一个中心服务器,负责跟踪系统中所有的参与节点,收集和统计节点状态,帮助参与节点互相发现,维护共享网络中文件的下载。一个Tracker服务器可以同时维护和管理多个文件共享网络。
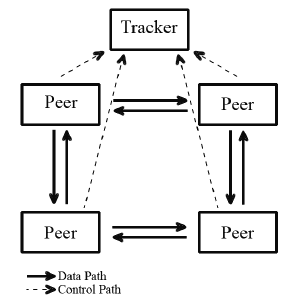
4.3 BFT与卫星传输恢复架构图

DCPX 表示损坏或不完整的DCP.
BFT即p2p的文件传输网络。
4.4 时序图与说明
创建节点PServer:业务端拿到完整正确的目录,通知psapi 服务,告知完整目录路径,psapi 服务开始创建冗余文件,完成后生成完成标记或主动通知业务端,生成种子,并启动p2p服务。p2p的做种时间设为1-2天结束。然后删除相关冗余文件(因为过了卫星接收的一定时间后再下载冗余就意义不大了)
冗余恢复节点PClient: 卫星接收端开始接收,通知papi开始dcp接收,papi开始下载同名dcp的par2文件。卫星接收端完成第一次接收,数据有损坏,则通知papi服务, 告知完整目录路径。 papi 服务开始校验,如果还没下载par2下载,则启动对PServer特定规则的同名目录的种子查询,发现并下载后开始启动冗余校验,发现所需block数量后,通过p2p下载所需的block数量,然后进行目录数据恢复。恢复的结果生成完成标记或者主动通知卫星接收端。(前者是卫星接收端主动定时查询,后者是被动等待通知)
种子中心服务器,可以和PServer同一台:存放所有的冗余文件种子。并供所有冗余恢复端查询。
par2的索引文件xx.par2, 由各个冗余恢复文件做种的.torrent种子文件,因为较小,足以支持高并发的短时间下载,都放在http服务上,便于下载。种子所对应的的文件则通过p2p的BFT网络进行传输。
5. 参考资料
卫星传输
标准:电影数字拷贝卫星分发系统技术要求和测量方法
https://www.hi67.cn/archives/6460326.html
王萃, IP网络传输数字电影拷贝的关键问题研究,现代电影技术,2013
王萃, 数字电影拷贝的 I P网络传输,现代电影技术,2014
王萃,王木旺等,电影数字拷贝的网络化传输, 现代电影技术,2013
王萃,中国专业电影数字拷贝的卫星传输发展概况,现代电影技术,2013
美国数字电影卫星传输和修复技术现状 ———赴美调研考察报告,现代电影技术,2011
肖凯,电影数字拷贝传输方式的技术经济分析,现代电影技术,2013
parity tools
Parity Volume Set Specification v1.0
http://parchive.sourceforge.net/docs/specifications/parity-volume-spec-1.0/article-spec.html
Parity Volume Set Specification 2.0
http://parchive.sourceforge.net/docs/specifications/parity-volume-spec/article-spec.html
par2cmdline
https://github.com/Parchive/par2cmdline
http://www.slyck.com/Newsgroups_Guide_PAR_PAR2_Files
https://en.wikipedia.org/wiki/Parchive
http://www.harley.com/usenet/file-sharing/11-understanding-par2-files.html
https://github.com/animetosho/ParPar/blob/master/benchmarks/info.md
p2p网络
P2P网络与BitTorrent技术简介
https://www.zybuluo.com/zhongdao/note/1390440
https://slideplayer.com/slide/12531843/
Error detection and correction
https://en.wikipedia.org/wiki/Error_detection_and_correction
https://en.wikipedia.org/wiki/Forward_error_correction
https://en.wikipedia.org/wiki/Internet_protocol_suite
Reed-Solomon
Reed Solomon Tutorial: Backblaze Reed Solomon Encoding Example Case
https://www.youtube.com/watch?v=jgO09opx56o
Backblaze Open Sources Reed-Solomon Erasure Coding Source Code
https://www.backblaze.com/blog/reed-solomon/
Reed–Solomon error correction
https://simple.m.wikipedia.org/wiki/Reed%E2%80%93Solomon_error_correction
https://en.wikiversity.org/wiki/Reed%E2%80%93Solomon_codes_for_coders
Reed-Solomon Codes
https://www.jianshu.com/p/4907433d1d69
https://www.slideshare.net/shaileshtanwar/reedsoloman-and-convolution-c?next_slideshow=1
Erasure Code原理
https://blog.csdn.net/sinat_27186785/article/details/52034588
Code Performance Evaluation
A Performance Evaluation and Examination of Open-Source Erasure Coding Libraries For Storage
https://www.usenix.org/legacy/event/fast09/tech/full_papers/plank/plank_html/
Reed-Solomon coder computing one million parity blocks at 1 GB/s. O(N*log(N)) algo employing FFT.
https://github.com/Bulat-Ziganshin/FastECC
