@zhongdao
2020-01-30T14:55:48.000000Z
字数 8599
阅读 2727
Visually Understanding Worker Pool
未分类
https://medium.com/coinmonks/visually-understanding-worker-pool-48a83b7fc1f5
Visually Understanding Worker Pool
Jul 20, 2018 · 8 min read
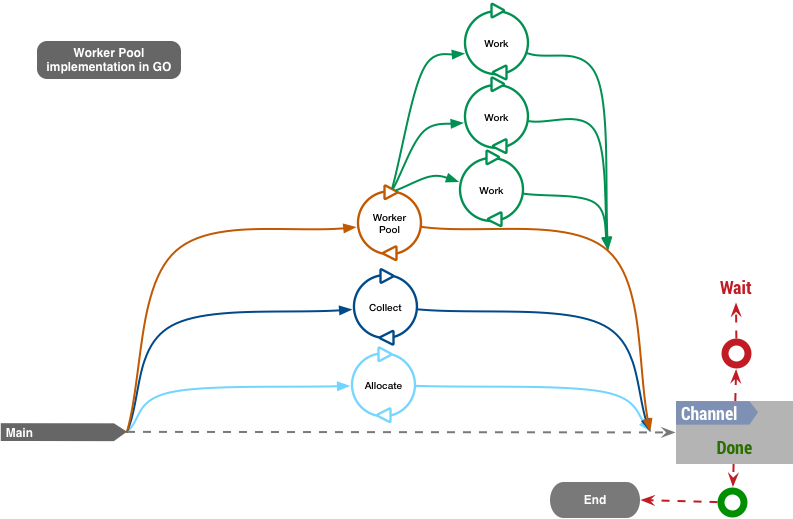
Example diagram of a worker pool process in Go using goRoutines
The problem we need to focus on is creating a more visual approach to understand patterns and some other solution architectures that could create a blackbox situation in your internal team if they are not understood correctly.
Often, we are tempted to “copy and paste” code and don’t even realize how things work in the underlying layers. Today, we are going to review the famous (yet underrated) Worker Pool (aka Thread Pool). In *Go,* this is commonly approached using buffered channels as the main queues and communication channels between goRoutines. Understanding channels before continuing with this post is more than advised for a clearer comprehension.
Understanding the Diagram
We started this post showing a high level diagram of a worker pool implementation in *Go*. It resumes the main operations that need to happen in any worker pool implementation:
- “Allocate” resources to be processed
- “Work” (or process) those resources
- and “Collect” the results for further post-processing
These operations can be accomplished in different ways, even a single script with iterative lines, but today we are going to use a concurrent and parallel design in *Go* to maximize the hardware resources available, obtain results as fast as possible and continue the tendency towards microservice architecture.
Let’s see at each component in a more detailed “zoomed-in” fashion:
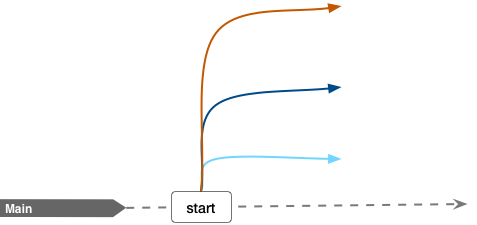
The main GoRoutine is the normal program execution, for this case our program does little in specific since we are focusing in worker pool, the only specific task to perform is spawning and controlling other GoRoutines related to the proper execution of the Worker Pool
Boolean Channel “Done”
The channel “Done” ( done chan bool) is used as the main program control which indicates that all tasks has been performed and all goRoutines completed. Different from the “main loop” design, the main GoRoutine waits for a signal to be sent via this channel to stop and end the program. Why we use a channel to control the program execution and wait for all goRoutines is easy to respond: simplicity
In the previous example, our program waits to continue the execution until the channel variable “done” ( <-m.done) receives a value. This makes the code smaller and easy to read.
Allocating Resources
“Allocate” goRoutine
“Allocate” goRoutine is a sub routine that spawns from the main goRoutine, its purpose is to allocate resources that are going to be used by the worker pool. It has a main loop with a limited lifetime: until all the resources has been allocated. To better understand this, lets take a look at the following diagram:
“Allocate” goRoutine tasks
“As long as there are resources to Allocate, the goRoutine is going to continue its operation” is the expression that better describes the previous diagram. The allocation execution receives in an array of unknown size of resources and iterates over the array, converts it to a structure “Job” that can be later on processed by another goRountine. The resources being converted to “Job” is sent to a buffered channel “Jobs” which has limited size/dimension. You might have noticed that in the example, the array of Resources is bigger than the elements that can be buffered/sent in the channel, and this is by design intended as it controls the number of parallel Jobs that can be performed simultaneously. That’s it, if the “Jobs” channel is full the iteration over resources will halt until it can allocate Jobs in the Jobs channel again.
Why are we converting Resources to Channel Jobs obeys the design principle of Separation of Concerns. Resources being sent to the Jobs channel are going to be picked up by another goRoutine for later processing, limiting the concern of the allocation to only receiving, converting and allocate. The following code represents the discussed diagram:
Processing the Jobs Channel (Jobs to be Done)
“Worker Pool” goRoutine existence is defined by the “Jobs” Channel: As long as there are jobs that need to be worked on and processed, continue doing so. Continuing with the Separation of Concerns this goRoutine purpose is the actual processing of Jobs, and as most-things-go, it works concurrent and in parallel. This is the most critical section of our discussion as is covers the creation and work assignment of the worker pool.
Worker Pool using Sync.WaitGroup to control spawning new GoRoutines
In this case, the worker pool goRoutine spawns new “work” (or “worker”) goRoutines, how many to spawn is defined by configuration or injected into our solution, for now lets define “3” as the number of workers in the pool. One key factor of any worker pool (or thread pool) is to control the size of the pool, if you don’t do so, chances are that hardware resources are going to be exhausted or even your program deadlocked.
We are going to simplify our solution by using Sync.WaitGroup which basically servers as structure that we can ask anytime to see if all the goRoutines have completed. Similar to our “Done” Channel, the WaitGroup package exposes a Wait method that will halt the execution until a value is received. The code looks similar to:
As you might have noticed it, the synchronisation is just an atomic counter that we increment ( Add) and then we decrement ( Done) inside each sub-goRoutine. Then the workerPool halts execution until wg.Wait() condition is satisfied.
Now let’s look into the actual execution of each “work” (or worker) to better understand all the synchronisation and actual processing of the Jobs.
“Work” goRoutine process
In the WokerPool goRoutine we saw how we spawn new “work” goRoutines inside the for loop by calling go m.work which will create the new goRoutine(s).
Inside this new goRoutine, is the actual processing of the Jobs and assigning results, for this, each new “work” goRoutine will perform a for range jobs loop over the channel “Jobs”. The effect this has is that each work routine will grab a unique Job due to the implementation of Channels in Go which uses locks and makes sure only one item in the channel can be picked up by a goRoutine, this also defines the lifetime of a “work” goRoutine: as long as there’s work to do in the Jobs channel, continue iterating. This technique exposes a better reading and understanding of the code, which hides all the machinery of locking and unlocking a shared structure between processes.
Once we pick a Job from the channel “Jobs” we process it and create a “Result” object that is then sent to a “Results” channel. This is a continuation of our adopted Separation of Concerns design, the lifetime of a “work” goRoutine is defined by the amount of time it takes to process a “Job” and the result sent to the “Results” channel, it will iterate again over the “Jobs” channel if its not closed yet.
The previous code represents this chapter, as you can see, the variable wg ( sync.WaitGroup)is passed as reference to the method so when we finish processing all the "Jobs” we can call wg.Done() letting the parent goRoutine (workerPool) know that this specific goRoutine has finished.
*Bonus Content:* the actual processing of the Job does not happen anywhere in the code we have published so far, this is because we are using Dependency Injection specifically by using the function signature ProcessorFunc as an argument to the worker pool and then to the work goRoutine, this isolates the actual implementation of the worker pool and processing the work is accomplished in another layer, keeping it simple to reuse.
Gathering the Results
“Collect” goRoutine
So what we should do once results are being sent to the “Results” Channels? The answer is simple: collect, process it and delegate the result.
Our buffered channel “Results” keeps all the results from all the workers, so we have a different approach to process this “queue” (in this case we just iterate over them). The important part about this implementation is understanding that processing a Job has a different concern than processing its results. One can take different actions depending on the outcome.
From the previous code is important to understand and correlate with the diagram a few factors:
- Dependency Injection is used again to inject the result into the “post-processor”, this creates a delegation of the result outside the pool context where the injected function can take different actions.
The signature for this Type is similar to:
type ResultProcessorFunc func(result Result) error - We are just iterating over the channel, this defines the lifetime of the collect routine. We can swap this approach and create another pool of workers to speed up the post-processing of results, but by design, this should not be necessary since processing a “Job” in the “work” goRoutines should in theory take more time that post-processing the result. If the later is not satisfied in your design it means you might have many business logic rules in the result that might be worth looking into and be moved to the “Job” processing.
- The
m.done <- trueat the end signals the “Done” channel letting the main goRoutine know that the worker pool has finished.
What’s Next?
At this point we have diagramed, understood and implemented a full concurrent, parallel and abstract worker pool in Go. The practice of creating visual representations and/or diagrams of our solutions to problems has been heavily appreciated since the beginning of the information era. It helps you abstract, find patterns and opportunities to improve your solutions and hopefully, create fertile soil for better documentations.
Feel free to grab the entire code and some examples here:
dmora/workerpoolworkerpool - Small Go-Lang package implementing the worker pool patterngithub.com
